









-
作者:Shaoting Zhu, Runhan Huang, Linzhan Mou, Hang Zhao
-
单位:清华大学交叉信息研究院,上海期智研究院,宾夕法尼亚大学GRASP实验室
-
标题:Robust Robot Walker: Learning Agile Locomotion over Tiny Traps
-
原文链接:https://robust-robot-walker.github.io/resources/rrw_paper.pdf
-
项目主页: https://robust-robot-walker.github.io/
主要贡献
-
论文提出了两阶段训练框架,该框架完全依赖于机器人的本体感觉来学习通过各种小障碍物的鲁棒行走策略,避免了对外部传感器的依赖,从而提高了在复杂环境中的适应性和可靠性。
-
引入了显式-隐式双状态估计范式,利用接触编码器来估计机器人不同关节链接上的接触力,并结合分类头来增强对接触表示的学习,有助于更有效地识别和应对不同的障碍物。
-
将任务重新定义为目标跟踪而非速度跟踪,并设计了精心设计的密集奖励函数和假目标命令,实现了近似的全向移动能力,显著提高了训练稳定性和在不同环境中的适应性。
-
设计了一个新的微小陷阱任务基准,并在模拟和真实世界环境中进行了广泛的实验,验证了所提出方法的有效性和鲁棒性,为未来的研究提供了有价值的参考。
研究背景

研究问题
论文主要解决的问题是如何使四足机器人在实际应用中具备稳健的行走能力,特别是在通过各种小障碍物(或“微型陷阱”)时。
现有的方法通常依赖于外部传感器,这些传感器在检测这些微小陷阱时可能不可靠。
研究难点
该问题的研究难点包括:
-
现有基于外部传感器的框架在处理微型陷阱任务时效果不佳;
-
在感知信息不完整的情况下,直接从零开始学习盲目行走策略非常困难;
-
一些目标跟踪框架虽然解决了上述问题,但缺乏全向运动能力或过度依赖外部定位技术,且通常使用稀疏奖励,导致训练不稳定和实际部署复杂。
相关工作
-
基于学习的行走:
-
该部分介绍了使用深度强化学习(DRL)来学习腿部机器人的行走行为。DRL通过端到端的学习过程,使机器人能够在模拟器中处理各种复杂情况,从而实现鲁棒的、可迁移的策略。
-
这些策略不仅允许机器人在平坦地形上行走,还能实现高速奔跑、穿越泥泞或不平的地形、后腿站立、开门、爬楼梯、攀爬岩石地形,甚至进行高速跑酷等复杂任务。
-
-
碰撞检测:碰撞检测在机器人中可以分为几个阶段:预碰撞阶段、碰撞检测阶段、碰撞隔离阶段、碰撞识别阶段、碰撞分类阶段、碰撞反应阶段和碰撞后阶段。对于四足机器人,碰撞检测方法通常分为基于模型的方法和无模型方法:
-
基于模型的方法:通常使用状态估计技术,有些方法依赖于外感知传感器,而另一些则完全依赖本体感觉进行估计。
-
无模型方法:涉及通过深度强化学习训练神经网络来估计接触力,这些方法可以是隐式的或显式的。无模型方法通过训练神经网络来直接估计接触力,而不需要复杂的物理模型。这种方法在处理复杂环境中的碰撞时具有更大的灵活性和适应性。
-
研究方法
任务定义
-
任务被定义为通过一系列微小的障碍物,称为“小陷阱”。这些障碍物包括三种类型:Bar(水平薄条)、Pit(小坑)和Pole(竖直细杆)。
-
这些障碍物通常位于机器人头部以下的高度,且从正常的前视图不可见。机器人在遇到这些障碍物时,需要自主调整速度以通过它们。

强化学习设置
-
论文将行走控制问题分解为离散的运动动态,并使用时间步长为0.02秒的离散时间步。他们使用近端策略优化算法(PPO)来优化策略。
-
为了提高训练效率和鲁棒性,论文将任务定义为目标跟踪而不是速度跟踪。
- 状态空间包括四种类型的观测值:
-
本体感觉 :包含来自IMU的重力向量和基座角速度、关节位置、关节速度和上一个动作。
-
特权状态 :包含基座线性速度(来自IMU的数据不可靠)和地面摩擦。
-
接触力 :包括每个关节链接与环境网格的接触力。
-
目标命令 :包含相对于当前机器人框架的目标位置和时间剩余。
-
- 动作空间:
-
动作空间 是12个关节的期望关节位置。
-
奖励函数
奖励函数由三个部分组成:任务奖励 、正则化奖励 和风格奖励 。总奖励是这三部分的和。
- 任务奖励:包括目标奖励、航向奖励和完成奖励:
-
目标奖励在整个回合中是密集的,鼓励机器人始终朝向目标移动。
-
航向奖励帮助机器人在接近目标时保持正确的方向。
-
完成奖励鼓励机器人在接近目标时保持静止。
-
-
正则化奖励:用于使机器人平稳、安全、自然地移动。包括速度限制奖励、停滞奖励、腿部能量奖励等。
-
风格奖励:使用对抗运动先验(AMP)来获得自然的步态并加快收敛速度。
训练和部署
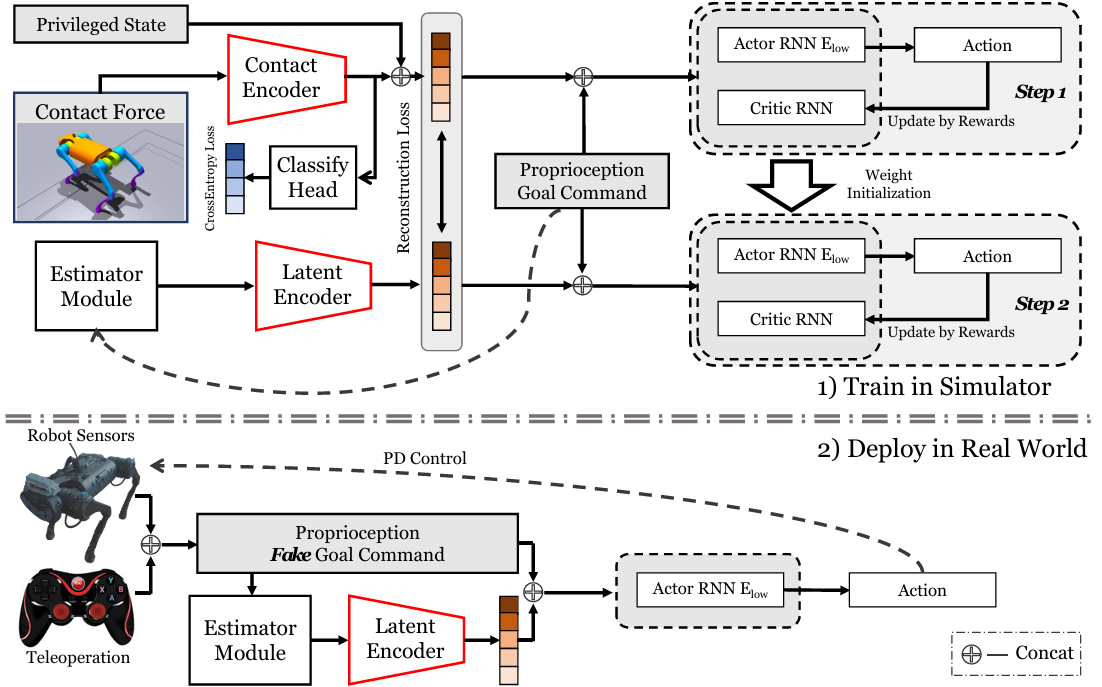
- 训练:采用两阶段的概率退火选择(PAS)框架进行训练。
-
在第一阶段,策略可以访问所有信息作为观测值,并使用显式-隐式双状态学习。
-
在第二阶段,策略只能访问本体感觉和目标命令,逐步适应不准确的估计。
-
- 部署:
-
策略通过遥控操作实现近似的全向移动,无需运动捕捉或其他辅助定位技术。
-
通过设计良好的任务奖励函数和比例,策略可以根据目标距离学习不同的移动策略。
-
实验
实验设置
-
论文使用IsaacGym进行策略训练,并在一个NVIDIA RTX 3090上部署了4,096个四足机器智能体。
-
首先在平面地形上训练12,000次迭代,然后在陷阱地形上分别对两个阶段进行30,000次迭代训练。
-
控制策略在仿真和真实世界中的运行频率为50 Hz。
-
策略部署在Unitree A1四足机器人上,该机器人配备了一个NVIDIA Jetson Xavier NX作为机载计算机。
-
在真实世界的部署中,机器人通过ROS消息接收来自遥控器的目标命令,并运行低级控制策略以预测PD控制的期望关节位置。
小陷阱基准测试

-
论文设计了一个新的仿真小陷阱基准测试。基准测试包括一个5米宽、60米长的跑道,沿路径均匀分布三种类型的陷阱。
-
陷阱包括高度从0.05米到0.2米的10个水平薄条、50个随机放置的竖直细杆和宽度从0.05米到0.2米的10个小坑。
-
每次实验部署1,000个机器人,从跑道的左侧开始,通过所有陷阱到达右侧。
-
基准测试使用三个指标:成功率、平均通过时间和平均行进距离。
仿真实验
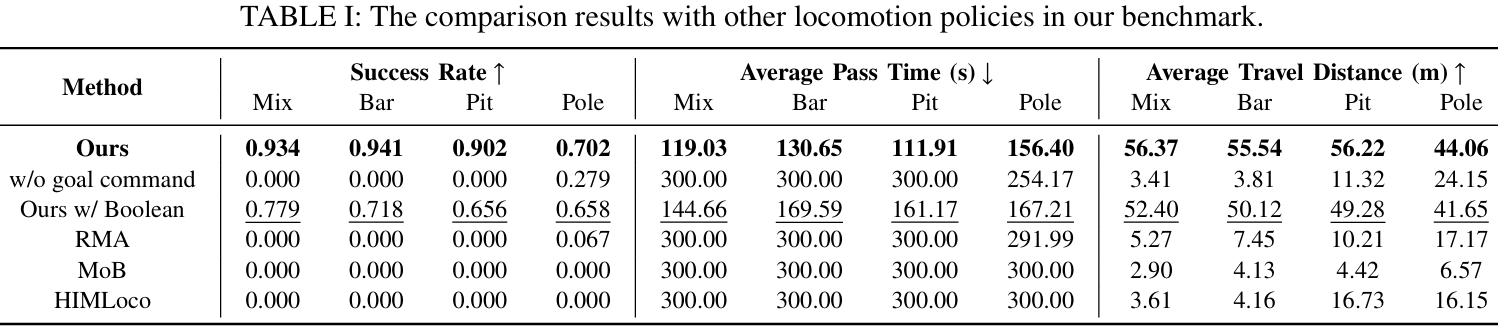
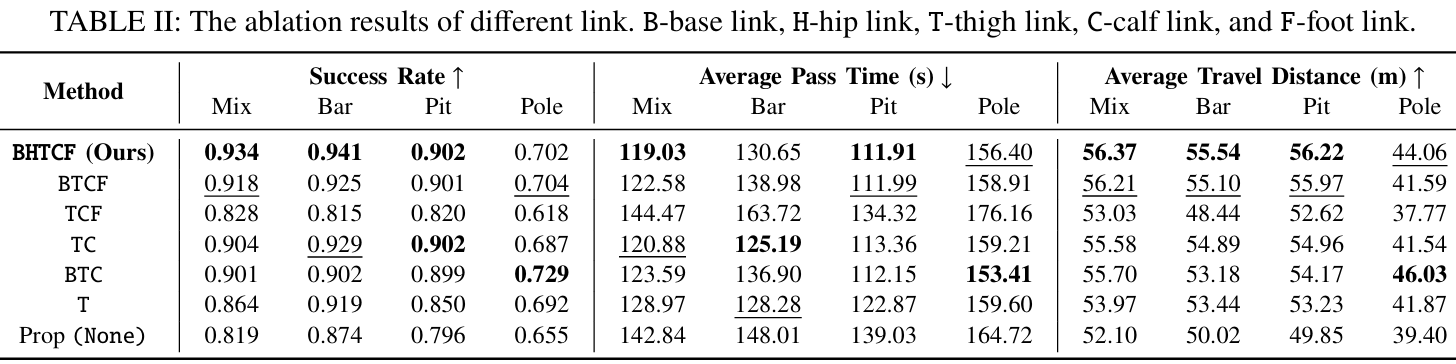
论文进行了多项实验以比较不同方法的性能:
-
不同关节链接的组合:仅使用本体感觉进行训练。
-
无目标命令:使用传统速度命令,但仅训练向前移动。
-
布尔值版本:没有编码器,直接将布尔值碰撞状态输入低级RNN。
-
RMA:使用1D-CNN作为异步适应模块的教师-学生训练框架。
-
MoB:学习单一策略,编码一组结构化的运动策略。
-
HIMLoco:通过对比学习显式估计速度并隐式模拟系统响应。
真实世界实验
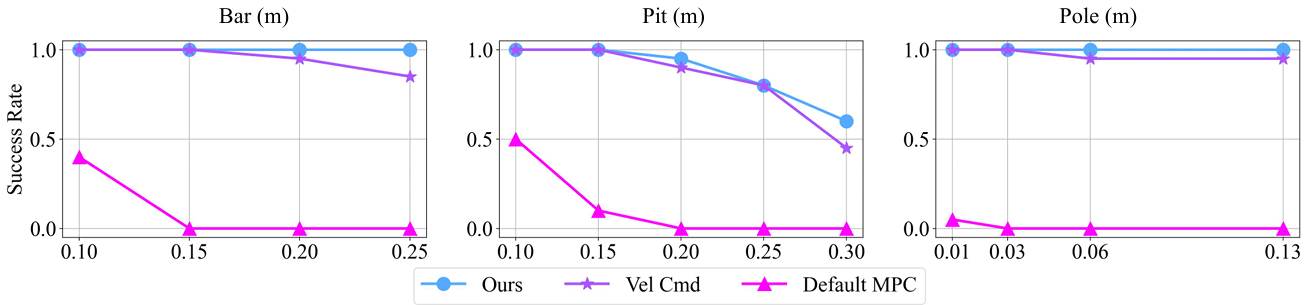
论文在真实机器人上部署策略并进行实验。机器人通过遥控操作实现了零样本全向移动。实验展示了机器人在遇到不同陷阱时的表现:
-
水平薄条:机器人在接触薄条后学会后退前腿,即使后腿被故意困住,也能检测到碰撞并抬起后腿越过薄条。
-
小坑:机器人在一条腿陷入空洞时学会用其他三条腿支撑身体,并在多条腿被困时用力踢腿以爬出小坑。
-
竖直细杆:机器人在碰撞细杆后学会向左或向右侧身,避免细杆并在一定距离后继续前进。
此外,论文还与其他策略进行了定量比较,结果显示他们的方法在性能上优于其他基线方法。

额外实验
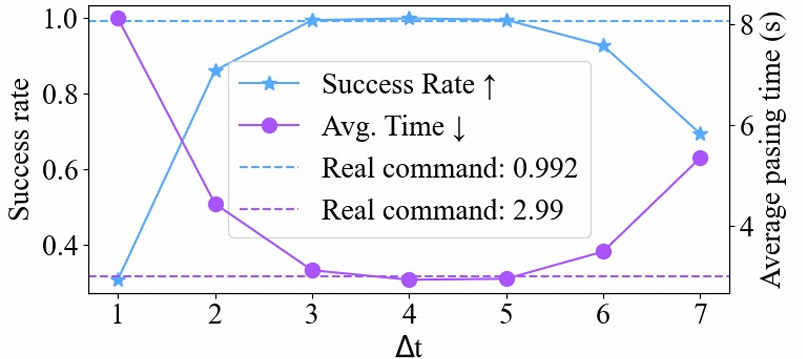
论文进行了额外的实验以进一步说明他们的方法:
-
不同假目标命令的:测试了不同值对假目标命令的影响。
-
不同假目标命令的:记录了不同常量目标命令下的机器人运动。
-
T-SNE实验:使用t-SNE方法可视化估计的双状态,显示了更分离和连续的编码。
-
重要性分析:通过计算雅可比矩阵来分析状态空间中每个输入的重要性,发现接触力占重要性的约25%。
总结
-
论文提出了两阶段训练框架,使四足机器人能够通过仅依赖本体感受来通过各种小型障碍物。
-
通过引入接触编码器和分类头,结合精心设计的奖励函数和假目标命令,实现了近似全向运动,无需定位技术。
-
在仿真和真实世界中的广泛实验证明了该方法的有效性和稳健性。
-
未来的工作可以解决速度大小控制和高度可变形陷阱的问题。


















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









