









-
作者:Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, Maosong Sun
-
单位:清华大学
-
论文标题:EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
-
论文链接:https://arxiv.org/pdf/2501.11858
-
项目主页:https://embodiedeval.github.io/
-
代码链接:https://github.com/thunlp/EmbodiedEval
主要贡献

-
论文提出了估基准EmbodiedEval,用于评估MLLMs在具身任务中的表现。通过提供多样化的交互式任务,填补了现有基准在非互动场景下评估MLLMs能力的空白。
-
EmbodiedEval包含328个不同的任务,分布在125个多样的3D场景中,涵盖了导航、物体交互、社交互动、属性问答和空间问答等五大类,旨在全面评估MLLMs的具身能力。
-
论文实现了统一的模拟和评估框架,支持多种交互,如移动、问答和与物体及人类的交互,旨在通过多样化的任务来全面评估MLLMs的具身能力。
-
论文开源了所有的评估数据和模拟框架,使得研究人员可以自由使用和扩展这些资源。
研究背景
研究问题
论文主要解决的问题是如何全面评估多模态大模型(MLLMs)作为具身智能体在交互环境中的能力。
现有的评估基准主要使用静态图像或视频,限制了对非交互场景的评估。
此外,现有的具身AI基准任务单一且不够多样化,无法充分评估MLLMs的具身能力。
研究难点
该问题的研究难点包括:
-
现有基准缺乏多样性和交互性,无法全面评估MLLMs在真实世界场景中的表现;
-
具身AI基准任务单一,难以捕捉MLLMs的广泛能力。
相关工作
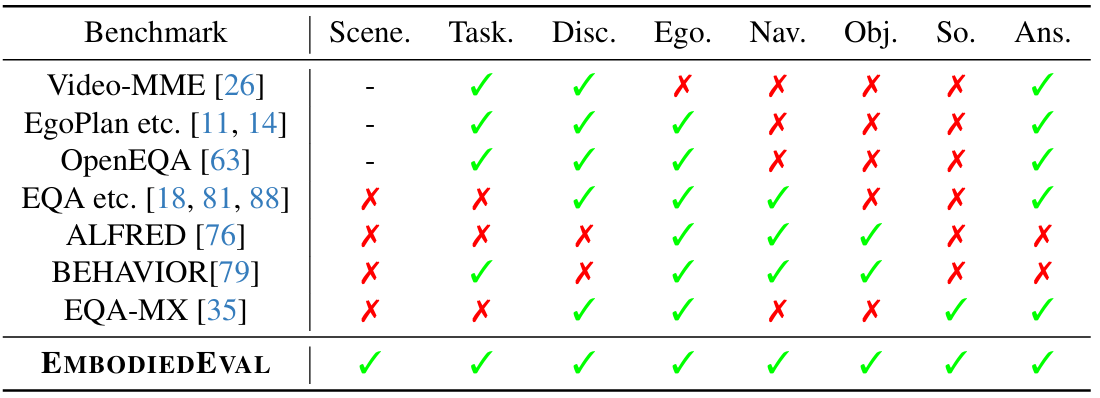
-
多模态大模型:
-
视觉指令调整:LLaVA通过视觉指令调整在多模态模型研究中取得了开创性进展,展示了其在多模态聊天任务中的强大能力。
-
多模态能力的提升:研究者们从多个方面改进了MLLMs,包括详细的描述生成、可信的响应、多语言多模态能力和视觉对齐等。
-
复杂任务的研究:一些研究探索了更复杂的任务,如图像-文本交错理解和视频理解。
-
-
MLLMs的评估:
-
感知和认知评估:主流的MLLMs基准主要关注感知和认知评估,如MME、MMB和MMMU。
-
更具挑战性的任务:为了提出更具挑战性的任务,一些基准引入了数学推理、OCR能力和科学知识等任务。
-
第一人称视角的评估:EgoVQA、EgoPlan-Bench、EgoThink和OpenEQA等基准在给定第一人称视角图像或视频的情况下评估MLLMs的推理和规划能力。
-
-
具身智能体的基准:
-
导航任务:R2R是第一个评估智能体在自然语言指令下导航能力的基准,后续的R4R和RxR进一步提高了导航过程的细粒度评估。目标对象导航是智能体与任何物体互动的前提步骤,相关的基准数据集包括SOON、REVERIE、DOZE和GOAT-Bench。
-
交互任务:ALFRED是最具代表性的交互数据集,要求智能体遵循指令完成涉及拾取和放置物体的任务。其他数据集包括移动物体、重新排列、整理房间和家庭活动等。
-
问答任务:EQA首次提出了导航后回答的机制。后续的EQA数据集包括涉及多个对象的问题、需要知识整合、设置在现实场景中和处理情境查询等。IQA要求与环境互动以收集更多观察结果来回答问题。
-
EmbodiedEval
任务类别
-
导航:涉及粗粒度和细粒度的自然语言指令,要求智能体从初始位置导航到目标位置,并在需要时找到特定对象。
-
物体交互:要求智能体通过与物体的直接交互改变环境状态,如移动物体、开关门窗和操作电器设备。
-
社交互动:涵盖人机交互,包括物品传递、换位思考、理解人类反馈和非言语交流。
-
属性问答(AttrQA):要求智能体探索环境以回答关于物体和场景属性的问题,扩展了传统的EQA任务。
-
空间问答(SpatialQA):要求智能体通过动作和观察回答与空间相关的问题,如大小、高度、位置、距离、面积、路径、布局和空间关系。
评估框架
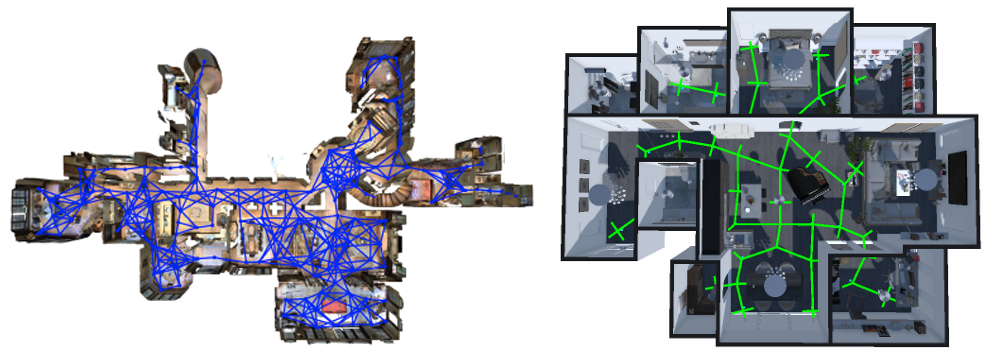
该框架基于LEGENT平台实现,旨在通过多样化的任务全面评估具身智能体的能力,而不是专注于特定任务的输入输出要求。
包括任务描述和自上而下的视觉信息。智能体通过这些信息来理解环境和任务需求。
-
动作空间:
-
运动空间:使用导航图作为运动空间,智能体可以在点之间旋转视图或移动。导航图的构建考虑了场景的多样性和任务的复杂性。
-
交互空间:采用离散的交互空间,类似于之前的具身AI任务,而不是连续空间。交互动作包括拾取、放置、开关等,要求智能体与环境中的物体进行互动。
-
答案空间:答案空间非常开放,允许多种可能的回复。智能体在探索环境后选择一个答案来完成问答任务。
-
-
成功标准:
-
使用谓词函数自动准确评估任务完成情况。每个谓词将模拟环境的状态映射为一个布尔值,指示成功与否。任务成功当且仅当所有谓词都返回真。
-
-
评估过程:
-
描述了评估过程中的步骤,包括初始化场景和导航图、选择动作、执行动作并更新观察历史,直到满足所有成功标准或任务失败。每个步骤中,智能体根据当前观察和历史信息选择最佳动作。
-
数据集构建

场景收集
-
多样性:为了更准确地评估智能体的泛化能力,EmbodiedEval使用了多种来源的场景,以确保场景的多样性和复杂性。
-
Objaverse Synthetic:利用Objaverse数据集中的对象库,通过程序生成方法创建了许多场景。
-
AI2THOR:从AI2THOR中提取和结构化室内房间场景,重点关注高度互动的对象。
-
HSSD:使用Habitat Synthetic Scenes Dataset(HSSD),提供高质量、现实和复杂的场景,包括房屋、别墅、庭院等。
-
Sketchfab:从Sketchfab中选取免费的3D场景,这些场景高度真实且多样化,涵盖了教室、超市、办公室和展览等多种环境。
任务收集
-
种子任务:首先从超过30个现有的具身智能体数据集和基准中收集种子任务。
-
生成多样化任务:使用这些种子任务,通过提示几个先进的大模型生成多样化的任务示例。设计了一些任务以结合各种能力,如复杂的视觉对齐、情景记忆、空间推理、定量推理、常识推理和规划。
任务标注
-
标注内容:标注开始于从候选任务池中选择任务并将其匹配到适当的场景。标注器配置动作空间,包括运动空间、交互空间和答案空间,并定义成功标准。
-
质量保证:所有任务标注必须满足一定的标准,如任务在给定场景中无歧义、问答任务需要场景观察、任务必须在模拟器中可执行等。
-
标注系统:开发了一个基于Unity的标注系统,提供场景和任务导入/导出、灵活的内容查看、可视化的动作空间和遵循预定义指南的引导式标注工作流。
-
标注过程:招募了八名专家标注员进行标注。在开始标注之前,进行了系统的培训。每个标注任务由至少三名评审员独立评估其正确性和质量。此外,通过提供专家演示和测试非专家参与者的表现来验证任务的可行性。
数据统计
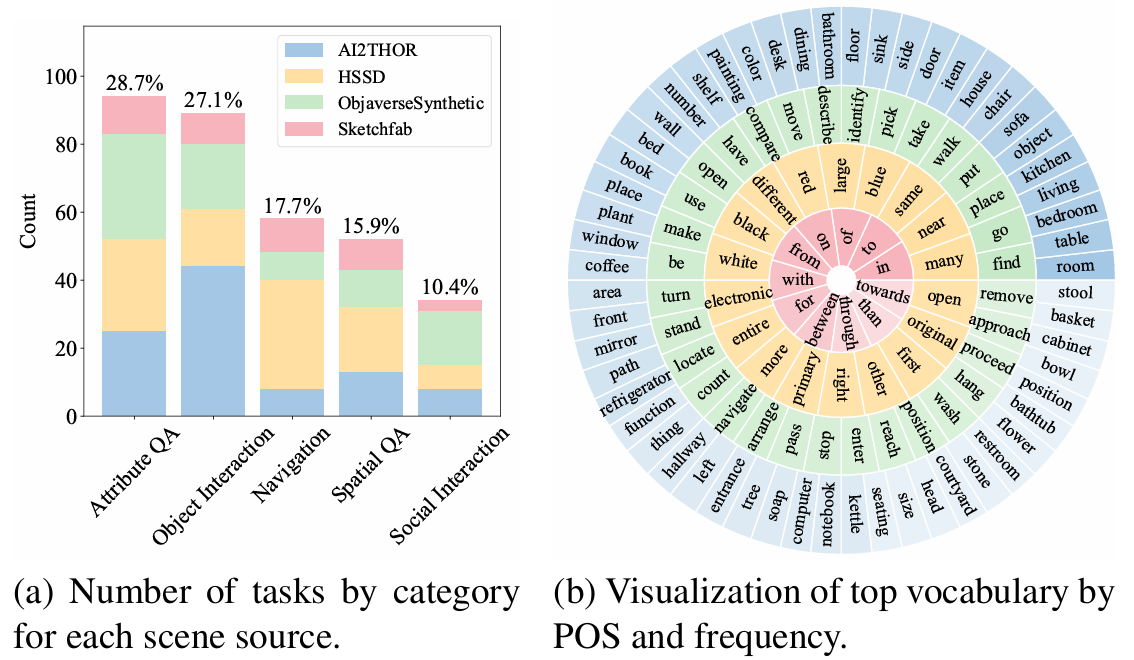
-
EmbodiedEval数据集包含328个人工标注的任务,这些任务被分为五个主要类别。这些类别涵盖了导航、物体交互、社交互动、属性问答和空间问答等具身任务类型。
-
这些任务分布在125个独特的场景中,展示了数据集的视觉多样性和复杂性。
-
数据集总共包含575个谓词实例和1,533个动作选项(不包括运动空间)。这包括1,213个答案选项和320个交互动作,显示了数据集在任务和动作上的丰富性。
-
每个任务描述平均包含16.09个单词,而答案选项平均包含5.72个单词。
-
基于专家演示,每个任务的平均步骤数为10.72步。
实验设置
-
评估设置:
-
模型输入:对于多图像MLLMs,输入包括任务提示、历史信息(自上而下的图像观察历史、动作历史、反馈历史)和动作空间(运动、交互、响应)。对于视频MLLMs,使用自上而下的视频代替图像观察历史。
-
最大尝试步数:每个任务的最大尝试步数设置为24,因为所有任务在专家演示中都在这个步数内完成。
-
图像分辨率:使用448x448的图像分辨率。
-
-
模型评估:
-
评估了22个MLLMs,包括闭源模型、开源多图像MLLMs和开源视频MLLMs。
-
这些模型在多模态基准上表现出色,如MMMU和Video-MME。
-
-
评估指标:
-
成功率:衡量智能体完全完成任务的比例,是主要评估指标。
-
目标条件成功率(Goal-condition Success, GcS):用于多目标任务,计算达到目标条件的比例。
-
路径长度加权成功率(Success Weighted by Path Length, SPL):评估导航和交互任务中的任务执行效率,考虑任务成功和相对于专家演示的路径效率。
-
结果与分析
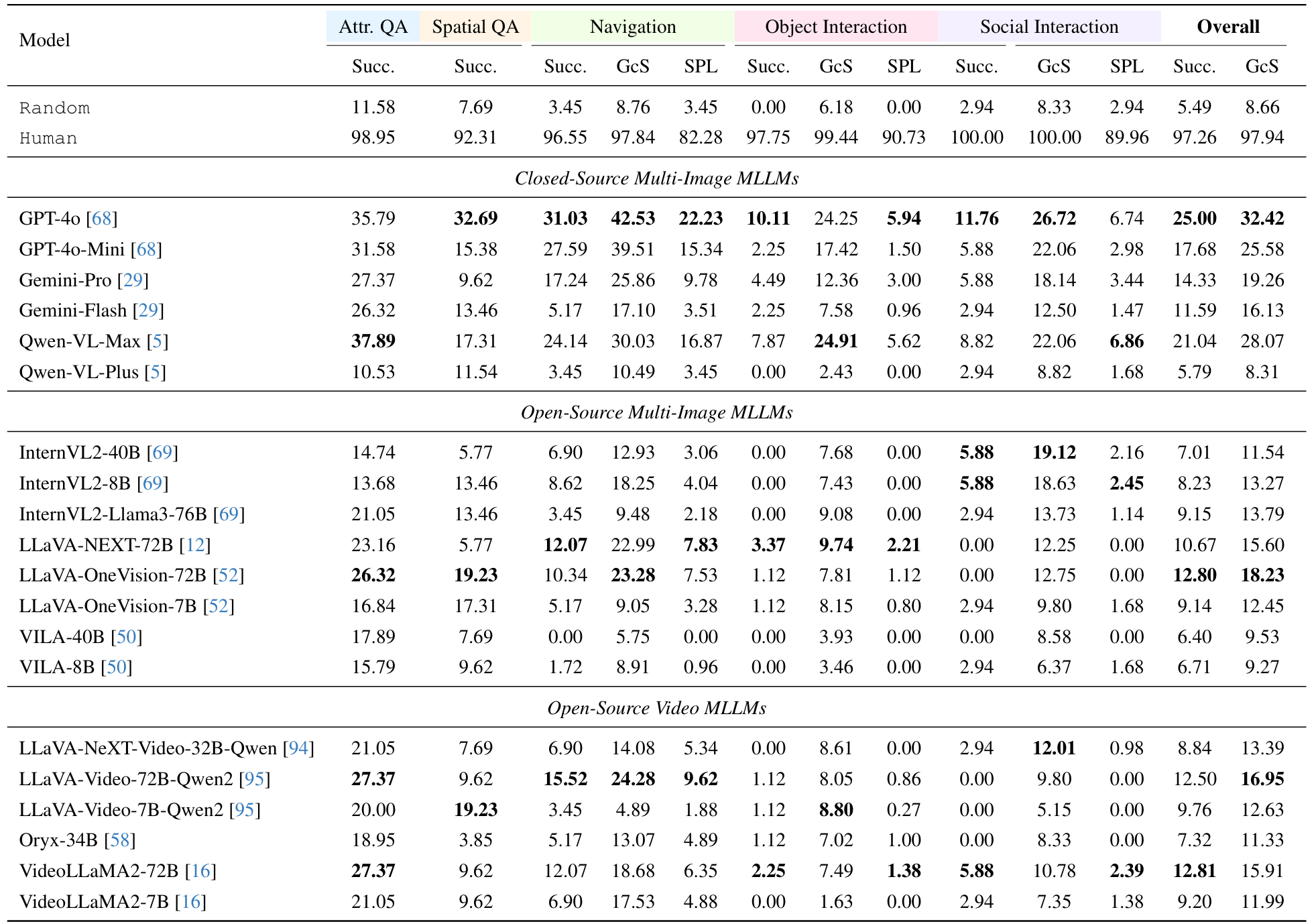
- 主要结果:
-
当前MLLMs在具身任务上的表现不佳。最佳模型GPT-4o的整体成功率为25.00%,GcS得分为32.42%。相比之下,非专家人类的成功率接近完美,为97.26%。
-
不同模型之间的性能差异显著,闭源模型在所有任务和指标上表现优于开源模型。开源模型中,较大的模型通常表现更好,但并非总是如此。
-
-
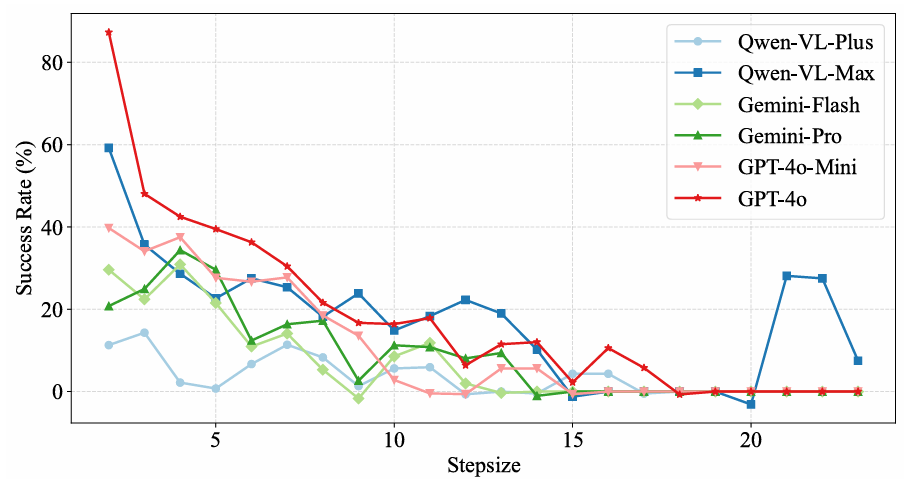
长程任务的挑战:
-
随着任务所需步骤和子目标的增加,MLLMs的性能显著下降。
-
这主要是由于任务复杂性和推理需求的增加,以及模型在处理长时间序列任务时的局限性。
-
-
温度影响研究:
-
发现所有模型在温度=1时表现略好于温度=0。这是因为具身任务需要一定程度的探索,而温度=0时输出的确定性可能导致模型陷入重复错误。
-

- 错误分析:
-
总结了MLLM具身智能体的四种主要错误类型:环境对齐中的幻觉、探索不足、空间推理不足和计划错误。
-
这些错误影响了模型在具身任务中的表现。
-
总结
论文提出了EMBODIEDEVAL,首次为MLLMs提供了一个综合的互动评估基准。
通过实验发现,当前的MLLMs在具身任务上表现不佳,显示出在处理复杂、多步目标方面的挑战。
论文为评估MLLMs的具身能力提供了新的方法和工具,具有重要的理论和实践意义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









