






1.获取数据:
想要获得道指30只成分股的最新股价
importrequestsimportreimportpandas as pddefretrieve_dji_list():try:
r= requests.get('https://money.cnn.com/data/dow30/')exceptConnectionError as err:print(err)
search_pattern= re.compile('class="wsod_symbol">(.*?).*?(.*?).*? .*?class="wsod_stream">(.*?)')
dji_list_in_text=re.findall(search_pattern, r.text)
dji_list=[]for item indji_list_in_text:
dji_list.append([item[0], item[1], float(item[2])])returndji_list
dji_list=retrieve_dji_list()
djidf=pd.DataFrame(dji_list)print(djidf)
整理数据, 改变列名, index等
cols=['code','name','lasttrade']
djidf.columns=cols #改变列名
djidf.index=range(1,len(djidf)+1)
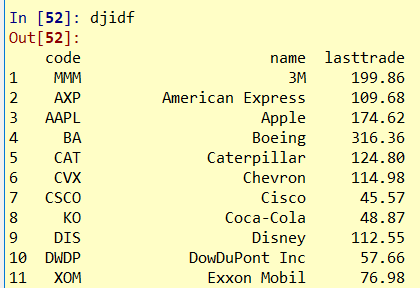
最后结果为:
数据的选择
djidf.code #获取code列+index
djidf['code'] #获取code列 , 两者同功能
djidf.loc[1:5,] #前5行
djidf.loc[:,['code','lasttrade']] #所有行
djidf.loc[1:5,['code','lasttrade']] #1-5行, loc表示标签index
djidf.loc[1,[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









