








-
作者:Yunzhe Xu, Yiyuan Pan, Zhe Liu, Hesheng Wang
-
单位: 上海交通大学人工智能学院,上海交通大学自动化系
-
论文标题:FLAME: Learning to Navigate with Multimodal LLM in Urban Environments
-
论文链接:https://arxiv.org/pdf/2408.11051
-
代码链接:https://github.com/xyz9911/FLAME
主要贡献
-
引入FLAME:提出了第一个基于多模态大语言模型(MLLM)的智能体FLAME,用于城市视觉语言导航(VLN)任务。
-
三阶段调优技术:提出了一种定制的三阶段调优技术,通过合成数据将Flamingo模型适应导航场景,充分释放MLLM的潜力。
-
实验验证:实验结果表明,FLAME在Touchdown和Map2seq数据集上显著优于SOAT方法,证明了MLLM在复杂导航任务中的潜力。
研究背景
研究问题
论文主要解决的问题是如何在城市环境中利用多模态大模型(MLLMs)进行视觉语言导航(VLN)。
尽管大模型在一般对话场景中表现出色,但在专门的导航任务中表现不佳,与专门的VLN模型相比存在性能差距。
研究难点
-
信息丢失:将视觉数据转换为语言时,视觉基础模型可能导致信息丢失。
-
计算资源:处理观察结果需要多次前向传递和大量计算资源。
-
户外导航挑战:户外导航的轨迹长度更长,难度更大,成功率比室内导航任务低40%。
相关工作
-
视觉语言导航:大多数进展集中在室内环境,传统VLN智能体缺乏高级决策能力。
-
多模态大模型:MLLMs在多种任务中展示了多模态推理能力,但在专家导航任务中的通用预训练不足。
-
数据增强:为了克服导航中的数据稀缺问题,提出了各种数据增强技术,但在户外导航中使用辅助训练数据来定制MLLMs的研究较少。
研究方法
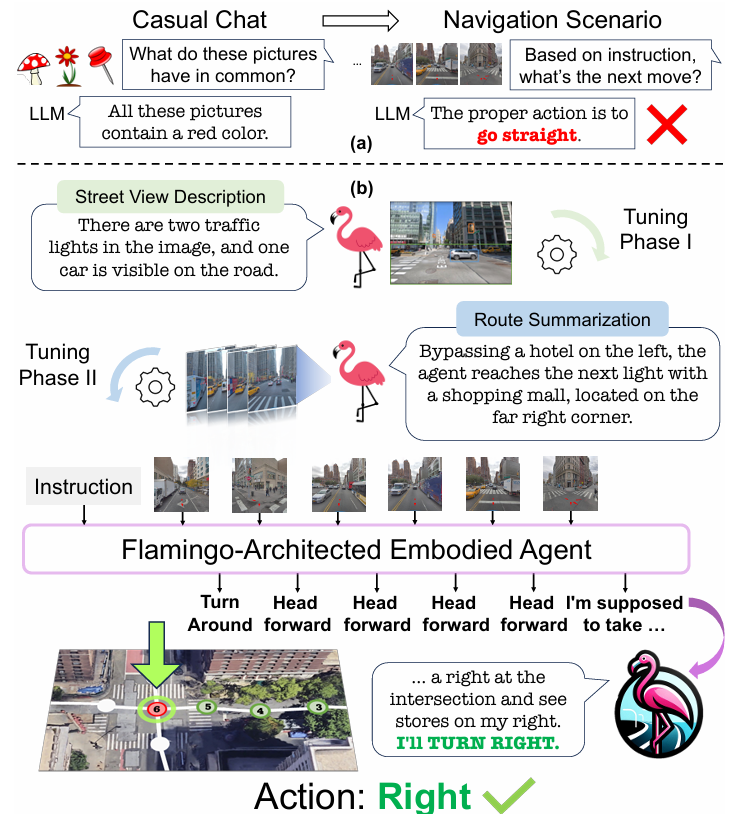
论文提出了FLAME(FLAMingo-Architected Embodied Agent),用于城市VLN任务的多模态大模型。
FLAME 架构
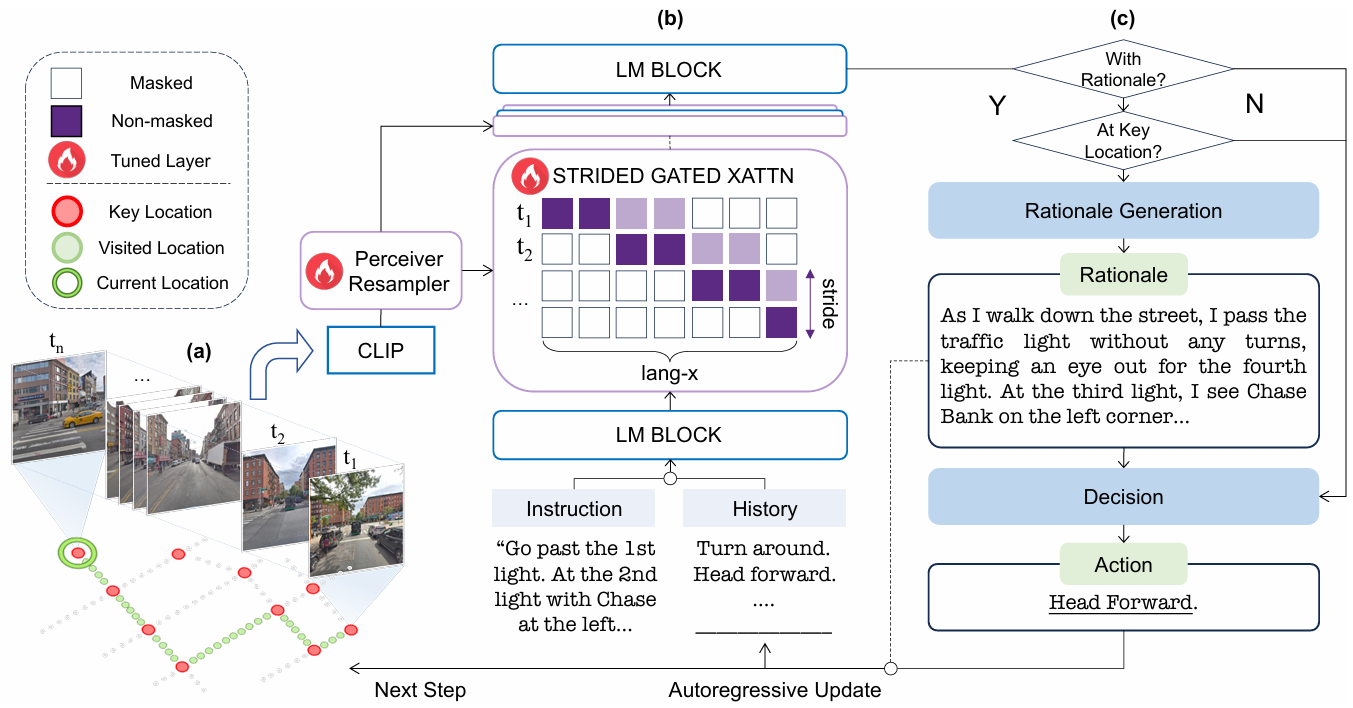
FLAME 基于 Flamingo 架构,利用交叉注意力来处理视觉和文本输入,而不增加上下文长度。为了适应城市 VLN 任务,FLAME 对 Flamingo 进行了两项关键改进:
-
Strided Cross-Attention:
-
为了处理城市 VLN 中的大量观察结果,FLAME 在交叉注意力层中实现了步幅交叉注意力。
-
这种方法通过减少需要处理的观察数量来优先考虑最近的观察结果,从而提高系统在动态环境中识别重要特征的能力。
-
-
动作预测:
-
FLAME 根据当前观察、历史观察和指令来预测动作。默认情况下,下一个动作是通过 MLLM 模型生成的。
-
此外,FLAME 还可以在关键位置(如交叉路口)生成理由,以提高智能体和可解释性。
-
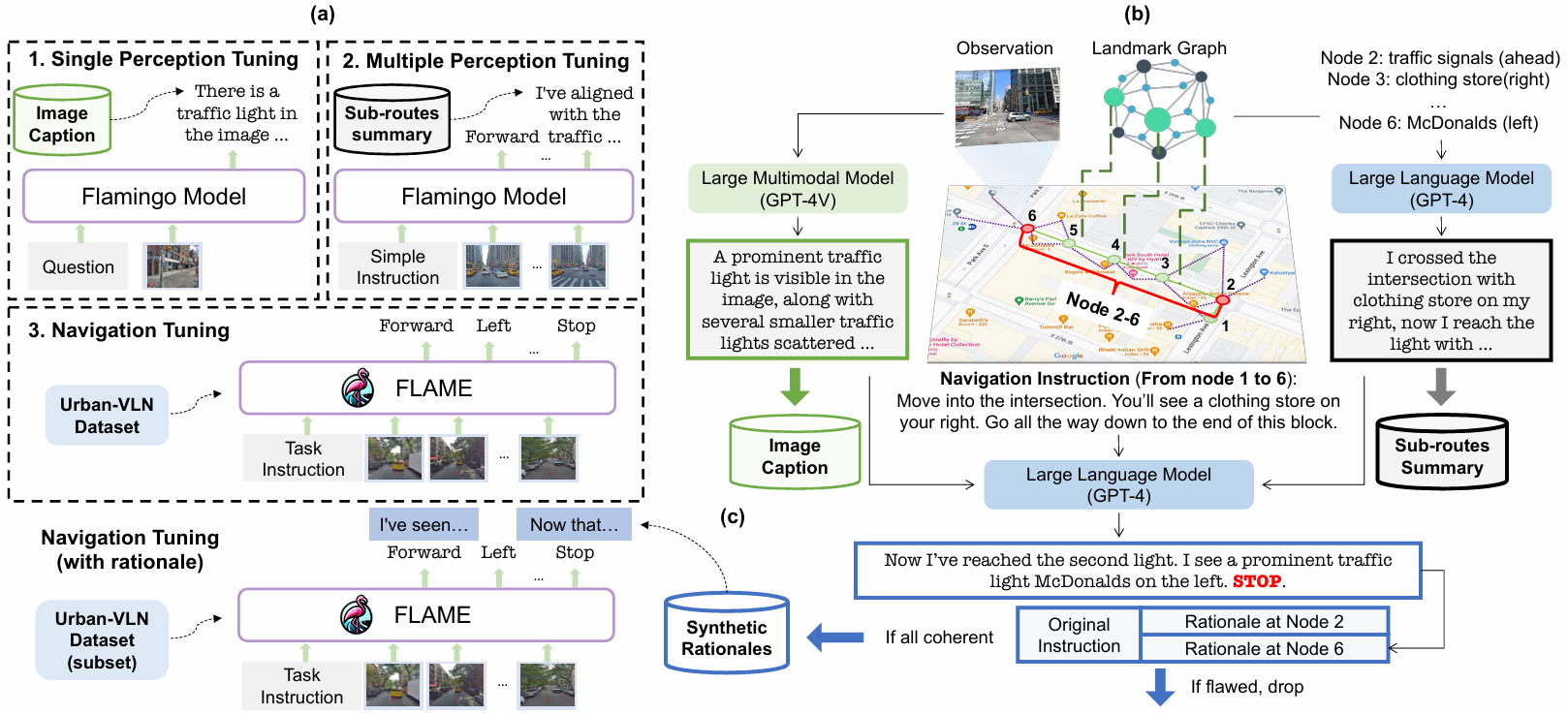
三阶段调优技术
为了将 Flamingo 适应到城市 VLN 任务,FLAME 提出了一个三阶段调优范式:
-
单感知调优:
-
在第一阶段,模型在街景描述任务上进行训练,以增强其特征识别能力。
-
训练目标是通过给定的观察和提示生成准确的描述。
-
-
多感知调优:
-
在第二阶段,模型处理序列化的观察结果并执行动作。
-
通过监督路线总结和模仿损失来训练模型,以生成详细的路线总结和简单的导航指令。
-
-
端到端导航调优:
-
在第三阶段,模型在 VLN 数据集上进行端到端微调,以最小化动作预测的损失。
-
这个阶段的目标是使模型能够在实际导航任务中表现更好。
-
合成数据生成
为了支持模型的微调,FLAME 使用 LLMs 自动生成街景描述、路线总结和导航理由:
-
街景描述生成:使用 GPT-4 生成关键位置的街景描述,以确保多样性和准确性。
-
路线总结生成:构建地标知识图,并使用 GPT-4 生成详细的路线总结和导航指令。
-
导航理由生成:为 VLN 数据集生成合成理由,以验证智能体的推理能力。通过分割轨迹并检索每个子路线的图像描述和总结来生成理由。
实验设计
实验设置
-
数据集:
-
实验在两个城市视觉语言导航(VLN)数据集上进行:Touchdown 和 Map2seq。
-
这两个数据集都在 StreetLearn 环境中进行,分别包含 9,326 和 7,672 个指令-轨迹对。
-
实验还使用了为前两个训练阶段生成的增强数据集。
-
-
基准比较:FLAME 与其他现有的最先进(SOTA)方法进行了比较,评估其在原始数据集上的性能。
评估指标
-
任务完成率(TC):表示成功样本所占的百分比。
-
最短路径距离(SPD):计算停止位置到目标的距离。
-
基于动态时间规整加权成功率(nDTW):评估智能体轨迹与真实轨迹的重叠程度。
-
推理能力评估:引入了两个新指标:
-
理由一致性(RC):评估智能体生成的理由与指令的一致性。
-
理由-动作对齐(RA):评估智能体的动作与其生成的理由的对齐程度。
-
实现细节
-
模型实现:FLAME 基于 Otter 和 OpenFlamingo,结合了 CLIP 和 LLaMA。为了适应 CLIP 的输入大小,对全景图进行了裁剪和调整。
-
训练时间:第一和第二阶段的训练各需 1 小时,导航微调需要 12 小时,在单个 A100 GPU 上进行。
结果与分析
与 SOTA 方法的比较
-
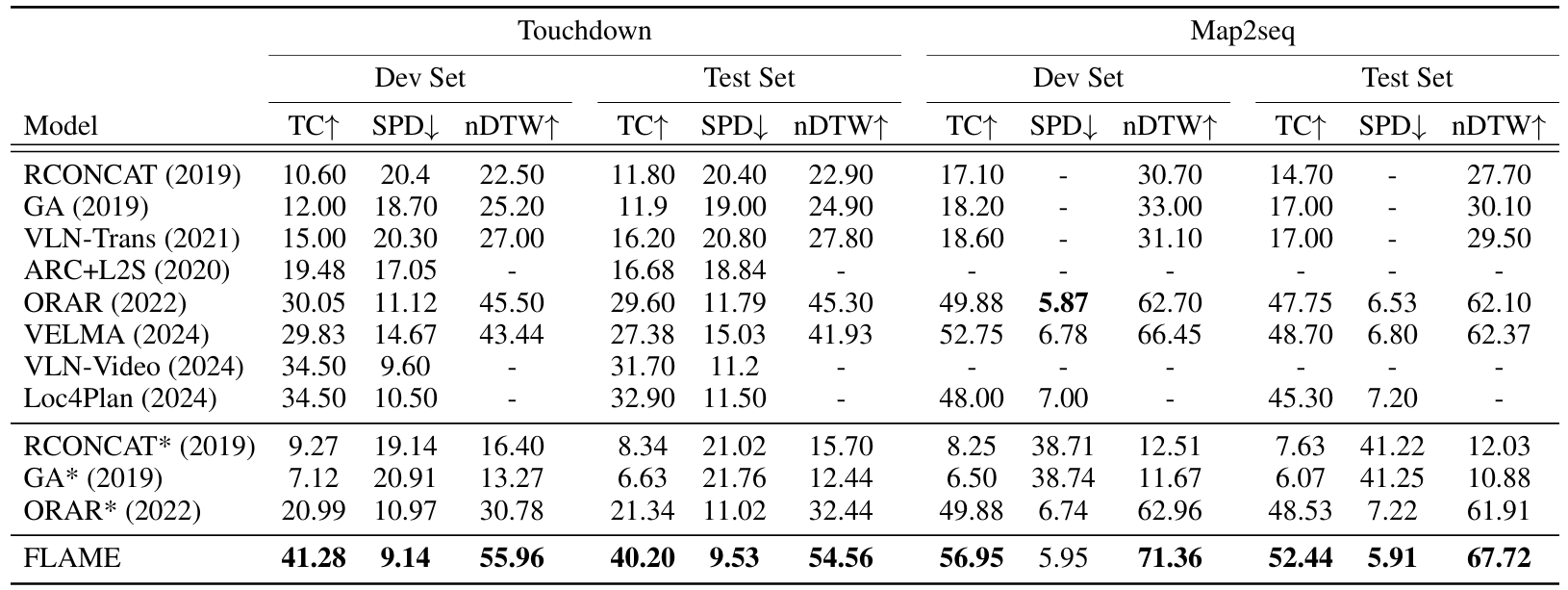
Touchdown 数据集:
-
FLAME 在测试集上超越了 Loc4Plan,任务完成率(TC)提高了 7.3%,最短路径距离(SPD)提高了 1.97%。
-
表明 FLAME 在理解和处理导航指令及环境线索方面具有优势,导致更高的成功率和更好的路径遵循。
-
-
Map2seq 数据集:
-
FLAME 在测试集上超越了 VELMA,TC 提高了 3.74%,nDTW 提高了 5.35%。
-
突显了多模态大模型(MLLMs)在捕捉综合信息方面的优势,相较于仅使用文本的 LLMs 更具优势。
-
-
开源方法的比较:
-
在限制的视场设置下,FLAME 的表现优于其他开源方法,尤其是在非全景视觉输入的情况下。
-
表明 FLAME 在非全景视觉输入中具有更好的适应性。
-
推理表现
-
自洽性方法:
-
通过探索不同的解码路径和温度来评估 FLAME 的推理能力。
-
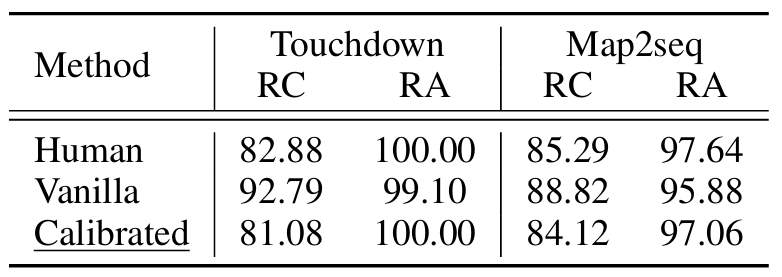
结果显示,FLAME 在理由一致性(RC)和理由-动作对齐(RA)方面表现良好,RC 和 RA 分别保持在 80% 和 95% 以上。
-
-
采样多样性:
-
较高的温度和更多的解码路径导致性能波动,但总体上增加了采样多样性和更大的解码预算,使得 FLAME 能够生成多样的理由并有效集成推理结果,从而改善决策。
-
分析
-
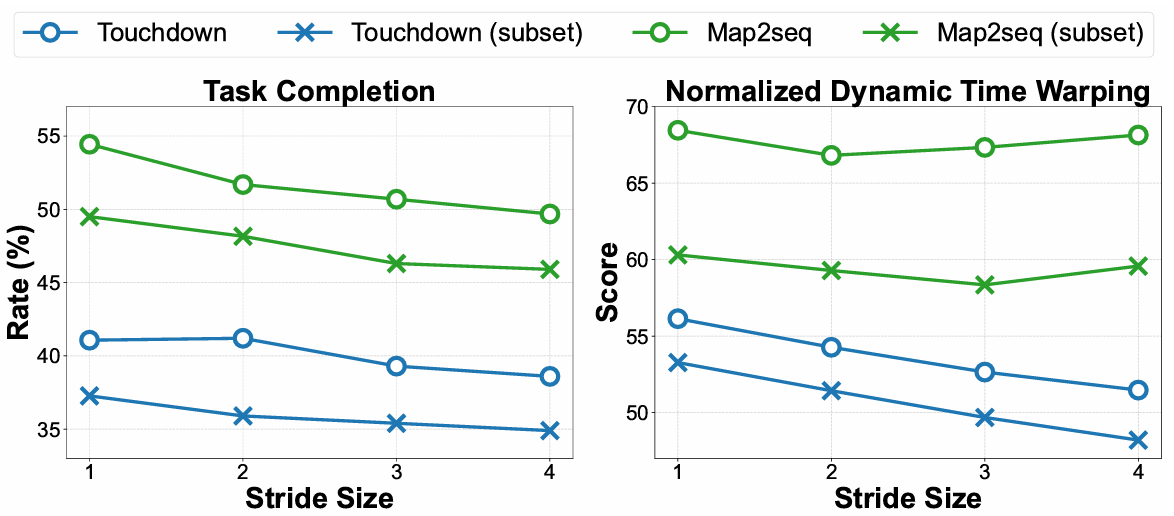
步幅交叉注意力的影响:实验表明,增加步幅大小通常与任务完成率的下降相关,强调了在决策过程中优先考虑当前观察的重要性。默认情况下,FLAME 设置步幅大小为 1。
-
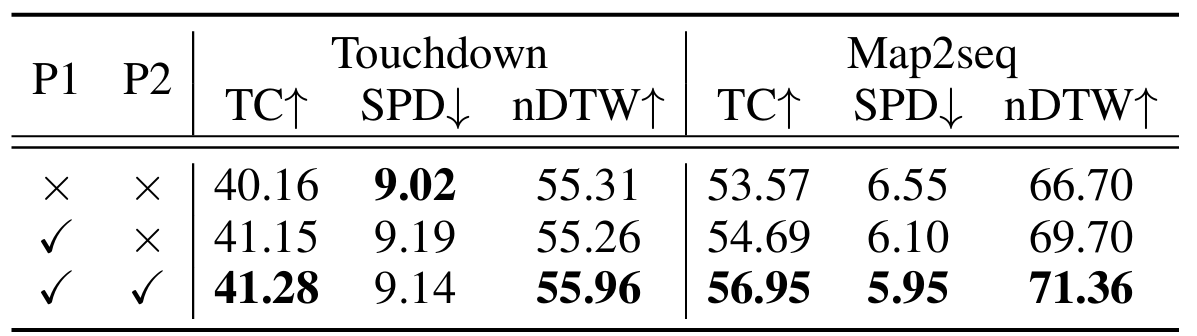
三阶段调优技术的有效性:通过逐步学习,FLAME 在导航任务中表现出色。未进行分阶段训练的基线模型表现不佳,而实施第一阶段和第二阶段调优后,性能显著提升。
-
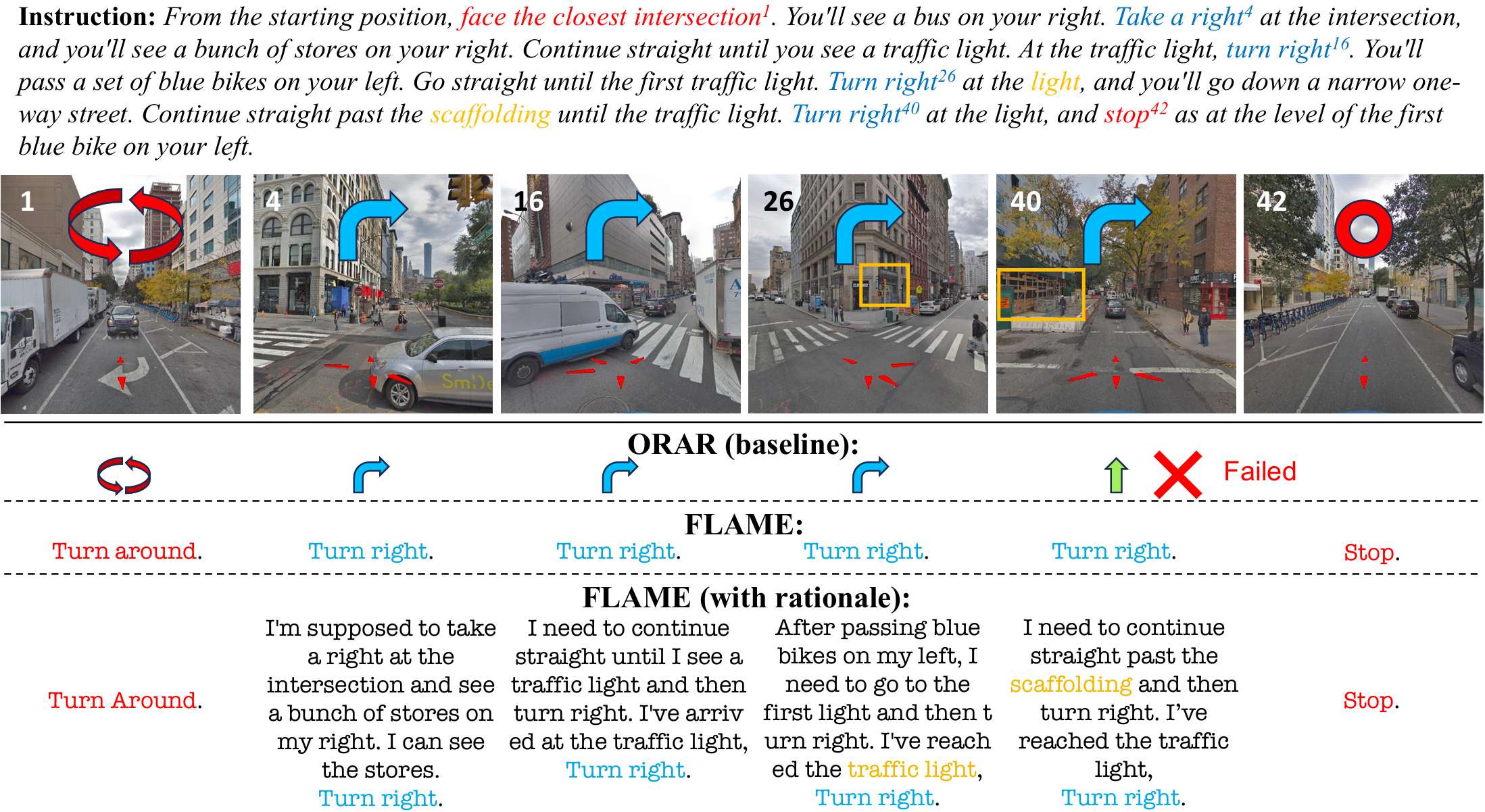
定性分析:通过定性示例展示了 FLAME 的导航能力。FLAME 能够准确识别关键地标并与指令对齐,显示出其在复杂导航任务中的有效性。
总结
论文介绍了FLAME,一种用于城市VLN任务的多模态大模型。
通过三阶段调优技术和合成数据,FLAME在城市VLN任务中取得了最先进的性能。
实验结果和推理性能证明了MLLMs在复杂导航任务中的潜力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









