








-
作者:Liuyi Wang, Zongtao He, Ronghao Dang, Mengjiao Shen, Chengju Liu* , Qijun Chen*
-
单位:同济大学电子与信息工程学院
-
原文:Vision-and-Language Navigation via Causal Learning https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_Vision-and-Language_Navigation_via_Causal_Learning_CVPR_2024_paper.pdf
-
代码链接 https://github.com/CrystalSixone/VLN-GOAT
摘要
视觉-语言导航(VLN)任务中,数据集普遍存在偏差,阻碍了模型在未见环境中的表现。论文介绍了一种基于因果推断范式的解决方案——广义跨模态因果Transformer(Generalized Cross-modal Causal Transformer,GOAT):
-
通过深入研究视觉、语言和历史中的可观测和不可观测因素,论文提出了后门和前门调整因果学习(BACL和FACL)模块,缓解潜在的伪相关性来促进无偏学习;
-
为了捕捉全局混杂特征,论文提出了一种由对比学习监督的跨模态特征池化(CFP)模块,也显示出在预训练期间改进跨模态表示的有效性;
-
在多个VLN数据集(R2R、REVERIE、RxR和SOON)上的实验证明了本文提出的方法相对于以往最先进的方法具有优越性。
1. 引言
数据集偏差,导致智能体可能会过度适应熟悉的环境,进而在外观和布局多样化的环境中性能下降。减轻VLN数据集偏差的一种方法是构建更广泛和多样化的数据集,包括:
-
使用speaker模型生成伪指令;
-
合成跨环境轨迹;
-
转移图像风格;
-
从网络收集数据;
-
以及标记更细粒度、实体对齐的指令。
然而,实现一个完全平衡且无偏差的数据集几乎是不可能的,研究者同样致力于在模型设计上开发能够对抗和减轻偏差的无偏模型,包括:
-
引入更多类型的输入(例如,对象和深度);
-
构建全局图来表示环境。
但这些方法还是忽略了潜在的数据集偏差以及任务背后的基本因果逻辑。
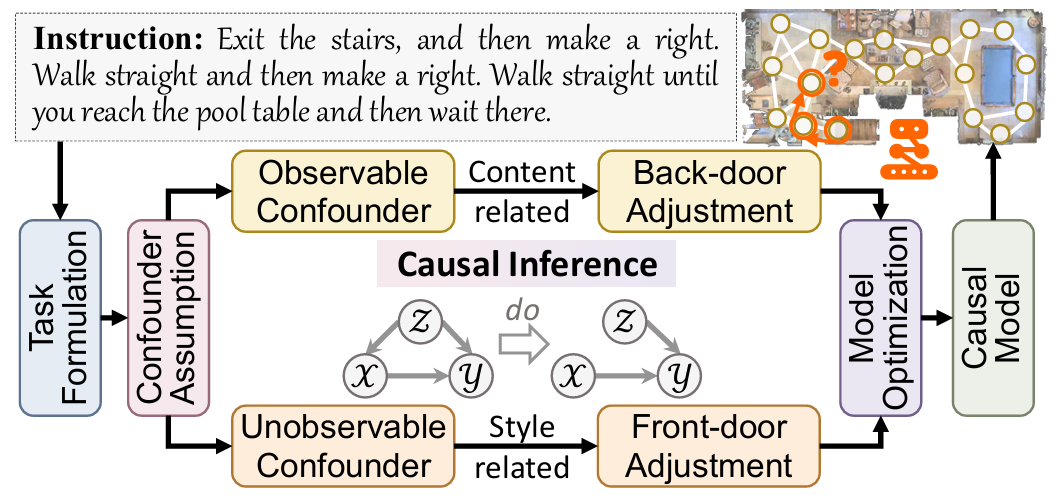
人类能够学习事件的内在因果关系,实现良好的类比关联能力。受此启发,本文使用因果推断来赋予VLN智能体类人的认知能力,提出了一个通用跨模态因果Transformer(GOAT)方法,使VLN模型能够减轻混杂因素引起的负面影响,从而实现因果推理决策:
-
提出统一的结构性因果模型来描述VLN任务,综合考虑不同模态中隐藏的可观测和不可观测混杂因素;
-
提出基于backdoor和frontdoor的因果学习模块来处理这些混杂因素,以实现端到端的无偏跨模态干预和决策;
-
设计了跨模态特征池化(CFP)模块,旨在聚合序列特征以实现语义对齐和构建混杂因素字典,以有效地聚合长序列特征;
-
采用对比学习来优化CFP,在预训练期间作为额外的辅助任务。
研究基础
任务描述
视觉语言导航(VLN)任务要求智能体根据自然语言指令在真实室内环境中进行导航。智能体接收自然语言指令,以及当前全景图分割成的36个子图像。智能体还知道其当前的朝向和仰角。 在导航过程中,智能体需要从附近的候选点中选择下一个点,或根据视觉线索预测动作。当智能体停止位置在距离目标位置3米内时,任务即为成功。对于目标导向任务,REVERIE和SOON还要求在终点定位目标对象。
VLN的结构因果模型
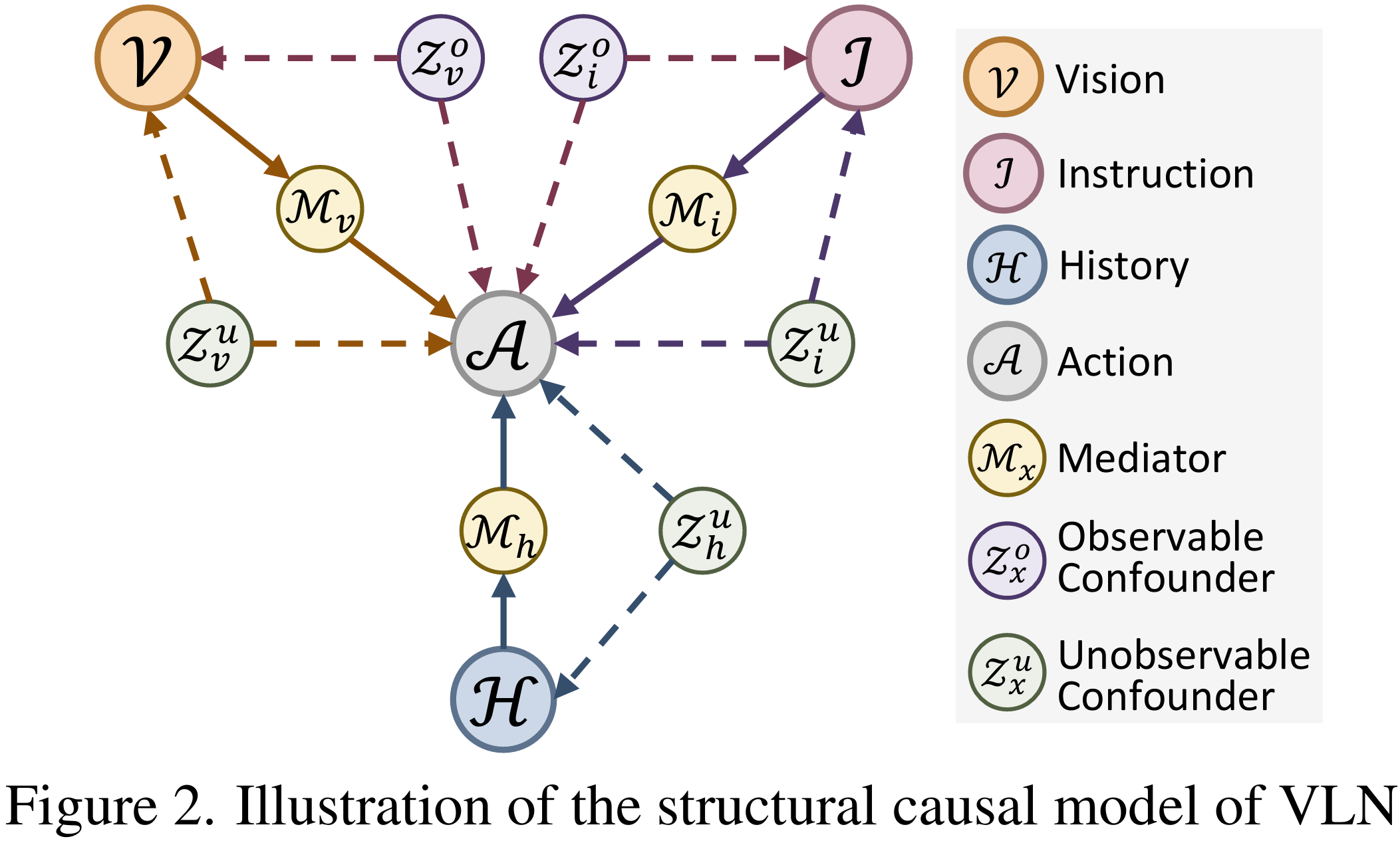
论文构建了一个结构因果模型,捕捉VLN中关键变量之间的关系:
-
视觉观察
-
语言指令
-
决策历史
-
动作预测
-
输入
-
输出
此前的VLN方法专注于学习观测关联,忽视了混杂因素在后门路径中引入的歧义。混杂因素是影响原因和结果的外部变量,例如经常发生的内容或特定属性。产生是因为输入数据的组合概率不可避免地受到现实世界中收集和模拟时可用资源限制的影响。存在是因为收集的环境、标记的指令或采样的轨迹也影响动作分布的概率。这些混杂因素在训练期间建立的错误的关系,导致新环境下的错误判断。 论文将不同模态中的隐藏混杂因素区分为可观测和不可观测两类:
-
可观测混杂因素包括可以被识别的实例(例如,房间类型参考和引导关键词);
-
不可观测混杂因素由难以定性描述的复杂模式和风格相关元素组成(例如,视觉中装饰风格、语言中句子模式和历史中轨迹趋势)。
由于不能显式地建模不可观测混杂因素,论文在和之间插入额外的中介,以建立前门路径。
方法
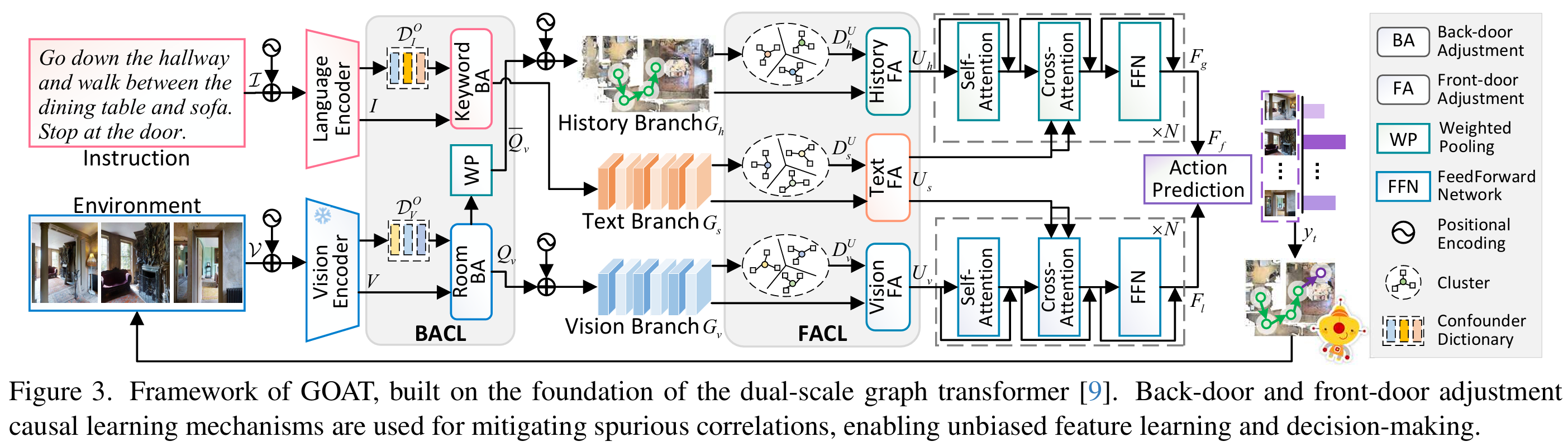
可观测因果推断
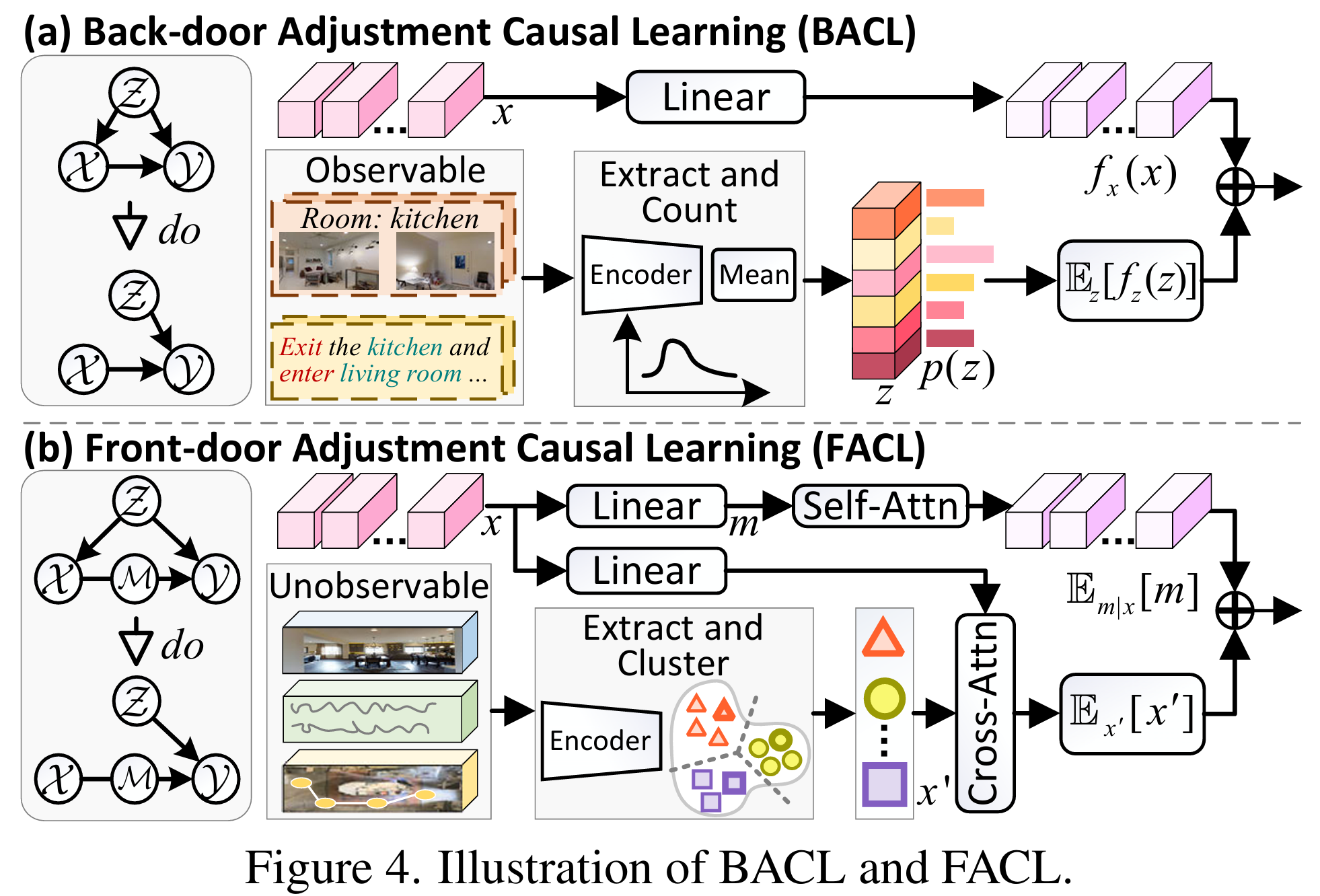
后门调整因果学习(BACL)
基于贝叶斯定理,典型的观测似然为,其中可能会带来偏差。Do-operator可以切断和之间的后门联系。根据不变性和独立性规则:
在这种情况下,干预操作通过阻断后门路径,使得有平等的机会纳入与预测相关的因果因素。由于条件概率是隐性的,本文将因果假设的目标效应具象带学习的特征,获得无偏特征进而得到无偏预测。因此,特定的网络模块被构建为: 。根据线性规则,可得。计算有两种方法,基于统计的方法和基于注意力的方法:
-
统计:
-
注意力:
其中表示训练集中属于第类的数量,如图4(a)所示。
文本中的BACL
在诸如“离开办公室,右转进入厨房”的VLN指令中,方向(例如,“离开”和“右转”)和地标(例如,“办公室”和“厨房”)等基本指导元素起着重要作用。这些常见于指令构建和动作分布的关键字,作为可观察到的混杂因素。论文首先构建关键词词典: , 包含个类别来存储共现特征。论文基于词性标签提取方向和地标关键词,并使用预训练的RoBERTa来获得每个提取标记记的特征表示。由于同一个单词在不同句子中可能具有不同的特征,论文计算每个关键词的平均特征:。 随后,文本内容的因果表示计算如下: 其中 和 分别表示可学习的嵌入层和全连接层。绝对位置编码 被添加以呈现位置信息,层归一化被用于在训练期间稳定隐藏状态。
视觉中的BACL
行动过程中,全景观察被划分为 36 个子图像。本文考虑室内房间导航,房间类型标签被视为可观察的混杂因素。论文使用CLIP和BLIP来提取图像特征和询问房间标签信息。通过计算每种房间参考类型的平均值,形成视觉房间参考字典 ,其中 是房间类型的数量。此外,矩阵 被用来呈现每个图像相对于智能体的位移方向,其中 和 表示航向和仰角方向。如果有额外的物体特征(针对目标导向任务),它们与图像特征一起被拼接起来。随后,使用两层Transformer编码器来捕捉空间依赖性:
不观测因果推断
前门调整因果学习(FACL)
如图4(b)所示,在输入和结果之间插入一个额外的中介变量,以构建前门路径。在VLN中,将从输入中选择关键区域用于预测。因此,模型推断可以表示为两部分:
-
特征选择器,它从中选择合适的知识,
-
动作预测器,它利用来预测。
为了消除不可观测混杂因素带来的伪相关性,论文同时在和采用do-operators: 其中表示整个表示空间的潜在输入样本,与当前输入不同。表示特征提取器作用于当前输入时获得的采样特征,而表示由基于均值的特征选择器从整个训练样本中随机采样的交叉采样特征。基于线性映射模型,可得。由于难以获得涉及复杂表示空间的期望的封闭形式解,因此通过查询机制来实现估计。使用了两个嵌入函数将输入传输到两个查询集和。然后,前门调整近似如下: 上述过程可以使用多头注意力高效实现,使得因果调整能够无缝集成到现有的基于Transformer的框架中。
文本、视觉和历史中的FACL
论文从VLN的三种输入中消除不可观察的混杂因素,即视觉、语言和历史。首先,遵循之前方法,通过添加额外的标记来构建视觉序列和历史序列,分别表示停止和循环记忆状态。表示第t步全景特征的加权总和。为了压缩特征序列并生成用于交叉采样的全局特征,论文通过CFP模块,结合注意力池化机制来构建视觉、历史和指令的混杂因素字典,分别表示为和,并计算因果增强特征和: 此外,论文引入自适应门融合(AGF)方法,通过集成来增强学习稳定性。每种模态下增强因果性特征与原始上下文特征: 其中 和 分别表示Sigmoid函数和逐元素乘法, 和 , 和 是可学习的参数。接下来,通过METER中的交叉注意力编码器 获得跨模态融合的局部特征 和全局特征 。通过动态融合 后接Softmax 激活函数 用于动作预测: 使用交叉熵损失来优化网络:
跨模态特征池化
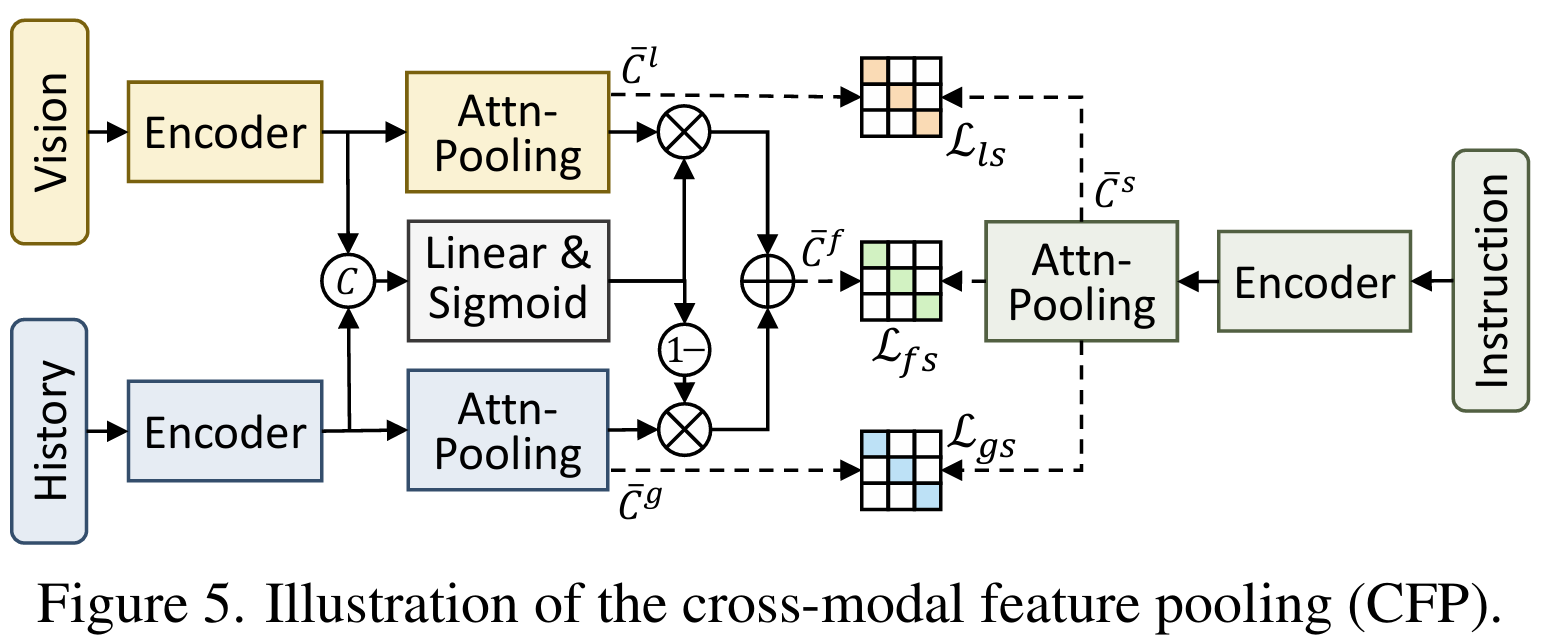
在VLN中实施前门调整的一个挑战是构建高效的全局特征字典,用于从长序列中提取特征。这需要将不同长度的序列特征压缩到一个统一的特征空间中,以有效表示每个样本。假设为序列特征,使用注意力池化来压缩序列长度: 其中 表示Tanh激活函数,是可学习的注意力矩阵,。如图5所示,对于视觉、历史、局部-全局融合和文本特征,论文使用Transformer层作为编码器,随后进行注意力池化以获得扁平化的特征 ,以及。然后,采用对比学习来优化这个跨模态特征池化(CFP)模块,同时提高不同模态的语义对齐。对比损失 的构建如下: 其中和分别代表批量大小和温度。同样,对比损失和是通过用替换和来计算。总的CFP损失是这些损失的和: 。 为了使网络对VLN的特征更加适应,便于构建样本的前门混杂因素字典,论文在预训练期间同时训练CFP模块和其他辅助任务。随后,训练过的注意力池化模块被用来提取不同模态的全局特征。在微调阶段,使用具有既定字典的BACL和FACL进行干预。CFP的优点体现在两个方面:(1)在预训练期间更有效地对齐不同模态,(2)提供了一种系统的方法从序列输入中提取表示。
实验
实验设置
本文在两种VLN基准测试上验证了GOAT模型:细粒度数据集(R2R和RxR-English)和目标导向数据集(REVERIE和SOON)。数据集分为训练集、共享环境验证集、不同环境验证集和未见过的测试集。评估指标包括导航误差(NE)、成功率(SR)、Oracle SR(OSR)、路径长度加权的SR(SPL)、标准化动态时间规整(nDTW)和按动态时间规整加权的SR(sDTW)。
模型由6层Transformer用于文本编码、2层Transformer用于全景编码和3层Transformer用于跨模态编码,使用CLIP-B/16提取图像特征,METER初始化网络权重。预训练阶段采用MLM、SAP和CFP,OG用于REVERIE和SOON,EnvEdit进行特征增强。预训练在Tesla V100 GPU上完成,优化器为AdamW,最大迭代次数300K次,批量大小48,学习率。微调阶段,使用基于环境dropout的speaker模型提供动态伪标签,学习率,最大迭代次数100K。
与SOTA的比较
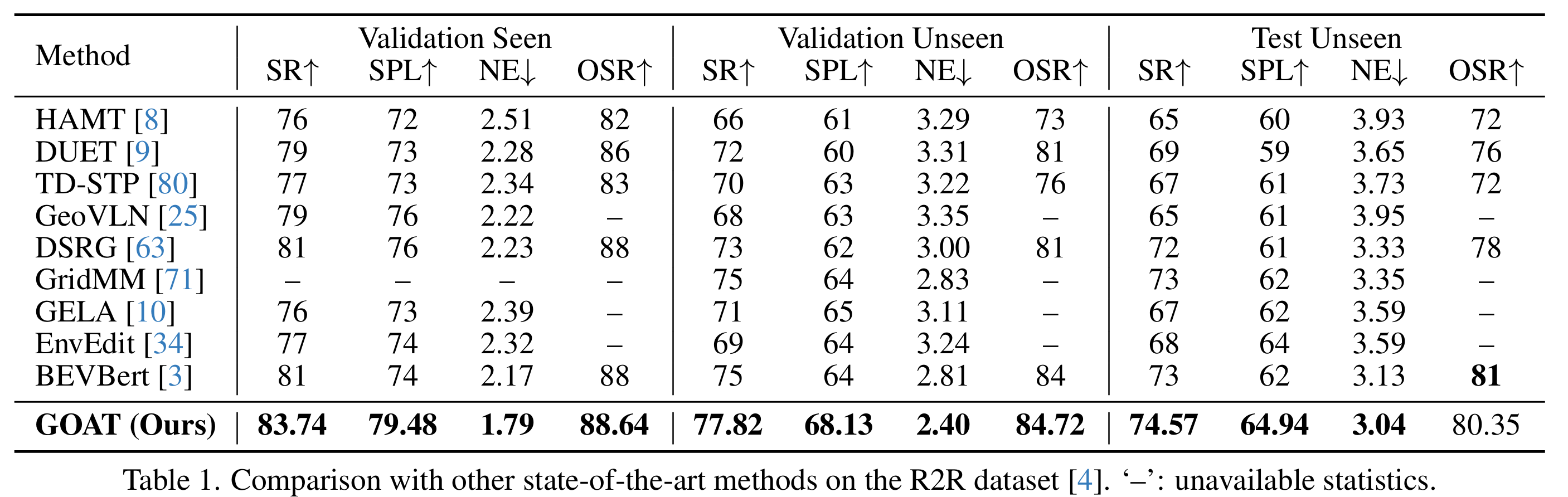
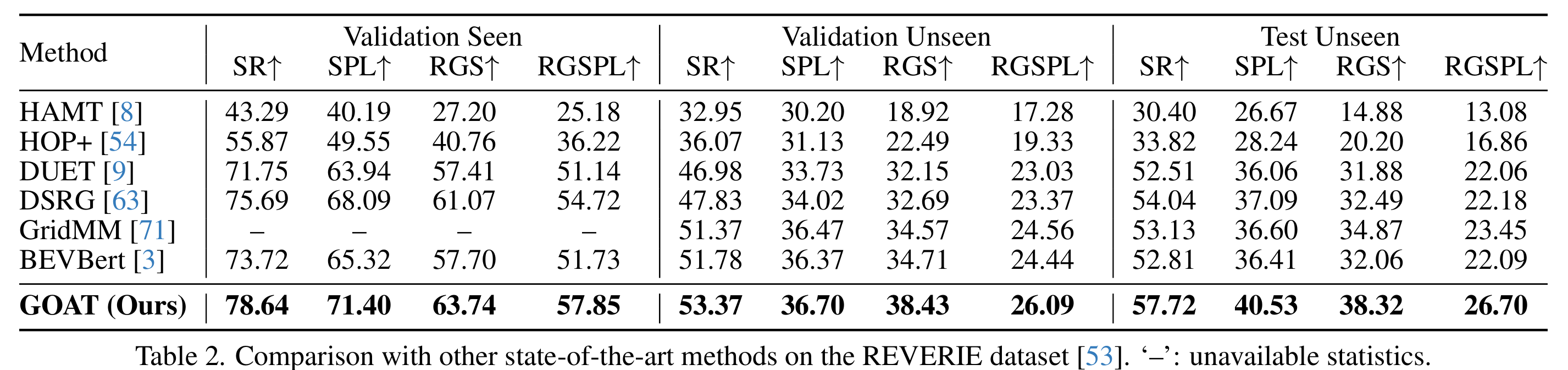
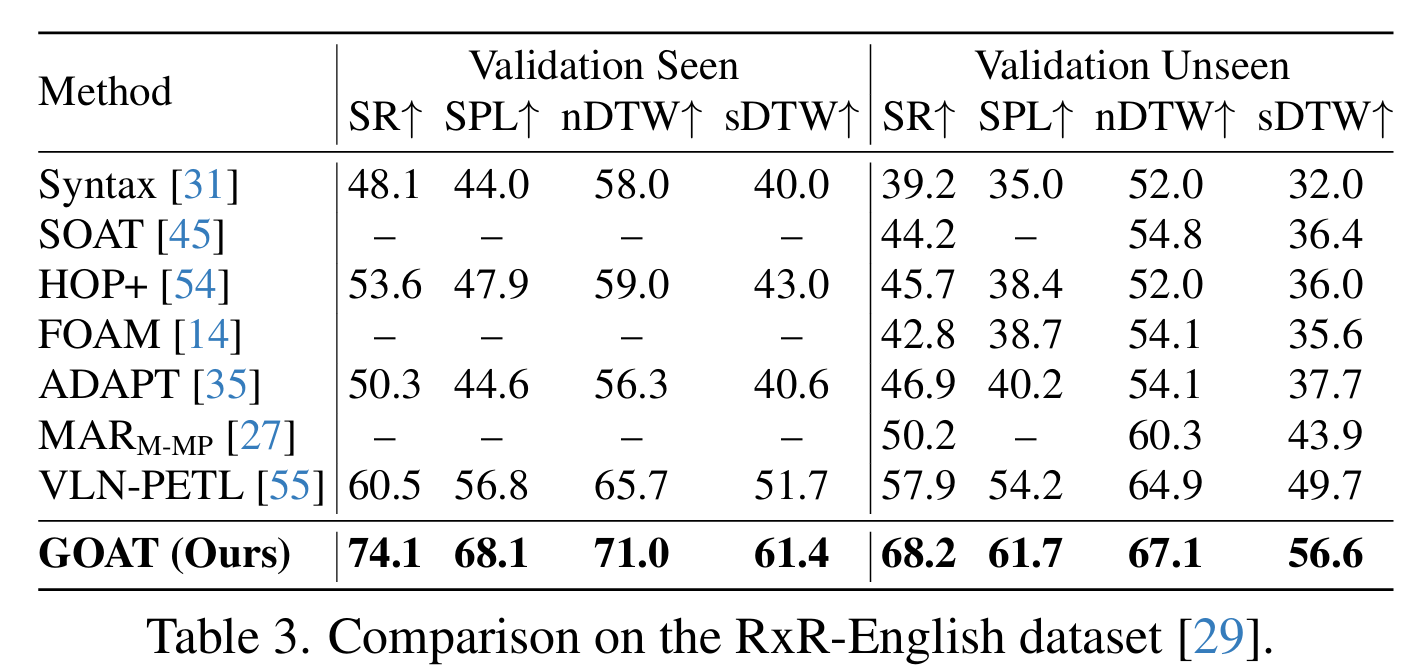
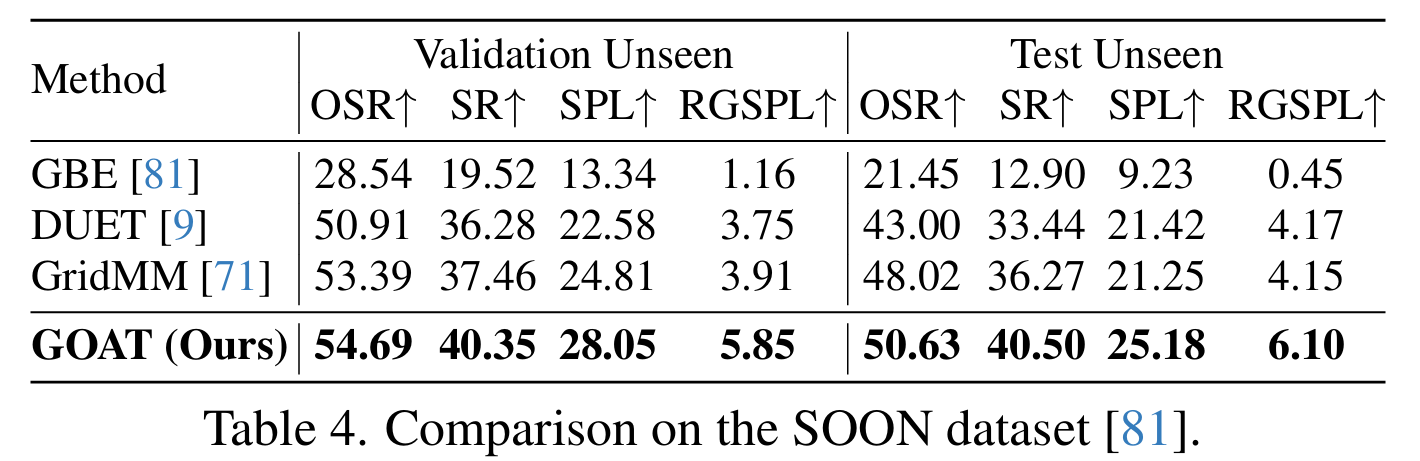
表1、2、3、4将GOAT与SOTA方法在R2R、REVERIE、RxR-English和SOON数据集上进行比较。在这四个数据集上,本文方法展现了卓越的导航性能、精确的指令遵循对齐以及跨所见和未见环境的准确物体定位。例如,在R2R中,GOAT在SPL方面相比BEVBert取得了显著的改进,三个子集的相对增加分别为7.41%、6.45%和4.74%。在REVERIE中,GOAT在三个子集上分别实现了11.83%、6.55%和20.87%的显著相对增强。在具有挑战性的SOON和RxR任务中,GOAT在性能指标上也展现了显著的改进,凸显了其在过去方法上的稳健性和卓越的泛化能力。
定量分析
-
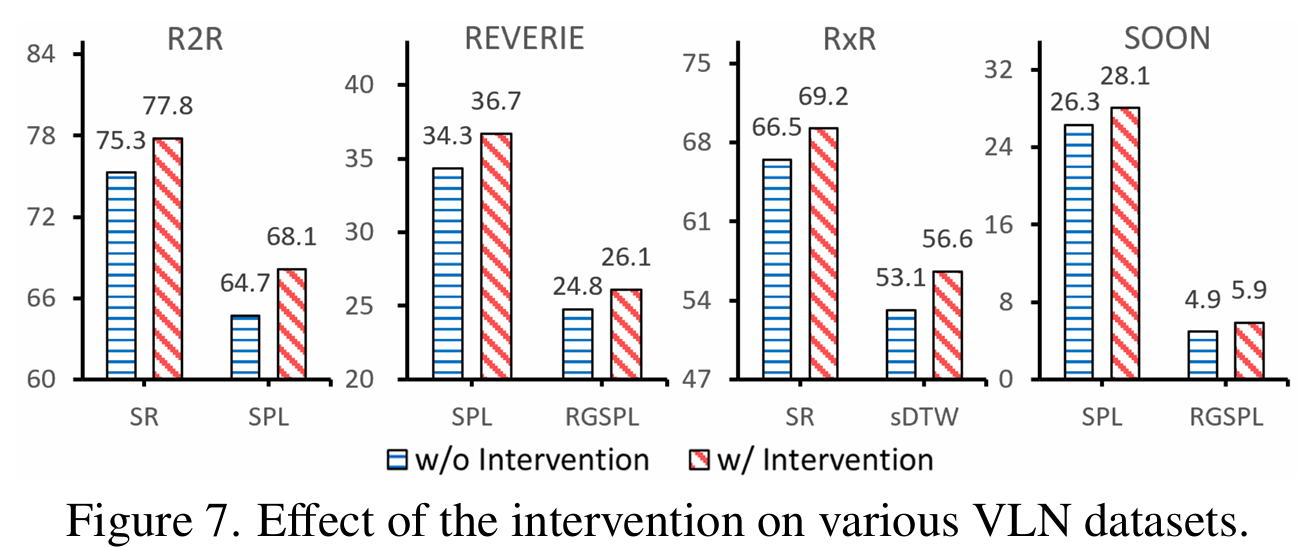
因果推断的影响。图7验证了因果推断对GOAT在不同VLN数据集未见环境中的影响。“W/o intervention”表示排除所提出的BACL和FACL干预措施在所有模态上的影响。在每个数据集上,因果推断显著提高了模型的性能。这强烈证明了因果学习在增强基于学习的模型泛化方面的巨大普及潜力。
-
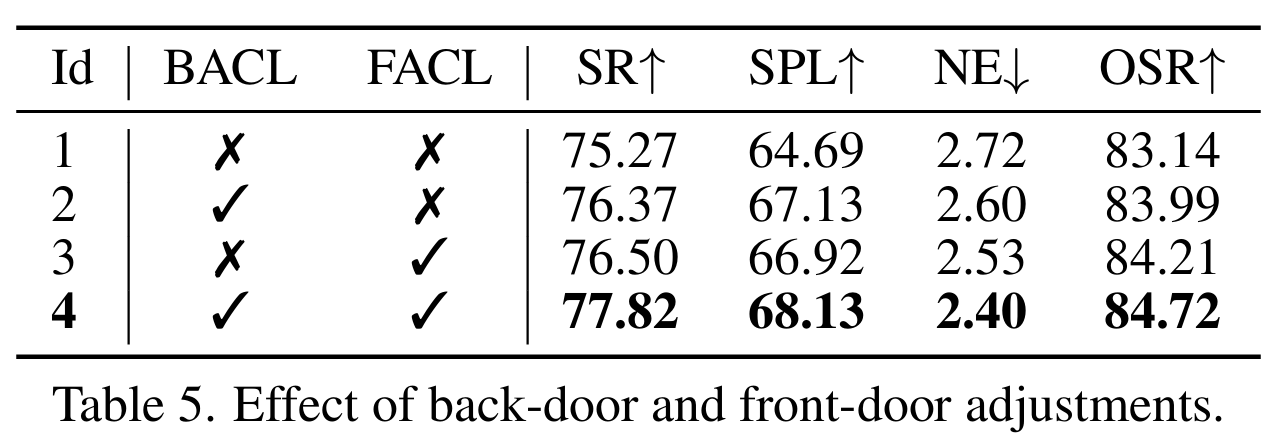
BACL和FACL的效果。表5分析了所提出的BACL和FACL对R2R未见场景的影响。与基线(#1)相比,单独应用BACL(#2)或FACL(#3)都会导致性能提升。同时使用BACL和FACL(#4)进一步提升了性能。这些发现验证了论文关于可观察和不可观察混杂因素观点的重要性。整合背门和正门调整对于全面解决数据集偏差以及提高模型的鲁棒性和泛化能力至关重要。
-
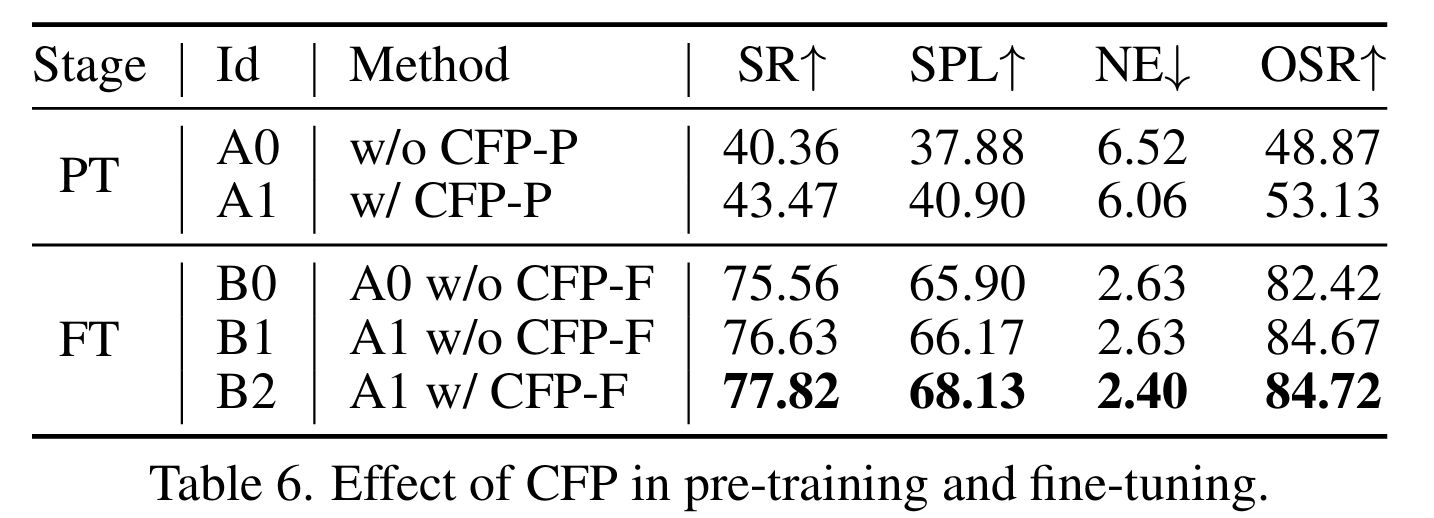
CFP的效果。在表6中,评估了所提出的CFP对R2R未见子集的有效性。在预训练(PT)阶段,将CFP作为额外的辅助任务(CFP-P)增强了训练性能,分别提高了SR和SPL 3.11%和3.02%。在微调(FT)阶段,论文将CFP中训练过的注意力模块提取前门字典(CFP-F)的全局特征的使用与否进行了比较,发现没有使用训练过的注意力模块时性能更好。“w/o CFP-F”表示使用简单的平均池化来压缩预训练模型中的特征。#B2显示,CFP为因果学习提供了更可靠的混杂因素表示(SPL↑1.96%)。
-
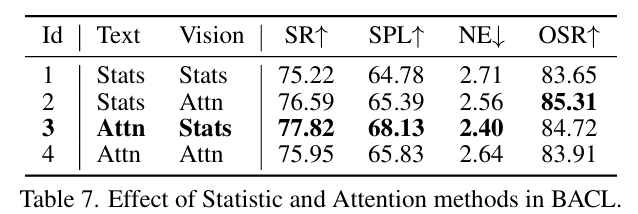
不同BACL在不同模态下的效果。表7展示了在BACL中,基于统计和基于注意力方法对R2R未见子集进行文本和视觉的各种组合的效果。结果表明,使用注意力方法处理文本和统计方法处理视觉可以获得最佳性能(#3)。直观上,这可以通过文本信息的结构化和RoBERTa端到端训练的参与来解释,使得注意力方法能够有效地捕捉上下文细微差别。相反,图像缺乏明确的因果关系,而且CLIP并不是为了效率原因而直接训练的。因此,统计方法确保了一个稳定的因果学习过程,保持了与视觉相关的特征的完整性。
定性分析
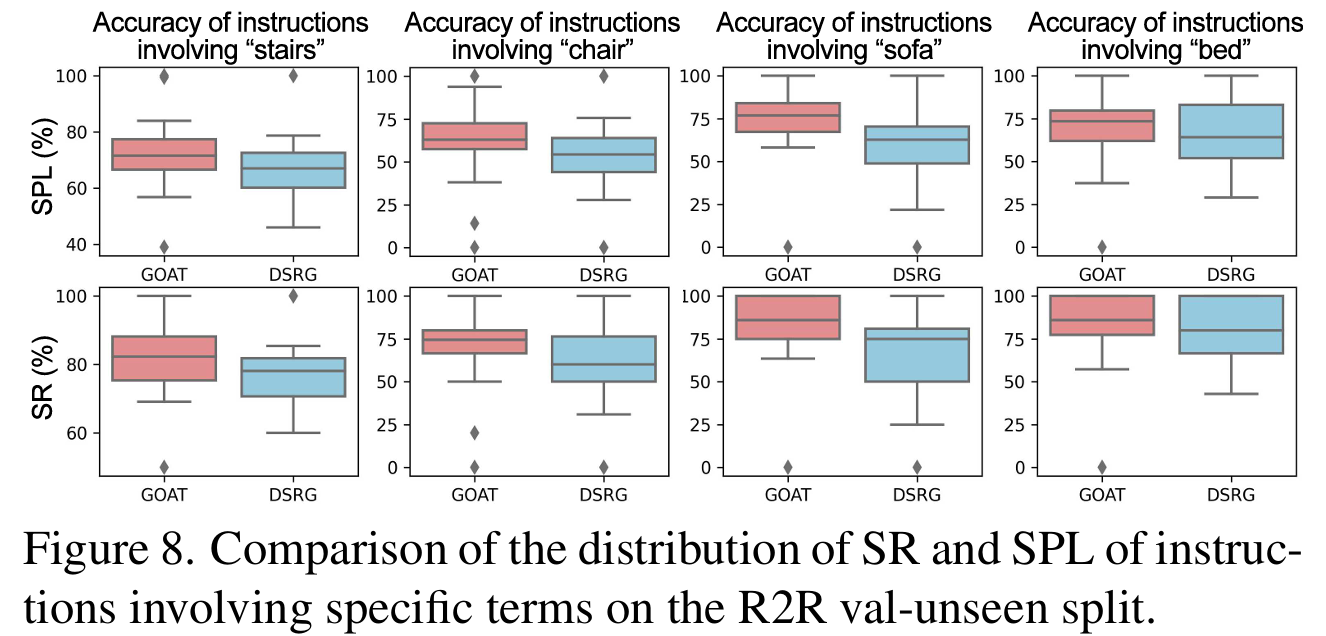
(1)偏差消除效应。在图8中,盒子的紧凑性代表了集中数据分布和减少了变异性,而靠近中心的中位数线表示了均匀的数据分布。它表明GOAT获得了更窄的盒子和中位数线,这些分布在不同的对象中更为集中。这一发现展示了通过集成因果干预,GOAT显著降低了预测偏差,从而增强了其在以前未见环境中的泛化能力。
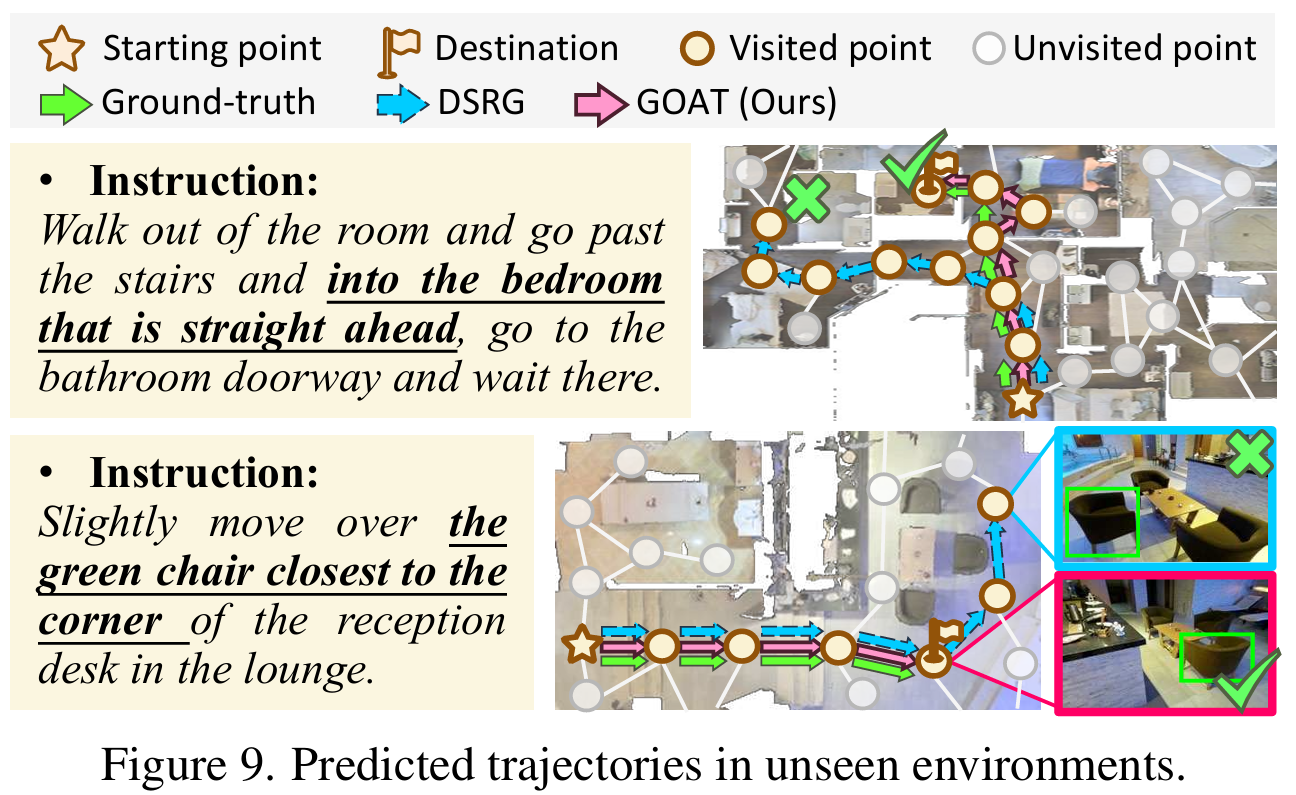
(2)可视化轨迹。在图9中,论文可视化了未见环境中的一些预测轨迹,并将其与RSRG和REVERIE数据集上的DSRG进行了比较。值得注意的是,GOAT精确捕捉了如“直行”和“最接近角落”的方向性提示以及微妙的指令,使得预测准确。这些实例突出了VLN任务中复杂的因果联系,其中特定的指令会提示相应的行动。GOAT增强的因果推理能力使其能够生成与提供指令一致的有理响应,强调了VLN系统中鲁棒因果推理的重要性。


















 2774
2774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









