






目录
1.2 type 函数和 isinstance 函数和print 函数
str.endswith(suffix[, start[, end]])
str.startswith(prefix[, start[, end]])
str.replace(old, new[, count])
5.使用代码完成一下逻辑,根据输入的行数打印如下图案(等边三角形)
6.有1,2,3,4这四个数字,能组成多少个互不相同且无重复数字的三个数?分别是什么?
7.请用嵌套for循环输出如下等边三角形(三个边均是5个*)
3.编写程序,键盘输入x和y的值,计算并输出表达式 ln(3x-1)/y的值。要求设置异常处理,对除0、负数求对数两种情况进行异常捕捉处理(math.log)
4.定义input_password函数,提示用户输入密码.如果用户输入长度<8,抛出异常,如果用户输入长度>=8,返回输入的密码
5.写⼀个⽅法sanjiao(a, b, c),判断三个参数是否能构成⼀个三⾓形,如果不能则抛出异常Exception,
7.编写代码调用CCircle方法,计算圆面积,定义一个异常,如果半径为 抛出异常
5.实现学生管理系统,完成对学员的增,删,改,查和退出学生管理系统。
4.写函数,获取传入列表的所有奇数位索引对应的元素,并将其作为新列表返回。
5.写函数,判断用户传入的对象(列表)长度是否大于5,如果大于5,那么仅保留前五个长度的内容并返回。不大于5返回本身。
6.写函数,检查传入的字符串是否含有空格,并返回结果,包含空格返回True,不包含返回False
7.写函数,接收n个数字,分别写4个函数求n数字的和、差、商、积
3.请实现一个装饰器,每次调用函数时,将函数名字以及调用此函数的时间点写入文件中
2-通过测试类来加载用例:load.loadTestsFromTestCase
3-通过测试所在模块来加载用例-load.loadTestsFromModule
2.4)利用unittestreport模块里面的ddt实现用例描述添加
Ⅰ 环境搭建
第 1 章. 环境搭建
1⃣️ 什么是 Python
Python 是一门编程语言,关于编程语言我们后面再详细讲。首先我们思考,为什么我们要学习 Python
1. 为什么要学习 Python
1.1 自动化
很多时候,虽然可以通过 gui 工具快速实现功能。但如果工作量大,内容重复,也是一个非常痛苦的事情。通过 Python 可以实现自动化,从而提高效率。
1.2 提高学习能力
在工作的过程中我们会学习很多软件的使用,也不断有新的软件开发出来。学习 Python 后可以深刻理解软件的本质,在学习新软件的时候能够更快的掌握和使用。
1.3 未来的趋势
随着时代的发展,未来的工作必将会要求人人懂电脑。那么会一门编程语言会让我们掌握先机。而 python 简单易学,且可以快速应用在我们的工作和生活中是我们首选的原因。
2. 什么是编程语言
前面讲到 Python 是一门编程语言,那编程语言是什么呢?
2.1 概念

人和人交流沟通所使用的语言叫做自然语言,例如汉语,英语等。

所谓的编程语言,其实就是人和计算机交流的语言。编程语言有极严格的语法,和准确没有歧义的语义,通过这些语法和语义编写出特定的程序交由计算机执行,完成设定好的任务。
学习编程语言和学习自然语言类似,自然语言都是先学习语法,字,词,然后阅读文章,最后模仿写文章,编程语言也是先学习语法,关键字,流程控制语句,然后阅读别人编写的代码,最后模仿编写自己的代码。

自然语言一般都会有成百上千的字和词,而编程语言通常只有几十个关键字,几个流程控制语句,所以编程语言比自然语言容易学得多。
2.2 分类
编程语言一般分为机器语言,汇编语言和高级语言。
2.2.1)机器语言

能够直接被计算机识别的指令称为机器语言。机器指令就是一串二进制数,010110101。它的优点是能够直接操作计算机最底层的动作。缺点是人类难以记忆和阅读,学习成本高,需要熟知计算机的物理原理,目前只有各大芯片厂商的技术人员使用机器语言进行编程外,绝大部分程序员使用的是高级语言。
2.2.2)汇编语言

汇编语言本质上就是机器语言,只不过为了阅读和书写,给不同的指令加上了简短的助记符。例如使用 ADD 表示加,SUB 表示减。但它的学习成本依然很高,只有少数对计算机硬件熟悉的程序员在使用。
2.2.3)高级语言

因为机器语言,汇编语言都是直接操作计算机底层的运算器的微小步骤,要实现我们看起来的简单功能例如在屏幕打印一行文字,需要大量代码。因此机器语言和汇编语言也称为低级语言。通过低级语言编写程序非常繁复,计算机科学家发明了高级语言。
高级语言并不是特指一种语言,在计算机技术的发展历程中出现了很多高级语言,其中大名鼎鼎的 C,Java,PYTHON 都是高级语言。
高级语言是对低级语言的封装,高级语言编写的代码是给人类阅读的,计算机不能直接识别,需要通过翻译成机器码然后交给计算机执行。
根据不同的翻译机制又分为编译型编程语言和解释型编程语言
1. 编译型编程语言
如果把高级语言编写的代码比作一篇英文文章,计算机比作一个不懂英文的人。那么这个人可以找一名懂英文的翻译将这篇文章翻译成中文后,他可以随时随地的阅读这篇翻译后的文章。
编译型编程语言就是通过编译器(英文翻译)将代码(高级语言编写的程序)编译(翻译)成可执行文件(翻译后的文章)。可执行文件可以在任何支持的平台上,脱离编译环境运行。
因为可执行程序就是机器码,所以它的执行效率高。但修改起来非常不方便,只要源代码修改后都需要重新编译后生成新的可执行程序。C 语言,C++ 就是典型的编译型编程语言。

2. 解释型编程语言
接上面的比喻,这个人还可以拿一个随身电子词典,逐字逐句的边看边翻译这篇文章。
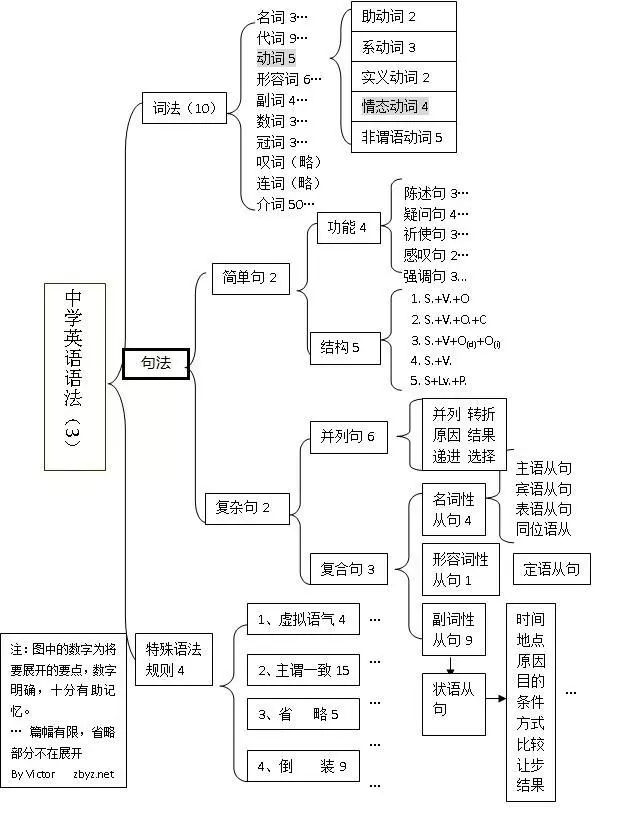
解释型编程语言就是通过解释器(电子词典)将代码逐行翻译成机器语言,然后交由计算机执行。解释型编程语言编写的程序离不开解释器,因为是边翻译边执行所以相对的效率不高,但是修改起来很方便,只要源代码修改了,下一次执行就是修改后的代码。Python,JavaScript 就是典型的解释型编程语言。
2⃣️ Python 运行环境搭建
上面我们学习了 Python 是一门解释型编程语言,那么 Python 代码离不开 Python 解释器,所谓的搭建 Python 开发环境搭建的核心就是安装 Python 解释器。
1. Python 解释器
python 解释器就是翻译 python 代码给计算机执行的一个程序。它的安装非常简单,在官网下载相对于平台的安装程序即可,注意下载 3.6+ 的版本。根据安装程序的指引,只需要简单的下一步下一步,除非人品有问题,否则一般不会有问题。
python 版本区别
目前 python 有两个大的版本,2.X 和 3.X。2.X 是遗产,3.X 是未来。除非特殊情况,新手建议学习 3.X。
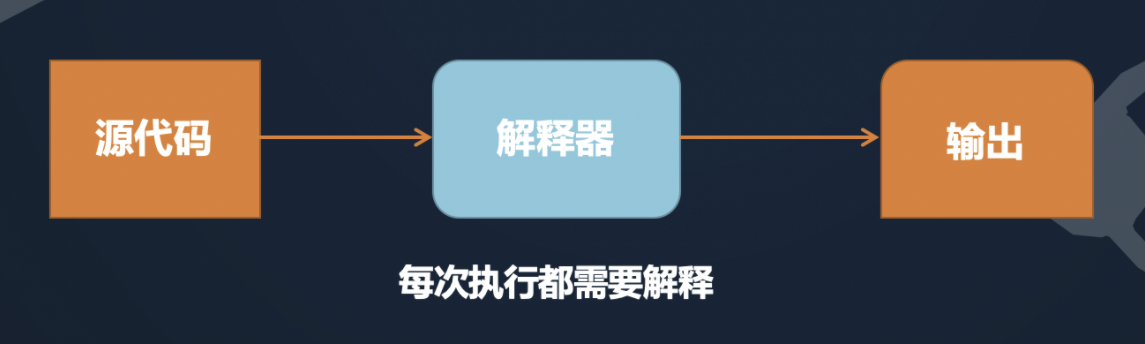
下载安装 python 解释器
访问 python 官网,下载解释器安装包。
注意按照操作系统下载对应版本。
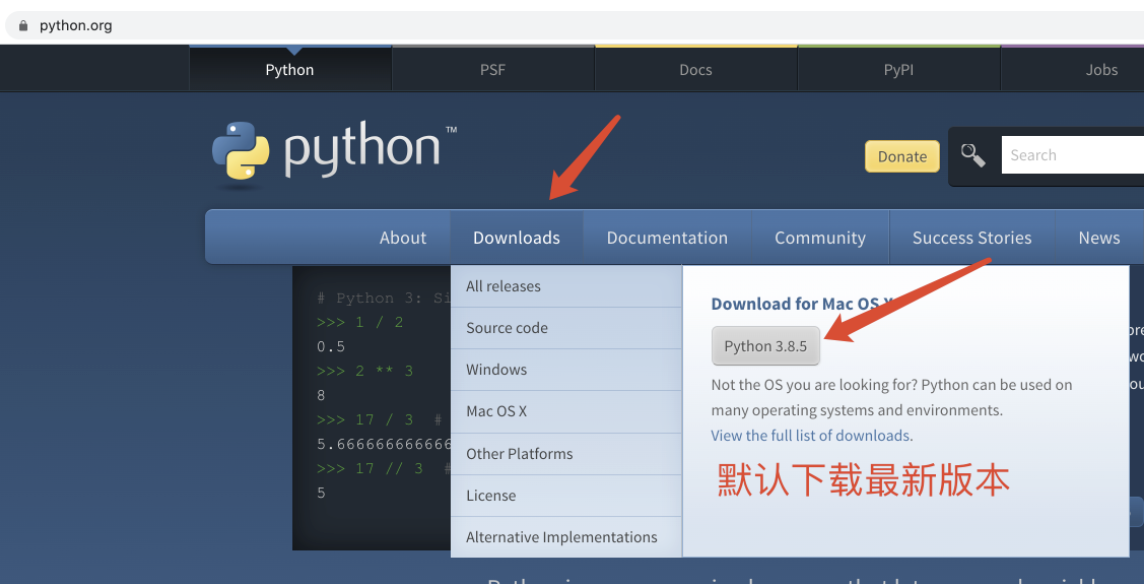
下载后双击安装文件会出现如下界面

记得勾选添加环境变量,然后就是下一步下一步,一般情况下都会正常安装成功。
2. cmd命令行工具
全黑的窗口,满屏的像瀑布一样流动的英文,这是电影中黑客出场的画面。
cmd 命令行工具就满足这个要求,在 windows 系统中,win 键 +R 键弹出运行窗口
不同版本,可能会有配色的不同,但功能一致。
其实这就是一个名字为 cmd.exe 的程序,感兴趣的同学可以在电脑中找下它的位置。
它有一个很重要的作用就是能够通过程序名自动调用对应的程序,而不需要去找到可执行文件双击执行。
例如,可以在命令行键入 notepad 回车,你会发现居然打开了记事本。
![]()
那是因为记事本这个程序的程序名就是 notepad.exe,机灵的小可爱就会联想 QQ 的程序名是 qq.exe 那么,那么在命令行中输入 QQ 是不是也可以打开 QQ 呢?
结果多半如下:

这是为什么呢? 其实 cmd 在接收到用户输入的命令后,会去电脑中搜索同名的程序或者批处理等文件,但是为了效率,它不会查找每个文件夹。
那它会去哪些文件夹中搜索呢?
3. 环境变量
环境变量其实是一系列常用程序所在路径的集合,记事本程序的路径存在默认的环境变量中所以可以通过命令行打开,QQ 程序的路径不在环境变量中,所以打不开。
windows 系统设置环境变量的步骤如下: 右键【我的电脑】-【属性】-【高级系统设置】-【环境变量】
⭐用户环境变量:对某个用户
系统变量:对整个系统
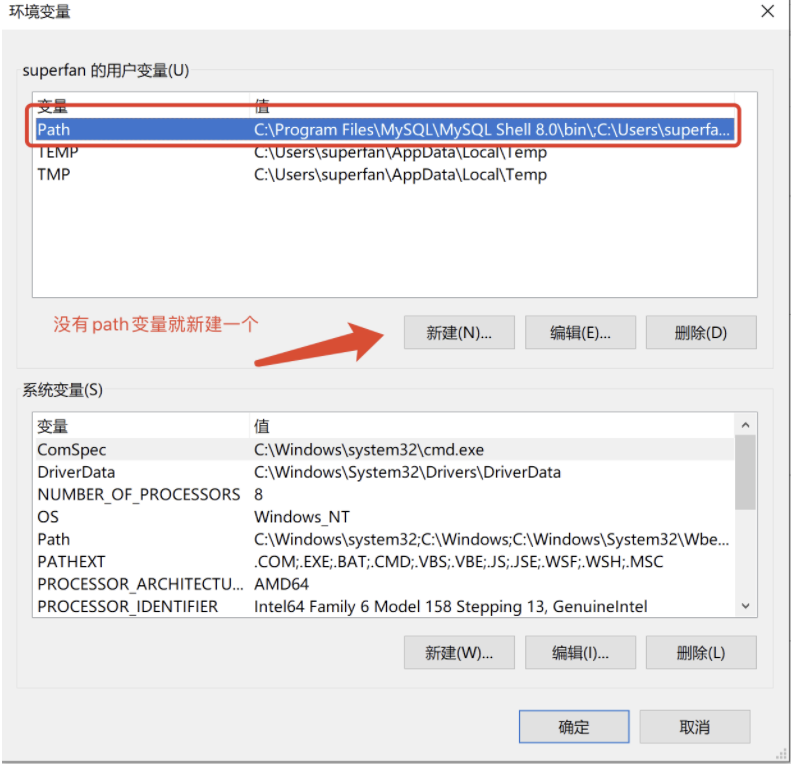
在用户变量中找到环境变量 path,如果没有就新建一个 path 变量。
点击编辑,将 QQ 程序路径添加到 path 中。
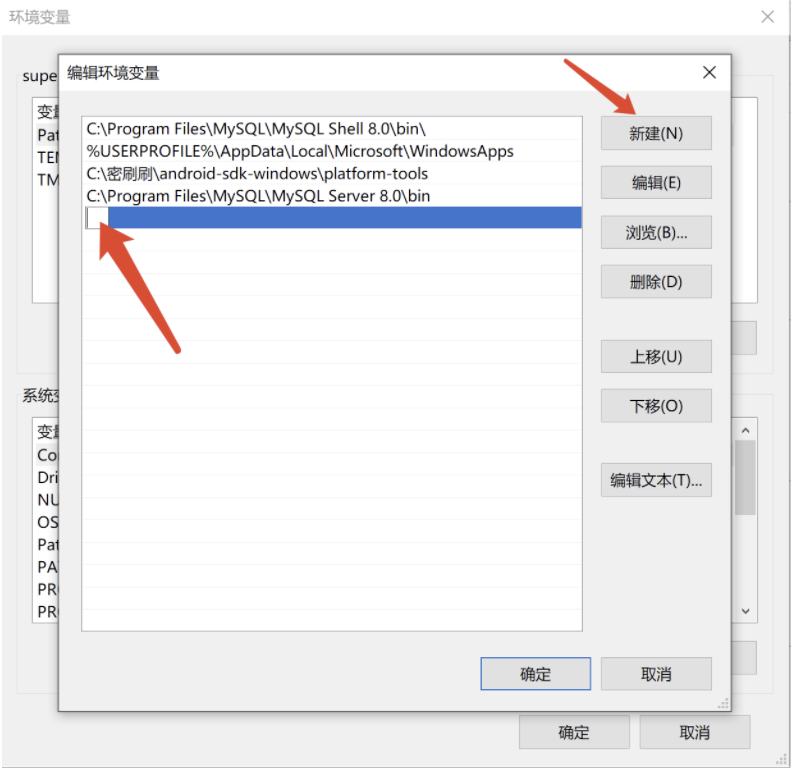
然后重新打开命令行工具应用新的环境变量,再次键入 QQ 你就可以打开 QQ 啦。
如果在安装 python 解释器的时候忘记勾选添加环境变量,也可以通过手动设置环境变量,然后在命令行中就可以运行 python 命令啦。
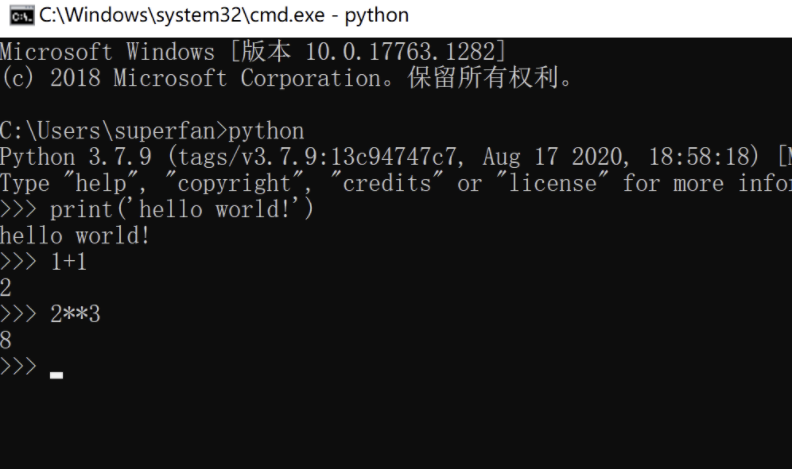
在命令行中键入 python 命令,出现如下窗口表示运行环境搭建成功。

⭐注意:path环境变量是按照顺序自上而下依次来找的,找到之后就会直接显示出对应的程序。
3⃣️ Python代码的编写和执行
python 代码的运行方式有两种:
1. 交互式
在命令行窗口输入命令
python
进入 python 解释器交互式客户端,在窗口中输入任意 python 代码,客户端窗口都会立即返回运行结果,当关闭客户端窗口后,代码不会保存。这种方式一般用来进行测试,不是正式的运行方式。
2. 脚本式
任意文本编辑工具都可以进行 python 代码的编写 ,在桌面新建一个文本文档,写入如下代码
print('hello world')
然后保存(尽量不要使用记事本直接编辑代码)。现在这个文本文档就是一个 python 的源代码文件,通常称为 python 脚本文件,通常我们会将 python 脚本文件的后缀改为 .py 。
python 代码本质上是通过 python 解释器解释成机器码后交由计算机执行的。
在命令行输入命令
python 脚本文件路径
就可以运行对应的脚本代码。

⭐可以运行.py文件,也可以不修改文件名后缀,直接运行

⭐可以用notepad命令运行,也可以用python命令运行

⭐在命令行运行太阳花:

3. 第一个python程序
3.1 集成开发环境
IDE:集成开发环境(软件) 加快开发效率
Pycharm 不包含解释器,运行代码时会找python解释器
虚拟环境会复制一个pythone不会改变原来安全好的pythone,但是占用内存比较大;
且运行代码时如果未选中,会运行不起来。

如果没有自动出现可以自行选择:

.idea文件是项目信息,不要去改动

⭐设置编码:两个地方

⭐Console就是设置python终端

⭐快捷键
1.复制:ctrl+D
2.跳到下一行:shift+enter
3.规范化:ctrl+alt+L
3.2 第一个python程序



4⃣️ Jupyter notebook
jupyter notebook 是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享文学化程序文档,支持实时代码,数学方程,可视化和 Markdown。
用来写学习笔记非常方便,所以推荐给大家。
1. 安装
安装好 python 解释器后,在命令行通过下面的 pip 命令安装 jupyter notebook
pip install jupyter notebook -i https://pypi.doubanio.com/simple
2. 开启 Jupyter notebook 服务
jupyter notebook 本质上是一个 Web 网站,打开 cmd 命令行,切换到你想存放 jupyter 文件的文件夹下,运行命令
jupyter notebook
如果环境搭建正确,它会自动打开默认浏览器,进入 Jupyter notebook 的编辑首页如下:
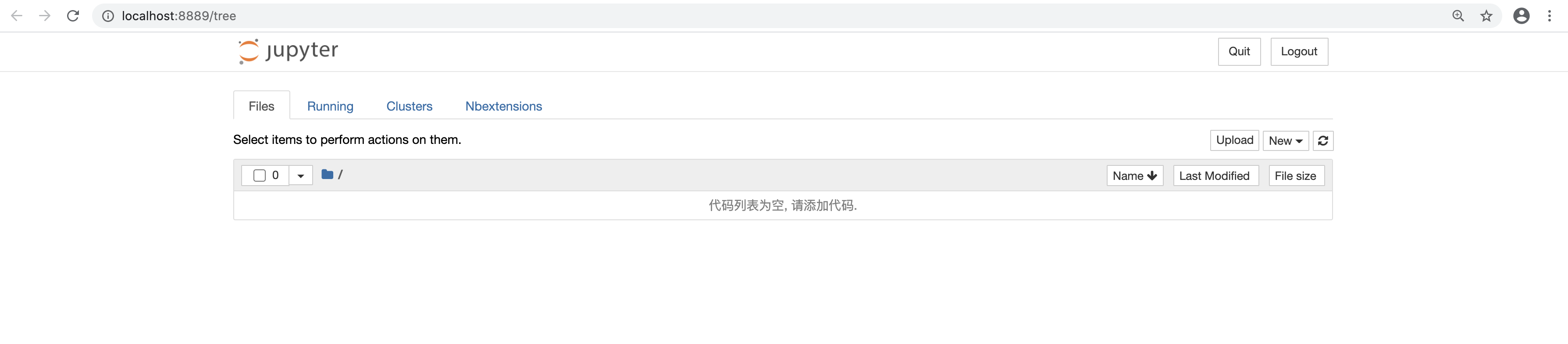
3. jupyter notebook 的使用
打开 Jupyter notebook 的服务后,可以在当前目录创建文件夹和笔记文件,笔记文件中可以写笔记也可以编写 python 代码,并且可以像在解释器中一样立即执行查看结果。
3.1 创建目录
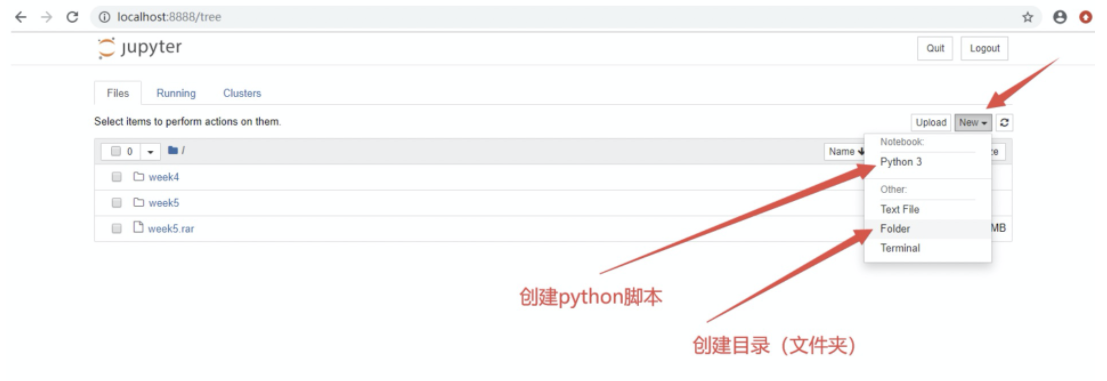

3.2 创建 python 脚本
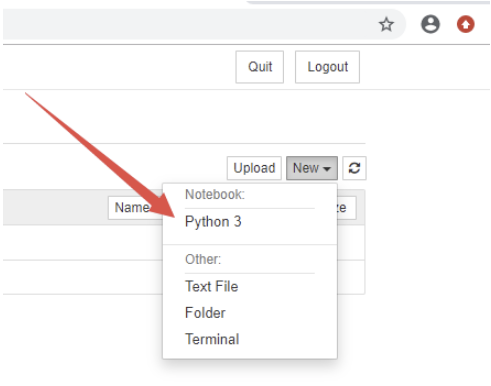
新建时选择 Python3,浏览器会打开一个新的页面如下
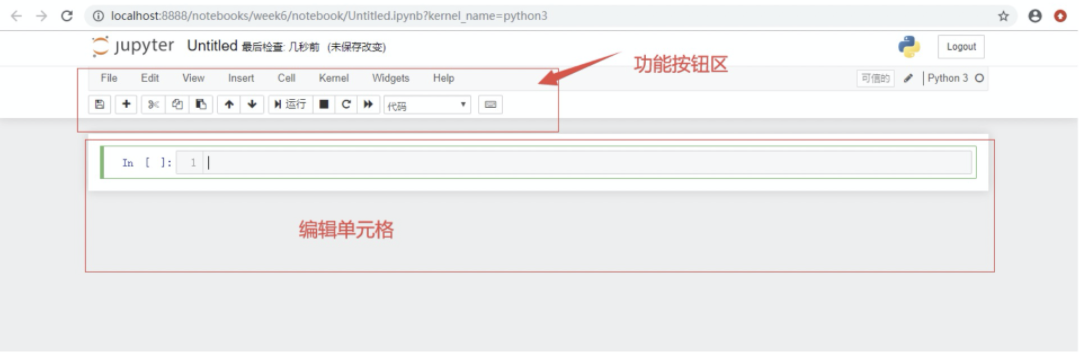
3.3 修改脚本名
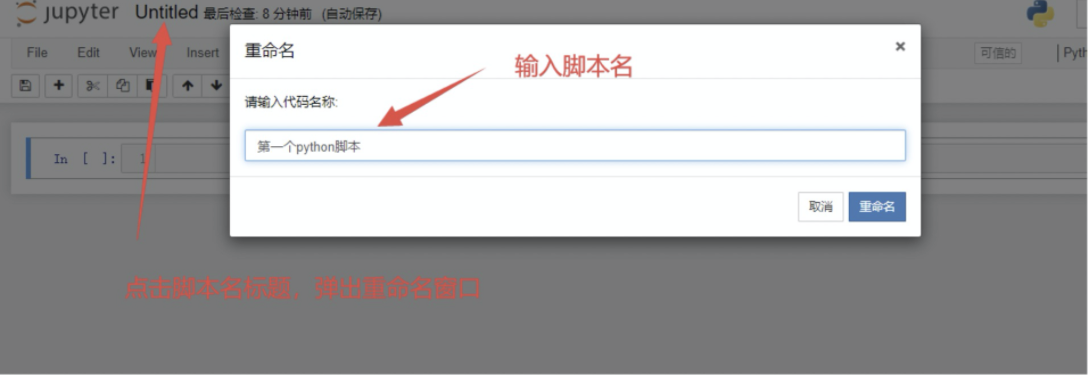
3.4 输入 python 代码
在单元格中直接键入代码
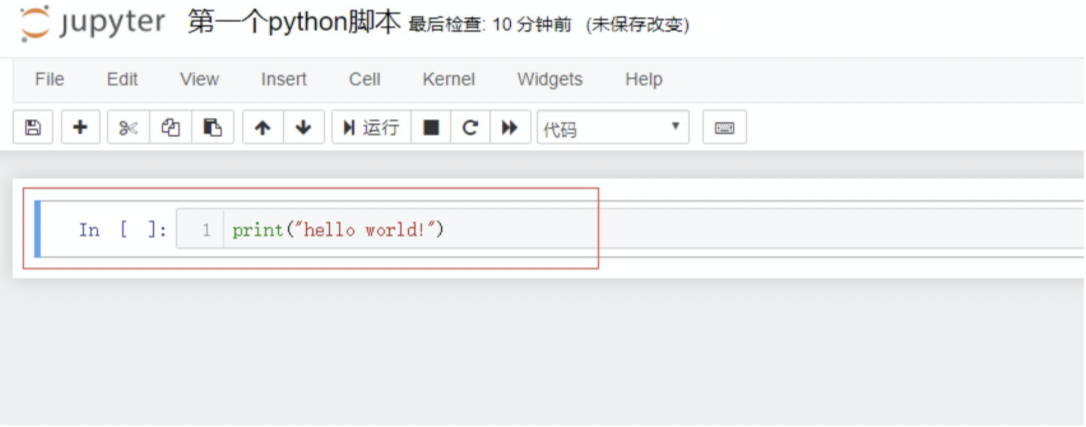
3.5 运行代码
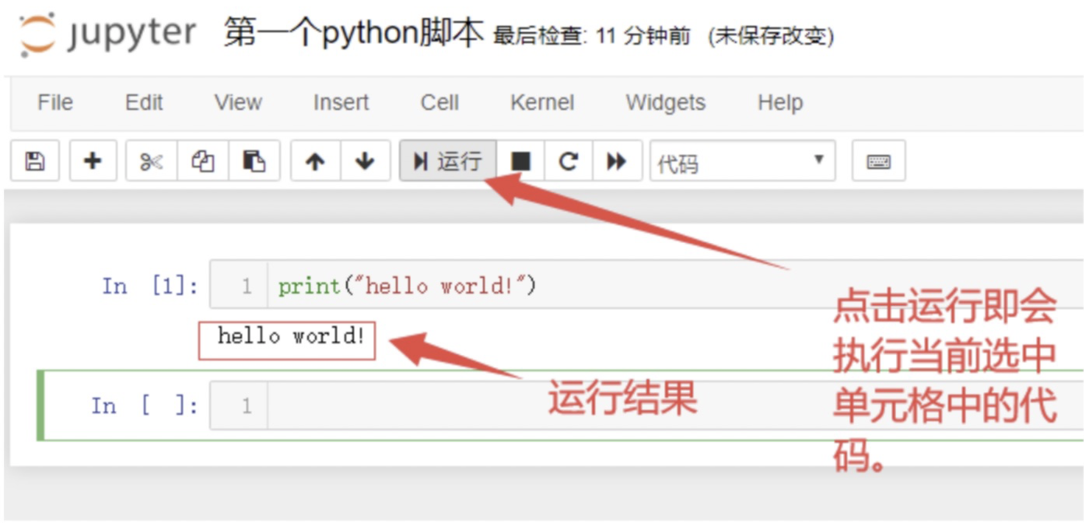
3.6 改变单元格模式
notebook 中既可以写代码,也可以写笔记,笔记的语法格式遵循 Markdown。每个单元格的默认格式是代码格式,可以切换为 标记,这是可以输入 Markdown 格式的文本,然后运行即可渲染出对应效果。
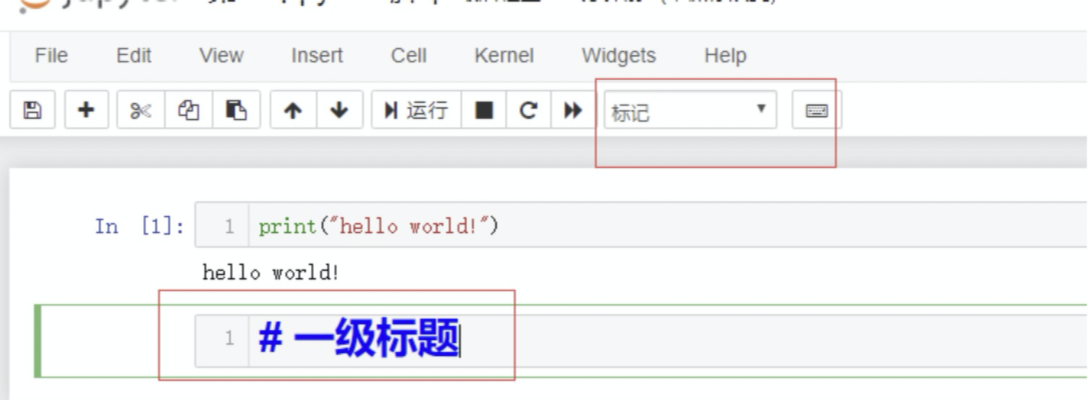
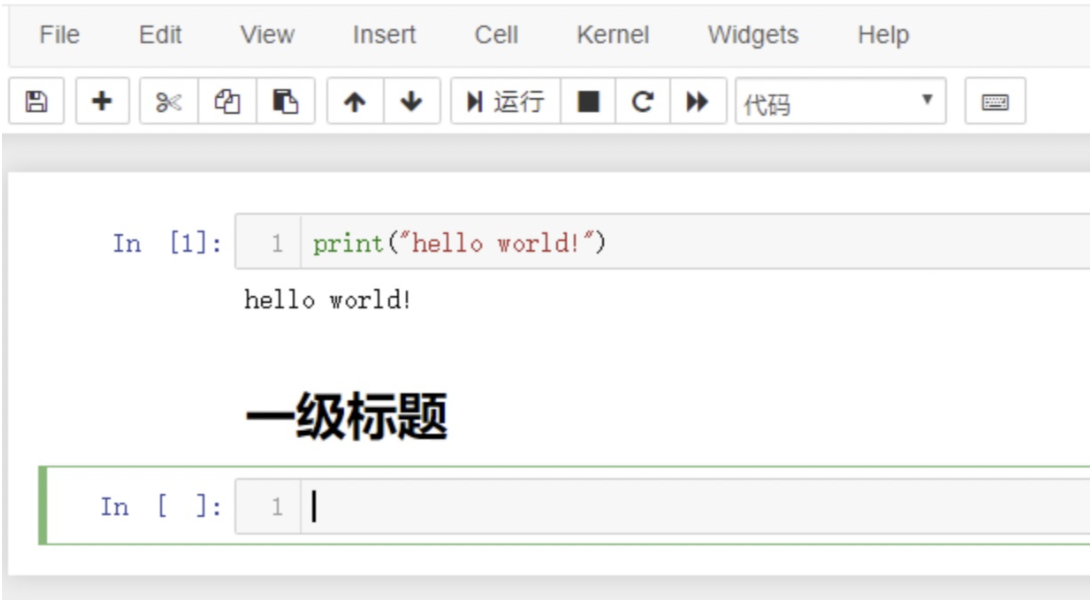
3.7 快捷方式
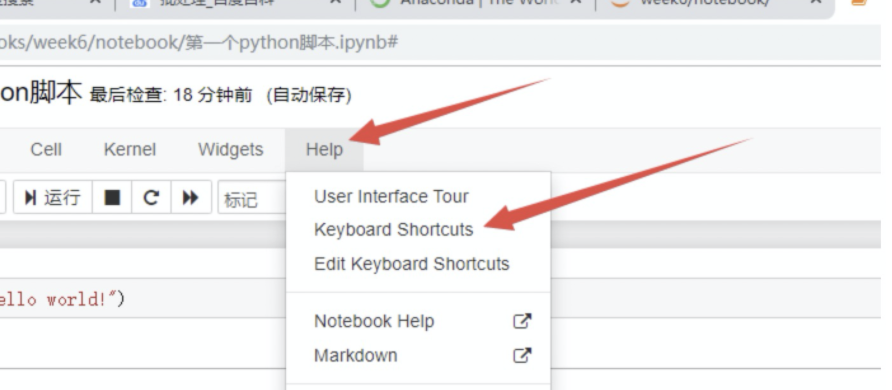
点击工具栏的 Help 按钮,再选中 Keyboard Shortcuts,就会弹出所有的快捷键说明
5⃣️ JupyterLab
JupyterLab 是下一代有界面的笔记本(notebook)。它的使用同 notebook,它界面更美观,功能更强大推荐使用它代替 jupyternotebook。
⭐注意:ie浏览器不支持jupyterlab
1. 安装
pip install jupyterlab -i https://pypi.doubanio.com/simple
查看pip版本:
![]()
2. 运行 JupyterLab 服务
⭐①在home下运行juypter {所在路径就是网站的根目录},打开家目录;
以.开头的隐藏文件不会显示

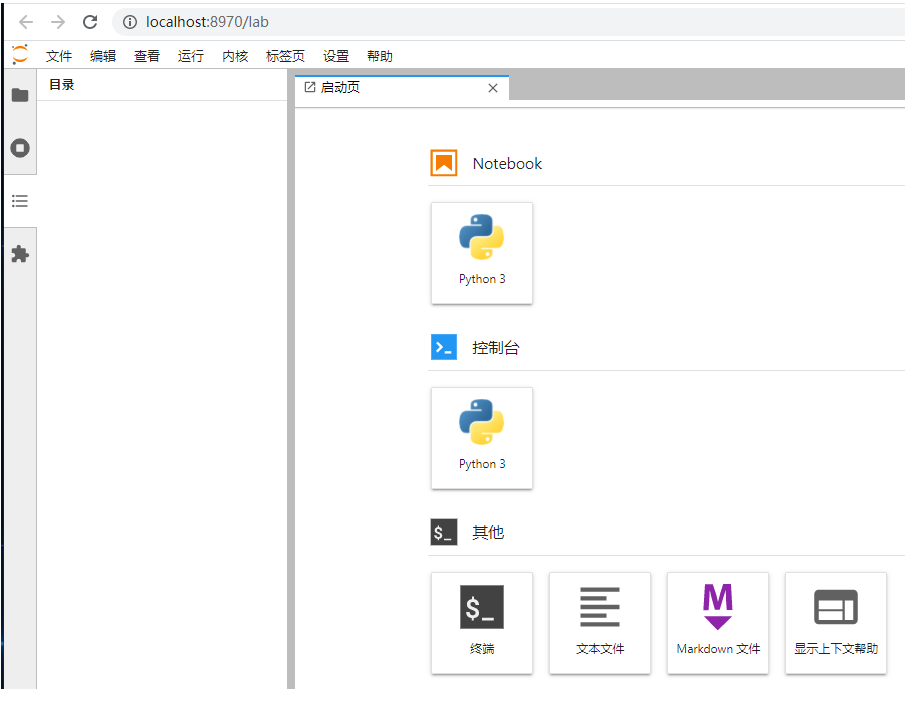
⭐②打开 cmd 命令行,切换到你想存放 jupyter 文件的文件夹下,运行命令
jupyter lab
如果环境搭建正确,它会自动打开默认浏览器,进入 JupyterLab 的编辑首页如下:
⭐③参数打开
![]()
⭐④在pycharm的终端打开

3. 安装中文插件
老版本需要下载安装包手动安装
下载 JupyterLab 的中文插件,地址如下
链接:https://pan.baidu.com/s/1wAJB0HiYsYcg8ZBnhQxIZw 提取码:uqpz
然后使用 pip 安装命令如下:
pip install 文件的路径\jupyterlab_language_pack_zh_CN-0.0.1.dev0-py2.py3-none-any.whl
新版本直接使用下面的命令安装:
pip install jupyterlab-language-pack-zh-CN
安装好后,重新打开 Jupyterlab,在设置,语言里会多一个中文选项,选择即可。

4. 其他使用
JupyterLab 对比 JupyterNotebook 除了界面功能更多外,更好看外,其他使用完全一致。且安装中文插件后,见名思意。
⭐①创建笔记本

⭐②重命名笔记本


⭐③运行代码
1.点击三角按钮

2.ctrl + enter
⭐④笔记模式
markdown语法

⭐⑤快捷方式
【帮助】 - 【启动经典Notebook】

【双击.ipynb文件】

【Help】 - 【Keyboard Shortcuts】

就可以查看到所有快捷方式 ->

⭐⑥快速进入文件夹下的方式:
1)cmd.exe窗口中使用Tab键补齐查找文件

2)进入要打开的文件,按住ctrl+shift,点击右键 - >在此处打开Powershell 窗口

再在打开的蓝色窗口种输入:jyputer lab

3)电脑上安装了GIT之后可以用Git Bash Here

⭐⑦如果开启服务器时浏览器没有自动打开jupyterlab,可以将链接复制到浏览器然后打开

6⃣️ Typora
1. 怎么把图片和文件一起移动
①文件 - 偏好设置

②把.md文件和.assets文件夹一起移动,assets文件夹里面存放的是.md文件用到的图片

Ⅱ 基本数据类型
第 2 章. 基本数据类型 (一)
⭐一个好用的测试网站:pythontutor.com/visualize.html#mode=display

思考,是上面的苹果堆好处理(运输,存储,加工)还是下面的有包装的苹果好处理?



1⃣️ Python语法规则
1. 代码结束


2. 注释


3. 代码层级
Python代码都要顶格写,不要随意的缩进和空格,除非有父子关系的代码【循环 |函数 |控制流if判断 |类】


4. 标识符

2⃣️ Python变量
1. 变量命名规范
在程序运行过程中会有一些中间值,在稍后的执行中会用到,这时可以将这些中间值赋值给变量,
然后在后面的代码中通过调用这些变量名来获取这些值。可以简单的理解为给这些值取一个别名,这个别名就代表这个值。
变量的命名规则:
-
由大小写字母 A-Z a-z,数字 0-9 和下划线
_组成 -
不能以数字开头
-
不能是关键字
-
变量名大小写敏感
-
字母和数字之间可以用下划线隔开 以便阅读
-
见名知意

# 正确的案例 lucky_num = 88 lucky_num2 = 888 # 错误的案例 年龄 = 18 # 错误示范,不要使用其他的字符创建变量名,切记 1lucky_num = 88 # 错误示范,会语法报错

# 上面的age 和 Age是两个不同的变量 Age = 19
python 官方占用了一些变量名作为程序的关键字,总共 35 个,这些关键字不能作为自定义变量名使用。

2. 变量名定义与引用


3⃣️ 什么是数据类型
编程语言通过一些复杂的计算机物理底层机制,创造不同类型的数据,用来表示现实世界中的不同信息,以便于计算机更好的存储和计算。
每种编程语言都会有一些基本的数据类型用来表示现实世界中的常见信息。
⭐基本数据类型:python预先定义的类型
自定义类型:面向对象时自封装的类型
Python 中的常见数据类型如下:
数值类型
| 名称 | 描述 |
|---|---|
| int(整数) | 数学概念中的整数 |
| float(浮点数) | 数学概念中的实数 |
| complex(复数) | 数学概念中的复数 |
⭐编写表格的原生方法:

语法说明:

序列类型
| 名称 | 描述 |
|---|---|
| str(字符串) | 字符串是字符的序列表示,用来表示文本信息 |
| list(列表) | 列表用来表示有序的可变元素集合。例如表示一个有序的数据组。 |
| tuple(元组) | 元组用来表示有序的不可变元素集合。 |
散列类型
| 名称 | 描述 |
|---|---|
| set(集合) | 数学概念中的集合,无限不重复元素的集合 |
| dict(字典) | 字典是无序键值对的集合。用来表示有关联的数据,例如表示一个人的基本信息。 |
其他类型
| 名称 | 描述 |
|---|---|
| bool(布尔型) | bool 型数据只有两个元素,True 表示真,False 表示假。用来表示条件判断结果。 |
| None | None 表示空。 |
4⃣️ 数值类型

1. 整数类型(int)
python 中整数类型用 int 表示,与数学中的整数概念一致
age = 18
其中 age 是变量名,= 是赋值运算符,18 是值。
上面的代码表示创建一个整数 18 然后赋值给变量 age。
1.1 赋值运算符
在 python 中 = 是赋值运算符,而不是数学意义上的等于号。
<span style="color:red">python 解释器会先计算 = 右边的表达式,然后将结果赋值给 = 左边的变量。</span>
res = 1 # 定义变量res赋值为1 res = res + 1 # 先计算res + 1 再赋值给变量res res # res的值为2
运行结果:
2
1.2 type 函数和 isinstance 函数和print 函数
❀python 提供了内建函数 type 用来查看值或者变量的类型。
只需要将变量或者值作为参数传入 type 函数即可。
type(age) # 返回对象的类
运行结果:
int
type(18) # ①输出值的类型 交互式输出
运行结果:
int
❀isinstance 是Python的一个内置函数,用来判断一个函数是否是一个已知的类型。
isinstance(object,classinfo)




❀print 函数用来在屏幕上输出传入的数据的字符串表现形式,是代码调试最重要的函数。
![]()
print(age) print(type(age)) # ②打印值的字符串表现形式 print函数输出
运行结果:
18
<class 'int'>

❀print 函数和交互式输出的其他区别

1.3 整数的常见表示形式
在 python 中整数最常见的是 10 进制整数,也有二进制,八进制和十六进制。
a = 10 # 十进制
print('a的类型为:', type(a), a)
a 的类型为: <class 'int'> 10
b = 0b1110 # 二进制 0b,0B前导符,print的时候会转换为10进制
print('b的类型为:', type(b),b)
b 的类型为: <class 'int'> 14
c = 0o57 # 八进制
print('c的类型为:', type(c),c)
c 的类型为: <class 'int'> 47
d = 0xa5c # 十六进制
print('d的类型为:', type(d), d)
d 的类型为: <class 'int'> 2652
⭐注意:python中没有四进制:

1.4 整数的取值范围
python 中整数类型的理论取值范围是[-无穷,无穷],实际取值范围受限于运行 python 程序的计算机内存大小。

2. 浮点数类型(float)
python 中浮点数用 float 表示,与数学中的实数概念一致,也可以理解为有理数。
a = 0.0
print('a的类型为:', type(a))
a 的类型为: <class 'float'>
2.1 浮点数的表现形式
在 python 中浮点数可以表示为 a.b 的格式,也可以表示为小写e或大写 E 的科学计算法。例如:
a = 0.0
print('a的类型为:', type(a))
a 的类型为: <class 'float'>
# 小数部分为零可以被省略
b = 76.
print('b的类型为:', type(b))
b 的类型为: <class 'float'>
c = -3.1415926
print('c的类型为:', type(c))
c 的类型为: <class 'float'>
d = 9.5e-2
print('d的类型为:', type(d))
d 的类型为: <class 'float'>
思考:
浮点数可以表示所有的整数数值,python 为何要同时提供两种数据类型?
整数是最好存储,最好处理的数据。计算机底层就是二进制数。 相同的操作整数要比浮点数快5-20倍
2.2 数学运算符
与数学中的常用运算符一致
| 运算符 | 描述 |
|---|---|
+ | 加法运算符 1+1 |
- | 减法运算符 3-2 |
* | 乘法运算符 9*9 |
/ | 除法运算符 9/3,除法运算后的结果一定为 float 类型 |
// | 整除运算符 10/3,也称为 地板除 向下取整 |
% | 取模运算符 10%3,表示 10 除以 3 取余数 |
** | 幂次运算符 2**3,表示 2 的 3 次幂 |
() | 括号运算符,括号内的表达式先运算 (1+2)* 3 |


注意:一个浮点数和一个整数进行运算后的结果一定为浮点数
2+1.0
3.0
9/3 # 除法运算的结果一定为float
3.0
9//2 # 地板除,向下取整,如果符号两边都是整数,结果才是整数
4

⭐ 除和整除的区别:

2.3 组合赋值运算符
赋值运算符与算术运算符可以组合使用,注意算术运算符要写在前面且中间不能有空格。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 等于-简单的赋值 | c = a + b print(c) # 30 |
| += | 加等于 | c += a 等同于 c = c + a |
| -= | 减等于 | c -= a 等同于 c = c - a |
| *= | 乘等于 | c *= a 等同于 c = c * a |
| /= | 除等于 | c /= a 等同于 c = c/a |
| %= | 取余等于 | c%=a 等同于 c = c%a |
| **= | 幂等于 | c ** =a 等同于 c = c ** a |
| //= | 取整除等于 | c//=a 等同于 c = c//a |
体现了程序员的"懒惰",这种懒惰大力提倡,使得代码简洁和高效。
a = 1 a += 2 # a = a+2 a
3
2.4 浮点数的不精确性
整数和浮点数在计算机中的表示不同,python 提供无限制且准确的整数计算,浮点数却是不精确的,例如:
0.2+0.1
0.30000000000000004
根据 sys.float_info.dig 的值,计算机只能提供 15 个数字的准确性。浮点数在超过 15 位数字计算中产生的误差与计算机内部采用二进制运算有关。
import sys print(sys.float_info.dig)
15
思考:
3.141592653589*1.23456789 的计算怎么准确
拓展:高精度浮点运算类型
import decimal
a = decimal.Decimal('3.141592653589')
b = decimal.Decimal('1.23456789')
print(a * b)
3.87850941358087265721
⭐因为整数计算是无限制且精准的,所以可以先转换成整数计算,再移动小数点

2.5 浮点数和整数的相互转化
int,float 是 python 的内置函数,通过它们可以对浮点数类型和整数类型相互转化
a = 1.9 # 转化为整数 # 通过调用int函数,提取浮点数的整数部分 b = int(a) print(b, type(b))
1 <class 'int'>
c = 2 # 转化为浮点数 # 通过调用float函数,将整数转化为小数部分为0的浮点数 d = float(c) print(d, type(d))
2.0 <class 'float'>
⭐布尔型 转为 整型/浮点型
print('True转为整数后,结果为:',int(True), type(int(True)))
print('True转为浮点数后,结果为:',float(True), type(float(True)))
True转为整数后,结果为:1 <class 'int'>
True转为浮点数后,结果为:1.0 <class 'float'>
3. 复数(complex)
科学计算中的复数。

a = 12.3+4j
print('a的类型为:', type(a))
# 运行结果:a的类型为: <class 'complex'>
print(a.real) # 实部
print(a.imag) # 虚部
a 的类型为: <class 'complex'>
12.3
4.0
⭐复数用来解决负整数的平方根

4. 布尔型(bool)
条件表达式的运算结果返回布尔型(bool),布尔型数据只有两个,True 和 False 表示 真 和 假。
True
True

False # 注意首字母大写
False
1.1 比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于-比较对象的值是否相等 | print(a==b) # False |
| is | 等于-比较对象的内存地址是否相同 | print(a is b) |
| != | 不等于 | print(a!=b) # True |
| > | 大于 | print(a>b) # False |
| < | 小于 | print(a<b) # True |
| >= | 大于等于 | print(a>=b) # False |
| <= | 小于等于 | print(a<=b) # True |
比较运算符运算后的结果是布尔型
python3不支持<>
a = 1 b = 2 a == b
False
a = 300 b = 300 a is b
False
a == b
True


1.2 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则 False | L = [1, 2, 3, 4, 5] a = 3 print(a in L) # True |
| not in | 如果在指定的序列中没有找到值返回 True,否则 False | print(a not in L) # False |
ls = [1,2,3,4,5] 1 in ls
True
s = ['abcdefg'] # 列表s里面只有一个元素 'a' in s
False

t = (1,2,3) 4 in t
False
#字典成员运算符默认检查的是key
#字典检索key很快
d = {'name': 'Felix','age':18}
'name' in d
True
st = {1,2,3}
1 in st
True
⭐
num = 1234 # 数字不能用于包含与被包含的判断 print(1 in num)
⭐
bol = True # bol值也不能用于这个计算 print("T" in bol)
1.3 布尔型运算
布尔型数据可以和数值类型数据进行数学计算,这时 True 表示整数1, False 表示整数 0
布尔型是整型的子类。加减乘除都可以算
True + 1
2
False + 1
1
1.4 布尔类型转换
任意数据都可以通过函数 bool 转换成布尔型。
在 python 中,None, 0(整数),0.0(浮点数),0.0+0.0j(复数),""(空字符串),空列表,空元组,空字典,空集合的布尔值都为 False,其他数值为 True
print(bool(0))
print(bool(0.0))
print(bool(0.0+0.0j))
print(bool(''))
print(bool([]))
print(bool(()))
print(bool({}))
print(bool(set()))
print(bool(None))
False
False
False
False
False
False
False
False
False
1.5 逻辑运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 与,如果 x 为 False,x and y 返回 x 的值,否则返回 y 的值 | print(a and b) # True |
| or | 或,如果 x 为 True,x and y 返回 x 的值,否则返回 y 的值 | print(a or b) # True |
| not | 非,如果 x 为 True,返回 False,反之,返回 True | print(not a) # False |
逻辑运算符两边的表达式不是布尔型时,在运算前会转换为布尔型。
True and True
True
True and False
False
0 and 1 # 短路
0
1 and 2 # and左边为True时,则由右边的值来决定整个表达式的值
2
True or False
True
False or False
False
1 or 0 # 短路
1
0 or '' #or左边为False时,则由右边的值来决定整个表达式的值
''
not 运算符返回的永远是True或者False


⭐运算符的优先级:



第 3 章. 基本数据类型 (二)
5️⃣ 序列类型
序列类型用来表示有序的元素集合。
1. 字符串

python 中字符串用 str 表示,字符串是使用成对的单引号,双引号,三引号包裹起来的字符的序列,用来表示文本信息。
1.1 字符串的定义
a = 'a'
b = "bc"
c = """hello,world"""
d = '''hello,d'''
e = """
hello,
world!
"""
print('a的类型为:', type(a)) # a的类型为: <class 'str'>
print('b的类型为:', type(b)) # b的类型为: <class 'str'>
print('c的类型为:', type(c)) # c的类型为: <class 'str'>
print('d的类型为:', type(d)) # d的类型为: <class 'str'>
print('e的类型为:', type(e)) # e的类型为: <class 'str'>
使用单引号和双引号进行字符串定义没有任何区别,当要表示字符串的单引号时(可使用转义),也可用双引号进行定义字符串,反之亦然。
一对单引号或双引号只能创建单行字符串,三引号可以创建多行表示的字符串。三双引号一般用来做多行注释,表示函数,类定义时的说明。三单引号一般用来定义一个变量。
print('最近我看了"平凡的世界"') # 最近我看了"平凡的世界"
print("最近我看了'平凡的世界'") # 最近我看了'平凡的世界'
⭐三引号创建多行表示的字符串

定义空字符串
a = '' print(a)
⭐字符串另一写法:

1.2 字符串的索引
任何序列类型中的元素都有 索引 用来表示它在序列中的位置。
字符串是字符的序列表示,单个字符在字符串中的位置使用 索引 来表示,也叫下标。
索引使用整数来表示。
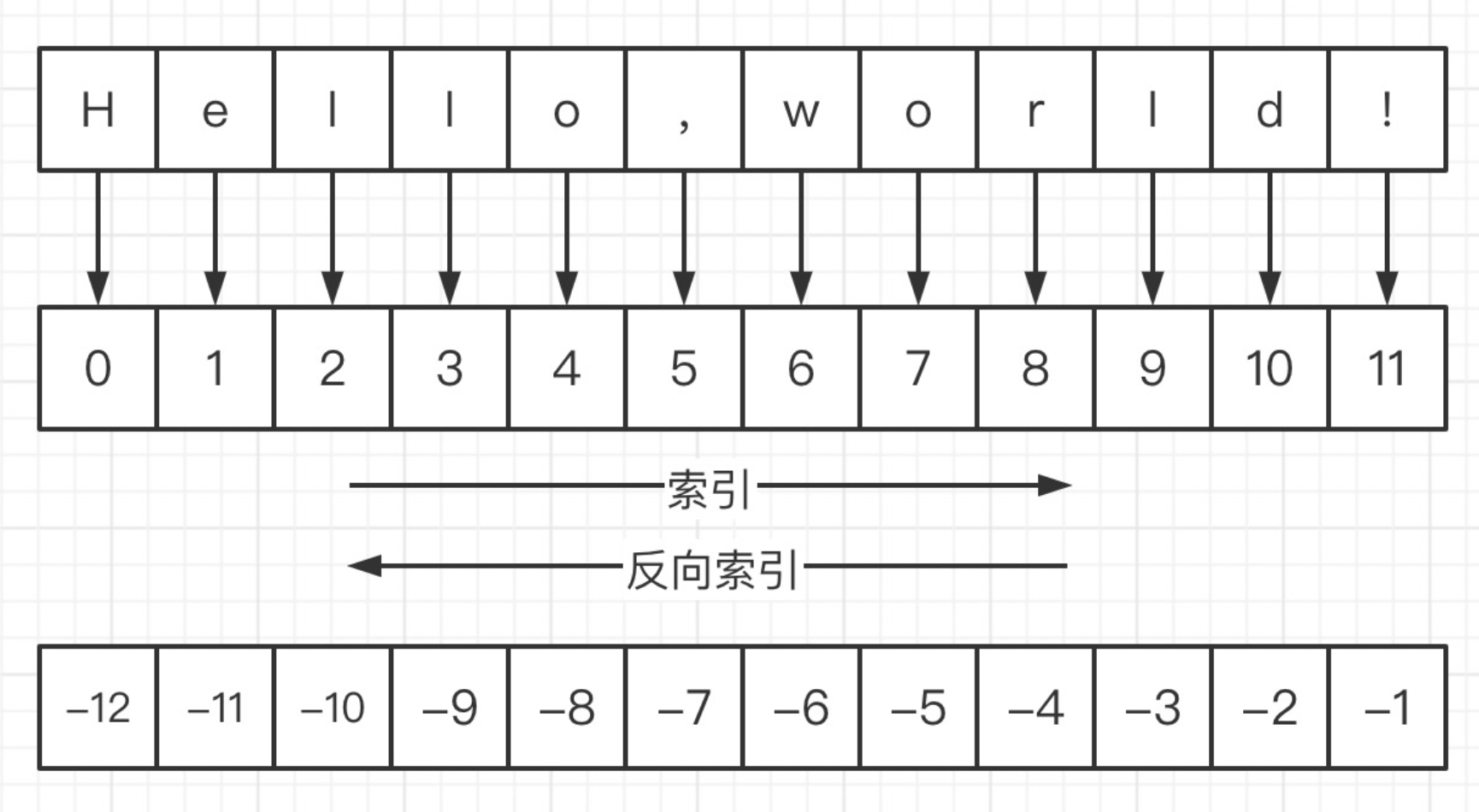
通过 索引 可以获取字符串中的单个字符
索引即偏移量,表示元素距离序列头部偏移位置的个数
语法如下:
str[index] s = 'hello world!' print(s[0]) print(s[-1])
h
!
注意字符串索引从 0 开始
1.3 字符串的切片
⭐ 字符串可以当作一个列表用
获取序列中的子序列叫切片。
字符串的切片就是获取字符串的子串。
字符串切片的语法如下:
str[start:end:step]
start 表示起始索引,end 表示结束索引,step 表示步长。
str[m:n:t] 表示从字符串索引为 m 到 n 之间不包含 n 每隔 t 个字符进行切片。
当 step 为 1 的时候可以省略。
特别的,当 step 为负数时,表示反向切片。
s = '0123456789' print(s[1:5]) # 包头不包尾
1234
print(s[:5]) # 从头开始切可以省略start
01234
print(s[1:]) # 切到末尾省略end
123456789
print(s[1::2]) # 步长为2进行切片
13579
❀从1开始切,每两个里面取第一个 13579
# 无论正向还是反向切片,索引是独立的[hello,world],无论正反,,的索引都是5 # (按步长分组后取每个组的第一个字符,负切片反向为头) print(s[1::-2]) # 步长为负数反向切片 # 1
思考
获取一个字符串的逆串,例如 'abc' 的逆串是 'cba'。
1.4 字符串拼接
python 中可以通过 + 拼接两个字符串
a = 'hello' b = ' ' c = 'world!' print(a+b+c)
hello world!
字符串和整数进行乘法运算-表示重复拼接这个字符串
print('*' * 10)
1.5 字符串常用方法
通过内建函数 dir 可以返回传入其中的对象的所有方法名列表。

str.capitalize()
返回原字符串的副本,其首个字符大写,其余为小写。

str.endswith(suffix[, start[, end]])
如果字符串以指定的 suffix 结束返回 True,否则返回 False。 suffix 也可以为由多个供查找的后缀构成的元组。 如果有可选项 start,将从所指定位置开始检查。 如果有可选项 end,将在所指定位置停止比较。
⭐判断变量name是否以al结尾
print(name[-2:]) == 'al'
print(name.endswith("al"))
str.startswith(prefix[, start[, end]])
如果字符串以指定的 prefix 开始则返回 True,否则返回 False。 prefix 也可以为由多个供查找的前缀构成的元组。 如果有可选项 start,将从所指定位置开始检查。 如果有可选项 end,将在所指定位置停止比较。
⭐判断变量name是否以al开头
print(name[:2]) == 'al'
print(name.startswith("al"))
str.isalnum()
如果字符串中的所有字符都是字母或数字且至少有一个字符,则返回 True , 否则返回 False 。 如果 c.isalpha() , c.isdecimal() , c.isdigit() ,或 c.isnumeric() 之中有一个返回 True ,则字符c是字母或数字。
str.isdigit()
如果字符串中的所有字符都是数字,并且至少有一个字符,返回 True ,否则返回 False 。 数字包括十进制字符和需要特殊处理的数字,如兼容性上标数字。这包括了不能用来组成 10 进制数的数字,如 Kharosthi 数。 严格地讲,数字是指属性值为 Numeric_Type=Digit 或 Numeric_Type=Decimal 的字符。
str.islower()
如果字符串中至少有一个区分大小写的字符且此类字符均为小写则返回 True ,否则返回 False 。
str.isupper()
如果字符串中至少有一个区分大小写的字符 4 且此类字符均为大写则返回 True ,否则返回 False 。
>>> 'BANANA'.isupper() True >>> 'banana'.isupper() False >>> 'baNana'.isupper() False >>> ' '.isupper() False
str.upper()
返回原字符串的副本,其中所有区分大小写的字符 4 均转换为大写。 请注意如果 s 包含不区分大小写的字符或者如果结果字符的 Unicode 类别不是 "Lu" (Letter, uppercase) 而是 "Lt" (Letter, titlecase) 则 s.upper().isupper() 有可能为 False。
所用转换大写算法的描述请参见 Unicode 标准的 3.13 节。
str.isspace()
如果字符串中只有空白字符且至少有一个字符则返回 True ,否则返回 False 。
空白 字符是指在 Unicode 字符数据库 (参见 unicodedata) 中主要类别为 Zs ("Separator, space") 或所属双向类为 WS, B 或 S 的字符。
str.lower()
返回原字符串的副本,其所有区分大小写的字符 4 均转换为小写。
所用转换小写算法的描述请参见 Unicode 标准的 3.13 节。
str.replace(old, new[, count])
返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。 如果给出了可选参数 count,则只替换前 count 次出现。
- count默认是-1,替换全部

str.strip([chars])
返回原字符串的副本,移除其中的前导和末尾字符。 chars 参数为指定要移除字符的字符串。 如果省略或为 None,则 chars 参数默认移除空白符。 实际上 chars 参数并非指定单个前缀或后缀;而是会移除参数值的所有组合:
>>> ' spacious '.strip()
'spacious'
>>> 'www.example.com'.strip('cmowz.')
'example'
最外侧的前导和末尾 chars 参数值将从字符串中移除。 开头端的字符的移除将在遇到一个未包含于 chars 所指定字符集的字符时停止。 类似的操作也将在结尾端发生。 例如:
>>> comment_string = '#....... Section 3.2.1 Issue #32 .......'
>>> comment_string.strip('.#! ')
'Section 3.2.1 Issue #32'

⭐输入字符串(列表)对应的前两个字符/后三个字符
print(li[-2:]) print(li[:3])
通过内建函数 help 可以返回传入函数的帮助信息。

str.find([chars])
每个编程语言都有其内在的编程范式,体现着编程语言设计者的哲学。编程语言发展史上有许多杰出的人物。下面是一些例子:
# -*- coding: UTF-8 -*-
programmers = [
"约翰·巴科斯(JohnWarnerBackus), 创建了Fortran语言",
"阿兰·库珀(Alan Cooper), 开发了Visual Basic语言",
"詹姆斯·高斯林(James Gosling), 开发了Java语言",
"安德斯·海尔斯伯格(Anders Hejlsberg), 开发了Turbo Pascal、Delphi、C#以及TypeScript",
"丹尼斯·里奇(Dennis MacAlistair Ritchie), 发明了C语言",
"比雅尼·斯特劳斯特鲁普(Bjarne Stroustrup), 他以创造C++编程语言而闻名,被称为“C++之父”",
"吉多·范罗苏姆(Guido van Rossum), 创造了 Python"
]为了进一步对上述文本数据解析,获得如下格式的结构化信息:
# -*- coding: UTF-8 -*-
[
{"name_cn": "约翰·巴科斯", "name_en": "JohnWarnerBackus", "achievement": "创建了Fortran语言"},
{"name_cn": "阿兰·库珀", "name_en": "Alan Cooper", "achievement": "开发了Visual Basic语言"},
...
]我们先分析一个例子,解析这个文本数据:"吉多·范罗苏姆(Guido van Rossum), 创造了 Python"。
- 首先,定义一个函数
parse_parts,通过第一个逗号,拆分出发明家的名字信息和成就信息。 - 其次,定义一个函数
parse_name,通过对name的进一步拆分,获得发明家的中英文名字信息。 - 最后,定义一个函数
parse_creators,完成解析。
完整的代码模版如下:
# -*- coding: UTF-8 -*-
def parse_parts(creator):
index = creator.find(',')
name, achievement = creator[0:index], creator[index+1:]
return name.strip(), achievement.strip()
def parse_name(name):
index = name.find('(')
name_cn, name_en = name[0:index], name[index:]
name_en = name_en[1:len(name_en)-1]
return name_cn, name_en
def parse_creators(creators):
# TODO(YOU): 请在此处正确实现
if __name__ == '__main__':
creators = ...
profiles = parse_creators(creators)
print(profiles)请找出以下对函数parse_creators的实现中,

1.6 字符串和数值的相互转化
1 和 '1' 不同,1.2 和 '1.2' 也不相同,但是它们可以相互转化
# 整数和字符串之间的转化
# 整数字符串,10进制的整数字符串
int('1') # 1
⭐int不能转化非十进制的整数字符串

str(1)
'1'
⭐使用base=0,将二进制、八进制、十六进制的整数字符串转化为整数

# 浮点数和字符串之间的转化
float('1.2')
1.2
str(1.2)
'1.2'
# 尝试 int('1.2')看看结果会是什么
int('1.2') #报错,int只能将整数字符串转换为整数,必须是十进制数
# 布尔值和字符串之间的转化
print('True转为字符串后,结果为:',str(True),'类型为:',type(str(True)))
# 字符串转为bool值
print('""转为布尔值后,结果为:',bool(""),'类型为:',type(bool("")))
True转为字符串后,结果为:True 类型为:<class 'str'>
""转为布尔值后,结果为:False 类型为:<class 'bool'>
⭐非零值为True,0为False
1.7 转义符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。常用转义字符如下表:
| (在行尾时) | 续行符 |
|---|---|
\\ | 反斜杠符号 |
\' | 单引号 |
\" | 双引号 |
| \a | 响铃 |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
print('窗前明月光,\n疑是地上霜。') # 输出换行
窗前明月光,
疑是地上霜。
print('对\\错') # 输出反斜杠本身
对\错
⭐\

print('\'') # 输出单引号本身
'
⭐\r

⭐\a

在定义字符串的时候,有时需要强制不转义
在字符串前面加上r这个引导符,字符串会原样输出,raw
⭐双反斜杠即输出反斜杠自身
![]()
⭐加r / R,或者斜杠(\)可以原样输出,而不会再输出许多个换行
1.8 字符串格式化


在实际工作中经常需要动态输出字符。
例如,我们通过程序计算计算机的内存利用率,然后输出
10:15 计算机的内存利用率为30%
其中下划线内容会动态调整,需要根据程序执行结果进行填充,最终形成上述格式的字符串输出。
python 支持三种形式的字符串格式化
①% 字符串格式化
语法格式如下:
%[(name)][flags][width][.precision]typecode
-
(name)可选,用于选择指定的key -
flags可选,可供选择的值有,注意只有在和数值类型的typecode配合才起作用-
+, 右对齐,正数前加正号,负数前加负号 -
-, 左对齐,正数前无符号,负数前加负号 -
空格, 右对齐,正数前加空格,负数前加负号 -
0, 右对齐,正数前无符号,负数前加负号;用0填充空白处
-
-
width,可选,字符串输出宽度 -
.precision可选,小数点后保留位数,注意只有在和数值类型的typecode配合才起作用 -
typecode 必选-
s,获取传入对象的字符串形式,并将其格式化到指定位置 -
r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置 -
c,整数:将数字转换成其 unicode 对应的值,10 进制范围为 0 <= i <= 1114111(py27 则只支持 0-255);字符:将字符添加到指定位置 -
o,将整数转换成 八 进制表示,并将其格式化到指定位置 -
x,将整数转换成十六进制表示,并将其格式化到指定位置 -
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置 -
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写 e) -
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写 E) -
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后 6 位) -
F,同上 -
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过 6 位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 e;)` -
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过 6 位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 E;)` -
%,当字符串中存在格式化标志时,需要用 %% 表示一个百分号
-
⭐写法1:%typecode
res = '%s计算机的内存利用率为%s%%' % ('11:15', 75)
print(res)
# '%s'作为槽位和 % 号后提供的值按顺序一一对应
11:15 计算机的内存利用率为 75%
⭐写法2:%[(name)]typecode
res = '%(time)s计算机的内存利用率为%(percent)s%%' % {'time':'11:15', 'percent': 75}
# % 后是字典时,可以通过name指定key对应的值
print(res)
11:15 计算机的内存利用率为 75%
⭐写法3:%[(flags)(width)]typecode # 输出两位数的月份,例如01,02 # 宽度为2,配合flages右对齐用0填充空白处,因为是整数所以不能用s res = '%02d' % 8 print(res)
08
⭐写法4:%[(name)(.precision)]typecode
# 保留2为小数
res = '%(time)s计算机的内存利用率为%(percent).2f%%' % {'time':'11:15', 'percent': 75.123}
print(res)
11:15 计算机的内存利用率为 75.12%
⭐写法5:%[(name)]typecode
print('字符串%(key)s,十进制%(key)d,科学计数%(key)e,八进制%(key)o,
16进制%(key)x,unicode字符%(key)c' % {'key': 65})
字符串 65,十进制 65,科学计数 6.500000e+01,八进制 101,16 进制 41,unicode 字符 A
②format 函数格式化
% 的字符串格式化继承自 C 语言,python 中给字符串对象提供了一个 format 函数进行字符串格式化,且功能更强大,并且大力推荐,所以我们要首选使用。
❀format是字符串的一个方法

基本语法是:
<模板字符串>.format(<逗号分隔的参数>)
在模板字符串中使用 {} 代替以前的 % 作为槽位
'{}计算机的内存利用率为{}%'.format('11:15', 75)
'11:15 计算机的内存利用率为 75%'
当 format 中的参数使用位置参数提供时,{} 中可以填写参数的整数索引和参数一一对应
'{0}计算机的内存利用率为{1}%'.format('11:15', 75)
'11:15 计算机的内存利用率为 75%'
当 format 中的参数使用关键字参数提供时,{}中可以填写参数名和参数一一对应
'{time}计算机的内存利用率为{percent}%'.format(time='11:15', percent=75)
'11:15 计算机的内存利用率为 75%'
{} 中除了可以写参数索引外,还可以填写控制信息来实现更多的格式化功能,语法如下
{<参数序号>:<格式控制标记>}
其中格式控制标记格式如下
[fill][align][sign][#][0][width][,][.precision][type]
-
fill 【可选】空白处填充的字符
❀可以写0 或 任意的单个字符 填充
-
align 【可选】对齐方式(需配合 width 使用)
-
<,内容左对齐
-
>,内容右对齐(默认)
-
=,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即:符号 + 填充物 + 数字
-
^,内容居中
-
-
sign 【可选】有无符号数字
-
+,正号加正,负号加负;
-
-,正号不变,负号加负;
-
空格 ,正号空格,负号加负;
-
-
#【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
-
, 【可选】为数字添加分隔符,如:1,000,000
-
width 【可选】格式化位所占宽度
-
.precision 【可选】小数位保留精度
-
type 【可选】格式化类型
-
传入” 字符串类型 “的参数
-
s,格式化字符串类型数据
-
空白,未指定类型,则默认是 None,同 s
-
-
传入“ 整数类型 ”的参数
-
b,将 10 进制整数自动转换成 2 进制表示然后格式化
-
c,将 10 进制整数自动转换为其对应的 unicode 字符
-
d,十进制整数
-
o,将 10 进制整数自动转换成 8 进制表示然后格式化;
-
x,将 10 进制整数自动转换成 16 进制表示然后格式化(小写 x)
-
X,将 10 进制整数自动转换成 16 进制表示然后格式化(大写 X)
-
-
传入“ 浮点型或小数类型 ”的参数
-
e, 转换为科学计数法(小写 e)表示,然后格式化;
-
E, 转换为科学计数法(大写 E)表示,然后格式化;
-
f , 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
-
F, 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
-
g, 自动在 e 和 f 中切换
-
G, 自动在 E 和 F 中切换
-
%,显示成百分比(默认显示小数点后 6 位)
-
-
⭐写法1:[fill][align][width]
# 输出两位数的月份,例如01,02
# 宽度为2右对齐,空白处填充0
res = '{:0>2}'.format(8)
print(res)
08
⭐写法2:[.precision][type]
# 保留2为小数
res = '{time}计算机的内存利用率为{percent:.2%}'.format(time='11:15', percent=0.75123)
print(res)
11:15 计算机的内存利用率为 75.12%
⭐写法3:
print('字符串{key},十进制{key:d},科学计数{key:e},八进制{key:o},
16进制{key:x},unicode字符{key:c}'.format(key=65))
字符串 65,十进制 65,科学计数 6.500000e+01,八进制 101,16 进制 41,unicode 字符 A
❀加前导符

❀为数字添加分隔符

不要小数点后面的小数 :.0%

'电脑内存占用率为{:.0%}'

③f表达式
3.6 新版功能:
1.定义:格式字符串字面值或称为 f-string f字符串 f表达式,是标注了 'f' 或 'F' 前缀的字符串字面值。
这种字符串可包含替换字段,即以 {} 标注的表达式。
基本语法是:
literal_char{expression[:format_spec]}
-
literal_char普通字符 -
expression表达式,变量或函数。 -
format_spec格式字符串,规则和format 里面的控制符一模一样
直接在 f 字符串的花括号内写上变量名,解释器会自动将变量的值的字符串形式替换
time = '11:15'
percent = 75
f'{time}计算机的内存利用率为{percent}%'
'11:15计算机的内存利用率为75%'

带格式的 f 字符串
# 输出两位数的月份,例如01,02
month = 8
res = f'{month:0>2}'
print(res)
08
# 保留2为小数
time = '11:15'
percent = 0.75123
res = f'{time}计算机的内存利用率为{percent:.2%}'
print(res)
11:15计算机的内存利用率为75.12%
key = 65
print(f'字符串{key},十进制{key:d},科学计数{key:e},八进制{key:#o},16进制{key:x},unicode字符{key:c}')
字符串65,十进制65,科学计数6.500000e+01,八进制0o101,16进制41,unicode字符A
包含运算和函数的 f 字符串
⭐可以输出表达式 与 其值
num = -1
print(f'{num+1=}')
num+1=0
print(f'{abs(num)=}')
abs(num)=1
s = 'abcd'
print(f'{s[::-1]=}')
s[::-1]='dcba'

2. 列表

python 中列表(list)用来表示有序可变元素的集合,元素可以是任意数据类型,序列中的元素可以增,删,改。
2.1 列表的定义
列表由一对中括号进行定义,元素与元素之间使用逗号隔开。
a = [] # 空列表
b = ["a", "b", "cde"] # 字符串列表项
c = [1, "b", "c"] # 数字列表项
d = [1, "b", []] # 列表列表项
e = [1, "b", [2, "c"]] # 列表作为列表的元素叫做列表的嵌套
print('a的类型为:', type(a)) # a的类型为: <class 'list'>
print('b的类型为:', type(b)) # b的类型为: <class 'list'>
print('c的类型为:', type(c)) # c的类型为: <class 'list'>
print('d的类型为:', type(d)) # d的类型为: <class 'list'>
print('e的类型为:', type(e)) # e的类型为: <class 'list'>
⭐列表的另一种写法:

2.2 列表的拼接
像字符串一样,列表之间可以进行加法运算实现列表的拼接,列表可以和整数进行乘法运算实现列表的重复。
[1,2,3] + [4,5,6]
[1, 2, 3, 4, 5, 6]
[1,2,3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
2.3 列表的索引和切片
序列的切片操作完全一致,参见字符串
注意嵌套列表的元素获取
ls = [1,2,['a','b']] ls[2][0]
'a'
2.4 列表的常用操作
python 中的列表操作非常灵活,是非常重要和经常使用的数据类型。
2.4.1)修改元素
列表的中的元素可以进行修改,只需使用索引赋值即可。
ls = [1,2,3] ls[1] = 'a' # 修改单个元素 print(ls)
[1, 'a', 3]
lst = ['java','selenium','postman'] # 将"selenium","postman"修改为['测试框架'] lst[1:] = ['测试框架'] # 修改多个元素 print(lst)
2.4.2)增加元素
给列表添加元素需要使用到列表的方法
.append(el),在列表的末尾添加一个元素
ls = [1,2,3] ls.append(4) print(ls)
[1, 2, 3, 4]

.insert(index, el),在列表的指定索引元素的前面插入一个元素
ls = [1,2,3] ls.insert(0,0) print(ls)
[0, 1, 2, 3]

.extend(iterable),扩展列表,元素为传入的可迭代对象中的元素
⭐脱掉一层外壳,后依次加入
ls = [1,2,3] ls.extend([4,5,6]) print(ls)
[1, 2, 3, 4, 5, 6]


2.4.3)删除元素
.pop(index=-1),删除指定索引的元素,并返回该元素,没有指定索引默认删除最后一个元素
ls = [1,2,3] ls.pop()
3
print(ls)
[1, 2]
ls.pop(0)
1
print(ls)
[2]

.remove(value),从列表中删除第一个指定的值 value,如不存在 value 则报错。
ls = [1,2,3,1] ls.remove(1) print(ls)
[2, 3, 1]

.clear(),清空列表,原列表变成空列表
ls = [1,2,3] ls.clear() print(ls)
[]
.del列表名[索引值],根据索引值删除单个元素/多个元素
⭐ 删除列表中的第2至第4个元素
del li[1:4] print(li)
2.5 列表的其他方法
.copy() ,返回一个列表的浅拷贝。在讲可变与不可变类型的时候再详细讨论。
.count(value),统计列表中 value 的出现次数,返还数量
ls = [1,2,3,1] ls.count(1)
2.index(self, value, start=0, stop=9223372036854775807),返回列表中指定值 value 的第一个索引值,不存在则报错
ls = [1,2,3,1] ls.index(1)
0
ls.index(1,1) #找value值为1所在的索引,从索引start为1的位置开始
3.reverse(),翻转列表元素顺序
ls = [1,2,3] ls.reverse() #因为reverse()函数返回值为None,所以要先操作倒叙 print(ls) # 然后再打印ls # print(ls[::-1]) # 使用切片方式反转
[3, 2, 1]
.sort(key=None, reverse=False),对列表进行排序,默认按照从小到大的顺序,当参数 reverse=True 时,从大到小。注意列表中的元素类型需要相同,否则抛出异常。
ls = [2,1,3] ls.sort() print(ls)
[1, 2, 3]
# 从大到小 ls.sort(reverse=True) print(ls)
[3, 2, 1]
ls = [1,2,'3'] ls.sort()
TypeError Traceback (most recent call last)
in
1 ls = [1,2,'3']
----> 2 ls.sort()
TypeError: '<' not supported between instances of 'str' and 'int'
⭐

![]()
lst = [1,'python','selenium','postman',True,123.345,'python']
print('python元素的索引值:',lst.index('python'))
del lst[lst.index('python')]
print(lst)
del lst[lst.index('python')]
print(lst)
2.6 字符串和列表的转换
字符串是字符组成的序列,可以通过 list 函数将字符串转换成单个字符的列表。
s = 'hello world!' ls = list(s) print(ls)
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!']
由字符组成的列表可以通过字符串的 join 方法进行拼接
# 接上面的案例 ''.join(ls)
'hello world!'


num1 = 100 print(list(num1)) #报错:TypeError: 'int' object is not iterable
3. 元组
元组(tuple)表示有序不可变元素的集合,元素可以是任意数据类型,序列中的元素不能增,删,改,可以说元组就是不可变的列表。
⭐元组与列表的区别:元组就是不可变的列表
3.1 元组的定义
元组通过一对小括号进行定义,元组之间使用逗号隔开。
a = () # 空元祖
b = ("a", "b", "cde") # 字符串元组
c = (1, "b", "c") # 数字元组
d = (1, "b", []) # 列表元组
e = (1, "b", (2, "c")) # 元祖的嵌套
f = 1,2
g = (1,) # 单元素元组
print('a的类型为:', type(a)) # a的类型为: <class 'tuple'>
print('b的类型为:', type(b)) # b的类型为: <class 'tuple'>
print('c的类型为:', type(c)) # c的类型为: <class 'tuple'>
print('d的类型为:', type(d)) # d的类型为: <class 'tuple'>
print('e的类型为:', type(e)) # e的类型为: <class 'tuple'>
print('f的类型为:', type(f)) # f的类型为: <class 'tuple'>
注意单元素元组的定义,一定要多加个逗号
g = ('hello')
h = ('hello',)
print('g的类型为:', type(g)) # g的类型为: <class 'str'>
print('h的类型为:', type(h)) # h的类型为: <class 'tuple'>
3.2 元组的索引和切片
序列的索引和切片完全一致,参见字符串。
3.3 元组的常用操作
元组的元素不能修改,增加和删除,其他操作和列表的操作一致。
元组利用不可修改的特性,应用在多变量赋值和函数多返回值上。
a, b = (1, 2) # 经常简写为a, b= 1, 2
当然多变量赋值时可以使用可迭代对象,但是元组最安全,它是不可变的。
关于函数多返回值的问题我们后面再讲
⭐tuple + ,形成一个新的元组(可用pythontutor.com/visualize.html#mode=display进行验证)
tp1 = (1, 2, 3, 4, 5)
tp2 = (100, 3.14) res = tp1 + tp2 print(res) print(tp1) print(tp2)
(100, 3.14, 1, 2, 3, 4, 5)
(1, 2, 3, 4, 5)
(100, 3.14)

⭐元组不可操作,要你操作怎么做?
tp1 = (1, 2, 3, 4, 5) print(id(tp1)) ls = list(tp1) # 先把元组变成列表 ls.append(6) # 操作list tp1 = tuple(ls) # 然后再变成tuple print(tp1) print(type(tp1)) # 但已不再是以前的tuple print(id(tp1)) # id 不一样了
3.4 元组的常用方法
元组只有两个公有方法 count,index 用法与列表相同。
3.5 len 函数
python 内建函数 len 可以获取对象中包含的元素个数
s = 'hello' ls = [1,2,3] t = (1,2,3) print(len(s)) #5 print(len(ls)) #3 print(len(t)) #3
4. 可变与不可变对象
python 中的对象根据底层内存机制分为可变与不可变两种。
可变对象可以在其 id() 保持固定的情况下改变其取值。
❀id(a),拿的是a地址的位置
下面的列表 a,修改值后,id 保持不变
a = [1,2,3] id(a) # 虚拟内存地址,一个大整数,每次运行都会变
14053670614592
# 修改a的值 a[0] = 'a' id(a)
14053670614592


基本数据类型中列表,集合和字典都是可变数据类型。
如果修改一个对象的值,必须创建新的对象,那么这个对象就是不可变对象。
例如下面的字符串 s,修改内容后 id 发生了改变。
s = 'hello' id(s)
140453671058032
s = 'Hello' id(s)
140453671058032
基本数据类型中数字,字符串,元组是不可变对象。
5. 可哈希对象
一个对象的哈希值如果在其生命周期内绝不改变,就被称为可哈希。可哈希对象都可以通过内置函数 hash 进行求值。
它们在需要常量哈希值的地方起着重要的作用,例如作为集合中的元素,字典中的键。
不可变数据类型都是可哈希对象,可变数据类型都是不可哈希对象。
hash(1)
1
hash([1,2])
TypeError Traceback (most recent call last)
in
----> 1 hash([1,2])
TypeError: unhashable type: 'list'
6. 赋值与深浅拷贝
6.1 赋值
python 是解释型编程语言,当解释器在碰到赋值语句时它首先会计算赋值符号右边的表达式的值,然后再创建左边的变量。
变量中实际存储的是值在内存中的地址,引用变量时通过地址指向内存中的值。通过内建函数 id 可以查看解释器中变量的虚拟内存地址整数值。
a = 1 id(a)
140721806448288
python 的赋值语句不复制对象,而是创建目标和对象的绑定关系。
所以将一个变量赋值给另外一个变量时,并不会创建新的值,只是新变量会指向值的内存地址
a = 1 b = a id(a) == id(b)
True
对于字符串和数字这样的不可变数据类型,当上例中的变量 a 自加 1 时,会创建一个新值重新,它不会改变原来的值。因此对变量 b 没有影响。
a += 1 print(a) print(b)
2
1
但是看下面的案例
ls = [1,2,3] ln = ls ls[0] = 2 print(ln)
[2, 2, 3]
会发现变量 ls 在修改列表的值后,变量 ln 的值也发生了同样的改变,这是因为 ls,ln 指向相同的列表。对可变数据类型进行变量赋值时要考虑这个特性。
6.2 浅拷贝
导入 copy 模块中的 copy 函数就是浅拷贝操作
import copy a = 123 s = 'hello' b = copy.copy(a) d = copy.copy(s) print(id(a),id(b)) print(id(s),id(d))
4382616384 4382616384
140571355341296 140571355341296
对于字符串、数字这种不可变数据类型来说,浅拷贝相当于变量赋值,所以变量 a 和 b 的 id 相等,变量 s 和 d 的 id 相等。
a += 1 print(a) print(b)
124
123
对原变量的修改会创建新的值,不会影响浅拷贝生成的变量,变量 a 自加 1 后指向值 124,变量 b 的值不变
对于可变数据类型:列表,字典,集合等浅拷贝会有不一样的结果。
ls = [1,'2',['a','b']] ln = copy.copy(ls) print(id(ls),id(ln))
140571352915648 140571355343040
当对可变数据类型进行浅拷贝时,会创建一个新的数据,所以变量 ls 和 ln 的 id 不相等。
print(id(ls[2]),id(ln[2]))
140571355288384 140571355288384
浅拷贝将原始对象中找到的对象引用插入其中。
也就是说,ls 列表中的元素,ln 中只是引用,ln 中的每个对应位置指向的内存地址和 ls 相同。
ls[0] = 2 print(ls) print(ln)
[2, '2', ['a', 'b']]
[1, '2', ['a', 'b']]
修改 ls 中第一个元素,因为是不可变数据类型,所以 ls 中第一个位置指向了新的内存地址,ln 中的不变。

ls[2][1] = 'c' print(ls) print(ln)
[2, '2', ['a', 'c']]
[1, '2', ['a', 'c']]
修改 ls 中最后一个元素,因为是可变数据类型,所以 ln 中的值也发生了改变。

6.3 深拷贝
不可变数据类型的深浅拷贝一致。
复杂数据类型进行深拷贝会对数据中的所有元素完全重新复制一份,不管有多少层嵌套,互不影响。
import copy ls = [1,2,3,['a', 'b']] # 深拷贝使用deepcopy ln = copy.deepcopy(ls) ls[3][0]='b' print(ls) print(ln)
[1, 2, 3, ['b', 'b']]
[1, 2, 3, ['a', 'b']]
⭐~浅拷贝:拷贝的是对象的引用,只会拷贝一层
⭐~深拷贝:会递归的拷贝对象里面每个元素所有的副本
⭐~浅拷贝:如同第二个文件夹复制第一个文件夹里面文件的快捷方式,当修改第二个文件夹里面快捷文件的内容时,第一个文件夹里面对应文件的内容也会改变。

⭐~深拷贝:如同拷贝一个文件夹副本,当修改原文件夹中文件的内容时,副本文件夹里面文件的内容,完全不受影响。

第 4 章. 基本数据类型 (三)
6️⃣ 散列类型
散列类型用来表示无序集合。
1. 集合

python 中集合(set)类型与数学中的集合类型一致,用来表示无序不重复元素的集合。
![]()
1.1 集合定义
集合使用一对大括号 {} 进行定义,元素之间使用逗号隔开。集合中的元素必须是不可变类型。
a = {1, 2, 3, 4, 5, 6}
b = {1,2,'a',('a',),1.5} # 集合中元素必须是不可变类型
print('a的类型为:', type(a)) # a的类型为: <class 'set'>
print('b的类型为:', type(b)) # b的类型为: <class 'set'>
{[1,2,3],(1,2,3)}
TypeError Traceback (most recent call last)
in
----> 1 {[1,2,3],(1,2,3)}
TypeError: unhashable type: 'list'
注意空集合的定义方式是 set()
a = set() # 空集合
# 注a = {} 是空字典
print(a)
set()
⭐集合不支持拼接和多次输出
1.2 集合的常用操作
1.2.1)添加元素
集合添加元素常用函数有两个:add 和 update
set.add(obj),向集合中添加元素 obj,如果集合中不存在则添加
s = {1,2}
s.add(1)
print(s)
{1, 2}
s.add(3) print(s)
{1, 2, 3}

set.update(iterable),向集合中添加多个元素,如果集合中不存在则添加
iterable:可迭代类型,即可被for循环的,除了数字、bool值和None
s = {1,2}
s.update({2,3})
print(s)
{1, 2, 3}
s.update([3,4]) # 把3,4依次添加进集合 print(s)
{1, 2, 3, 4}

1.2.2)删除元素
set.pop() 随机删除并返回集合中的一个元素,如果集合中元素为空则抛出异常。
可做抽奖代码
s = {'a','b','c'}
s.pop()
'a'
set.remove(ele),从集合中删除元素 ele,如果不存在则抛出异常。
s = {'a','b','c'}
s.remove('a')
print(s)
{'b', 'c'}
s.remove('d')
KeyError Traceback (most recent call last)
in
----> 1 s.remove('d')
KeyError: 'd'
set.discard(ele),从集合中删除元素 ele,如果不存在不做任何操作
s = {'a','b','c'}
s.discard('d')
print(s)
{'a', 'b', 'c'}
set.clear(),清空集合
s = {1,2,3}
s.clear()
print(s)
set()
1.2.3)集合运算
| 数学符号 | python 运算符 | 含义 | 定义 |
|---|---|---|---|
| ∩ | & | 交集 | 一般地,由所有属于 A 且属于 B 的元素所组成的集合叫做 AB 的交集。 |
| ∪ | | | 并集 | 一般地,由所有属于集合 A 或属于集合 B 的元素所组成的集合,叫做 AB 的并集 |
| -或\ | - | 相对补集/差集 | A-B,取在 A 集合但不在 B 集合的项 |
| ^ | 对称差集/反交集 | A^B,取只在 A 集合和只在 B 集合的项,去掉两者交集项 |
交集 intersection()
取既属于集合 A 和又属于集合 B 的项组成的集合叫做 AB 的交集
s1 = {1,2,3}
s2 = {2,3,4}
s = s1 & s2
print(s)
# print(s1.intersection(s2))
{2, 3}
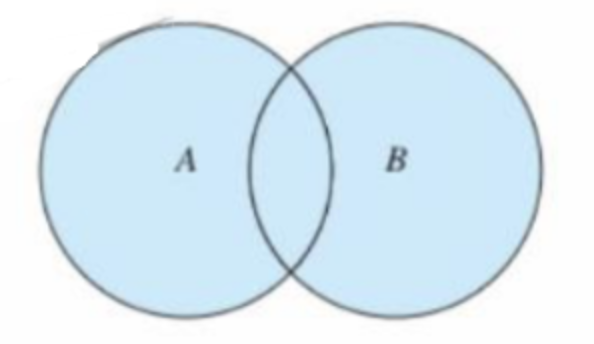
并集 union()
集合 A 和集合 B 的所有元素组成的集合称为集合 A 与集合 B 的并集
s1 = {1,2,3}
s2 = {2,3,4}
s = s1|s2
print(s)
# print(s1.union(s2))
{1, 2, 3, 4}
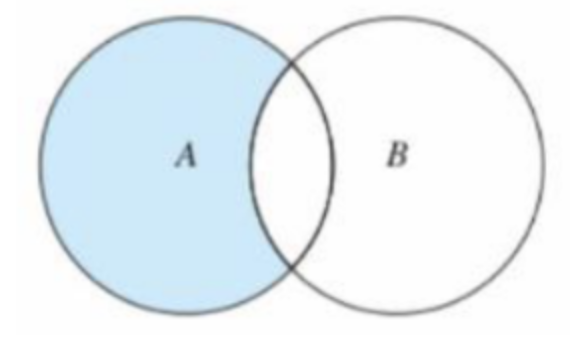
补集 difference()(差集)
取在集合 A 中不在集合 B 中的项组成的集合称为 A 相对 B 的补集
s1 = {1,2,3}
s2 = {2,3,4}
s = s1-s2
print(s)
print(s1.difference(s2))
{1}
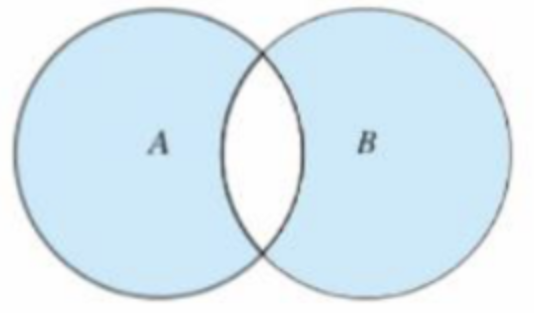
对称差集 symmetric_difference()
取不在集合 AB 交集里的元素组成的集合称为对称差集,也叫反交集
s1 = {1,2,3}
s2 = {2,3,4}
s = s1^s2
print(s)
print(s1.symmetric_difference(s2))
{1, 4}
1.2.4)集合查询
⭐ set 无序的,查询需要转换成列表
s1 = {"huahua","花花","为什么","那么","红"}
lst1 = list(s1) # 进行转换
print(lst1[0])
1.3 集合去重
集合具有天生去重的性质,因此可以利用它来去除序列中的重复元素
ls = [1,1,2,3,4,4,3,2,5] ls = list(set(ls)) print(ls)
[1, 2, 3, 4, 5]
set('aabbcc')
{'a', 'b', 'c'}
1.4 集合类型转换


2. 字典

因为集合无序,因此不能很便捷的获取特定元素。利用集合元素不重复的特性,使集合中的元素映射值组成键值对,再通过键来获取对应的值。
2.1 字典的定义
python 中的字典(dict)数据类型就是键值对的集合,使用一对大括号进行定义,键值对之间使用逗号隔开,键和值使用冒号分割。
字典中的键必须是不可变数据类型,且不会重复,值可以是任意数据类型,且支持修改。
⭐ key通常用str
a = {} # 空字典
b = {
1: 2, # key:数字;value:数字
2: 'hello', # key:数字;value:字符串
('k1',): 'v1', # key:元祖;value:字符串
'k2': [1, 2, 3], # key:字符串;value:列表
'k3': ('a', 'b', 'c'), # key:字符串;value:元祖
'k4': { # key:字符串;value:字典
'name': 'feifei',
'age': '18'
}
}
print('a的类型为:', type(a)) # a的类型为: <class 'dict'>
print('b的类型为:', type(b)) # b的类型为: <class 'dict'>
⭐ 字典不支持加号拼接和乘号多次输出

2.2 字典的索引
字典通过键值对中的键作为索引来获取对应的值。字典中的键是无序的。
d = {1:2, 'key': 'value'}
print(d[1])
2
print(d['key'])
value
这种方式很好的将键和值联系起来,就像查字典一样。

2.3 字典的常用操作
2.3.1)增加元素
字典可以直接利用 key 索引赋值的方式进行添加元素,如果 key 存在则修改字典
d = {'name': 'xinlan'}
d['age'] = 18
print(d)
{'name': 'xinlan', 'age': 18}
dict.update(new_dict),将 new_dict 合并进 dict 中。
d = {'name': 'xinlan'}
n_d = {'age':18, 'sex':'男'}
d.update(n_d)
print(d)
{'name': 'xinlan', 'age': 18, 'sex': '男'}
d.update({'sex': '女','height': 170}) # 当有重复key的时候会覆盖原值
print(d)
{'name': 'xinlan', 'age': 18, 'sex': '女', 'height': 170}
2.3.2)修改元素
直接通过 key 索引赋值的方式可以对字典进行修改,如果 key 不存在则添加
d = {'name': 'xinlan'}
d['name'] = 'XinLan'
print(d)
{'name': 'XinLan'}
多修改:update
2.3.3)删除元素
dict.pop(key[,d]),删除指定的 key 对应的值并返回该值,如果 key 不存在则返回 d,如果没有给定 d,则抛出异常
d = {'name': 'xinlan','age': 18}
d.pop('age')
18
print(d)
{'name': 'xinlan'}
d.pop('age') # 报错

dict.popitem(),按照LIFO(last-in,first-out)后进先出的方式删除字典 dict 中的一个键值对,并以二元元组 (key,value) 的方式返回
d = {'name': 'Felix','age': 18}
d.popitem()
('age', 18)

clear(),清空字典
d = {'name': 'Felix','age': 18}
d.clear()
del字典名[key],通过key来进行删除,删除键值对
2.3.4)查询元素
通过 key 索引可以直接获取 key 对应的值,如果 key 不存在则抛出异常。
d = {1:2, 'key': 'value'}
print(d[1])
2
d['name']
KeyError Traceback (most recent call last)
in
----> 1 d['name']
KeyError: 'name'
dict.get(key,default=None),获取 key 对应的 value 如果不存在返回 default
交互式输出,返回None不显示,可以用print打印出来

d = {1:2, 'key': 'value'}
d.get(1)
2
d.get('name',0)
0
2.3.5)字典常用方法



2.4 字典的转换


7️⃣ 其他类型
1. None
None 是 python 中的特殊数据类型,它的值就是它本身 None,表示空,表示不存在。
print(None) # 注意首字母大写
None
练习:
1.用户输入三角形三边长度,并计算三角形的面积
a = float(input("请输入三角形第一边的边长 a:"))
b = float(input("请输入三角形第二边的边长 b:"))
c = float(input("请输入三角形第三边的边长 c:"))
if a+b>c or b+c>a or c+a>b:
p = (a+b+c)/2
s = (p*(p-a)*(p-b)*(p-c))**0.5
print("三角形的面积是:{}".format(s))
else:
print("两边之和必须大于第三边")
Ⅲ 程序流程控制
第 5 章. 程序流程控制 (一)
程序流程控制(一)
python 是通过一些程序结构来控制程序的执行顺序和流程的。
1⃣️ 程序结构
计算机程序是一条条按顺序执行的指令。顺序结构是计算机程序的基础,但单一的顺序结构不能解决所有问题。计算机程序由三种基本结构组成:
-
顺序结构
-
分支结构
-
循环结构
1. 顺序结构

我们每天早上起床,穿衣服,洗脸,刷牙,叠被子,吃早餐,这些按照单一顺序进行的就是顺序结构。
顺序结构是程序执行的基本流程,它会按照代码从上往下的顺序依次执行。
a = 1 a += 1 print(a)
2
例如上面的代码,执行流程为
-
定义变量
a,并赋值为整数 1 -
变量
a自加 1 -
调用函数
print输出变量a的值
从上往下依次执行
2. 分支结构
出门时是否带伞要根据天气条件进行判断,如果天气好就不带,如果可能下雨或正在下雨就要带,这就是分支结构。
分支结构是程序根据条件判断结果而选择不同代码向前执行的一种方式,也叫条件分支。
分支结构包括:
-
单分支
-
二分支
-
多分支
2.1 单分支
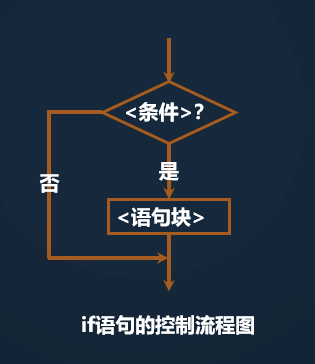
在 python 中单分支结构通过 if 语句来实现,语法如下:
if <条件>:
语句块
-
注意条件语句结束后要紧跟冒号
-
语句块是
if条件满足后执行的一条或多条语句序列 -
语句块中语句通过缩进与
if语句所在行形成包含关系 -
缩进按照规范为 4 个空格
if 语句会首先计算 <条件> 表达式,如果结果为 True 则会执行所包含的语句块,结果为 False 则会跳过所包含的语句块。
if 语句中的语句块的执行与否依赖于条件判断。但无论什么情况,控制都会 转到与 if 语句同级别的下一条语句。
案例:成绩是否及格

input 函数
input 函数用来接收用户输入的文本信息,然后以字符串的形式返回,它接收字符串参数作为提示信息输出。



⭐
一个程序,有开始,有结束 ->绝大多数情况下
代码的执行逻辑:从上到下,从里到外

score = input('请输入你的成绩>>>:')
print(score,type(score))
请输入你的成绩 >>>:100
100 <class 'str'>
score = input('请输入你的成绩>>>:')
# 转换类型
score = float(score)
# 判断
if score < 60:
print('没及格,赏一巴掌')
if score >= 60:
print('有进步,么么哒,亲一下')
请输入你的成绩 >>>:100
有进步,么么哒,亲一下


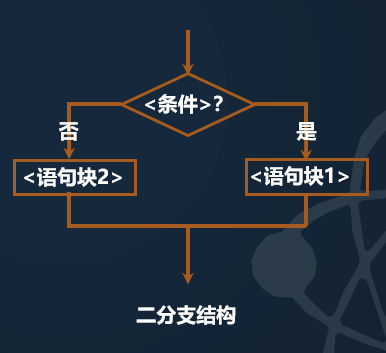
2.2 二分支
python 中二分支结构通过 if-else 语句来实现的,语法 格式如下:
if <条件>: <语句块1> else: <语句块2>
-
< 语句块 1> 是在 if 条件满足后执行的一个或多个语句序列
-
< 语句块 2> 是 if 条件不满足后执行的语句序列
- if,else是关键字,条件和else后面的冒号不能省略
-
注意缩进,< 语句块 2> 通过缩进与 else 所在行形成包含关系
二分支语句用于区分 < 条件 > 的两种可能 True 或者 False,分别形成执行路径
案例:成绩是否及格(2)
通过二分支改进案例成绩是否及格
score = input('请输入你的成绩>>>:')
# 转换类型
score = float(score)
# 判断
if score < 60:
print('没及格,赏一巴掌')
else:
print('有进步,么么哒,亲一下')
请输入你的成绩 >>>:100
有进步,么么哒,亲一下
三目运算
二分支结构还有一种更简洁的表达方式,语法格式如下:
<表达式> if <条件> else <表达式2>
适合代码块为 1 行语句时,这种方式也叫三目运算。
上面的代码可以改写为:
score = input('请输入你的成绩>>>:')
# 转换类型
score = float(score)
# 判断
print('没及格,赏一巴掌') if score < 60 else print('有进步,么么哒,亲一下')
请输入你的成绩 >>>:100
有进步,么么哒,亲一下
对于简单判断,三目运算可以将多行语句写成一行,简洁明了。
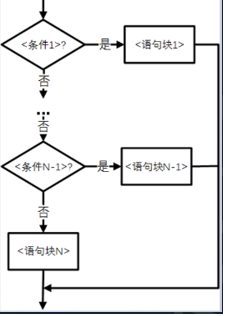
2.3 多分支
python 通过 if - elif - else 表示多分支结构,语法如下:
if <条件1>: <代码块1> elif <条件2>: <代码块2> ... else: <代码块3>
多分支是二分支的扩展,用于多个判断条件多条执行路径的情况。python 依次执行判断条件,寻找第一个结果为 True 的条件,执行该条件下的代码块,同时结束后跳过整个 if-elif-else 结构,执行后面的语句。如果没有任何条件成立,则执行 else 下的代码块,且 else 语句是可选的,也即是说可以没有 else 语句。

案例:成绩评价
上面的案例对成绩的评价太粗糙了,60 分就可以赏个么么哒。通过多分支改进上面的案例。
请根据用户输入的成绩,按一下等级分区:
-
< 40: E
-
40-60: D
-
60-75: C
-
75-85: B
-
85-100: A
score = input('请输入你的成绩>>>:')
# 转换类型
score = float(score)
# 判断
if score < 40:
print('等级:E')
elif 40<= score < 60:
print('等级:D')
elif 60<= score < 75:
print('等级:C')
elif 75<= score < 85:
print('等级:B')
else:
print('等级:A')
# 多分枝,尽量做到条件之间互斥
请输入你的成绩 >>>:100
等级:A
2.4 巢状分支


3. 循环结构
工作日每天 9:00 到公司上班,17:30 下班,周而复始,这就是循环结构。
python 中循环结构有两种:
-
条件循环也叫 while 循环
-
遍历循环也叫 for 循环
3.1 条件循环
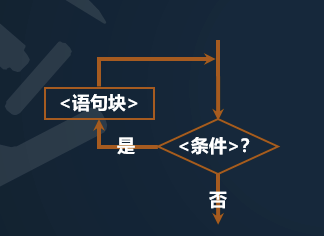
python 中的条件循环通过 while 循环语句来实现,所以也叫 while 循环,语法格式如下:
while <条件>: 代码块
-
while关键字空格后接条件表达式末尾加上冒号组成while语句 -
代码块中的代码通过 4 个空格和
while语句形成包含关系
while` 语句首先计算 `<条件>` 表达式,如果结果 `True`,则执行对应代码块中的语句,执行结束后再次执行 `<条件>表达式,再次判断结果,如果为 `True` 则循环执行,直到 `<条件>` 表达式为 `False` 时跳出循环,执行和 `while` 语句相同缩进的下一条语句。
当 <条件> 表达式恒为 True 时,形成无限循环,也叫死循环,需要小心使用。
当 <条件> 表达式恒为 Flase 时,则无法进入循环体
# 依次打印0-9
i = 0
while i < 10:
print(i)
i = i + 1
0
1
2
3
4
5
6
7
8
9
# 序列的循环
# 列表的元素循环
ls = ['a','b','c','d','e','f']
index = 0
while index < len(ls):
print(ls[index])
index += 1
a
b
c
d
e
f
# 散列的循环
# 集合没办法循环
dc = {'name': 'felix', 'age': 18}
index = 0
# 转换成列表
keys = list(dc.keys())
while index < len(keys):
print(dc[keys[index]])
index += 1
felix
18
⭐信息

⭐调试

3.2 遍历循环
python 中使用关键字 for 来实现遍历循环,也叫 for 循环,也叫迭代循环,语法格式如下:
for <循环变量> in <遍历结构>: 代码块
-
关键字
for+ 空格 +<循环变量>+ 关键字in+< 遍历结构 >+ 冒号组成 for 语句 -
代码块通过缩进和 for 语句形成包含关系
for 循环会依次取出遍历结构中的元素,然后赋值给循环变量,每次遍历都会执行代码块,直到取出遍历结构中的所有元素。
所有可迭代对象都可以作为遍历结构进行 for 循环。
基本数据类型中序列数据类型,散列数据类型都可以进行迭代。
# for循环来遍历可迭代对象非常方便
# 序列的迭代
# 列表的迭代
ls = [0,1,2,3,4,5,6,7,8,9]
for i in ls:
print(i)
0
1
2
3
4
5
6
7
8
9
# 散列的迭代
st = {1,2,3,4,5,6}
for i in st:
print(i)
1
2
3
4
5
6
dc = {'name': 'xinlan', 'age': 18}
# 字典key的迭代
for key in dc:
print(key)
name
age
# 字典值的迭代
for key in dc:
print(dc[key])
xinlan
18
for value in dc.values():
print(value)
xinlan
18


迭代器(iterator)
迭代器是一个可以记住遍历位置的对象。for 循环迭代本质上就是通过迭代器来实现的。
通过内建函数 iter 可以创建迭代器。
iter('abc')
<str_iterator at 0x7fdc6a017670>
不是所有的数据类型都可以创建迭代器,凡是能够创建迭代器的对象称为 可迭代对象,反之是 不可迭代对象
range 函数
# 场景:循环100次
for i in range(1,101):
print('打印第{}遍helle python'.format(i))
内建函数 range ,是序列类型数据,可以创建输出整数序列的迭代器。支持索引取值和切片操作。
range(start, stop,step)
range(i,j)生成 i,i+1,i+2,...,j-1,start 默认为 0,当给定 step 时,它指定增长步长。
# 输出0-9
for i in range(10):
print(i)
0
1
2
3
4
5
6
7
8
9
# 输出1-10
for i in range(1,11):
print(i)
1
2
3
4
5
6
7
8
9
10
# 输出-1--10
for i in range(-1,-11,-1):
print(i)
-1
-2
-3
-4
-5
-6
-7
-8
-9
-10
for 循环经常和 range 函数配合用来指定循环次数。

⭐可以通过list()函数转化为列表类型的数据
print(list(range(10))) print(list(range(1,5))) print(list(range(1,10,2)))
⭐for 循环中的range -- 是迭代器,用于生成一个整数的序列
r = range(10) # 根据给到的一个数字,生成一个列表 -- 是可迭代的对象 print(list(r))
3.3 循环控制关键字
循环有时候需要主动中断来提高程序执行效率。
ls = [60,59,78,80,56,55]
# ls中存放的是所有学生的成绩
# 要判断是否有同学不及格
for i in ls:
if i < 60:
print('有同学不及格')
有同学不及格
有同学不及格
有同学不及格
可以发现上面的案例中,其实第二个成绩就不及格了,但是程序继续循环下去,如果数据量小,效率差别不大,但数据量大时会影响程序的执行效率。在实际的代码编写中会有很多这种情况,这是就需要能够主动结束循环的能力。
break 关键字
python 中循环结构可以使用 break 跳出当前循环体,脱离该循环后代码继续执行。
for i in ls:
if i >= 60:
print('有同学及格')
break
有同学及格
index = 0
while index < len(ls):
if ls[index] >= 60:
print('有同学及格')
break
有同学及格
for i in range(1,4):
for j in range(1,4):
if i==2:
break
print(i,j)
1 1
1 2
1 3
3 1
3 2
3 3
continue 关键字
python 中循环结构还可以使用 continue 关键字用来跳出当次循环,继续执行下一次循环。
# 输出所有奇数
for i in range(10):
if i%2 == 0:
continue
print(i)
1
3
5
7
9
for i in range(10):
if i%2 == 0:
break
print(i)

⭐continue 终止本轮循环,回到开头继续判断(如果再次判断,条件为False,就停止循环)
while a:
a -= 1
if a%2 == 0:
print("当前a的值为是偶是:{}".format(a))
continue # 4走的这个if,遇到continue会重新判断不会管后面的代码
if a<5:
print("a的值小于5,当前a为:{}".format(a)) # 所以最后a的值是3
break
print("循环结束了!")

else 关键字
循环结构还可以通过和 else 关键字进行配合,用来检测循环是否正常循环结束,还是 break 掉了。
for i in range(10):
if i%2 != 0:
continue
print(i)
else:
print('循环正常结束')
0
2
4
6
8
循环正常结束
for i in range(10):
if i%2 != 0:
break
print(i)
else:
print('循环正常结束')
0
""" break:终止循环,(跳出循环体,执行循环之外的代码) continue:中止当前本轮循环,直接进入下一轮循环, break,continue:while和for 都适用。 """
3.4 多层循环
print('* ',end=''): 输出时加参数 end='',让下一次执行print输出不换行
⭐第一层循环控制行,第二层循环控制列
打印正方形: n*n

打印三角形:
n = 9
for i in range(n):
for j in range(i+1):
print("* ",end='')
print()
打印乘法口诀表:格式化输出,左对齐,长度占四个字符
for i in range(1,10):
for j in range(1,i+1):
print("{}*{}={:<4}".format(j,i,i*j),end='')
print()
练习:
1.大小写互换,转换为镜像
2.输入一个年份,输出是否为闰年。
闰年条件:能被4整除但不能被100整除,或者能被400整除的年份都是闰年
year = int(input("请输入年份:"))
if year%4 == 0 and year %100 !=0 or year%400 == 0:
print("{}年是闰年".format(year))
else:
print("{}年不是闰年".format(year))
3.完成一个猜数字游戏
# 进入程序后
# 提示用户输入 要猜的数字
# 其他人输入时,提示数字大了,或者小了
# 猜到正确的数字为止,提示恭喜猜对了
# (选做:可以控制每位玩家的猜数字次数,例如,一个人只能猜3次,3次猜错结束程序,显示正确的数字后,重新开始)
# (选做: 猜数字的游戏中的数字尝试让系统生成,提示:random.randint(n,m) 可以让python在n-m之间生成一个随机数)
flag = 1
z = random.randint(1, 100)
m = 3
while flag:
n = int(input("请输入你要猜的数字:"))
if n > z:
print("大了")
elif n<z:
print("小了")
else:
print("恭喜猜对了")
flag = 0
m -= 1
if m == 0:
break
print("退出系统。。。")
4.一个5位数,判断它是不是回文数
# 个位与万位相同,十位与千位相同
# 方法一
num = input("请输入任意数:")
if num == num[::-1]:
print("是回文数")
else:
print("不是回文数")
/**
* num / 10000; //万位
*(num % 10000) / 1000; //千位
*(num % 1000) / 100; //百位
*(num % 100) / 10; //十位
* num % 10; //个位
*/
# 方法二
num = int(input("请输入任意五位数数:"))
if ((num//10000)==(num%10) and ((num%10000)//1000)==((num%100)//10) and num>=10000 and num<=99999):
print("%d是回文数"%num)
else:
print("%d不是回文数"%num)
# 方法三
x = int(input("请输入任意五位数数:"))
if __name__ == '__main__':
if x < 10000 or x > 99999:
print("输入错误")
else:
ten_thousand = x // 10000 #拆分最高位万位
thousand = x % 10000 // 1000 # 拆分千位
ten = x % 100 // 10 # 拆分十位
indiv = x % 10 # 拆分个位
if indiv == ten_thousand and ten == thousand:
print("%d是回文数" %x)
else:
print("%d不是回文数" %x)
# 方法四:http://c.biancheng.net/view/9816.html
5.使用代码完成一下逻辑,根据输入的行数打印如下图案(等边三角形)
请输入需要打印的行数:5
*
***
*****
*******
*********
n = int(input("请输入需要打印的行数:"))
for i in range(1,n+1):
for j in range(1,n-i+1):
print(" ",end="")
for k in range(1,2*i):
print("*",end="")
print()
# 断点调试看

# 输入直角三角形,就先打印* 再打印空格
6.有1,2,3,4这四个数字,能组成多少个互不相同且无重复数字的三个数?分别是什么?
提示:123,321就是符合要求,数字既不相同,而且每个数字的个十百位也不重复;而121,212就不行,因为数字的各位与百位重复
lst = [1, 2, 3, 4]
lt = []
for a in lst: # 百位
for b in lst: # 十位
for c in lst: # 个位
if a!=b and a!=c and b!=c: # 每一位都不相等
num = a*100+b*10+c*1
lt.append(num)
print("符合要求的数共有{}个,分别为:{}".format(format(len(lt)),lt))
7.请用嵌套for循环输出如下等边三角形(三个边均是5个*)
@@@@@@*
@@@@@* *
@@@@* * *
@@@* * * *
@@* * * * *
for i in range(5):
for j in range(6-i):
print("@",end="")
for k in range(i+1):
print("*",end="")
print()
2⃣️ 异常处理
python所有的内置异常类型汇总 - musen - 博客园 (cnblogs.com)

在程序的编写过程中会出现各种错误,语法错误在程序启动时就会检测出来,它是程序正常运行的前提条件。程序中还有一种错误发生在程序运行后,可能是由于逻辑问题,又或者是业务发生了改变,为了能让用户有更好的体验,加强代码的健壮性,我们需要对这些错误进行处理,也叫异常处理。
⭐异常:导致程序无法继续执行,例如:字符串和数字相加,除以0,对None进行操作
⭐中断当前程序执行,然后打印红字
1.异常处理
1.1 try-except
在 python 中通过 try-except 语句进行异常处理。
回忆我们前面关于成绩评价的案例,当用户输入非数值时程序会发生什么?
score = input('请输入你的成绩>>>:')
# 转换类型
score = float(score)
# 判断
if score < 40:
print('等级:E')
elif 40<= score < 60:
print('等级:D')
elif 60<= score < 75:
print('等级:C')
elif 75<= score < 85:
print('等级:B')
else:
print('等级:A')
请输入你的成绩 >>>:abc
ValueError Traceback (most recent call last)
in
1 score = input('请输入你的成绩 >>>:')
2 # 转换类型
----> 3 score = float(score)
4 # 判断
5 if score < 40:
ValueError: could not convert string to float: 'abc'

try-except 语句的基本语法格式如下:
try:
<语句块1>
except <异常类型1>:
<语句块2>
except <异常类型2>:
<语句块3>
语句块 1 中的代码如果发生异常,且异常与类型与对应 excep 语句中的异常类型相同则会被其捕获,从而执行对应的语句块
⭐当语句块1有多个不同类型的错误时,需要对不同类型的错误进行处理,要写多个except;不然会让没有异常的语句因为下面的错误语句也被独个的except进行处理。

try:
score = input('请输入你的成绩>>>:')
# 转换类型
score = float(score)
# 判断
if score < 40:
print('等级:E')
elif 40<= score < 60:
print('等级:D')
elif 60<= score < 75:
print('等级:C')
elif 75<= score < 85:
print('等级:B')
else:
print('等级:A')
except ValueError as e:
print(e)
print('请输入正确的成绩')
请输入你的成绩 >>>:aaa
could not convert string to float: 'aaa'
请输入正确的成绩
1.1.1)万能异常处理

1.1.2)单分支&多分枝

1.2 try-except-else

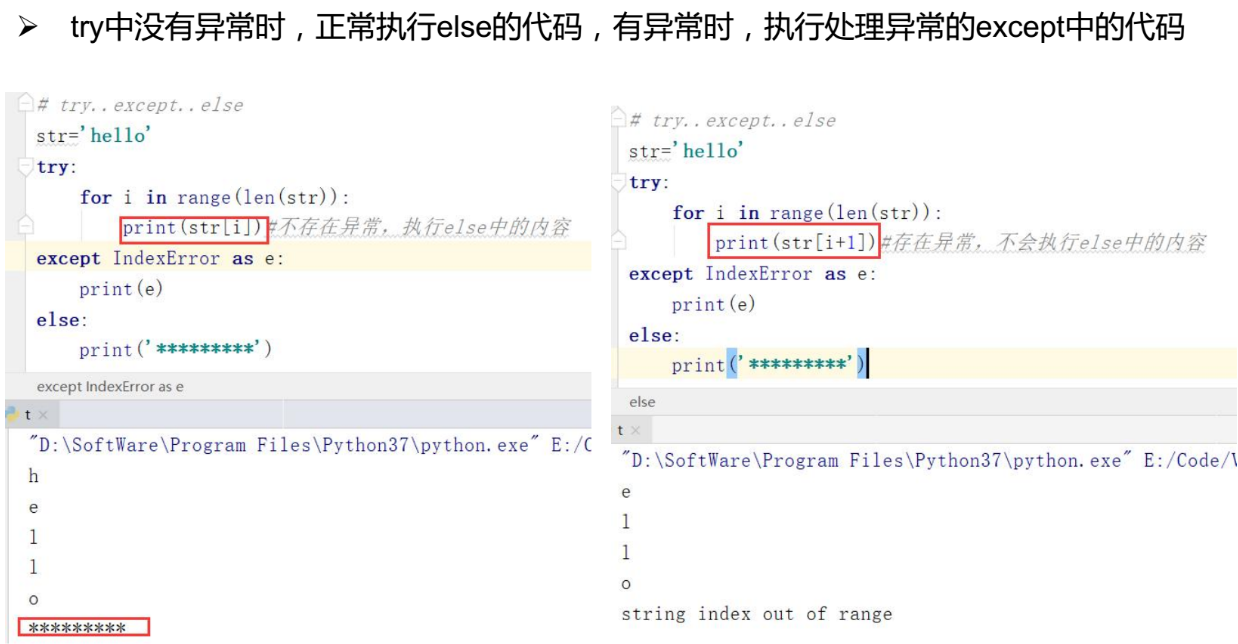
1.3 try-except-finally


1.4 try-except-else-finally
除了 try 和 except 关键字外,异常语句还可以与 else 和 finally 关键字配合使用,语法格式如下:
try: <语句块1> except <异常类型>: <语句块2> ... else: <语句块3> finally: <语句块4>
代码执行流程如下:

没有发生异常时,会执行 else 语句后的代码块,不管有没有发生异常,finally 语句后的代码块一定会执行
try:
a = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
index = input('请输入一个正整数>>>:')
index = int(index)
print(a[index])
except Exception as e:
print(e)
print('请输入一个正整数')
else:
print('没有发生异常')
finally:
print('我一定会执行')
请输入一个正整数 >>>:1
B
没有发生异常
我一定会执行
⭐
2. 异常种类:

指定异常类型:
找到异常后,直接执行处理,后面的异常不会捕捉(如分支条件的if/else):

如果有多个异常,其中一个没捕获到异常,报错:

3. 获取异常信息

⭐
3.1 assert:
断言:assert +表达式 (表达式返回一个bool值)
我希望是一个什么结果(预期结果) -- 常用元素定位,assert 标签是否存在
如果表达式是False,就会出现异常


练习
1.修改字典中所有键值对的值,新的值为原来的值乘10


2.求1-n所有奇偶数个数及他们的平均值

3.编写程序,键盘输入x和y的值,计算并输出表达式 ln(3x-1)/y的值。要求设置异常处理,对除0、负数求对数两种情况进行异常捕捉处理(math.log)
import math
while True:
try:
x = int(input("请输入x的值:"))
y = int(input("请输入y的值:"))
a = math.log(3 * x - 1) / y
print(a)
except ZeroDivisionError:
print("除数不能为0")
except ValueError:
print("发生异常,函数域U错误")
else:
break
4.定义input_password函数,提示用户输入密码.如果用户输入长度<8,抛出异常,如果用户输入长度>=8,返回输入的密码
5.写⼀个⽅法sanjiao(a, b, c),判断三个参数是否能构成⼀个三⾓形,如果不能则抛出异常Exception,
显⽰异常信息a,b,c”不能构成三⾓形”,如果可以构成则显⽰三⾓形三个边长,在⽅法中得到命令⾏输⼊的三个整数,调⽤此⽅法,并捕获异常
def sanjiao(a,b,c):
if a+b>c and a+c>b and b+c>a:
print(a,b,c)
else:
raise Exception("不能构成三角形")
sanjiao(3,4,5)
sanjiao(3,9,1)
6.从命令行得到5个整数,放入列表中,然后打印输出,要求:
如果输入数据不为整数,要捕获产生的异常,显示“请输入整数”
捕获输入参数不足5个的异常(越界),显示“请输入最少5个整数”
def option_ls():
list_1 = []
for i in range(5):
try:
j = int(input("请输入整数:"))
except:
print("请输入整数!")
else:
list_1.append(j)
if len(list_1) !=5:
raise Exception("请输入至少五个整数!")
option_ls()
7.编写代码调用CCircle方法,计算圆面积,定义一个异常,如果半径为 抛出异常
class RadioError(Exception):
def __init__(self,msg):
super().__init__(msg)
self.msg = msg
import math
def round():
try:
a = int(input("请输入半径:"))
if a<0:
raise RadioError("半径必须大于0")
else:
print(a**2*math.pi)
except RadioError as e:
print(RadioError,e)
except ValueError:
print("请输入数字类型")
round()
3⃣️ Debug



查看数据类型:

Ⅳ 函数与代码复用
第 6 章. 函数与代码复用
看下面一段伪代码:
if cpu使用率 >80%: 连接邮箱 发送邮件 关闭邮箱 if 内存使用率 >80%: 连接邮箱 发送邮件 关闭邮箱 if 硬盘使用率 >80%: 连接邮箱 发送邮件 关闭邮箱
思考这段代码有什么问题?
1⃣️ 函数的概念
函数是一段具有特定功能的,可重用的语句组,用函数名来表示并通过函数名进行完成功能调用。
函数也可以看作是一段具有名字的子程序,可以在需要的地方调用执行,不需要再在每个执行地方重复编写这些语句。每次使用函数可以提供不同的参数作为输入,以实现对不同数据的处理;函数执行后,还可以以反馈相应的处理结果。
函数是一种功能抽象。
2⃣️ python中函数的定义
Python 定义一个函数使用 def 关键字,语法形式如下:
def <函数名>(<参数列表>): <函数体> return <返回值列表>
函数名的命名规范:只能由数字字母下划线组成,不能用数字开头 命名风格:尽量简短、见名知意,推荐使用下划线命名法(每个单词之间用下划线连接) 注意点:不能和python中的关键字重名,也不要和python中的内置函数重名(如果重名会覆盖内置函数)
实例:生日歌
过生日时要为朋友唱生日歌,歌词为:
Happy birthday to you! Happy birthday to you! Happy birthday,dear<名字> Happy birthday to you!
编写程序为 Mike 和 Lily 输出生日歌。最简单的方式是重复使用 print() 语句
# 最简单的方式
print('Happy birthday to you!')
print('Happy birthday to you!')
print('Happy birthday, dear Mike!')
print('Happy birthday to you!')
print('Happy birthday to you!')
print('Happy birthday to you!')
print('Happy birthday, dear Lily!')
print('Happy birthday to you!')
Happy birthday to you!
Happy birthday to you!
Happy birthday, dear Mike!
Happy birthday to you!
Happy birthday to you!
Happy birthday to you!
Happy birthday, dear Lily!
Happy birthday to you!
以函数的方式
# 定义函数
def happy():
print('Happy birthday to you!')
def happy_birthday(name):
happy()
happy()
print('Happy birthday, dear {}!'.format(name))
happy()
# 调用函数
happy_birthday('Mike')
print()
happy_birthday('Lily')
Happy birthday to you!
Happy birthday to you!
Happy birthday, dear Mike!
Happy birthday to you!
Happy birthday to you!
Happy birthday to you!
Happy birthday, dear Lily!
Happy birthday to you!
看起来感和上面的直接 print 还多了几行代码,但是考虑如果要给 100 个人唱生日歌的情况。
函数的注释
①函数的注释 与 普通的注释有一定的区别,他描述函数用来做什么,参数的含义,是否有返回值
函数用来做什么?
:param 参数的诠释
:return 函数的返回结果
这样在调用函数时,能更加直观的去理解函数的参数含义以及函数的返回值含义


②调用函数时鼠标移上函数可以看到函数的注释
(补图)
③打印函数的注释信息:print(函数.__doc__)

⭐ 也可以用 ctrl + 左键点击进入函数查看(mac : command + 左键 )
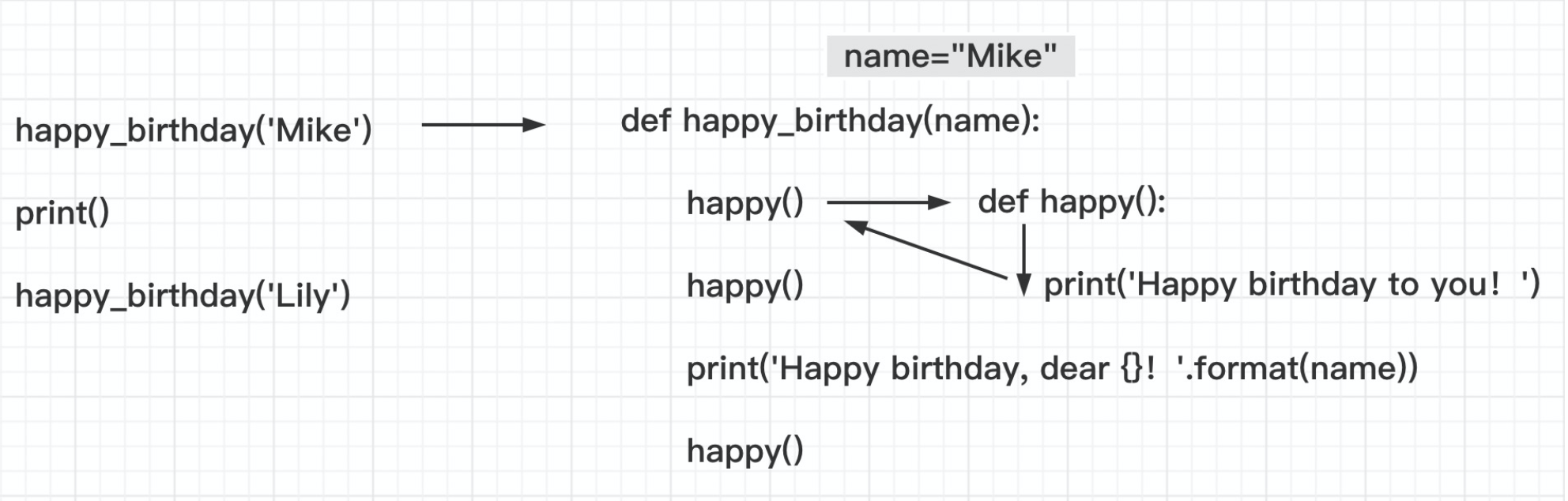
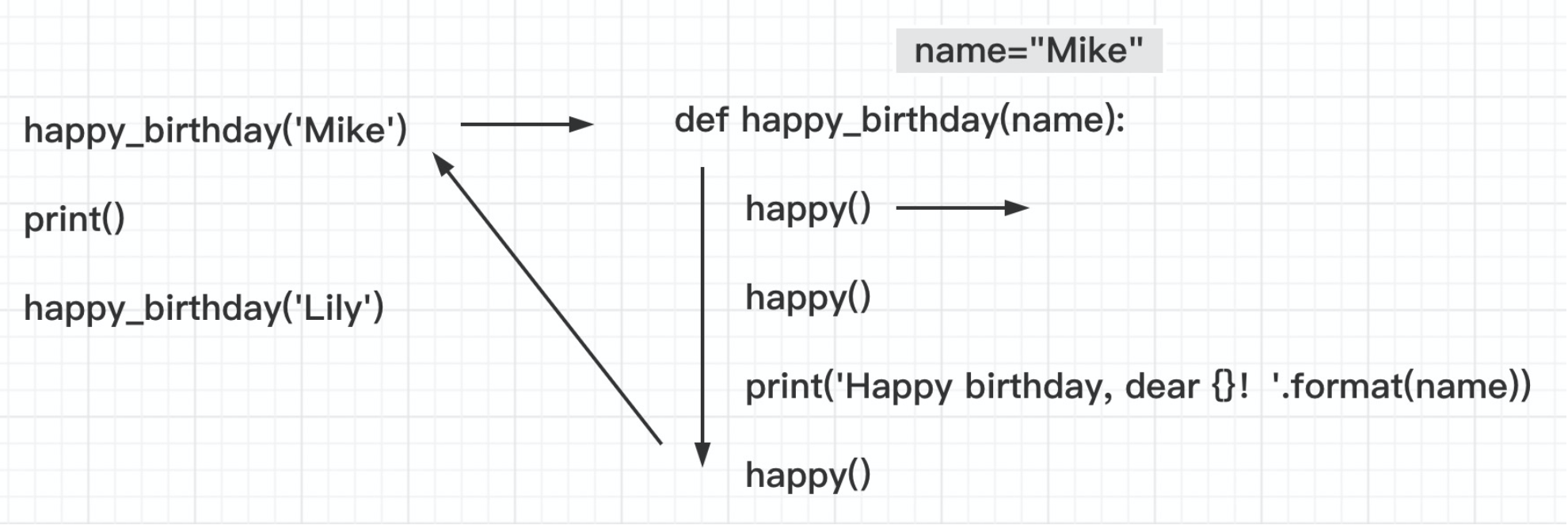
3⃣️ 函数的调用过程
①函数的调用:函数名()
程序调用一个函数需要执行以下四个步骤:
-
调用程序在调用处暂停执行
-
在调用时将实参赋值给函数的形参
-
执行函数体语句
-
函数调用结束给出返回值,程序回到调用前的暂停处继续执行
上面的 happy_birthday 函数的调用过程

②函数的嵌套
1)一个函数内可以直接调用另一个函数
# ①函数的嵌套调用
def fun1():
print("桃花开了")
def fun2():
print("梅花开了")
fun1() # 调用fun1函数
fun2()
梅花开了
桃花开了
注意:函数执行原理顺序
- 顶格代码 同级别:从上到下依次执行。
- 缩进代码:函数体代码,只有在函数调用的时候才会执行。


2)函数相互调用会死循环
def fun1():
print("桃花开了")
fun2()
def fun2():
print("梅花开了")
fun1() # 调用fun1函数
3)python中 函数内可以定义函数,也可以直接调用
# ②函数的嵌套定义与调用
def fun3():
print("今天天气真好~~")
def fun4():
print("可以去踏青了~~")
fun4() # 嵌套调用fun4函数
print("调用fun3会打印几句话?")
fun3()
今天天气真好~~
可以去踏青了~~
调用fun3会打印几句话?
4)断点调试

4⃣️ 函数的返回值:return
4.1)返回值
函数还有一个很重要的功能就是返回结果。
python 中使用 return 关键字来退出函数,返回到函数被调用的地方继续往下执行。
return 可以将 0 个,1 个,多个函数运算完的结果返回给函数被调用处的变量。
函数可以没有返回值,也就是说函数中可以没有 return 语句,这时函数返回 None,例如上面我们定义的那些函数。

None - 调用函数并将函数值打印出来 - 结果为None

有返回值 - 调用函数,并将函数值打印出来 - return后的结果
return 会将多个返回值以元组的形式返回。
案例:
定义一个函数接收 2 个或多个数值,并返回它们的和。
def add(x,y,*args):
x += y
for i in args:
x += i
return x
res = add(1,2)
print(res)
3
定义一个函数接收被除数 x 和除数 y,返回它们的商和余数。
def my_mod(x,y):
res1 = None
res2 = None
if x < y:
res1 = x
res2 = 0
else:
i = 0
while x >= y:
x = x-y
i += 1
res1 = i
res2 = x
return res1, res2
res = my_mod(10,3)
print(res)
(3, 1)
⭐如果return多个结果可以用多变量接收
⭐如何获取函数的返回结果,也就是return的值
方法一:定义变量接收值
a = my_mod(10,3) print(a)
方法二:直接用print()打印函数调用的结果
print(my_mod(10,3))
注意:
-函数里不会有print这种语句,需要哪个数据给别人用可定义为返回值。
-也不会有input这种语句,用户输入的数据可以通过传参的参数传入。

5️⃣ 函数的参数
定义函数时 () 里的参数叫形参(形式参数),它只是一个变量名,供函数体中的代码调用。
函数调用时,传入 () 里的参数叫实参(实际参数),它是实际的数据,会传递给形参,供函数体执行。
5.1)形参
定义函数时,形参根据功能不同,可以定义几种类型。
5.1.1 必须参数
在定义函数时,如果要求调用者必须传递实参给这个形参,它就是必须参数。
定义了几个,调用函数时就要传几个。
直接定义在函数名后的 () 中的形参就是必须参数。
例如上面的 happy_birthday 函数中的 name。
案例:
定义一个函数接收两个数,然后打印它们的和
def add(x,y):
print(x+y)
add(1) # 调用时必须传递实参给必须参数,否则报错
TypeError Traceback (most recent call last)
in
----> 1 add(1) # 调用时必须传递实参给必须参数,否则报错
TypeError: add() missing 1 required positional argument: 'y'
5.1.2 默认参数(缺省参数)
在定义函数时,某些形参有可能在调用时不用接收实参,这种情况可以定义为默认参数。
在函数名后 () 中,以 参数名=默认值 的形式定义的形参就是默认参数。
注意:默认参数必须定义在必须参数的后面
案例:
定义一个函数,它接收两个参数 content 和 times,
content 是函数要打印的内容
times 是函数打印的次数,如果不传递 times 默认打印 1 次
# 定义
def my_print(content, times=1):
for i in range(times):
print(content)
# 调用
my_print('happy birthday!')
my_print('happy birthday!', 2)
happy birthday!
happy birthday!
happy birthday!
调用函数时传递实参给默认形参会覆盖默认值。
⭐ 1.有默认值的参数,在定义的时候一定要写到最后面
2.如果两种 传参形式 混合使用,位置参数写前面,指定参数名传参写后面
3.如果两种 传参形式 混合使用,同一参数不能传递两次
5.1.3 不定参数
在定义函数时,不确定在调用时会传递多少个实参时,可以定义不定参数。
不定参数根据传递实参的不同(详见 4.2 实参)有分为两种。
位置不定参
在函数名后的 () 中,在形参前加 * 号可以定义位置不定参,通常它会定义为 *args。
它用来接收函数调用时,以位置参数传递过来的超过形参数量的多余的实参。
注意:不定参必须定义在默认参数后面【❄不一定要放在最后,放在何处,前面的参数接收完剩下的都归他。】
位置不定参数会将所有多余的位置实参创建成元组。
def func(a, *args):
print(args,type(args))
func(1,2,3,4)
(2, 3, 4) <class 'tuple'>

案例:
定义一个函数,接收 2 个以上的数,打印它们的和。
def add(x,y,*args):
x += y
for i in args:
x += i
print(x)
add(1,2,3,4)
10
关键字不定参
在函数名后的 () 中,在形参前加 ** 号可以定义关键字不定参,通常它会定义为 **kwargs。
它用来接收函数调用时,以关键字参数传递过来的超过形参数量的多余的实参。
注意:不定参必须定义在默认参数后面
关键字不定参数会将所有多余的关键字实参创建成字典。
def func(a, **kwargs):
print(kwargs,type(kwargs))
func(a=1,b=2,c=3,d=4)
{'b': 2, 'c': 3, 'd': 4} <class 'dict'>
⭐可以打印,打印要去星花

5.2)实参
调用函数时传递实参有两种方式。
5.2.1 位置参数
调用函数时,传递实参时默认会按照形参的位置一一对应,这种实参传递叫做位置参数。
案例
定义一个函数实现打印一个数的 n 次幂。
def my_power(x, n):
print(x**n)
my_power(3,2)
my_power(2,3)
9
8
5.2.2 关键字参数(指定参数)
调用函数时,传递实参时以 形参名=实参 的形式传递参数,叫做关键字参数。
这时不用考虑参数的位置。
注意:关键字参数必须写在位置参数后面。
案例
使用关键字参数调用上面的案例
my_power(x=3,n=2) my_power(n=2,x=3) my_power(3,n=2)
9
9
9
my_power(n=2,3)
File "", line 1
my_power(n=2,3)
^
SyntaxError: positional argument follows keyword argument
5.2.3 *,** 在传递实参时的用法
* 解包
在传递实参时,可以通过 * 对迭代对象列表、元组进行解包。
def fun(a,b,*arg):
print(a,b,arg)
ls = [1,2,3,4,5,6]
fun(*ls) # => fun(1,2,3,4,5,6) ⭐=>fun(ls[0],ls[1],ls[2],ls[3],ls[4],ls[5])
1 2 (3, 4, 5, 6)
⭐ * 表示传入的是元组
def fun1(*args): print(args) print(type(args)) print(args[0])
fun1(1, 2, 3, 4, 5)
(1, 2, 3, 4, 5)
<class 'tuple'>
1
** 解包
在传递实参时,可以通过 ** 对字典对象进行解包。
def fun(a,b, **kwargs):
print(a,b,kwargs)
d = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
fun(**d) # => fun(a=1,b=2,c=3,d=4)
1 2 {'c': 3, 'd': 4}
⭐ ** 表示传入的是一个字典
def fun2(**kwargs): print(kwargs) print(type(kwargs)) print(kwargs["name"]) fun2(name="花花",addr="长沙")
{"name":"花花", "addr":"长沙"}
<class 'dict'="">
花花

练习
1.简单题
2.封装一个可以打印任意比例正方形的函数
3.封装一个计算器函数



4.定义一个可以完成任意个数字相加的函数


5.实现学生管理系统,完成对学员的增,删,改,查和退出学生管理系统。
"""
实现学生管理系统,完成对学员的增,删,改,查和退出学生管理系统。
要求1:使用一个list用于保存学生的姓名。
要求2:输入0显示所有学员信息,1代表增加,2代表删除,3代表修改,4代表查询,exit代表退出学生管理系统。每一个功能定义一个自定义函数。界面如下:
系统界面如下:
-----------------------欢迎进入V220班学生管理系统-----------------------------
请选择系统功能:
0:显示所有学员信息
1:添加一个学员信息
2:删除一个学员信息
3:修改一个学员信息
4:查询一个学员信息
exit:退出学生管理系统
(0)输入0后效果如下:
0
["那棵草","下个路口见"..]
(1)输入1后效果如下:
1
请输入增加人的姓名:南一
["那棵草","下个路口见",'南一'..]
(2)输入2后效果如下:
2
请输入删除人的姓名:南一
["那棵草","下个路口见"..]
(3)输入3后效果如下:<注意:如果list中没有这个学员则打印:V217班没有这个学员>
3
请输入需要修改人的姓名:下个路口见
请输入需要修改后的姓名:小蓝紫
["那棵草","小蓝紫"..]
(4)输入4后效果如下:<注意:如果list中没有这个学员则打印:V217班没有这个学员>
请输入查询人的姓名:那棵草
那棵草在座位号(0<下标>)的位置。
(5)输入exit后效果如下:
exit
欢迎使用V220的学生管理系统,下次再见。
"""
mylist = ["那棵草","下个路口见"]
str1 = """
-----------------------欢迎进入V220班学生管理系统-----------------------------
请选择系统功能:
0:显示所有学员信息
1:添加一个学员信息
2:删除一个学员信息
3:修改一个学员信息
4:查询一个学员信息
exit:退出学生管理系统
"""
def getallinfo():
print("所有学员信息:",mylist)
caozuo(input(str1+"请输入你的选择:"),mylist)
def addinfo():
name = input("请输入增加人的姓名:")
if name in mylist:
print("{}名字已存在,请添加不同的名字".format(name))
else:
mylist.append(name)
print("新增学员后的信息:",mylist)
caozuo(input(str1+"请输入你的选择:"), mylist)
def delinfo():
delname = input("请输入要删除人的姓名:")
if mylist.count(delname)>0:
mylist.remove(delname)
print("删除学员后的信息:",mylist)
else:
print("V217班没有这个学员!")
caozuo(input(str1+"请输入你的选择:"), mylist)
def updateinfo():
oldname = input("请输入要修改人的姓名:")
newname = input("请输入要修改后的姓名:")
if mylist.count(oldname)>0:
mylist[mylist.index(oldname)] = newname
print("修改后的学员信息:",mylist)
else:
print("V217班没有这个学员!")
caozuo(input(str1+"请输入你的选择:"), mylist)
def selectinfo():
selectname = input("请输入要查询人的姓名:")
if mylist.count(selectname)>0:
print("{}在座位号({}<下标>)的位置。".format(selectname,mylist.index(selectname)))
else:
print("V217班没有这个学员!")
caozuo(input(str1+"请输入你的选择:"), mylist)
def caozuo(num,mylist):
if num == "0":
getallinfo()
elif num == "1":
addinfo()
elif num == "2":
delinfo()
elif num == "3":
updateinfo()
elif num == "4":
selectinfo()
elif num == "exit":
print("欢迎使用V220的学生管理系统,下次再见。")
else:
print("输入不正确,请重新输入!")
caozuo(input(str1+"请输入你的选择:"),mylist)
caozuo(input(str1+"请输入你的选择:"),mylist)
6️⃣ lambda 函数
简单来说,lambda 函数用来定义简单的,能够在一行内表示的函数。
语法格式如下:
lambda 参数:逻辑
lambda arg1,arg2,... : expression
案例
f = lambda x,y : x + y res = f(1,2) print(res)
3lambda 函数一般不会直接定义,通常是作为参数传递给其他函数作为参数使用。
或
res = (lambda x,y : x+y)(1,2) res = (函数)(传参)
⭐:前定义函数参数,:后是返回值
⭐ :打印圆周率
import math
p = math.pi print(p) # 可以打印圆周率
⭐:函数的本体
res = lambda r:pow(r,2) * math.pi print(res) # 打印函数的本体,函数所在的内存地址 print(res(r=5))
⭐:普通函数 - 匿名函数(+内置函数) - 结合函数

1. 序列调用匿名函数


2. 内置函数map使用


3. 匿名函数在自动化中的使用

7️⃣ 变量作用域
python 中一个变量能够被访问的范围叫做作用域。根据作用域的大小简单的分为全局变量和局部变量。
7.1)全局变量
python 是解释型编程语言,解释器在运行一个 python 程序时会在计算机内存中申请一块内存用来运行这个程序。全局变量在这块内存空间中都可以被访问和修改。
直接定义在函数外的变量就是全局变量,在程序运行的全过程有效。
7.2)局部变量
定义在函数里的变量就是局部变量,它只在它定义的函数里起作用,一旦函数执行完毕它就不存在了。
⭐一个模块就是一个.py文件

案例
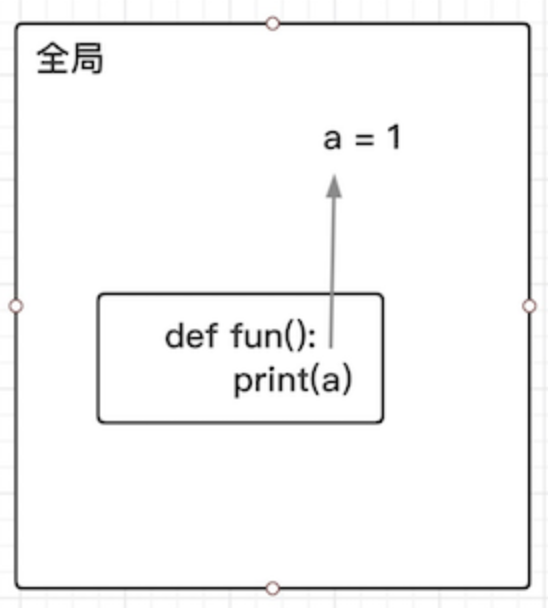
a = 1 # 全局变量
def fun():
print(a)
fun()
1
①上面的案例说明全局变量能够在函数里访问。
②全局变量也能在函数外访问
def fun():
b = 2 # 局部变量
print(b)
fun()
print(b)
2
NameError Traceback (most recent call last)
in
4
5 fun()
----> 6 print(b)
NameError: name 'b' is not defined
③上面的案例说明局部变量在函数外部不能直接访问
⭐ ④函数外部可以直接修改全局变量 a = 100 a = a + 200 print(a)
*****************************************************************
a = 1
def fun():
a += 1 # 尝试直接在函数内部修改全局变量
print(a)
fun()
UnboundLocalError Traceback (most recent call last)
in
4 a += 1 # 尝试直接在函数内部修改全局变量
5 print(a)
----> 6 fun()
in fun()
2 def fun():
3
----> 4 a += 1 # 尝试直接在函数内部修改全局变量
5 print(a)
6 fun()
UnboundLocalError: local variable 'a' referenced before assignment
⑤上面的案例说明在函数内部不能直接修改全局变量(不可变数据类型)
⑥可变数据类型的动态添加或删除等修改数据不受影响(⭐因为没有改变全局变量指向的内存地址),所以可变类型的全局变量在使用的过程中需要格外的注意
a = [1,2]
def func():
a[0] = 2
print(a)
func()
print(a)
[2, 2]
[2, 2]
7.3)global 关键字
函数外部可以修改全局变量。
有时候需要在函数内部修改全局变量。
⑦使用 globals 关键字可以在函数内部修改全局变量
案例1:
a = 1 # 全局变量
def fun():
# global要放在第一行
global a # 申明 a 是全局变量
global b # 全局变量要先声明,后定义
b = 4
a += 1 fun() print(a) print(b)
2
4
案例2:
a = 1 # 全局变量
def fun():
# global要放在第一行
global a # 申明 a 是全局变量
global b # 全局变量要先声明,后定义
b = 4
a += 1 print(b) # 先print b 再调用函数,会报错,因为b没有先定义,函数的执行逻辑:从上往下,由内而外
fun()
7.4)变量访问优先级
⑧函数内部访问变量,优先查找局部变量,如果局部变量中没有,才会引用全局变量。
⭐因为自定义的函数,在当前模块中优先级高于内置函数,所以自定义的函数和内置函数重名会覆盖掉内置函数
8️⃣ python 内建函数
python 解释器提供了 70 多个内置函数。
⭐小写的就是全局内建函数和类

8.1)基本数据类型类(转换函数)
8.1.1 int
-
int([x]) -> integer
-
int(x, base=10) -> integer
将一个数字或字符串转换成整数。
如果 x 不是一个数字,那么它必须是和 base 匹配的整数字符串表达式
int(1.1)
1
int('1')
1
int('0b0101',2)
5
int('0x11',16)
17
int('0o11',8)
9
8.1.2 float
将一个字符串或数字转换为浮点数。
float(123)
123.0
float('1.2')
1.2
判断是否浮点数:
print(isinstance(1.0, float))
True
8.1.3 complex
-
complex(real=0, imag=0)
创建一个复数通过实部和虚部
complex(10,8)
(10+8j)
8.1.4 str
-
str(object='')
通过给定的对象创建一个新的字符串对象。
str(1)
'1'
str([1,2,3])
'[1, 2, 3]'
str({'name':'xinlan'})
"{'name': 'xinlan'}"
8.1.5 list
-
list(iterable=())
根据传入的可迭代对象创建一个列表,如果没有参数返回空列表
list()
[]
list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list('abcde')
['a', 'b', 'c', 'd', 'e']
8.1.6 tuple
-
tuple(iterable=())
根据传入的可迭代对象创建一个元组,如果没有参数返回空元组
tuple()
()
tuple('abcd')
('a', 'b', 'c', 'd')
8.1.7 set
-
set(iterable)
根据传入的可迭代对象创建一个集合对象。
set('abc')
{'a', 'b', 'c'}
set(range(10))
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
8.1.8 dict
根据传入的参数创建一个字典对象
# 形如(key, value)的键值对数据
dict([('name','xinlan'),('age',18)])
{'name': 'xinlan', 'age': 18}
# 关键字参数 dict(name='xinlan',age=18)
{'name': 'xinlan', 'age': 18}
8.1.9 bool
bool()

8.2)常用内建函数_1
8.2.1 print
-
print(value,..,sep=' ', end='\n')
-
value 会打印 value 的字符串形式
-
sep 分隔符,当有多个 value 时默认用空格作为分割
-
end 每次打印在最后默认添加回车换行符
-
打印传入对象的字符串形式
print(1,2,3,sep=',')
1,2,3
print(1,end='') print(2)
12
8.2.2 input
接收用户的输入数据,以字符串的形式返回。
可以接收字符串参数作为提示信息输出
input('>>>:')
:aaa
'aaa'
8.2.3 type
-
type(object)
返回 object 的类型
type(1)
int
8.2.4 dir
-
dir([object])
返回传入对象的所有属性和方法名的列表
8.2.5 help
-
help(builtins.object)
返回内建对象的帮助信息
help(help)
Help on _Helper in module _sitebuiltins object:
class _Helper(builtins.object)
| Define the builtin 'help'.
|
| This is a wrapper around pydoc.help that provides a helpful message
| when 'help' is typed at the Python interactive prompt.
|
| Calling help() at the Python prompt starts an interactive help session.
| Calling help(thing) prints help for the python object 'thing'.
|
| Methods defined here:
|
| call(self, *args, kwds)
| Call self as a function.
|
| repr**(self)
| Return repr(self).
| Data descriptors defined here: |
| dict |
| dictionary for instance variables (if defined) |
| weakref |
| list of weak references to the object (if defined) |
8.2.6 len
-
len(obj)
返回容器的元素个数
len([1,2,3])
3
8.2.7 hash
-
hash(obj)
返回对象的 hash 值
hash('a')
3636161774609400683
8.2.8 iter
-
iter(iterable)
根据传入的可迭代对象返回一个迭代器
iter('abcd')
<str_iterator at 0x7f98b7dd2eb0>
8.2.9 id
-
id(obj)
返回传入对象的身份 id(虚拟内存地址的整数形式)
id(1)
4344134656
8.2.10 range
-
range(stop) -> range object
-
range(start, stop[,step])
返回一个 range object 对象,产生整数序列
range(10)
range(0, 10)
range(0,10,2)
range(0, 10, 2)
更多方法详见官方文档
8.3)常用内建函数_2
8.3.0 数学函数
abs() 绝对值
divmod() 返回商和余数
round() 四舍五入(银行家算法)
pow() 次方
sum() 求和
min() 最小值
max() 最大值




8.3.1 min
min((1,2,3,4,5)) min([1,2,3,4,5])
8.3.2 max
max((1,2,3,4,5)) max([1,2,3,4,5])
8.3.3 sum
sum((1,2,3,4,5)) sum([1,2,3,4,5]) sum(dic.values())
8.3.4 eval
识别字符串中有效的python表达式




其他脱引号方法:Python 字符串脱引号的三大法宝(eval,literal_eval,json.loads)详解 - 测试派
8.3.5 zip
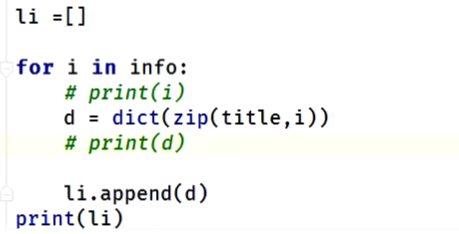
聚合打包

⭐以索引相组合,以最短的列表为基,进行聚合
案例

练习
1.格式转换


2.zip应用


3.写函数,接收两个数字参数,返回最大值
例如:
传入:10,20
返回:20
def get_max(a,b):
mmax = a
if b>a:
mmax = b
return mmax
def getmax(*args):
lst = []
for i in args:
lst.append(i)
return max(lst)
print(getmax(*(1,2,3,4,5,6)))
print(get_max(1,2))
4.写函数,获取传入列表的所有奇数位索引对应的元素,并将其作为新列表返回。
例如:
传入:[34,23,52,352,352,3523,5]
返回:[23,352,3523]
def x(*args):
return args[1::2]
print(list(x(*[34,23,52,352,352,3523,5])))
def getnewlist(mylist):
list1 = []
for i in range(0,len(mylist)):
if i%2!=0:
list1.append(mylist[i])
return list1
print(getnewlist([34,23,52,352,352,3523,5]))
5.写函数,判断用户传入的对象(列表)长度是否大于5,如果大于5,那么仅保留前五个长度的内容并返回。不大于5返回本身。
例如:
传入1:[34,23,52,352,666,3523,5] 返回1:[34,23,52,352,666]
传入2:[34,23,52] 返回2:[34,23,52]
def f(*args):
if len(args)>5:
return args[:5]
else:
return args
print(list(f(*[34,23,52,352,666,3523,5] )))
print(list(f(*[34,23,52] )))
def get5len(mylist):
list1 = []
if len(mylist)>5:
for x in range(5):
list1.append(mylist[x])
else:
list1=mylist
return list1
print(get5len([34,23,52,352,666,3523,5] ))
print(get5len([34,23,52] ))
6.写函数,检查传入的字符串是否含有空格,并返回结果,包含空格返回True,不包含返回False
例如:
传入:"hello world"
返回:True
def isstrip(str1):
a = False
for x in str1:
if x==' ':
a = True
break
return a
print(isstrip("hello world!"))
7.写函数,接收n个数字,分别写4个函数求n数字的和、差、商、积
def sum1(*args):
res = 0
for n in args:
res += n
return res
def sub1(num1,*args):
res = num1
for n in args:
res -= n
return res
def mult(*args):
res = 1
for n in args:
res *= n
return res
def div1(num1,*args):
res = num1
for n in args:
res /= n
return res
9️⃣ 装饰器
1. 函数的传递
python中可以把函数当作变量传递
def fun1():
print("执行了fun1函数")
def fun2(fun_name):
print("我是第二个函数的打印")
fun_name() # 等同于fun1()
fun2(fun_name=fun1)
# fun2(fun_name=fun1()) # 报错(先执行fun1()完成打印,再把fun1()执行的结果None传给了fun_name,fun_name=None,那么fun_name() = None())
⭐函数的调用与引用:
调用:在函数后面加一个小括号() -- 语法,就是在执行对应的函数,跑函数里面的代码
引用:不加小括号,直接写函数命,这叫函数的本体
2. 函数的嵌套


⭐ python中一个函数的内部还可以定义函数


3. 装饰器


⭐
简化掉所有流程,只要遇到@符号,就去找同名函数,如果有的话就先去执行同名函数
装饰器是针对函数执行的增强,增强:就是在函数执行的前面或后面插入一段代码
装饰器的语法规则:在函数头上加 @装饰器名称
目的:对原来定义好的方法(函数)进行增强
import logging
logging.basicConfig(level=logging.DEBUG)
def log_info(fun_name):
def wra():
logging.info('执行内部函数')
return fun_name() # 返回fun_name参数本体
# ②return fun_name
return wra # 返回了wra函数本体
@log_info
def fun5():
print("fun5函数执行了。。。")
fun5() # ②fun5()() # 没有人用
结果:
INFO:root:执行内部函数
fun5函数执行了。。
# 写了@log_info后,会默认把fun5当作参数传递给log_info,会默认去调用wra,这是装饰器的规则
# 执行fun5()函数,在执行之前,通过装饰器完成日志的打印,再去执行它

⭐ 装饰器真正的原理(原则)
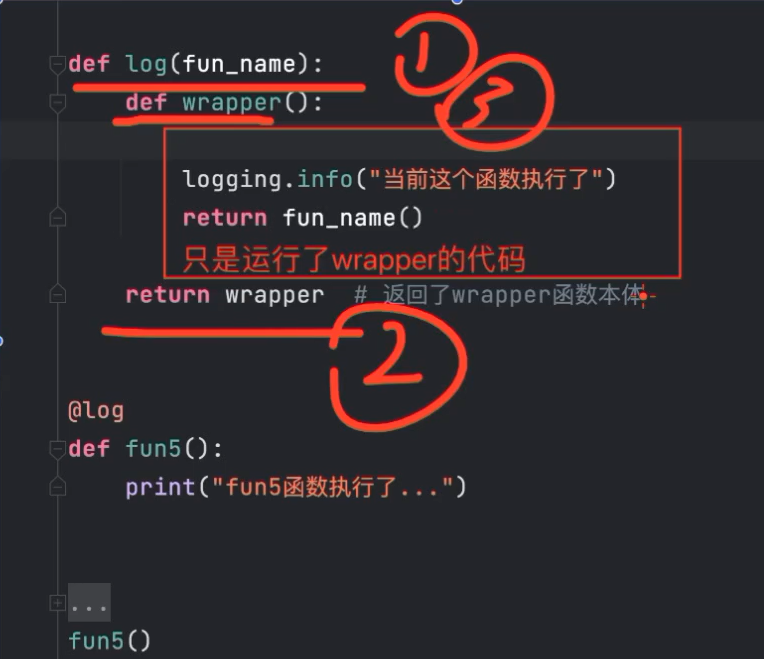
案例:
① 案例

②被装饰函数-带参


练习:
1.请实现一个装饰器,把函数的返回值+100然后返回
def fun1(value):
def warpper(value):
ret = print(value+100)
return ret
return warpper
@fun1
def fun(num):
print("函数执行加100操作")
fun(5)
2.请实现一个装饰器,通过一次调用使函数重复执行5次
def fun2(value):
def warpper(*args,**kwargs):
for i in range(5):
value(*args,**kwargs)
return warpper
@fun2
def fun():
print("重复执行函数")
fun()
3.请实现一个装饰器,每次调用函数时,将函数名字以及调用此函数的时间点写入文件中
import time
def fun3(value):
def warpper(*args,**kwargs):
with open(r'D:\AutoTest\P_test\txt1',encoding='utf-8',mode='a+') as f:
stime = time.localtime()
f.write("时间:{} 函数名:{}\n".format(time.strftime("%Y-%m-%d %H-%M-%S",stime),value.__name__))
print("时间:{} 函数名:{}".format(time.strftime("%Y-%m-%d %H-%M-%S",stime),value.__name__))
ret = value(*args,**kwargs)
return ret
return warpper
@fun3
def fun():
print("执行")
fun()
4.判断函数中被传入的数据类型——
# 编写装饰器,条件如下:
#1)确保函数接收到的每一个参数都是证书;
#2)如果参数不是整型数,打印TypeError:参数必须为整型(提示。。。)
如:if not isinstance(i,int):
# print('函数所有的参数并非都是int型')
def wapper(value):
def inner(*args,**kwargs):
for i in args:
if not isinstance(i,int):
print('函数不是int型')
break
else:
res = value(*args,**kwargs)
print("函数是int型")
return res
return inner
@wapper
def fun(num):
return num
fun(34.3)
5.冒泡排序(不考虑时间复杂度)

6.用户输入月份,判断这个月是哪个季节(for循环实现)


7.列表去重(不用sort)


Ⅴ 文件操作
第 7 章. 文件操作
壹-文件概述
1. 什么是文件
计算机文件是一个存储在存储器上的数据序列,可以包含任何数据内容。
概念上,文件是数据的集合和抽象。
用文件形式组织和表达数据更有效也更为灵活。
文件包括两种类型:文本文件和二进制文件。
文件本质上都是存储在存储器上的二进制数据。
使用 HexEditor 可以以 16 进制的方式打开任何文件。

特别的文本文件遵循统一的字符编码,在打开时,计算机会根据字符编码解析成编码表上对应的字符。
二进制文件和文本文件本质上没有区别,只是没有统一的编码,需要根据特定的程序进行解析和运行。
无论是文本文件还是二进制文件都可以用"文本文件方式"和"二进制文件方式"打开,打开后的操作不同。
2. 字符编码
计算机底层只能表示二进制信息,不能直接表示文字。计算机显示给我们看的文字可以看做是很小的一张张字符的图片。但如果文字都以图片进行存储和传输,图片体积非常大,从而效率会变得很低。
所以计算机科学家将这些单个字符图片放到一个文件中,这个文件就是字体文件。再给每个字符一个编号,存储传输时就用字符的编号。这个编号表就是字符编码(简单这么理解)。
文本文件存储的就是每个字符的编号,计算机在打开文本文件时,会根据指定的编码,去编码表中查询一个一个的字符,再渲染给用户。
2.1 ascii 码
因为历史原因,字符编码有很多。最先发明的是 ascii 码。
总共 127 个字符,因此使用一个字节(8 位二进制)来表示,也即是一个字符占一个字节的大小。

在记事本中键入 abc123+-*/,然后使用 HexEditor 打开后发现跟上面的编码表是一致的。

2.2 gb2312
可以看到 ascii 码里只有英文字母和常见字符,没有中文,以及世界上其他国家的文字。随着计算机的发展,各国都创建了自己国家的计算机字符编码。
1980 年中国发布了 gb2312, GB2312 是一个简体中文字符集,由 6763 个常用汉字和 682 个全角的非汉字字符组成。
gb2312 使用两个字节表示一个汉字。
通过字符串的 encode 方法可以根据字符编码进行编码
'中'.encode('gb2312')
b'\xd6\xd0'
2.3 gbk
GB2312 的出现,基本满足了汉字的计算机处理需要,但对于人名、古汉语等方面出现的罕用字,GB 2312 不能处理,这导致了后来 GBK 及 GB18030 汉字字符集的出现。
GBK 即汉字内码扩展规范,K 为扩展的汉语拼音中“扩”字的声母。GBK 编码标准兼容 GB2312,共收录汉字 21003 个、符号 883 个,并提供 1894 个造字码位,简、繁体字融于一库。
gbk 也是使用两个字节表示一个汉字。
'中'.encode('gbk')
b'\xd6\xd0'
'囙'.encode('gb2312')
UnicodeEncodeError Traceback (most recent call last)
in
----> 1 '囙'.encode('gb2312')
UnicodeEncodeError: 'gb2312' codec can't encode character '\u56d9' in position 0: illegal multibyte sequence
'囙'.encode('gbk')
b'\x87\xe0'
2.4 unicode
世界上存在着多种编码方式,同一个编码值,在不同的编码体系里代表着不同的字。要想打开一个文本文件,不但要知道它的编码方式,还要安装有对应编码表,否则就可能无法读取或出现乱码。
我上大学时玩电脑游戏最大的问题就是乱码。
以日文的编码方式创建一个文本文件写入 やめて,然后用记事本打开会显示如下:

这个问题促使了 unicode 码的诞生。
unicode 将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。
Unicode 固然统一了编码方式,但是它的效率不高,比如 UCS-4(Unicode 的标准之一)规定用 4 个字节存储一个符号,那么每个英文字母前都必然有三个字节是 0,这对存储和传输来说都很耗资源。
将之前写有 abc123+-*\ 的文件用记事本另存为 unicode 会发现文件的体积大了一倍。(本来应该是 4 倍,windows 做了优化)


2.5 utf-8
为了提高 Unicode 的编码效率,于是就出现了 UTF-8 编码。UTF-8 可以根据不同的符号自动选择编码的长短。比如英文字母可以只用 1 个字节就够了。"汉"字的 Unicode 编码是 U+00006C49,然后把 U+00006C49 通过 UTF-8 编码器进行编码,最后输出的 UTF-8 编码是 E6B189。utf-8 中汉字使用 3 个字节存储。
'a'.encode('utf-8')
b'a'
'中'.encode('utf-8')
b'\xe4\xb8\xad'
注意为了统一 python3 在内存中所有的字符都采用 unicode。
贰-python 操作文件
python 提供内置函数 open()实现对文件的操作。
python 对文本文件和二进制文件采用统一的操作步骤,和把大象放冰箱里的一样分三步,"打开-操作-关闭。"


1. open 函数
open(file, mode='r', encoding=None)
打开文件并返回对应的 file object。如果该文件不能打开,则触发 OSError。
-
file 包含文件名的字符串,可以是绝对路径,可以是相对路径。
-
mode 一个可选字符串,用于指定打开文件的模式。默认值
r表示文本读。 -
encoding 文本模式下指定文件的字符编码
mode 的取值:
| 字符 | 意义 |
|---|---|
'r' | 文本。取(默认),文件不存在则找不到报错 |
'w' | 文本只写入,并先清空文件(慎用),文件不存在则创建 |
'x' | 文本写,排它性创建,如果文件已存在则失败 |
'a' | 文本只写,如果文件存在则在末尾追加,不存在则创建 |
和 mode 组合的字符
| 字符 | 意义 |
|---|---|
'b' | 二进制模式,例如:'rb'表示二进制读。常用于图片、视频、音频等文档 |
't' | 文本模式(默认),例如:rt 一般省略 t |
'+' | 读取与写入,例如:'r+' 表示同时读写 |

⭐读取模式文件不存在会报错(r rb r+),写入模式文件不存在则创建
2. 读文本文件
在当前目录下创建一个名为 test.txt 的文本文件,(注意编码方式)文件中写入下面的内容:
静夜思 床前明月光,疑是地上霜。 举头望明月,低头思故乡。
2.1 操作基本步骤
-
read(n)
# 读取指定字节长度的内容,不指定长度,默认读取所有的内容
# 打开文件 mode=rt,t可以省略
fb = open('test.txt', 'r', encoding='utf-8')
# 读取
content = fb.read() # read 所有内容,读取后是一个字符串
print(content)
# 关闭文件
fb.close()
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
上面这种操作经常会忘记关闭文件句柄,造成资源浪费,所以处理文件时往往使用 with 语句进行上下文管理。
2.2 with 上下文管理
with open('test.txt', 'r', encoding='utf-8') as fb:
print(fb.read())
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
with 语句执行完毕会自动关闭文件句柄。
2.3 相对路径与绝对路径
进行文件处理时经常会碰到相对路径和绝对路径的问题。
绝对路径好理解,它指定了文件在电脑中的具体位置,以 windows 电脑为例:
d:\lemon\课件\python入门.md
相对路径一般是指相对当前脚本的路径,比如上面的案例中的 test.txt 因为和当前脚本在同一个文件夹下,所以可以直接使用 test.txt 作为文件名来操作。
也可显式的表达当前路径 ./test.txt,./ 表示当前目录。
../ 表示上级目录,同理 ../../ 表示上上级目录,依此类推。
那什么时候使用相对路径,什么时候使用绝对路径呢。
一般情况下项目本身的资源文件和脚本路径相对固定,为了不影响项目的移植性,必须使用相对路径。
如果需要读取操作系统中固定位置的系统文件一般使用绝对路径。




2.4 逐行读取
在读取文本文件时,经常需要按行读取,文件对象提供了多种方法进行按行读取。
-
readline
从文件中读取一行;如果 f.readline() 返回一个空的字符串,则表示已经到达了文件末尾
with open('test.txt', 'r', encoding='utf-8') as fb:
print(fb.readline())
print(fb.readline())
print(fb.readline())
print(fb.readline())
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
练习:读出前十行数据
# ①
for i in range(10):
print(file.readline())
# ②
count = 0
while count < 10:
print(file.readline())
count += 1
# ③读出5到8行的诗句
for i in range(10):
if 5<=i<=8:
print(file.readline())
else:
file.readline() # 只读不打印
-
readlines
以列表的形式返回文件中所有的行。
with open('test.txt', 'r', encoding='utf-8') as fb:
content = fb.readlines()
print(content)
['静夜思\n', '床前明月光,疑是地上霜。\n', '举头望明月,低头思故乡。']
-
迭代
要从文件中读取行,还可以循环遍历文件对象。这是内存高效,快速的,并简化代码:
# 5星推荐
with open('test.txt', 'r', encoding='utf-8') as fb:
for line in fb:
print(line)
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。

3. 读二进制文件
任何文件都可以以二进制读的方式打开,读取 test.txt 的二进制内容。
# mode=rb,不需要encoding参数
with open('test.txt', 'rb') as fb:
content = fb.read()
print(content)
b'\xe9\x9d\x99\xe5\xa4\x9c\xe6\x80\x9d\n\xe5\xba\x8a\xe5\x89\x8d\xe6\x98\x8e\xe6\x9c\x88\xe5\x85\x89\xef\xbc\x8c\xe7\x96\x91\xe6\x98\xaf\xe5\x9c\xb0\xe4\xb8\x8a\xe9\x9c\x9c\xe3\x80\x82\n\xe4\xb8\xbe\xe5\xa4\xb4\xe6\x9c\x9b\xe6\x98\x8e\xe6\x9c\x88\xef\xbc\x8c\xe4\xbd\x8e\xe5\xa4\xb4\xe6\x80\x9d\xe6\x95\x85\xe4\xb9\xa1\xe3\x80\x82'
# 也可以逐行读取,以\n换行符标志
with open('test.txt', 'rb') as fb:
for line in fb:
print(line)
b'\xe9\x9d\x99\xe5\xa4\x9c\xe6\x80\x9d\n'
b'\xe5\xba\x8a\xe5\x89\x8d\xe6\x98\x8e\xe6\x9c\x88\xe5\x85\x89\xef\xbc\x8c\xe7\x96\x91\xe6\x98\xaf\xe5\x9c\xb0\xe4\xb8\x8a\xe9\x9c\x9c\xe3\x80\x82\n'
b'\xe4\xb8\xbe\xe5\xa4\xb4\xe6\x9c\x9b\xe6\x98\x8e\xe6\x9c\x88\xef\xbc\x8c\xe4\xbd\x8e\xe5\xa4\xb4\xe6\x80\x9d\xe6\x95\x85\xe4\xb9\xa1\xe3\x80\x82'
4. 写文本文件
4.1 清除写 w
案例:将锄禾这首诗写入 test.txt 文件中
# mode=w 没有文件就创建,有就清除内容,小心使用
with open('test.txt', 'w', encoding='utf-8') as fb:
fb.write('锄禾\n')
fb.write('锄禾日当午,汗滴禾下土;\n')
fb.write('谁知盘中餐,粒粒皆辛苦。\n')
运行后会发现之前写有静夜思的 test.txt 内容修改为锄禾,因为 w 模式会清除原文件内容,所以小心使用。
4.2 追加写 a
案例:将静夜思这首诗追加到 test.txt 文件中
# mode=a 追加到文件的最后
with open('test.txt', 'a', encoding='utf-8') as fb:
fb.write('静夜思\n床前明月光,疑是地上霜;\n举头望明月,低头思故乡。\n')
追加写,光标在文章最后
案例:将重写后的文件读取出来
方法一:重新打开文件,再读
file = open('13.txt', 'w+', encoding='utf-8')
print(file.read())
方法二:
file = open('13.txt', 'w+', encoding='utf-8') # 如果文件存在,先清空文件,再做其他操作
file.write('醉里簪花')
file.seek(0, 0) # 重新改变光标的位置,(移动位置,相对位置) 相对开头移动0位
print(file.read())
4.3 排他写 x
案例:在当前目录中创建文件 test.txt,存在则不创建
# mode=x
try:
with open('test.txt', 'x', encoding='utf-8') as fb:
fb.write('')
except Exception as e:
print(e)
[Errno 17] File exists: 'test.txt'
5. 写二进制文件
在写模式后加 b 即是写二进制模式,这种模式下写入内容为字节数据。
- 不单独用(rb wb ab xb)
- 不能加encoding="UTF8"
例如:将爬到的图片二进制信息写入文件中。
import requests
url = 'https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1247698508,1430079989&fm=26&gp=0.jpg'
response = requests.get(url)
with open('校花.jpg', 'wb') as f:
f.write(response.content)
6. 读写文件

有时候需要能够同时读写文件,在模式后面加上 + 号即可给读模式添加写,给写模式添加读。
with open('test.txt', 'r+', encoding='utf-8') as f:
# 读文件
print(f.read())
f.write('草\n离离原上草,一岁一枯荣;\n野火烧不尽,春风吹又生!\n')
锄禾
锄禾日当午,汗滴禾下土;
谁知盘中餐,粒粒皆辛苦。
静夜思
床前明月光,疑是地上霜;
举头望明月,低头思故乡。

6.1 复制一个普通的文本文件
指定路径,就在指定路径下复制一个文件
f2 = open('../demo/copy_demo1.py', 'a', encoding='utf-8')
不指定路径,就是在当前的目录下复制一个文件
f2 = open('copy_demo1.py', 'a', encoding='utf-8')


6.2 复制一个非文本文件


7. 案例:python 处理解析 CSV 文件
# 读取csv文件并解析为嵌套列表
data = []
with open('鸢尾.csv', 'r', encoding='gbk') as f:
for line in f:
# 去掉换行符
line = line.strip()
data.append(line.split(','))
data
# 将数据写为csv文件
with open('test.csv', 'w', encoding='utf-8') as f:
for item in data:
f.write(','.join(item) + '\n')
8. 文件指针
open 函数返回的文件对象使用文件指针来记录当前在文件中的位置。
8.1 read 方法
在读模式下,使用文件对象的 read 方法可以读取文件的内容。它接收一个整数参数表示读取内容的大小,文本模式下表示字符数量,二进制模式下表示字节大小。
with open('test.txt', 'r', encoding='utf-8') as f:
content = f.read(3)
print(content)
锄禾
content # 三个字符
'锄禾\n'
with open('test.txt', 'rb') as f:
content = f.read(3)
print(content)
b'\xe9\x94\x84'
'锄'.encode('utf-8') # 三个字节
b'\xe9\x94\x84'
当以读的方式打开文件后文件指针指向文件开头,执行 read 操作之后,根据读取的数据大小指针移动到对应的位置。
8.2 tell 方法
文件对象的 tell 方法返回整数,表示文件指针距离文件开头的字节数。
with open('test.txt', 'r', encoding='utf-8') as f:
print(f.tell())
content = f.read(3)
print(content)
print(f.tell())
0
锄禾
7
content.encode('utf-8')
b'\xe9\x94\x84\xe7\xa6\xbe\n'r 模式打开文件后文件指针指向文件开头,执行 read 操作之后,根据读取的数据大小指针移动到对应的位置。
with open('test.txt', 'a', encoding='utf-8') as f:
print(f.tell())
243a 模式打开文件后文件指针指向文件末尾。
8.3 seek 方法
通过文件对象的 seek 方法可以移动文件句柄
seek 方法接收两个参数:
-
offset 表示偏移指针的字节数
-
whence 表示偏移参考,默认为 0
-
0 表示偏移参考文件的开头,offset 必须是 >=0 的整数
-
1 表示偏移参考当前位置,offset 可以是负数
-
2 表示偏移参考文件的结尾,offset 一般是负数
-
注意文本模式下只允许从文件的开头进行偏移,也即只支持 whence=0
with open('test.txt', 'r', encoding='utf-8') as f:
print(f.read(3))
# 跳转到文件开头
f.seek(0)
# 再读取第一个字
print(f.read(1))
锄禾
锄
with open('test.txt', 'rb') as f:
# 读取文件最后的10字节
f.seek(-10,2)
print(f.read())
b'\xe5\x8f\x88\xe7\x94\x9f\xef\xbc\x81\n
⭐file模式总结

练习

data0 = ['data0','data1','data2','data3']
d = {}
ls = []
for i in range(4):
with open('txt','r+',encoding='utf-8') as f:
content = f.readline()
ls.append(content.strip('\n'))
d = dict(zip(data0,ls))
print(d)


3.创建一个文本,随意输入多行内容,计算一共有多少行
with open(r"D:\AutoTest\P_test\txt1",encoding='utf-8',mode='r') as f:
contents = f.readlines()
print("该文件行数为:{}".format(len(contents)))
4.创建一个txt文本,输入 success,fail,pass
# 面试题:一篇英语文章,求里面一共多少单词,每个单词出现多少次
with open(r"D:\AutoTest\P_test\txt1",encoding='utf-8',mode='r') as f:
contents = f.read()
# print(contents)
lst = contents.replace("\n"," ").split(" ")
# print(lst)
print("pass的数量为:{}".format(lst.count("pass")))
print("fail的数量为:{}".format(lst.count("fail")))
print("success的数量为:{}".format(lst.count("success")))
# 求单词个数? - set不允许重复,能算出单词总数
# 每个单词出现多少次? list.count(set[i])
# 文章还有逗号 句号 等干扰因素要考虑
叁-路径处理
os — Miscellaneous operating system interfaces — Python 3.10.0 documentation

1. os.path.abspath()




2. os.path.dirname()
获取文件或者目录的上级目录


3. os.path.join()
拼接路径
# 获取项目的根路径
BASE_DIR = os.path.dirname(os.paht.dirname(os.path.abspath(__file__)))
print(BASE_DIR)

4. 扩展方法
os.chdir() 切换工作路径 ==> cd
os.mkdir() 在某个目录下创建一个新目录 ==>mkdir
os.rmdir() 删除一个目录 ==>rmdir
os.listdir() 获取当前路径下的目录列表,返回列表格式数据 ==>ls
os.getcwd() 获取工作路径 ==>pwd



⭐sys模块和python解析器交互,os模块和操作系统交互
5.pathlib

Ⅵ 模块和包
第 9 章. 模块和包
①被导入模块如果有print或者函数的调用,导入后,会被自动执行;所以要将被导入模块的测试代码放到 main里面
②在被调用模块中,__name__的值等于__main__ ,所以条件成立,会执行测试代码

③调用时值将变化,会等于此模块相对于此项目目录的绝对路径。if条件不成立,所以if下面的影响语句就不会执行

包和模块
如果你从 Python 解释器退出并再次进入,之前的定义(函数和变量)都会丢失。因此,如果你想编写一个稍长些的程序,最好使用文本编辑器为解释器准备输入并将该文件作为输入运行。这被称作编写 脚本 。随着程序变得越来越长,你或许会想把它拆分成几个文件,以方便维护。你亦或想在不同的程序中使用一个便捷的函数, 而不必把这个函数复制到每一个程序中去。
⭐框架中的代码要放在包里面,pytest执行的时候有时会找不到文件夹里面的代码(pythonxx文件和xx包)
1. 模块
1.1 概念
为支持这些,Python 有一种方法可以把定义放在一个文件里,并在脚本或解释器的交互式实例中使用它们。这样的文件被称作 模块 ;模块中的定义可以 导入 到其它模块或者 主 模块(你在顶级和计算器模式下执行的脚本中可以访问的变量集合)。
模块是一个包含 Python 定义和语句的文件。文件名就是模块名后跟文件后缀 .py 。
⭐
包:就是python的文件夹
模块:就是我们的文件名(不包含.py)
import math
import time

案例:
使用你最喜欢的文本编辑器(当然不建议 windows 记事本)在当前目录下创建一个名为 fibo.py 的文件,文件中含有以下内容。
# 斐波那契数列 模块
def fib(n): # 打印斐波那契数列到数n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
1.2 导入模块
通过关键字 import 可以在代码中导入写好的模块,语法如下:
import 模块名
案例:
现在进入解释器,并用以下代码导入 fibo.py
import fibo
在当前变量表中,不会直接定义模块中的函数名,它只是定义了模块名。接下来,通过模块名 fibo 就可以访问其中的函数
fibo.fib(10) fibo.fib2(10)
0 1 1 2 3 5 8
[0, 1, 1, 2, 3, 5, 8]import 语句有一个变体,它可以把模块中的名称(变量,函数名,类名)直接导入到当前模块的变量表里,语法如下:
from 模块名 import 名称
案例:
from fibo import fib, fib2
这并不会把被调模块名引入到当前变量表里,而是将函数名 fib,fib2 引入,现在可以直接访问这两个函数了。
fib(10) fib2(10)
0 1 1 2 3 5 8
[0, 1, 1, 2, 3, 5, 8]
还有一个变体可以导入模块中定义的所有名称,语法如下:
from 模块名 import *
这会导入所有非以下划线(_)开头的名称。 在多数情况下,Python 程序员都不会使用这个功能,因为它在解释器中引入了一组未知的名称,而它们很可能会覆盖一些你已经定义过的东西。
注意通常情况下从一个模块或者包内导入 * 的做法是不太被接受的, 因为这通常会导致代码的可读性很差。不过,在交互式编译器中为了节省打字可以这么用。
如果模块名称之后带有 as,则跟在 as 之后的名称将直接绑定到所导入的模块。语法如下:
import 模块名称 as 新名称 from 模块名称 import 名称 as 新名称
案例:
import fibo as fib fib.fib(10)
0 1 1 2 3 5 8
这会和 import fibo 方式一样有效地调入模块, 唯一的区别是它以 fib 的名称存在的。
这种方式也可以在用到 from 的时候使用,并会有类似的效果:
from fibo import fib as fibonacci fibonacci(10)
0 1 1 2 3 5 8
注意:出于效率的考虑,每个模块在解释器会话中只被导入一次。
⭐import可以具体到变量、函数以及类,但至少要到模块名


⭐如果不是自己写的模块,可以直接import 如:import os
⭐除了顶层目录,一层一层的剥开你的心
⭐
import time # import 模块名
print(time.time()) # 时间的模块time ,获取当前时间的函数time()
from time import time # from 模块名 import 函数名
print(time())

2. 包
2.1 概念
模块的问题解决了代码过长不便于维护问题,但是如果不同人编写的模块名相同怎么办?为了避免模块名冲突,python 又引入了用目录来组织模块的方法,称为包。
为了避免 fibo.py 与其他模块冲突,我们可以选择一个顶层包名,例如:my_fibo,然后创建名为 my_fibo 的文件夹,将模块 fibo.py 放入该文件夹下。然后通过 import 包名.模块名 的方式引入,只要顶层包名不起冲突,模块就不会起冲突。现在 fibo 模块的引入就是这样的:
import my_fibo.fibo
但是这样导入引用时也要用全名
my_fibo.fibo.fib(10)
0 1 1 2 3 5 8
也可以通过结合 from 引用
from my_fibo import fibo
这样可以是用 fibo 调用模块中的函数
fibo.fib(10)
0 1 1 2 3 5 8
也可以直接导入所需的函数或变量
from my_fibo.fibo import fib
这样可以直接调用 fib 函数
fib(10)
0 1 1 2 3 5 8
请注意,当使用 from package import item 时,item 可以是包的子模块(或子包),也可以是包中定义的其他名称,如函数,类或变量。 import 语句首先测试是否在包中定义了 item;如果没有,它假定它是一个模块并尝试加载它。如果找不到它,则引发 ImportError 异常。
相反,当使用 import item.subitem.subsubitem 这样的语法时,除了最后一项之外的每一项都必须是一个包;最后一项可以是模块或包,但不能是前一项中定义的类或函数或变量。
注意每一个包根目录下都有一个 __init__.py 的文件,这个文件必须存在,因为 python 就是通过它来区分普通文件夹和包。
![]()
手动设置根目录:

3.标准库

3.1 time模块


3.1.1)三种时间表示的相互转换


3.2 datetime模块

3.2.1)datetime截取

3.2.2)datetime之间的转换


3.3 calender模块
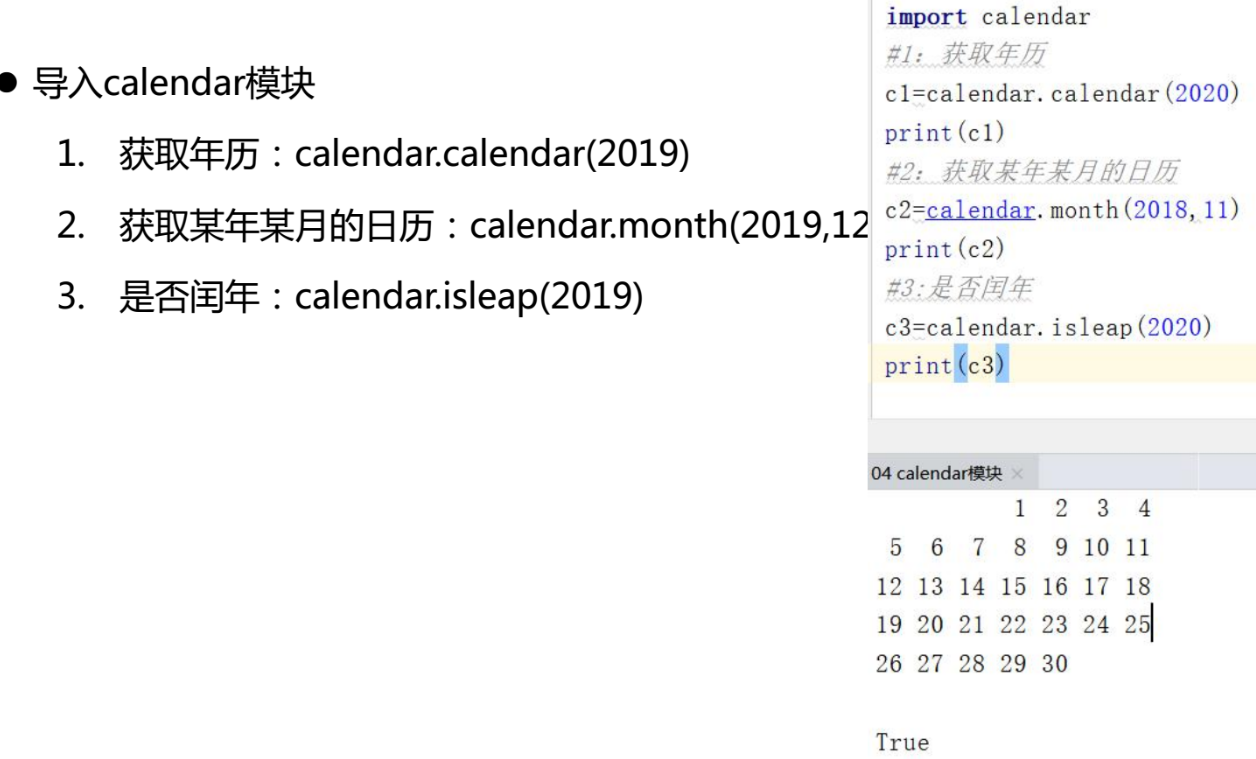
4.第三方库
作为一个受欢迎的开源开发项目,Python 拥有活跃的贡献者和用户支持社区,并且根据开放源代码许可条款,其软件可供其他 Python 开发人员使用。
这使 Python 用户可以受益于其他人已经针对常见(有时甚至是罕见的)问题创建的解决方案,并可以有效地共享和协作,并有可能将自己的解决方案贡献给公共资源库。
其他用户共享在公共资源库中的 python 项目就是第三方库。
换句话说就是别人写的 python 模块。
4.1 pip
有很多方法可以管理 python 的第三方库,推荐使用 pip 下载,安装,删除第三方库。
从 Python 3.4 开始,它默认包含在 Python 二进制安装程序中。
命令行中输入以下命令来安装模块的最新版本和依赖项:
pip install SomePackage
4.2 pip 源的配置
因为 pip 会从网上下载模块,默认服务器在国外,可以配置将 pip 源服务配置为国内的镜像服务器。
国内比较稳定优质的镜像:
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 豆瓣:http://pypi.douban.com/simple/
4.2.1)临时配置
通过在安装命令后加上-i 参数手动临时指定源
pip install requests -i https://pypi.doubanio.com/simple
如果提示没有权限可加上--user
pip install requests -i https://pypi.tuna.tsinghua.edu.cm/simple --user
4.2.2)永久配置
通过修改 pip 的配置文件,以后运行 pip 命令会使用配置中的源。
windows 平台配置
-
新建 pip 配置文件夹,直接在 user 用户目录中创建一个名为 pip 的文件夹( 即 %HOMEPATH%\pip),如下图所示:
-
接着在 pip 文件夹中创建一个名为 pip 的文本文件(后缀名由" .txt "改为 " .ini "),格式如下所示:
文件内容如下:
[global] index-url = https://pypi.doubanio.com/simple [install] trusted-host = https://pypi.doubanio.com/
保存后重新打开命令行工具使用 pip 安装第三方库就会使用配置的源。
liux/mac 平台配置
-
在家目录下创建 pip 配置文件夹
.pip
cd ~ # 切换到家目录
mkdir .pip # 创建配置文件夹
-
创建配置文件
cd .pip # 切换到配置文件夹下
vim pip.conf # 创建并编辑配置文件
文件内容如下:
[global] index-url = https://pypi.doubanio.com/simple [install] trusted-host = https://pypi.doubanio.com/
保存后重新打开终端使用 pip 安装第三方库就会使用配置的源。




5.自定义模块化使用


Ⅶ 面向对象基础
第 10 章. 面向对象基础
面向对象
前面我们讲到基本数据类型用来表示最常见的信息。但是信息有无穷多种,为了更好的表达信息,我们可以创建自定义数据类型。
1. 类
1.1 类的概念
一种数据类型就是类。例如整数,浮点数,字符串。
1.2 类的定义
python 中通过关键字 class 可以定义一个自定义数据类型,基本语法如下:
class 类名: 属性 方法
注意:python 中类名规则同变量,首字母大写,一般使用 大驼峰 来表示。
案例
例如:创建一个 Point 类用于表示平面坐标系中的一个点
class Point:
"""
表示平面坐标系中的一个点
"""
print(Point)
<class '__main__.Point'>
<__main__.Point object at 0x0000021D799D4940>

2. 对象
2.1 对象的概念
某种数据类型的一个具体的数据称为这个类的一个对象或者实例。通过类创建对象叫做实例化。
所谓的面向对象,就是把一些数据抽象成类的思想。
python 是一门面向对象的编程语言,python 中一切皆对象。
前面学习的函数也是 python 中的一个类,定义的某个函数就是函数类的一个具体实例。
def func():
pass
print(type(func))
<class 'function'>
2.2 实例化
除了基本数据类型实例化的过程中用到的特殊的语法规范外,所有自定义类型进行实例化都是通过调用类名来实现的,非常简单,语法如下:
对象 = 类名(参数)
看起来和调用函数一样。
案例
给上面创建的 Point 类创建一个实例。
point = Point() print(type(point)) print(point) # 查看对象分配的内存空间
<class 'main.Point'>
⭐ 实例化对象操作属性

3. 属性
类和对象的特征数据称为属性。

3.1 类属性
类的特征称为类属性。
3.1.1)类属性的定义
①直接在类中定义的变量(与 class 语句只有一个缩进),就是类属性。
案例:
给 Point 类创建一个 name 属性用来表示名称。
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
⭐②类外面:类名.属性名 = '属性值'
⭐ 类属性有公有和私有两种,私有类属性是以两个下划线开头的。
⭐自定义的类,python会自动生成__dict__属性,这个属性可以获取到类所有的属性和方法,以字典形式返回

3.1.2)类属性的访问
类属性可以直接通过类名和对象以句点法访问,语法格式如下:
类名.类属性名 (-推荐使用) 对象.类属性名
案例:
print(Point.name) # 直接通过类名访问类属性 point=Point() # 创建一个实例 print(point.name) # 通过对象访问类属性
点
点
注意:如果不存在属性则抛出 AttributeError 的异常
print(Point.a)
AttributeError Traceback (most recent call last)
in
----> 1 print(Point.a)
AttributeError: type object 'Point' has no attribute 'a'

3.1.3)类属性的更新


![]()
3.2 对象属性(成员属性/实例属性)
对象的特征数据称为对象属性。

3.2.1)对象属性的定义
对象属性一般定义在构造方法中,详见下面构造方法一节。
通过句点法 对象.对象属性 以赋值的方式可以直接定义对象属性。
案例:
平面坐标系中的每个点都有 x 坐标和 y 坐标,通过类 Point 创建一个对象表示点(x=1,y=2)
point = Point() # 通过赋值直接定义对象属性 point.x = 1 point.y = 2
注意:在定义对象属性时如果和类属性同名,那么通过对象将无法访问到类属性。
3.2.2)对象属性的访问
实例属性:只能通过这个实例对象访问 ; 通过句点法 `对象.对象属性` 可以访问对象属性。
案例:
访问上面案例中 point 的 x 坐标和 y 坐标
print(point.x) print(point.y)
1
2
访问对象属性时,首先会检查对象是否拥有此属性,如果没有则去创建对象的类中查找有没有同名的类属性,如果有则返回,如果都找不到则抛出 AttributeError 的异常

3.2.3)对象属性的修改

3.3 内置属性

4. 方法
定义在类中的函数称为方法。通过调用的方式的不同,分为对象方法,类方法,静态方法和魔术方法。

4.1 对象方法
定义在类中的普通方法,一般通过对象调用称为对象方法。
4.1.1)对象方法的定义
为了讲清楚对象方法的定义和调用,我们先看下面的案例。
案例:
定义函数 my_print,它接收一个 Point 对象,然后打印这个点的 x,y 坐标。
def my_print(point):
print('({},{})'.format(point.x, point.y))
p = Point()
p.x = 1
p.y = 2
my_print(p)
(1,2)
定义函数 distance,它接收两个 Point 对象,然后返回这两个点的距离。
def distance(p1, p2):
return ((p1.x-p2.x)**2 + (p1.y-p2.y)**2)**0.5
p1 = Point()
p2 = Point()
p1.x = 1
p1.y = 2
p2.x = 3
p2.y = 4
res = distance(p1,p2)
print(res)
2.8284271247461903
观察上面的两个函数,发现它们都接收一个或多个 Point 的对象作为参数。为了显式的加强这样的联系,我们可以将它们定义在 Point 的类中。
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def my_print(point):
print('({},{})'.format(point.x, point.y))
def distance(p1, p2):
return ((p1.x-p2.x)**2 + (p1.y-p2.y)**2)**0.5
4.1.2)对象方法的调用
对象方法和属性一样,可以通过句点法进行调用。
类名.方法名(参数) 对象.方法名(参数)
通过类名调用方法时,和普通函数没有区别
# 更新了类,再次实例化对象 point = Point() point.x = 1 point.y = 2 p1 = Point() p2 = Point() p1.x = 1 p1.y = 2 p2.x = 3 p2.y = 4 Point.my_print(point) res = Point.distance(p1, p2) print(res)
(1,2)
2.8284271247461903
通过对象调用方法时,对象本身会被隐式的传给方法的第一个参数
point.my_print() res = p1.distance(p2) print(res)
(1,2)
2.8284271247461903
因此,定义对象方法会习惯性的把第一个形参定义为 self,self代表对象本身;哪个对象调用方法,方法中的self代表的就是哪个对象
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def my_print(self):
print('({},{})'.format(self.x, self.y))
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5
方法中如果要自定义参数,参数定义在self之后 调用方法时,除了self不用传递,其他的参数传递和函数调用一样 实例方法:只能通过实例对象去调用,调用时会把对象传递给第一个参数self

⭐总结:


4.2 类方法
在类中通过装饰器 classmethod 可以把一个方法变成类方法。
类方法的第一个参数定义为:cls 类方法中的cls代表的是类本身
调用时一个类方法把类自己作为第一个实参传递给cls,就像一个实例方法把实例自己作为第一个实参传递给self。
案例
定义一个类方法 base_point 用来返回坐标原点。
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def my_print(self):
print('({},{})'.format(self.x, self.y))
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5
@classmethod
def base_point(cls):
bp = cls()
bp.x = 0
bp.y = 0
return bp
通过类本身或者是该类的实例都可以调用类方法;
p = Point() bp1 = p.base_point() bp1.my_print() bp2 = Point.base_point() bp2.my_print()
(0,0)
(0,0)
类方法一般都用来生成特殊对象。
4.3 类方法的进阶学习
4.3.1)类函数调用类属性
案例:
class SuperMan:
# 类的属性
name = 'nick'
def protect_people(self):
print('我是超人,我叫:%s'%self.name)
p = SuperMan()
p.protect_people()
输出结果:
我是超人,我叫:nick
class SuperMan:
# 类的属性
name = 'nick'
@classmethod
def protect_people(cls):
print('我是超人,我叫:%s' % cls.name)
print('我是超人,我叫:%s' % SuperMan.name)
print('我是超人,我叫:%s' % SuperMan().name)
p = SuperMan()
p.protect_people()
总结:
在函数里面调用类属性,必须通过实例对象和类去调用
4.3.2)类函数带有位置参数
案例:
参照类方法的
4.3.3)类函数带有默认参数
案例:
class SuperMan:
# 类的属性
name = 'nick'
def protect_people(self,name='毛毛'):
print('我是超人,我叫:%s' % name)
p = SuperMan()
p.protect_people('笑笑') # 传入参数
p.protect_people() # 不传入参数
输出结果:
我是超人,我叫:笑笑
我是超人,我叫:毛毛
4.3.4)类函数之间的相互调用
4.3.4.1)类函数调用不带参数的类函数
案例:
class SuperMan:
# 类的属性
name = 'nick'
def protect_people(self,name='毛毛'):
print('我是超人,我叫:%s' % name)
self.fly_to_sky()
def fly_to_sky(self):
print('我是超人,我可以飞上天!')
p = SuperMan()
p.protect_people('笑笑')
输出结果:
我是超人,我叫:笑笑
我是超人,我可以飞上天!
4.3.4.2)类函数调用带参数的类函数
案例:
class SuperMan:
# 类的属性
name = 'nick'
def protect_people(self,name='毛毛'):
print('我是超人,我叫:%s' % name)
def fly_to_sky(self,name):
self.protect_people(name)
print('我是超人,我可以飞上天!')
p = SuperMan()
p.fly_to_sky('非非')
输出结果:
我是超人,我叫:非非
我是超人,我可以飞上天!
4.3.5)类函数带有动态参数
案例:
class SuperMan:
# 类的属性
name = 'nick'
def protect_people(self,*args):
for name in args:
print('我是超人,我叫:%s' % name)
p = SuperMan()
p.protect_people('非非','毛毛','滔滔','思思')
输出结果:
我是超人,我叫:非非
我是超人,我叫:毛毛
我是超人,我叫:滔滔
我是超人,我叫:思思
4.3.6)类函数带有关键字参数
案例:
class SuperMan:
# 类的属性
name = 'nick'
def protect_people(self,**kwargs):
print('我是超人,我的个人信息是:%s' % kwargs)
p = SuperMan()
p.protect_people(name='非非',sex='girl',age=20)
输出结果:
我是超人,我的个人信息是:{'name': '非非', 'sex': 'girl', 'age': 20}
4.4 特殊方法(魔术方法)
在类中可以定义一些特殊的方法用来实现特殊的功能,也称为魔术方法。这些方法一般都以双下划线 __ 开头
__init__
__init__ 又叫构造方法,初始化方法,在调用类名实例化对象时,构造方法会自动被调用,类名括号 () 后的参数会传递给构造方法,那么对象就会有相应的实例属性,对象属性一般在这个方法中定义。

⭐self是对象本身,那么创建对象,调用__init__方法后,指定 self.属性名 = 属性值 ,就是为对象的对象属性赋值,把传进来的参数值给对应属性;
案例1:
上面案例中的 Point 类实例化后,需要手动创建对象属性 x 和 y,这显然容易出错和不规范,正确的做法应该是在构造方法中定义属性 x 和 y
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def __init__(self, x, y):
self.x = x
self.y = y
def my_print(self):
print('({},{})'.format(self.x, self.y))
def distance(self, p2):
return ((self.x - p2.x) ** 2 + (self.y - p2.y) ** 2) ** 0.5
@classmethod
def base_point(cls):
return cls(0, 0)
# 实例化
p1 = Point(1, 2)
p2 = Point(x=3, y=4)
p1.my_print() # 实例调用类的方法
p2.my_print()
print(p1.name) # 实例调用类的属性值
(1,2)
(3,4)
点
案例2:类函数调用初始化值
class SuperMan:
def __init__(self,name):
self.name = name
def protect_people(self):
print('我是超人,我叫:%s' % self.name)
p = SuperMan('nick')
p.protect_people()
输出结果:
我是超人,我叫:nick
如果类函数里面要调用初始化的值,可以直接调用,要记得加self关键字。
注意:对象属性只能通过对象调用
SuperMan.age=age 赋值给类属性则可以通过类来访问
__str__
__str__ 方法在对象被 print 函数打印时被调用,print 输出 __str__ 方法返回的字符串。
案例:
上面案例中 Point 类里的 my_print 方法可以去掉,定义一个 __str__ 方法
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return '({},{})'.format(self.x, self.y)
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5
@classmethod
def base_point(cls):
return cls(0,0)
p = Point(2,2)
print(p)
(2,2)
更多的特殊方法详见官方文档
4.5 静态方法
在类中通过装饰器 staticmethod 可以把一个方法变静态方法。
静态方法不会接收隐式的第一个参数,它和普通的函数一样,只是被封装到类中。
通过类和对象都可以调用。
案例:
在 Point 类中定义一个静态方法,用来计算两个数的和。
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return '({},{})'.format(self.x, self.y)
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5
@classmethod
def base_point(cls):
return cls(0,0)
@staticmethod
def sum(x,y):
return x+y
Point.sum(1,2)
3
p = Point(1,2) p.sum(3,4)
7
4.6 类方法的不同使用场景
①如果方法内部要使用对象的属性或调用对象的其他方法,方法定义为实例方法。
②如果方法内部要使用类的属性或其他的类方法,方法定义为类方法。
③如果方法中既不使用类的属性和方法,也不使用对象的属性和方法,定义为静态方法。
5. 类的继承
类还有一个重要的特性是继承。
在pyhton3中所有的类都有一个顶级的父类(基类):object
5.1 继承
当定义一个类时,可以从现有的类继承,新的类称为子类(Subclass),被继承的类称为基类,父类或超类(Base class,Super class).
子类可以继承父类的属性和方法。
注意:私有属性和方法不能继承
案例:
创建一个类用来表示三维的点。
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return '({},{})'.format(self.x, self.y)
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5
@classmethod
def base_point(cls):
return cls(0,0)
@staticmethod
def sum(x,y):
return x+y
class TdPoint(Point):
"""
表示三维的点
"""
在上面的案例中 TdPoint 类继承了 Point 类。对于 TdPoint 来说 Point 是它的父类,对于 Point 类来说 TdPoint 是他的子类。
print(dir(TdPoint))
['class', 'delattr', 'dict', 'dir', 'doc', 'eq', 'format', 'ge', 'getattribute', 'gt', 'hash', 'init', 'init_subclass', 'le', 'lt', 'module', 'ne', 'new', 'reduce', 'reduce_ex', 'repr', 'setattr', 'sizeof', 'str', 'subclasshook', 'weakref', 'base_point', 'distance', 'name', 'sum']
虽然在 TdPoint 类中没有定义任何的属性和方法,但它自动继承了父类 Point 的属性和方法。
5.2 多继承
一个子类可以同时继承多个父类:
5.2.1)类的多继承-类方法不同
案例:
class A:
def add(self,a,b):
print('类A中的加法',a+b)
class B:
def sub(self,a,b):
print('类B中的减法',a-b)
class C(A,B):
pass
C().add(1,2)
C().sub(1,2)
输出结果:
类A中的加法 3
类B中的减法 -1
子类C继承了父类AB的所有方法,调用的时候,就直接去父类里面取方法进行调用即可。
5.2.2)类的多继承-类方法相同
案例:
class A:
def add(self,a,b):
print('类A中的加法',a+b)
class B:
def add(self,a,b):
print('类B中的加法',a+b)
def sub(self,a,b):
print('类B中的减法',a-b)
class C(B,A):
pass
C().add(1,2)
C().sub(1,2)
输出结果:
类B中的加法 3
类B中的减法 -1
子类C调用的全部是父类B中的方法,这就是多继承的另一个特点:顺序继承。当出现同名方法的时候,会按照是顺序优先调用前面父类的同名方法。
5.3 重写
在上面的案例中,虽然 TdPoint 类继承了 Point 的属性和方法,但是三维的点比二维的点多了一个纬度,所以大部分方法和属性不合适,需要重写。
在子类中定义同名的方法和属性会覆盖父类的方法和属性。
class Point:
"""
表示平面坐标系中的一个点
"""
name = '点'
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return '({},{})'.format(self.x, self.y)
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5
@classmethod
def base_point(cls):
return cls(0,0)
@staticmethod
def sum(x,y):
return x+y
class TdPoint(Point):
"""
表示三维的点
"""
def __init__(self, x, y, z):
self.x = x
self.y = y
self.z = z
def __str__(self):
return '({},{},{})'.format(self.x, self.y, self.z)
def distance(self, p2):
return ((self.x-p2.x)**2 + (self.y-p2.y)**2 + (self.z-p2.z)**2)**0.5
@classmethod
def base_point(cls):
return cls(0,0,0)
上面的代码中 TdPoint 类重写了父类中的init,str,distance,base_point 四个方法
p1 = TdPoint(1,2,3) p2 = TdPoint(2,3,4) print(p1)
(1,2,3)
p1.distance(p2)
1.7320508075688772
print(TdPoint.base_point())
(0,0,0)
⭐方法文档字符串注释的添加:在方法下打一对三引号""""""
5.4 拓展
子类可以重写父类中的方法
子类还可以拓展一些父类中没有的方法
5.5 super 方法
重写了父类方法后如果又要调用父类的方法怎么解决呢?
例如,三维点在计算点与点的距离时,要求同时返回投射到二维平面的点的距离。
class TdPoint(Point):
"""
表示三维的点
"""
def __init__(self, x, y, z):
self.x = x
self.y = y
self.z = z
def __str__(self):
return '({},{},{})'.format(self.x, self.y, self.z)
def distance(self, p2):
d2 = Point.distance(self, p2)
d3 = ((self.x-p2.x)**2 + (self.y-p2.y)**2 + (self.z-p2.z)**2)**0.5
return d2, d3
@classmethod
def base_point(cls):
return cls(0,0,0)
p1 = TdPoint(1,2,3)
p2 = TdPoint(2,3,4)
p1.distance(p2)
(1.4142135623730951, 1.7320508075688772)
可以直接通过类名的方式调用对应的方法。但是这种方法的耦合性太大,官方推荐使用 super 函数。
class TdPoint(Point):
"""
表示三维的点
"""
def __init__(self, x, y, z):
self.x = x
self.y = y
self.z = z
def __str__(self):
return '({},{},{})'.format(self.x, self.y, self.z)
def distance(self, p2):
d2 = super().distance(p2)
d3 = ((self.x-p2.x)**2 + (self.y-p2.y)**2 + (self.z-p2.z)**2)**0.5
return d2, d3
@classmethod
def base_point(cls):
return cls(0,0,0)
p1 = TdPoint(1,2,3)
p2 = TdPoint(2,3,4)
p1.distance(p2)
<super: <class 'TdPoint'>, >
(1.4142135623730951, 1.7320508075688772)
在具有单继承的类层级结构中,super 可用来引用父类而不必显式地指定它们的名称,从而令代码更易维护。
super()会返回一个代理对象,它会将方法调用委托给父类,这对于访问已在类中被重载的父类方法很有用。
class SoftWareTestEngineer:
def __init__(self,name,age):
self.name = name
self.age = age
def basic_skill(self):
print(self.name+'今年'+str(self.age)+'岁,可以做点点点功能测试')
class JuniorSoftWareEngineer(SoftWareTestEngineer):
def basic_skill(self):
print(self.name+'今年'+str(self.age)+'岁,可以按照完整的业务逻辑以及测试用例完成功能测试,达到99%的通过率')
def auto_test(self,code):
print(self.name+'能够做%s自动化测试'%code)
class SeniorSoftWareTestEngineer(JuniorSoftWareEngineer):
def auto_test(self, code):
super(SeniorSoftWareTestEngineer,self).auto_test(code)
print('我还可以利用Python代码写接口自动化、web自动化、APP自动化框架!')
SeniorSoftWareTestEngineer('summer',20).auto_test('python')
输出结果:
summer能够做python自动化测试
我还可以利用Python代码写接口自动化、web自动化、APP自动化框架!
super类写的是子类的类型,顺着子类的类名找到对应的父类,并调用父类的方法,实现超继承。
在子类中调用被重写的父类方法
# 方式一、:父类名.方法名(self,xxx,xx....)
PhoneV1.__init__(self,size, year)
# 方式二:super().方法名(xxx,xx....)
super().__init__(size, year)

5.6 多态
python 是一门动态语言,严格的来说 python 不存在多态。
def bark(animal):
animal.bark()
上面的函数 bark 接收一个对象,并调用了对象的 bark 方法。对于 python 来说只要传入的对象有 bark 方法这个函数就可以执行,而不必去检查这个对象的类型。
class Animal:
def bark(self):
print('嗷嗷叫!')
class Dog(Animal):
def bark(self):
print('汪汪叫!')
class Cat(Animal):
def bark(self):
print('喵喵叫!')
class Duck(Animal):
def bark(self):
print('嘎嘎叫!')
dog = Dog()
cat = Cat()
duck = Duck()
bark(dog)
bark(cat)
bark(duck)
汪汪叫!
喵喵叫!
嘎嘎叫!
上面的案例中 dog 是 Dog 类型的一个实例,同时它也是 Animal 的一个实例。但是反过来不成立。
对于静态语言来说函数 bark 如果需要传入 Animal 类型,则传入的对象必须是 Animal 类型或者它的子类,否则,不能调用 bark。
dog,cat,duck 都是 Animal 类型,但是它们执行 bark 后的输出又各不相同。一个类型多种形态,这就是多态。
对于 python 这样的动态语言来说,则不需要传入的一定是 Animal 类型,只要它具有一个 bark 方法就可以了。
⭐不继承也能实现多态,python的多态都是伪多态。
class SomeClass:
def bark(self):
print('随便叫!')
sc = SomeClass()
bark(sc)
随便叫!
⭐因为函数参数类型和函数参数长度没有限制,多以python无多态
⭐ 多态:定义好一个制式,按照这个制式向接口去提供对应的不同对象,根据你提供的不同对象执行不同的操作
# 常用的支付方式:微信支付 支付宝支付 银行卡支付
class PayMent():
def pay(self):
print("给钱")
class WeChat(PayMent):
def pay(self):
print("微信支付")
class AliPay(PayMent):
def pay(self):
print("支付宝支付")
class Card(PayMent):
def pay(self):
print("银行卡支付")
class StartPay(): # 没有继承
def pay(self,obj): # 也定义一个pay函数,定义一个变量,用来接收未知的对象
obj.pay()
s = StartPay()
ali = AliPay()
s.pay(obj=ali)
支付宝支付
5.7 私有化
python 中不存在那种只能在仅限从一个对象内部访问的私有变量。
但是,大多数 Python 代码都遵循这样一个约定:以一个下划线开头的名称 (例如 _spam) 应该被当作是 API 的非公有部分 (无论它是函数、方法或是数据成员)。 这应当被视为一个实现细节,可能不经通知即加以改变。
class A:
_arg1 = 'A'
def _method1(self):
print('我是私有方法')
a = A()
a._arg1
'A'
a._method1()
我是私有方法
这种以一个下划线开头的属性可以被类和实例调用。
只是在 from xxx import * 时不会被导入。
还有一种定义私有属性的方法是以两个下划线开头的名称(例如__spam),这种方式定义的私有变量只能在类的内部访问。
class A:
__arg1 = 'A'
def __method1(self):
print('我是私有方法')
a = A()
a.__arg1
AttributeError Traceback (most recent call last)
in
1 a = A()
----> 2 a.__arg1
AttributeError: 'A' object has no attribute '__arg1'
这种限制访问的原理是,以双下划线开头的属性名(至少带有两个前缀下划线,至多一个后缀下划线)会被改写成 _classname__spam,所以在类外部通过原名称反问不到,但在类的内部使用原名称可以访问。
a._A__arg1
'A'
私有属性和私有方法也不能被继承。
⭐ 私有的实例属性,只能在自己内中调用(对象是独立的)



⭐内置属性

⭐私有方法和属性是用来实现内部逻辑的,外部不能直接调用


6.类的封装

6.1 实例方法封装

6.2 私有属性封装



6.3 装饰器@property

装饰器@property定义与调用


7.自省与反射机制
7.1 自省
在日常生活中,自省(introspection)是一种自我检查行为。
在计算机编程中,自省是指这种能力:检查对象以确定它是什么类型、它有哪些属性和哪些方法。自省向程序员提供了极大的灵活性和控制力。
type
type 函数可以返回一个对象的类型
type(1)
int
isinstance
检查一个对象是否是某个或某些类型的实例
isinstance(1,int)
True
issubclass
检查一个类是否是某个或某些类的子类
issubclass(bool, int)
True
dir
返回一个传入对象的属性名和方法名的字符串列表
print(dir(1))
['abs', 'add', 'and', 'bool', 'ceil', 'class', 'delattr', 'dir', 'divmod', 'doc', 'eq', 'float', 'floor', 'floordiv', 'format', 'ge', 'getattribute', 'getnewargs', 'gt', 'hash', 'index', 'init', 'init_subclass', 'int', 'invert', 'le', 'lshift', 'lt', 'mod', 'mul', 'ne', 'neg', 'new', 'or', 'pos', 'pow', 'radd', 'rand', 'rdivmod', 'reduce', 'reduce_ex', 'repr', 'rfloordiv', 'rlshift', 'rmod', 'rmul', 'ror', 'round', 'rpow', 'rrshift', 'rshift', 'rsub', 'rtruediv', 'rxor', 'setattr', 'sizeof', 'str', 'sub', 'subclasshook', 'truediv', 'trunc', 'xor', 'as_integer_ratio', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
python 中的自省函数有很多,凡是可以检查对象状态的函数都可以称为自省函数。
7.2 反射
反射就是动态的操作对象。
简单的讲就是根据字符串形式的属性名方法名操作对应的对象。
hasattr
检查一个对象是否有给定名称的属性
hasattr([1,2,3],'append')
True
getattr
返回一个对象给定名称的属性
getattr(x,'y') 等价于 x.y
class Point:
name = '点'
getattr(Point,'name')
'点'
动态获取属性
参数1:对象(类)
参数2:属性名
参数3:属性不存在时返回的默认值(不写,则属性不存在时报错)
getattr(Point,double,None)
setattr
给一个对象/类 添加一个给定名称的属性
把动态的数据绑定为类或者对象的属性名和属性值
setattr(x, 'y', v) 等价于 x.y = v
setattr(Point,'x',1) Point.x
1



⭐动态给类和对象设置属性,可以实现接口间依赖参数的传递,setattr getattr
delattr
删除对象的一个给定名称的属性
delattr(x, 'y') 等价与 del x.y
delattr(Point, 'x') Point.x
AttributeError Traceback (most recent call last)
in
----> 1 Point.x
AttributeError: type object 'Point' has no attribute 'x'
自省和反射机制的理解需要大量的阅读源码。

练习1:学生类
class Students:
"""
学生类
"""
identity = '学生'
def __init__(self,name,age,gender,english,math,chinese):
self.name = name
self.age = age
self.gender = gender
self.english = english
self.math = math
self.chinese = chinese
def sum_score(self):
"""计算总分"""
res = self.english + self.math + self.chinese
return res
def avg_score(self):
"""计算平均分"""
# res = (self.english + self.math + self.chinese)/3
res = self.sum_score()/3
return res
def desc_info(self):
"""打印信息"""
print('学员名字:{},年龄:{},性别:{}...'.format(self.name,self.age,self.age))
练习2:烤鸭店
print("~~~=欢迎使用花花老师的烤鸭店计算器=~~~")
projects = {}
# print("**** 准备开始录入商品 ****")变成装饰器
def decorator_01(func_name):
def pre_print(*args): # *args接收self
print("**** 准备开始录入商品 ****")
return func_name(*args)
return pre_print
class Duck():
@decorator_01
def input_goods(self): # 封装成类函数后要将self传给装饰器
"""录入商品的功能""" # 添加函数的注释
pro_list = [] # 列表要在if里面,不能在if上面,因为每一次进入while循环都会把列表清空一次,所以会查不出数据
load_txt = ["请输入商品的名称:", "请输入商品的成本价:", "请输入商品的出产地:", "请输入商品的生产日期:", "其他商品属性1:", "其他商品属性2:"]
for i in load_txt:
name1 = input(f"{i}") # 这样也可以,还挺帅的
pro_list.append(name1)
projects[pro_list[0]] = pro_list # 此时要用这个
def select_goods(self):
# 这里还要做一个判断,如果字典里面没有Key值的时候如何处理?
# 查询商品的功能
load_name = input("输入你要查询的商品名称:") # key的名字是唯一的不允许重复
print("{}".format(projects[load_name]))
def cycle(self):
while True:
# 转义字符:键盘上有一部分键,不能在代码中显示
# 用英文去代替特殊键位
# 百度词典搜索 转义字符
ope_type = input("1 - 录入商品 \n2 - 查询商品\n3 - 退出系统\n请做出您的选择:")
# pro_list = []
if ope_type == "1":
self.input_goods() # 将鼠标移到函数上面,就能显示出来这个函数是用来做什么的,需不需要传参数
elif ope_type == "2":
self.select_goods()
elif ope_type == "3":
# 退出系统的功能
print("正在退出系统!!!")
break
else:
print("系统无法识别您的操作,即将关闭系统~")
break
duck = Duck()
duck.cycle()
Ⅷ python单元测试
1.小结
2.单元测试
1.unittest框架
1.1)四个核心概念
· TestCase:一个testcase的实例就是一个测试用例
· TestSuite:多个测试用例集合在一起。TestLoader:是用来加载TestCase到TestSuite中的
· TestRunner:用来执行测试用例的。
· fixture:测试用例环境的搭建和销毁。测试前准备环境的搭建(setUp),执行测试代码(run),以及测试后环境的还原(tearDown)
1.2)单元测试案例
·测试需求1

myCode.py
def counter(a, b, method): """ 计算两个整数加减乘除的计算器 :param a: 数值1 :param b: 数值2 :param method: 数值的运算方法 :return: 运算的结果 """ # 判断a,b是否是int类型 if isinstance(a, int) and isinstance(b, int): if method == "+": return a + b elif method == "-": return a - b elif method == "*": return a * b elif method == "/": return a / b else: return '计算方式有误' else: return '参数a和b只能为整数类型的数据'
""" 正向用例: 1、加 入参:11,22,+ 预期结果:33 2、减 入参:11,22,- 预期结果:-11 3、乘 入参:2,10,* 预期结果:20 4、除 入参:20,10,/ 预期结果:2.0 反向用例: 5、传入的计算方式:不是加减乘除 入参: 11,22 , a 预期结果:计算方式有误 6、传入的数值非整数类型 入参:11.3,99,+ 预期结果:参数a和b只能为整数类型的数据 7、。。。 8、。。。 """ # 手工用例:
if __name__ == '__main__': res = counter(11, 22, '-') print(res)
·编写测试用例
unittest中的测试用例定义的规范:
·定义一个测试用例类,测试用例类要继承unittest.TestCase
·测试用例类中,测试方法要以test_开头,就是一条测试用例
⭐继承了unittest.TestCase 会有标识;

⭐test_开头的方法也会有标识

编写测试用例示范代码如下:
demo1_testcase.py
# 在写代码之前记得要引入unittest模块以及被测试的函数counter
# 单个用例文件只能单独运行整个模块或类,或单独运行某条用例 import unittest
from myCode import counter
# 定义一个测试用例类
class TestDemo(unittest.TestCase):
def test_01add(self):
# 第一步:准备用例数据
# 用例的入参
params = {'a': 11, 'b': 22, 'method': '+'}
# 预期结果
expected = 33
# 第二步:调用功能函数(调用接口),获取实际结果
result = counter(**params)
# 第三步:比对预期结果和实际结果是否一致(python内置关键字assert断言)
# assert expected == result
# unittest封装的断言方法,断言更详细
self.assertEqual(expected, result)
def test_02(self):
# assert 11 == 22
# 第一步:准备数据
# 用例的入参
params = {'a': 11, 'b': 22, 'method': '-'}
# 预期结果
expected = -11
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_03(self):
# self.assertEqual(11, 22)
# 第一步:准备数据
# 用例的入参
params = {'a': 2, 'b': 10, 'method': '*'}
# 预期结果
expected = 20
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_04(self):
# 第一步:准备数据
# 用例的入参
params = {'a': 20, 'b': 10, 'method': '/'}
# 预期结果
expected = 2
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_05(self):
# 第一步:准备数据
# 用例的入参
params = {'a': 11, 'b': 22, 'method': 'a'}
# 预期结果
expected = '计算方式有误'
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_06(self):
# 第一步:准备数据
# 用例的入参
params = {'a': 11.3, 'b': 99, 'method': '+'}
# 预期结果
expected = '参数a和b只能为整数类型的数据'
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
# 编写测试用例在main函数下面 if __name__ == '__main__' unittest.main()
·生成测试集
如上是利用unittest.main()执行所有的用例,但是有的时候是不需要执行所有的用例的,可以按照自己的需求去添加用例。那就要使用TestSuite来帮助我们更好的实现单元测试了。
测试套件:unittest.TestSuite
用例加载器:unittest.TestLoader
demo2_testsuite.py
1-用addTest增加一条用例:测试类类名(测试方法名)
# 用addTest增加一条用例:测试类类名(测试方法名)
import unittest
# 一、创建一个套件
suite = unittest.TestSuite()
# 二、增加一条用例,先加哪个套件,先执行
from work15.demo1_testcase import TestDome
suite.addTest(TestDome('test_01add'))
addTest是其中的一种加载测试用例的方式,还有一种是通过TestLoadder来加载测试用例,如下三种方式:
2-通过测试类来加载用例:load.loadTestsFromTestCase
# 添加测试类到测试套件 load.loadTestsFromTestCase import unittest # 一、创建一个套件 suite = unittest.TestSuite() # print(suite) 测试套件里面还没有用例 # <unittest.suite.TestSuite tests=[]> # 二、创建一个用例加载器 load = unittest.TestLoader() # 三、加载用例到测试套件 # 3.1添加测试类到测试套件 from work15.demo1_testcase import TestDome suite.addTest(load.loadTestsFromTestCase(TestDome)) # print(suite) 打印出测试类里面的所有用例
3-通过测试所在模块来加载用例-load.loadTestsFromModule
# 添加测试模块到测试套件 load.loadTestsFromModule import unittest # 一、创建一个套件 suite = unittest.TestSuite() # 二、创建一个用例加载器 load = unittest.TestLoader() # 三、加载用例到测试套件 # 3.2添加测试模块到测试套件 from work15 import demo1_testcase suite.addTest(load.loadTestsFromModule(demo1_testcase))
4-添加一个测试的目录load.discover
# 添加一个测试的目录 load.discover # 测试用例目录下面的用例模块必须要使用test开头(也可以通过参数pattern指定查找用例模块的规则,pattern='test*.py') import unittest # 一、创建一个套件 suite = unittest.TestSuite() # 二、创建一个用例加载器 load = unittest.TestLoader() # 三、加载用例到测试套件 # 3.3、添加一个测试的目录 suite.addTest(load.discover(r'D:\autotest\pythonn-api-test0\work15\testcase'))
5-测试中使用
import unittest # 以上三个步骤可以简写为一行(实际使用): suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase') print(suite)
·执行测试用例
上面已经生成测试集,加载测试用例,接下来就需要执行测试集中的用例,会用到TextTestRunner模块,生成一个用例“执行器”专门来执行测试用例
测试运行程序:unittest.TextTestRunner
此为单独创建一个run.py文件
run.py
import unittest # 方法一:将测试套件文件导入 from work15 import demo2_testsuite.py # 创建一个测试运行程序 runner = unittest.TextTestRunner() runner.run(demo2_testsuite.suite) # 方法二:创建一个测试套件,加载测试用例到测试套件 # 不单独写测试集模块方法如下:
import unittest # 方法二:加载测试用例到测试套件 suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase') # 创建一个测试运行程序 runner = unittest.TextTestRunner() runner.run(suite)
执行结果:

有失败或者错误的结果:

·生成测试报告
①文本格式的测试报告生成1

报告打开结果:

②文本格式的测试报告生成2
最后要生成测试报告,TextTestRunner是能够直接存储测试结果的,部分源码如下所示(暂不写):
import unittest
# 加载测试用例到测试套件
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase')
# 文本格式的测试报告生产(unittest自带的文本测试报告)
with open('report.txt','w',encoding='utf-8') as f:
# 通过类创建runner对象
runner = unittest.TextTestRunner(stream=f,'test',2)
# runner对象调用他的run方法
runner.run(suite)
TextTestRunner会把TestTestResult存储的结果存到指定的文件中去,TextTestRunner里面的方法有三个参数,("存储结果的文件","测试报告描述","存储模式")
存储模式有0,1,2三种模式。设置为2那么所有的测试结果会存储到当前目录下的test.txt中,执行代码后的测试结果为:

③使用第三方的扩展库来生成HTML格式的测试报告
# ---------------使用第三方的扩展库来生产测试报告--------------- # 1、安装命令:pip install BeautifulReport import unittest suite = unittest.defaultTestLoader.discover(r'C:\project\py41_class\py41_day15\testcase') from BeautifulReport import BeautifulReport br = BeautifulReport(suite) br.report(description='花园生成的报告', filename='report.html', report_dir='./reports') # 不指定路径,就默认生成在当前运行文件的同级目录下
执行结果:

④unittestreport报告
# 可以加镜像源地址下载
# 不要直接在settings里面下,settings里面下载是下到pycharm里面的,脱离了pycharm用不了,
后面用Jenkins跑后,如果包全部在pycharm的settings里面下的,用Jenkins跑的话包就加载不出来
# ===================2unittestreport===================
import unittest
# 安装命令:pip install unittestreport
# 官方文档:https://unittestreport.readthedocs.io/en/latest/#
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase')
from unittestreport import TestRunner
runner = TestRunner(suite,
filename="musen.html",
report_dir="./reports",
title='python自动化研究院生成的报告',
tester='小柠檬',
desc="500万的大项目测试报告",
templates=2
)
runner.run()
执行结果:

·fixture
demo4_fixture.py
"""
测试夹具(测试用例的前后置方法):
setUp:用例级别的前置方法,每条用例执行之前都会执行
setUpClass:测试类级别的前置方法,每个测试类中的用例执行之前都会执行(只会执行一次)
tearDown:用例级别的后置方法,每条用例执行完之后都会执行
tearDownClass:测试类级别的后置方法,每个测试类中的用例全部执行完之后会执行(只会执行一次)
可以做脏数据的处理
"""

问:跑自动化时,执行过程中产生的脏数据如何清理?
# 整个测试用例跑完后,数据用不到了,可以在后置方法里面执行SQL语句删除(如果有数据库执行权限,如无,则脏数据不用你管)
1.3)练习
接口自动化框架演变
测试登录的功能
①登录功能函数
def login_check(username=None, password=None):
"""
登录校验的函数
:param username: 账号
:param password: 密码
:return: dict type
"""
if username != None and password != None:
if username == 'python35' and password == 'lemonban':
return {"code": 0, "msg": "登录成功"}
else:
return {"code": 1, "msg": "账号或密码不正确"}
else:
return {"code": 1, "msg": "所有的参数不能为空"}
if __name__ == '__main__':
# 1、账号密码正确
res = login_check('python35', 'lemonban')
expected = {"code": 0, "msg": "登录成功"}
# if res == expected:
# print("用例:正确的账号密码 --执行通过")
assert res == expected
# 2、密码错误
res = login_check('python35', 'lemonban222')
expected = {"code": 1, "msg": "账号或密码不正确"}
assert res == expected
# if res == expected:
# print("用例:密码错误 --执行通过")
②编写测试用例
import unittest
from work16.work15.myCode import login_check
class TestLogin(unittest.TestCase):
def test_login_pass(self):
"""正向用例:登录成功"""
# 第一步:准备用例数据
params = {'username': "python35", "password": "lemonban"}
expected = {"code": 0, "msg": "登录成功"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_error(self):
"""反向用例:密码错误"""
#第一步:准备用例数据
params = {'username': "python35", "password": "lemonban11"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_error(self):
"""反向用例:账号错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_and_pwd_error(self):
"""反向用例:账号密码都错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban111"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params) # (username="python3522",password="lemonban111")
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_is_none(self):
"""反向用例:账号为空"""
# 第一步:准备用例数据
param = {"password": "lemonban"}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_is_none(self):
"""反向用例:密码为空"""
# 第一步:准备用例数据
params = {'username': 'python35'}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
class TestLogin2(unittest.TestCase):
def test_login_pass(self):
"""正向用例:登录成功"""
# 第一步:准备用例数据
params = {'username': "python35", "password": "lemonban"}
expected = {"code": 0, "msg": "登录成功"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_error(self):
"""反向用例:密码错误"""
#第一步:准备用例数据
params = {'username': "python35", "password": "lemonban11"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_error(self):
"""反向用例:账号错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_and_pwd_error(self):
"""反向用例:账号密码都错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban111"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params) # (username="python3522",password="lemonban111")
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_is_none(self):
"""反向用例:账号为空"""
# 第一步:准备用例数据
param = {"password": "lemonban"}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_is_none(self):
"""反向用例:密码为空""" # 用例方法的文档字符串注释会当成用例的描述,测试报告里面用例描述就是这个
# 第一步:准备用例数据
params = {'username': 'python35'}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
if __name__ == '__main__':
unittest.main()
③执行测试用例并生成报告run.py
import unittest from unittestreport import TestRunner suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work16\work15\testcases') runner = TestRunner(suite, filename="work15.html", report_dir="./reports", title='python自动化大数据研究院生成的报告', tester='小柠檬', desc="大数据测试报告", templates=1 ) runner.run()
2.DDT数据驱动
2.1)unittest中常用的断言方法
| 方法 | 检查 |
|---|---|
| assertEqual(a,b) | a==b |
| assertNotEqual(a,b) | a!=b |
| assertTrue(x) | bool(x) is True |
| assertFalse(x) | bool(x) is False |
| assertIs(a,b) | a is b |
| assertIsNOT(a,b) | a is notb |
| assertIsNone(x) | x is None |
| assertIsNotNone(x) | x is not None |
| assertIn(a,b) | a in b |
| assertNotIn(a,b) | a not in b |
| assertIsInstance(a,b) | isinstance(a,b) |
| assertIsNotInstance(a,b) | not isinstance(a,b) |
| assertGreater(a,b) | a>b |
| assertGreaterEqual(a,b) | a>=b |
| assertLess(a,b) | a<b |
| assertLessEqual(a,b) | a<=b |
# python中非0为True
# 0 0.0 0+0j "" [] {} () False 为False
# 什么地方用?web自动化-点击后是否跳转到对应的页面(找到某个东西则说明进入到了某个页面)
import unittest
class My(unittest.TestCase):
pass
#点击
#TestCase,可以查看到所有的unittest里面的断言方法
2.2)用例数据参数化之ddt
import unittest
from ddt import ddt, data
@ddt
class TestDemo(unittest.TestCase):
# 以测试数据为驱动,生成测试用例,data里面有多少条数据就生成多少条测试用例
# 每一条数据,执行用例时会当成参数传给item接收
@data(1, 22, 3, 4, 5, 6, 7)
def test_login(self, item):
print('item:', item)



2.3)将练习中的测试用例ddt参数化
test_demo1.py
import unittest
from work16.work15.myCode import login_check
from ddt import ddt, data
cases = [
{'params': {'username': "python35", "password": "lemonban"},
'expected': {"code": 0, "msg": "登录成功"}
},
{'params': {'username': "python35", "password": "lemonban11"},
'expected': {"code": 1, "msg": "账号或密码不正确"}
},
{'params': {'username': "python3522", "password": "lemonban"},
'expected': {"code": 1, "msg": "账号或密码不正确"}
},
{'params': {'username': "python3522", "password": "lemonban111"},
'expected': {"code": 1, "msg": "账号或密码不正确"}
},
]
@ddt
class TestLogin(unittest.TestCase):
@data(*cases)
def test_login_pass(self, item):
# 删除备注,因为用例描述信息每一条用例都会一样
print('item:', item) # 通过print输出的内容会在测试报告里面显示出来
# 第一步:准备用例数据
# 解包后参数是字典,所以可以通过key取值
params = item['params']
expected = item['expected']
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params) # 值也是字典,**解包
# 第三步:断言
self.assertEqual(expected, result)
run.py
import unittest from unittestreport import TestRunner suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work16\testcases') # 不传位置,默认在当前目录下生成report.html测试报告 runner = TestRunner(suite) runner.run()
2.4)利用unittestreport模块里面的ddt实现用例描述添加
用例数据是列表(元组)嵌套字典的格式,title字段可以在测试报告里面添加描述
2.4.1 list_data
import unittest
from work16.work15.myCode import login_check
from unittestreport import ddt, list_data
# title会显示在测试报告的用例描述里
cases = [
{'params': {'username': "python35", "password": "lemonban"},
'expected': {"code": 0, "msg": "登录成功"},
'title': "正向用例:登录成功"
},
{'params': {'username': "python35", "password": "lemonban11"},
'expected': {"code": 1, "msg": "账号或密码不正确"},
'title': "反向用例:密码错误"
},
{'params': {'username': "python3522", "password": "lemonban"},
'expected': {"code": 1, "msg": "账号或密码不正确"},
'title': "反向用例:账号错误"
},
{'params': {'username': "python3522", "password": "lemonban111"},
'expected': {"code": 1, "msg": "账号或密码不正确"},
'title': "反向用例:账号密码都错误"
},
]
@ddt
class TestLogin2(unittest.TestCase):
# 不需要解包
@list_data(cases)
def test_login_pass(self, item):
print('item:', item)
# 第一步:准备用例数据
params = item['params']
expected = item['expected']
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
2.4.2 json_data
①单独创建一个json文件,放到data文件夹里:login.json
②利用json_data编写测试用例
login.json
[
{"params": {"username": "python35", "password": "lemonban"},
"expected": {"code": 0, "msg": "登录成功"},
"title": "正向用例:登录成功"
},
{"params": {"username": "python35", "password": "lemonban11"},
"expected": {"code": 1, "msg": "账号或密码不正确"},
"title": "反向用例:密码错误"
},
{"params": {"username": "python3522", "password": "lemonban"},
"expected": {"code": 1, "msg": "账号或密码不正确"},
"title": "反向用例:账号错误"
},
{"params": {"username": "python3522", "password": "lemonban111"},
"expected": {"code": 1, "msg": "账号或密码不正确"},
"title": "反向用例:账号密码都错误"
}
]
test_demo.py
import unittest
from work16.work15.myCode import login_check
from unittestreport import ddt, json_data
"""
json格式数据和python数据的不同点:
python中的列表 :[] ---->在json中叫做数组 Array
python中的字典 :{key:value} ---->在json中叫做对象 object
python中的布尔值:True False ---->在json中的布尔值 true false
python中的空值:None ---->在json中的布尔值 null
json中的引号 统一使用双引号
关于使用unittestreport中json文件数据做参数化处理:
第一步:from unittestreport import ddt, json_data
第二步:在测试类上面@ddt
第三步:在测试方法上面@json_data,传入json数据文件的路径
第四步:在测试方法中定义一个参数,用来接收json_data传递过来的用例数据
注意点:json文件中的数据 要是数组(列表)嵌套对象(字典)的格式
"""
@ddt
class TestLoginJson(unittest.TestCase):
# 传入json文件的用例数据
@json_data(r'D:\autotest\pythonn-api-test0\work16\data\login.json')
def test_login_json(self, item):
print(item) # 用例描述
# 第一步:准备用例数据
params = item['params']
expected = item['expected']
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
·python数据转换为json-序列化
json数据和python中数据类型的转换
1、json.dumps():将python中的数据转换为 json数据
2、json.loads():将json数据转换为python中的数据
3、json.load():加载json文件,转换为python对应的数据格式
4、json.dump():将python数据,写入json文件(自动化转换格式)

⭐ crtl+R 在login.json文档里可以进行字符替换
⭐ json语法:JSON 语法 | 菜鸟教程
·将json数据转换为python数据-反序列化
json.loads():将json数据转换为python中的数据



·加载json文件,转换为python对应的数据格式
json.load():加载json文件,转换为python对应的数据格式
test.json


·将python数据,写入json文件(自动转换格式)
运行完后在指定路径产生data.json()文件
![]()


2.4.3 yaml_data
⭐没讲,看官网
yaml文件格式:
- 表示列表
键值对开头表示字典
:后面有个空格

pip install pyyaml
·yaml文件的读取
data.yaml
- 11 - 22 - 33 - 44 - age: '18' name: musen
data2.yaml
name: musen
age: 18
lists:
- 11
- 22
- 33
- 44
- 55
cases:
params: 111
expected: 22

# 把文本格式的数据转换成对应的python数据(列表或字典)
![]()

·将python数据写入yaml文件
import yaml
cases = [
{"excepted": {"code": 1, "msg": "注册成功"},
"params": ['python3', '123456', '123456'],
"title": "注册成功"
},
{"excepted": {"code": 0, "msg": "两次密码不一致"},
"params": ['python4', '1234567', '123456'],
"title": "两次密码不一致"
},
{"excepted": {"code": 0, "msg": "该账户已存在"},
"params": ['python31', '123456', '123456'],
"title": "账号已注册"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python1', '12345', '12345'],
"title": "密码长度少于6位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python21', '1234561234561234567', '1234561234561234567'],
"title": "密码长度大于18位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['py012', '1234567', '1234567'],
"title": "账号长度少于6位"
}
]
with open('musen.yaml', 'w', encoding='utf-8') as f:
yaml.dump(cases, f, allow_unicode=True)
2.4.4 练习:用例数据与测试代码分离
①要测试的代码:myCode.py
②测试用例:testcase文件下以test_开头的py文件
③测试数据:data文件下的用例数据文件
④run.py
①myCode.py
##
#
users = [{'user': 'python31', 'password': '123456'}]
def register(username=None, password1=None, password2=None):
# 判断是否有参数为空
if not all([username, password1, password2]):
return {"code": 0, "msg": "所有参数不能为空"}
# 注册功能
for user in users: # 遍历出所有账号,判断账号是否存在
if username == user['user']:
# 账号存在
return {"code": 0, "msg": "该账户已存在"}
else:
if password1 != password2:
# 两次密码不一致
return {"code": 0, "msg": "两次密码不一致"}
else:
# 账号不存在 密码不重复,判断账号密码长度是否在 6-18位之间
if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18:
# 注册账号
users.append({'user': username, 'password': password2})
return {"code": 1, "msg": "注册成功"}
else:
# 账号密码长度不对,注册失败
return {"code": 0, "msg": "账号和密码必须在6-18位之间"}
②test_demo.py
import unittest
from work17.work16.myCode import register
from unittestreport import ddt, list_data
cases = [
{"excepted": {"code": 1, "msg": "注册成功"},
"params": ['python3', '123456', '123456'],
"title": "注册成功"
},
{"excepted": {"code": 0, "msg": "两次密码不一致"},
"params": ['python4', '1234567', '123456'],
"title": "两次密码不一致"
},
{"excepted": {"code": 0, "msg": "该账户已存在"},
"params": ['python31', '123456', '123456'],
"title": "账号已注册"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python1', '12345', '12345'],
"title": "密码长度少于6位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python21', '1234561234561234567', '1234561234561234567'],
"title": "密码长度大于18位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['py012', '1234567', '1234567'],
"title": "账号长度少于6位"
}
]
@ddt
class RegisterTestCase(unittest.TestCase):
@list_data(cases)
def test_register(self, item):
"""正常注册"""
# 第一步:准备用例的数据
# 预期结果:
excepted = item['excepted']
# 参数:data
data = item['params']
# 第二步:调用被测试的功能函数,传入参数,获取实际结果:
# 对列表拆包,用一个*
res = register(*data)
# 第三步:断言(比对预期结果和实际结果)
self.assertEqual(excepted, res)
③run.py
# unittest调用默认加载器defaultTestLoader,加载用例
import unittest from unittestreport import TestRunner # 相对路径,传入当前目录下的testcase目录,加载用例到测试套件 # 运行文件run.py和测试目录在同一级别用. suite = unittest.defaultTestLoader.discover(r".\testcase") # 创建一个用例运行器,传入测试套件 runner = TestRunner(suite) # 调用运行器的run方法执行用例 runner.run()

3.python操作excel
pip install openpyxl
只能执行xlsx的excel文件
excel中的三大对象:

3.1)excel文件读写
import openpyxl # 1、加载excel文件为一个工作簿对象(workbook) wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx') # print(wb) # ①是一个Workbook对象 # 2、选中要读取的表单 login_sh = wb['login'] # ②是一个表单对象 print(login_sh) # 打印表单对象 <Worksheet "login"> # 3、读取表格中的数据(通过指定行,列取获取格子对象) res = login_sh.cell(row=1,column=1) # ③cell是一个表格对象 print(res) # 打印格子对象 ,选中第一行第一列这个格子<Cell 'login'.A1> # 4、获取格子中的数据(格子对象的value属性) data = res.value print(data) # 5、往表格中写入数据,只是写入到工作簿对象里面 login_sh.cell(row=3,column=2,value='java666') # 6、将最新的工作薄对象保存为文件,保存之后写入才成功 wb.save(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
3.2)批量读取表单中的数据
import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\①testing\⑤autotest\api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['login']
# 3、按行获取表单所有的格子对象--获取出来的数据是列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
"""
[
(<Cell 'login'.A1>, <Cell 'login'.B1>, <Cell 'login'.C1>),
(<Cell 'login'.A2>, <Cell 'login'.B2>, <Cell 'login'.C2>),
(<Cell 'login'.A3>, <Cell 'login'.B3>, <Cell 'login'.C3>)
]
"""
# # 遍历读取出来的所有数据
# for item in datas:
# # 遍历出来的item 是每行的所有格子对象
# print(item)
# for c in item:
# # c 是一个格子对象
# print(c.value)
# -----------------需求,将所有的数据读取出来组装为列表嵌套列表的格式------------
new_list = []
# 4、遍历读取出来的数据
for item in datas:
li = []
# 遍历出来的item 是每行的所有格子对象
for c in item:
# c 是一个格子对象
li.append(c.value)
print('li:', li)
# 将这一行的数据添加到new_list中
new_list.append(li)
print(new_list)

3.3)列表推导式
# 1、for循环往列表中添加数据
li = []
for i in range(5):
li.append('python{}'.format(i))
print(li)
# 2、列表推导式
li = ['python{}'.format(i) for i in range(5)]
print(li)
3.4)批量读取表单数据-优化版
import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['login']
# 3、按行获取表单所有的格子对象--获取出来的数据时列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
# 4、通过推导式的语法读取表单中的数据
new_list = []
# 遍历读取出来的数据
for item in datas:
li = [c.value for c in item]
new_list.append(li)
print(new_list)
# new_list = [[c.value for c in item] for item in datas]
# print(new_list)
3.5)读取excel中的用例数据

import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['register']
# 3、按行获取表单所有的格子对象--获取出来的数据时列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
# 4、通过推导式的语法读取表单中的数据
new_list = []
# 遍历读取出来的数据
for item in datas:
li = [c.value for c in item]
new_list.append(li)
# print(new_list)
"""
[
['case_id', 'title', 'params', 'expected'],
[1, '注册成功', "['python3', '123456', '123456']", '{"code": 1, "msg": "注册成功"}'],
[2, '两次密码不一致', "['python4', '1234567', '123456']", '{"code": 0, "msg": "两次密码不一致"}'],
[3, '账号已注册', "['python31', '123456', '123456']", '{"code": 0, "msg": "该账户已存在"}'],
[4, '密码长度少于6位', "['python1', '12345', '12345']", '{"code": 0, "msg": "账号和密码必须在6-18位之间"}']
]
"""
title = new_list[0]
# print('title:', title)
cases =[]
for i in new_list[1:]:
res = dict(zip(title, i))
cases.append(res)
print(cases)

3.6)读取excel中的用例数据-优化版
一个循环实现:
import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['register']
# 3、按行获取表单所有的格子对象--获取出来的数据时列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
# 4、通过推导式的语法读取表单中的数据
new_list = []
# 5、获取表头的数据
title = [i.value for i in datas[0]]
# 6、遍历表头以外的其他行数据
for item in datas[1:]:
# 获取遍历出来的行中所有的数据
li = [c.value for c in item]
# 和表头打包为字典
d = dict(zip(title,li))
# 将打包的字典,添加搭配new_list中
new_list.append(d)
print(new_list)
# 可以用eval去掉params值的引号

3.7)封装excel读取数据类
excel文档注意点:不要在用例表格里面的其他地方填写空格,不然会导致读取出许多空行或空列的数据。
"""
封装的需求:
1、方便读取excel中的数据
封装的方法:
1、封装一个读数据的方法
入参:
读取的文件(文件路径)
读取的表单(表单名)
返回值:
读取出来组装好的数据
2、写入数据的方法
入参:文件,表单,行,列,写入的值
"""
import openpyxl
class ExcelHandle:
def read_data(self, filepath, sheet):
"""
读取excel数据的方法
:param filepath: 读取的文件(文件路径)
:param sheet: 读取的表单(表单名)
:return:
"""
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filepath)
# 2、选中表单
sh = wb[sheet]
# 3、按行获取所有的格子对象
rows_list = list(sh.rows)
# 4、获取表头
title = [i.value for i in rows_list[0]]
cases = []
# 5、遍历表头外的其他行
for item in rows_list[1:]:
# 获取遍历出来这一行的所有数据,放到列表中
li = [i.value for i in item]
# 将表头和这一行的数据打包,转换为字典
res = dict(zip(title, li))
cases.append(res)
return cases
def write_data(self, filepath, sheet, row, column, value):
"""
:param filepath: 要写入的excel文件路径
:param sheet: 表单名
:param row: 行
:param column: 列
:param value: 写入的值
:return:
"""
# 1、加载excel文件为一个工作薄对象
wb = openpyxl.load_workbook(filepath)
# 2、选取要操作的表单
sh = wb[sheet]
# 3、写入值
# sh.cell(row=row, column=column, value=value)
sh.cell(row, column).value = value
# 4、将工作薄保存为文件
wb.save(filepath)
if __name__ == '__main__':
excel = ExcelHandle()
data = excel.read_data(r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx', 'register')
# print(data)
file = r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx'
# excel.write_data(file, 'Sheet2', 1, 1, 'python')
excel.write_data(file, 'login', 3, 4, '自动化测试')
3.8)封装excel读取数据类-优化版
运行写操作,要关闭excel文件

# 文件名在创建对象的时候就传进入,通过实例属性保存起来
"""
封装的需求:
1、方便读取excel中的数据
封装的方法:
1、封装一个读数据的方法
入参:
读取的文件(文件路径)
读取的表单(表单名)
返回值:
读取出来组装好的数据
2、写入数据的方法
入参:文件,表单,行,列,写入的值
"""
import openpyxl
class ExcelHandle:
def __init__(self, filepath):
"""
:param filepath: 要操作的文件
"""
self.file = filepath
def read_data(self, sheet):
"""
读取excel数据的方法
:param sheet: 读取的表单(表单名)
:return:
"""
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(self.file)
# 2、选中表单
sh = wb[sheet]
# 3、按行获取所有的格子对象
rows_list = list(sh.rows)
# 4、获取表头
title = [i.value for i in rows_list[0]]
cases = []
# 5、遍历表头外的其他行
for item in rows_list[1:]:
# 获取遍历出来这一行的所有数据,放到列表中
li = [i.value for i in item]
# 将表头和这一行的数据打包,转换为字典
res = dict(zip(title, li))
cases.append(res)
return cases
def write_data(self, sheet, row, column, value):
"""
:param sheet: 表单名
:param row: 行
:param column: 列
:param value: 写入的值
:return:
"""
# 1、加载excel文件为一个工作薄对象
wb = openpyxl.load_workbook(self.file)
# 2、选取要操作的表单
sh = wb[sheet]
# 3、写入值
# sh.cell(row=row, column=column, value=value)
sh.cell(row, column).value = value
# 4、将工作薄保存为文件
wb.save(self.file)
if __name__ == '__main__':
excel = ExcelHandle(r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx')
data = excel.read_data('register')
data2 = excel.read_data('login')
excel.write_data('login', 4, 1, '木森')
3.9)用例与数据分离
debug查看数据类型

将字符串eval成对应类型的数据

# excel格子里面是纯数字读取出来就是数值类型,其他数据读取出来都是字符串
# 如果里面的数据比较复杂,比如又null true要进行转化的,就用loads
# 回写测试结果到excel
import unittest
from work18.demo2_excelhandle import ExcelHandle
from unittestreport import ddt, list_data
from work18.myCode import register
# 读取excel中的用例数据
excel = ExcelHandle(r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx')
cases = excel.read_data('register')
""" 通过用例编号获取行号 """
# @ddt
# class TestRegister(unittest.TestCase):
#
# @list_data(cases)
# def test_register(self, item):
# # 第一步:准备用例数据
# # 如果参数中有true null等使用json.loads
# params = eval(item['params'])
# expected = eval(item['expected'])
# case_id = item['case_id']
# # 第二步:调用对应de测试函数(请求接口),获取返回的实际结果
# result = register(*params)
# try:
# # 第三步:比对预期和实际结果是否一致(断言)
# self.assertEqual(expected, result)
# except AssertionError as e:
# excel.write_data('register', row=case_id + 1, column=5, value='执行不通过')
# print('不通过')
# # 捕获到断言异常之后,一定要使用raise抛出异常,不然unittest监测不到这是一条失败的用例
# raise e
# else:
# excel.write_data('register', row=case_id + 1, column=5, value='通过')
# print('通过')
""" 通过索引获取行号,索引从0开始,与行号相差2"""
@ddt
class TestRegister(unittest.TestCase):
@list_data(cases)
def test_register(self, item):
# 第一步:准备用例数据
params = eval(item['params'])
expected = eval(item['expected'])
# 获取行号,用列表的index方法
r = cases.index(item) + 2
# 第二步:调用对应点测试函数(请求接口),获取返回的实际结果
result = register(*params)
try:
# 第三步:比对预期和实际结果是否一致(断言)
self.assertEqual(expected, result)
except AssertionError as e:
excel.write_data('register', row=r, column=5, value='执行不通过')
# 捕获到断言异常之后,一定要使用raise抛出异常,不然unittest是监测不到这是一条失败的用例
raise e
else:
excel.write_data('register', row=r, column=5, value='通过')
3.10)新-批量获取
3.10.1 获取表格所有数据

3.10.2 获取部分数据

3.10.3 excel数据格式

4.配置文件的使用
ini、conf、cfg
配置块:section
配置项:option

配置文件解析器 configparser --- 配置文件解析器 — Python 3.12.1 文档
4.1)配置文件解析器
from configparser import ConfigParser filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini' # 创建一个配置文件解析器对象 conf = ConfigParser() # 通过解析器去解析配置文件 conf.read(filepath, encoding='utf-8') # 返回的是配置文件名称,可以不接收 # 读取配置文件中的配置
# 1、get方法:读取出来的数据是字符串
res = conf.get('mysql', 'port')
print(res)

# 2、getint : # ----->int(get()) 只能读取数值
res = conf.getint('mysql', 'user')
print(res, type(res))
# 3、getfloat : # ----->float(get())
res = conf.getfloat('mysql', 'port')
print(res, type(res))
# 4、getboolean: # ----->bool(get),只能读取bool值
res = conf.getboolean('mysql', 'status')
print(res,type(res))
4.2)配置文件的写入操作
# 了解即可
from configparser import ConfigParser
# 1、创建一个配置文件解析器对象
conf = ConfigParser()
# 2、通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
# 3、往配置文件中写入数据,section option value
conf.set('logging', 'name', 'p99999999999999')
# 4、将写入的内容保存到配置文件
with open(filepath, 'w', encoding='utf-8') as f:
conf.write(f)
4.3)配置文件常用方法


4.3.1)获取配置文件所有的配置块
from configparser import ConfigParser
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
# ①获取配置文件中所有的配置块
sections = conf.sections()
print(sections)
if 'db' in sections:
res = conf.get('db', 'port')
print(res)
else:
res = 'report.log'
4.3.2)获取指定的配置块下面所有的配置项
from configparser import ConfigParser
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
res = conf.options('mysql')
print(res) # 获取某配置块下所有的配置项
if 'db' in conf.sections() and 'port' in conf.options('db'):
res = conf.get('db', 'port')
print(res)
else:
res = 'report.log'
4.3.3)获取配置块下面所有的配置项和值
from configparser import ConfigParser
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
# 列表嵌套元组
res = conf.items('mysql')
print(res)
# 转换为字典
res = dict(conf.items('mysql'))
print(res)


4.4)配置文件操作的封装
from configparser import ConfigParser
class CfgParser(ConfigParser):
# 重写配置文件解释器对象ConfigParser里面的init方法
def __init__(self, file, encoding='utf-8'):
# 调用被重写的父类方法
super().__init__()
# 初始化时候就把配置文件对象传入进来,加载配置文件到配置文件解析器
# 因为只有read方法使用了file,所以不用单独保存file属性
# 如果封装了一个写入的方法,就可以将file属性保存
# 封装就是简化加载那一步(要加载再读)
self.read(file, encoding=encoding)
if __name__ == '__main__':
conf = CfgParser(r'D:\autotest\pythonn-api-test0\work18\data\musem.ini')
# 要解析哪个配置文件,直接传给conf就可以了;初始化后,就已经创建了一个配置文件解析器,可以直接读取配置文件内容,不用再调用read方法去加载了
res = conf.get('mysql', 'user')
print(res)
5.logging日志模块


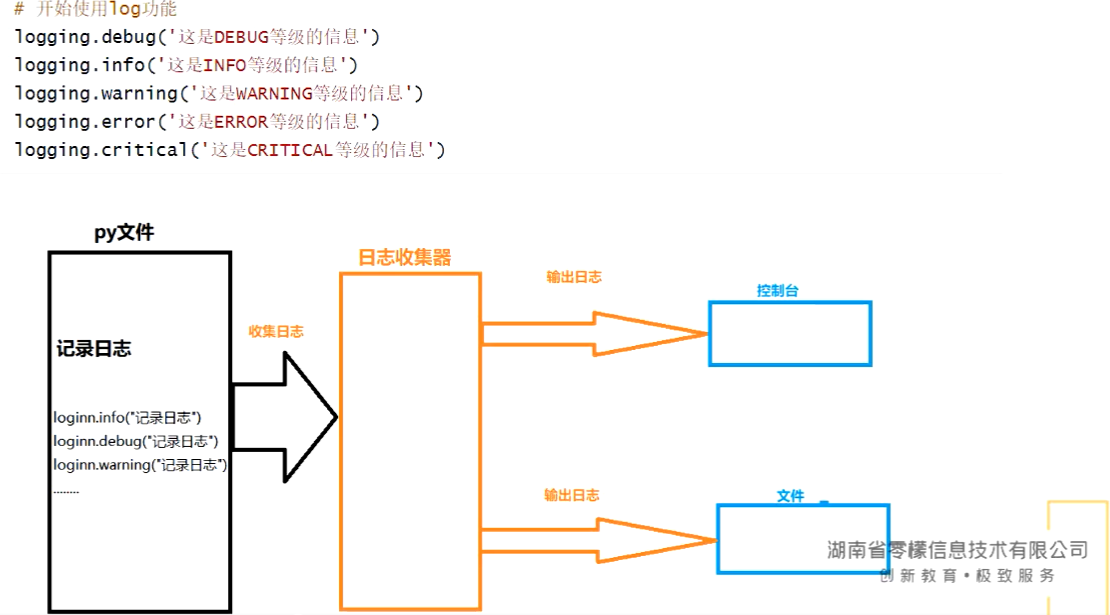
5.1)logging模块的基本使用


5.2)创建日志收集器

import logging
# 日志收集器的创建:logging.getLogger(日志收集器名称)
http_log = logging.getLogger('HTTP')
# 设置日志收集的等级为DEBUG,还要设置日志输出的等级。。
http_log.setLevel('DEBUG')
http_log.debug('----------DEBUG----------')
http_log.info('----------info----------')
http_log.warning('----------warning----------')
http_log.error('----------error----------')
http_log.critical('----------critical----------')
# 自己创建的日志收集器没有设置日志输出格式:只输出日志内容

5.3)创建日志输出渠道:控制台
import logging
# 1、日志收集器的创建:logging.getLogger(日志收集器名称)
http_log = logging.getLogger('HTTP')
# 2、设置日志收集的等级为DEBUG
http_log.setLevel('DEBUG')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
http_log.debug('----------DEBUG-------------')
http_log.info('----------info-------------')
http_log.warning('----------warning-------------')
http_log.error('----------error-------------')
http_log.critical('----------critical-------------')

5.4)创建日志输出渠道:文件

import logging
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger('HTTP')
# 2、设置日志收集的等级为DEBUG
http_log.setLevel('DEBUG')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(文件)
# fh = logging.FileHandler('musen.log', encoding='utf-8')
fh = logging.FileHandler(r'D:\①testing\⑤autotest\api-test0\work19\logs\lemon.log', encoding='utf-8')
fh.setLevel('ERROR')
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
http_log.debug('----------DEBUG---人人----------')
http_log.info('----------info---哈哈----------')
http_log.warning('----------warning---啊啊----------')
http_log.error('----------error---嗷嗷的----------')
http_log.critical('----------critical---哎哎哎----------')

# pycharm设置的文件默认是utf-8编码格式打开,创建日志输出渠道的时候没有设置输出到文件的编码格式,默认会是GBK
# 自动生成一个日志文件

5.5)设置日志输出的格式


import logging
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger('HTTP')
# 2、设置日志收集的等级为DEBUG
http_log.setLevel('DEBUG')
# 创建一个日志输出的格式
mat= logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(文件)
fh = logging.FileHandler(r'D:\autotest\api-test0\work19\logs\lemon.log', encoding='utf-8')
fh.setLevel('ERROR')
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
http_log.debug('----------DEBUG---人人----------')
http_log.info('----------info---哈哈----------')
http_log.warning('----------warning---啊啊----------')
http_log.error('----------error---嗷嗷的----------')
http_log.critical('----------critical---哎哎哎----------')


# 可以查看Formatter源码看他的日志格式怎么设置


5.6)封装日志收集器
import logging
def create_logger(name, level, f_level, s_level, filepath):
"""
创建日志收集器
:param name: 日志收集器的名称
:param level: 收集器的收集等级
:param f_level: 输出到文件的等级
:param s_level: 输出到控制台的等级
:param filepath: 日志文件的名称
:return:
"""
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger(name)
# 2、设置日志收集的等级为DEBUG
http_log.setLevel(level)
# 创建一个日志输出的格式
mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel(s_level)
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(文件)
fh = logging.FileHandler(filepath, encoding='utf-8')
fh.setLevel(f_level)
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
return http_log
log = create_logger(xxx)
if __name__ == '__main__':
# 封装的文件里面已经调用了create_logger函数,下面就不需要再调用一次了
# log = create_logger(name='MUSEN', level='DEBUG', f_level='DEBUG', s_level='DEBUG', filepath='./lemonban.log')
log.debug('这是DEBUG等级的信息')
log.info('这是INFO等级的信息')
log.warning('这是WARNING等级的信息')
log.error('这是ERROR等级的信息')
log.critical('这是CRITICAL等级的信息')
# 还未分离出参数时,未参数化时在别的地方调用日志函数log对象

⭐不在模块里面调用函数时,在测试用例中引用参数化后的日志
from demo7_logger import create_logger
log = create_logger(name='MUSEN', level='DEBUG', f_level='DEBUG', s_level='DEBUG', filepath='./lemonban.log')
log.debug('这是DEBUG等级的信息')
log.info('这是INFO等级的信息')
log.warning('这是WARNING等级的信息')
log.error('这是ERROR等级的信息')
log.critical('这是CRITICAL等级的信息')
5.7)日志轮转器


import logging
from logging.handlers import RotatingFileHandler, TimedRotatingFileHandler
# def create_logger(name, level, f_level, s_level, filepath):
# """
# 创建日志收集器(按文件大小进行轮转)
# :param name: 日志收集器的名称
# :param level: 收集器的收集等级
# :param f_level: 输出到文件的等级
# :param s_level: 输出到控制台的等级
# :param filepath: 日志文件的名称
# :return:
# """
# # 1、日志收集器的创建:logging.getLogger(名称)
# http_log = logging.getLogger(name)
# # 2、设置日志收集的等级为DEBUG
# http_log.setLevel(level)
# # 创建一个日志输出的格式
# mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# # 3、创建一个日志输出渠道(控制台)
# sh = logging.StreamHandler()
# sh.setLevel(s_level)
# sh.setFormatter(mat)
# # 4、将日志输出渠道添加到日志收集器中
# http_log.addHandler(sh)
# # 5、创建一个日志输出渠道(输出到文件的轮转器)
# fh = RotatingFileHandler(filepath, maxBytes=1024*1024*10, backupCount=3, encoding='utf-8')
# fh.setLevel(f_level)
# fh.setFormatter(mat)
# # 6、将日志输出渠道添加到日志收集器
# http_log.addHandler(fh)
# return http_log
def create_logger(name, level, f_level, s_level, filepath):
"""
创建日志收集器(按时间进行轮转)
:param name: 日志收集器的名称
:param level: 收集器的收集等级
:param f_level: 输出到文件的等级
:param s_level: 输出到控制台的等级
:param filepath: 日志文件的名称
:return:
"""
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger(name)
# 2、设置日志收集的等级为DEBUG
http_log.setLevel(level)
# 创建一个日志输出的格式
mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel(s_level)
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(输出到文件的轮转器)
# 按时间轮转
fh = TimedRotatingFileHandler(filepath, encoding='utf-8', when='S', interval=2, backupCount=7)
fh.setLevel(f_level)
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
return http_log
log = create_logger(name='MUSEN', level='DEBUG', f_level='DEBUG', s_level='DEBUG', filepath='./logs/lemonban.log')
if __name__ == '__main__':
import time
###
log.debug('这是DEBUG等级的信息')
time.sleep(1)
log.info('这是INFO等级的信息')
time.sleep(1)
log.warning('这是WARNING等级的信息')
time.sleep(1)
log.error('这是ERROR等级的信息')
time.sleep(1)
log.critical('这是CRITICAL等级的信息')
5.8)loguru库

生成日志文件:

3.简单框架编写
3.1)框架模型分析

3.2)分层设计


3.3)数据驱动
![]()
3.4)代码编写
1.common
handle_excel.py
"""
封装读取excel数据的方法
"""
import openpyxl
class ExcelHandle:
def __init__(self, filepath):
"""
:param filepath: 要操作的文件
"""
self.file = filepath
def read_data(self, sheet):
"""
读取excel数据的方法
:param sheet: 读取的表单(表单名)
:return:
"""
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(self.file)
# 2、选中表单
sh = wb[sheet]
# 3、按行获取所有的格子对象
rows_list = list(sh.rows)
# 4、获取表头
title = [i.value for i in rows_list[0]]
cases = []
# 5、遍历表头外的其他行
for item in rows_list[1:]:
# 获取遍历出来这一行的所有数据,放到列表中
li = [i.value for i in item]
# 将表头和这一行的数据打包,转换为字典
res = dict(zip(title, li))
cases.append(res)
return cases
def write_data(self, sheet, row, column, value):
"""
:param sheet: 表单名
:param row: 行
:param column: 列
:param value: 写入的值
:return:
"""
# 1、加载excel文件为一个工作薄对象
wb = openpyxl.load_workbook(self.file)
# 2、选取要操作的表单
sh = wb[sheet]
# 3、写入值
# sh.cell(row=row, column=column, value=value)
sh.cell(row, column).value = value
# 4、将工作薄保存为文件
wb.save(self.file)
handle_log.py
import logging
from logging.handlers import TimedRotatingFileHandler
from conf.settings import LOG
def create_logger(name, level, f_level, s_level, filepath):
"""
创建日志收集器(按时间进行轮转)
:param name: 日志收集器的名称
:param level: 收集器的收集等级
:param f_level: 输出到文件的等级
:param s_level: 输出到控制台的等级
:param filepath: 日志文件的名称
:return:
"""
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger(name)
# 2、设置日志收集的等级为DEBUG
http_log.setLevel(level)
# 创建一个日志输出的格式
mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel(s_level)
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(输出到文件的轮转器)
fh = TimedRotatingFileHandler(filepath, encoding='utf-8', when='D', interval=1, backupCount=7)
fh.setLevel(f_level)
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
return http_log
log = create_logger(**LOG)
2.conf
settings.py
# 日志输出的相关配置
LOG = {
'name': 'MUSEN',
'level': 'DEBUG',
'f_level': 'DEBUG',
's_level': 'ERROR',
'filepath': 'D:\\①testing\\⑤autotest\\api-test1\\logs\\lemonban.log'
}
3.datas
data.xlsx

4.logs
lemon.log
5.reports
report_dir='./reports'
6.testcases
test_register.py
import unittest
from common.handle_excel import ExcelHandle
from unittestreport import ddt, list_data
from myCode import register
from common.handle_log import log
excel = ExcelHandle(r'D:\①testing\⑤autotest\api-test1\datas\data.xlsx')
cases = excel.read_data('register')
@ddt
class TestRegister(unittest.TestCase):
@list_data(cases)
def test_register(self, item):
# 第一步:准备数据
params = eval(item['params'])
expected = eval(item['expected'])
# 第二步:调用功能函数(调用接口),获取实际结果
result = register(*params)
log.info('预期结果:{}'.format(expected))
log.info('实际结果:{}'.format(result))
# 第三:断言
try:
self.assertEqual(expected, result)
except AssertionError as e:
log.error('【{}】-- 用例执行失败'.format(item['title']))
# 输出断言的异常信息
# log.error(e)
log.exception(e)
raise e
else:
log.info('【{}】--用例执行成功'.format(item['title']))
# ⭐用log.error(e)

# ⭐用log.exception(e)异常对象 更详细
7.run.py
run.py
import unittest from unittestreport import TestRunner suite = unittest.defaultTestLoader.discover(r'D:\①testing\⑤autotest\api-test1\testcases') runner = TestRunner(suite,report_dir='./reports') runner.run()
⭐被测函数myCode.py
users = [{'user': 'python31', 'password': '123456'}]
def register(username=None, password1=None, password2=None):
# 判断是否有参数为空
if not all([username, password1, password2]):
return {"code": 0, "msg": "所有参数不能为空"}
# 注册功能
for user in users: # 遍历出所有账号,判断账号是否存在
if username == user['user']:
# 账号存在
return {"code": 0, "msg": "该账户已存在"}
else:
if password1 != password2:
# 两次密码不一致
return {"code": 0, "msg": "两次密码不一致"}
else:
# 账号不存在 密码不重复,判断账号密码长度是否在 6-18位之间
if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18:
# 注册账号
users.append({'user': username, 'password': password2})
return {"code": 1, "msg": "注册成功"}
else:
# 账号密码长度不对,注册失败
return {"code": 0, "msg": "账号和密码必须在6-18位之间"}














 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









