








-
作者:Haodong Hong, Yanyuan Qiao, Sen Wang, Jiajun Liu, Qi Wu
-
单位:昆士兰大学,CSIRO Data61,阿德莱德大学
-
标题:GENERAL SCENE ADAPTATION FOR VISION-AND-LANGUAGE NAVIGATION
-
原文链接:https://arxiv.org/pdf/2501.17403
-
代码链接:https://github.com/honghd16/GSA-VLN
主要贡献
-
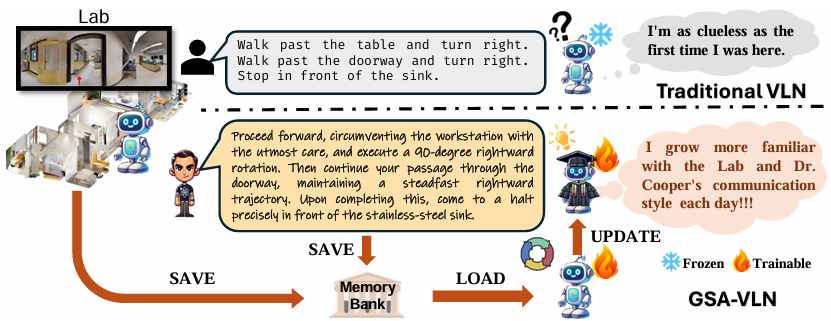
论文引入了通用场景自适应(GSA-VLN)任务,要求智能体在特定场景中执行导航指令,并随着时间的推移不断适应以提高性能,旨在更好地模拟现实世界中机器人操作的环境。
-
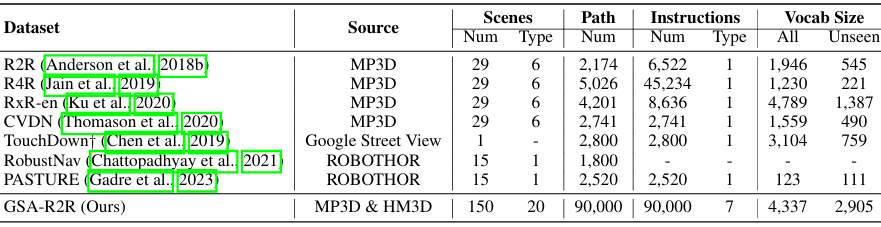
为了评估智能体在ID(分布内)和OOD(分布外)上下文中的适应性,创建了数据集GSA-R2R,显著扩展了环境和指令的多样性和数量,提供了更广泛的场景和指令类型。
-
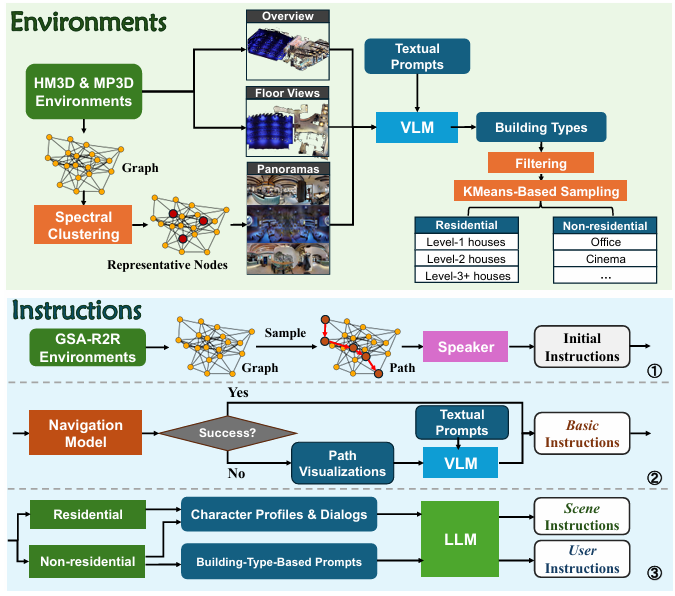
提出了三阶段的指令编排流程,利用大模型(LLMs)来精炼生成指令,并应用角色扮演技术来将指令重新表述为不同的说话风格,旨在模拟现实世界中用户指令的一致性。
-
提出了GR-DUET模型,结合了基于记忆的导航图和环境特定的训练策略,在所有GSA-R2R分割上实现了SOTA性能,展示了其在特定环境中持续优化导航模型的能力。
研究背景
研究问题
传统视觉语言导航(VLN)任务主要评估智能体在严格未见过的指令和环境下的泛化能力,而现实世界中的导航机器人通常在物理布局、视觉观察和语言风格相对一致的环境中操作。
因此,本文主要解决的问题是如何在VLN任务中,使智能体能够在持续环境中进行适应,从而提高其在零样本情况下的性能。
研究难点
该问题的研究难点包括:
-
现有VLN数据集中缺乏分布外(OOD)数据和指令风格多样性有限;
-
如何在单场景中实现智能体的持续适应;
-
如何在不增加额外反馈或辅助的情况下,通过无监督学习技术改进智能体的性能。
相关工作
- 视觉语言导航:
-
VLN任务涉及智能体根据自然语言指令进行导航。传统的VLN研究主要集中在使用Room-to-Room(R2R)数据集等标准场景来评估智能体的能力。
-
这些研究通常关注于不同的文本输入方式,如高层次的对象导向指令、多语言指令和多模态指令。
-
然而,大多数这些研究都基于相同的场景数据集,缺乏对多样化场景的探索。
-
- 适应方法在VLN中的应用:
-
尽管没有先前的研究专门解决单场景适应问题,但一些研究提供了潜在的解决方案。这些方法可以分为两类:基于优化的方法和基于记忆的方法。
-
基于优化的方法在目标环境中更新导航模型的参数,而基于记忆的方法则显式地存储关于已访问地点和指令的信息以帮助决策。
-
- 持续环境中的VLN:
-
在持续环境中操作的智能体的概念已经在具身AI中引起了广泛关注。例如, Iterative VLN(IVLN)通过组织所有指令形成长视域游历来增强智能体在一个环境中的表现。
-
然而,IVLN强调的是长视域导航,而GSA-VLN则专注于使智能体能够从多种视觉建筑和指令类型中适应每个环境。
-
任务与数据集
基础介绍
-
在VLN任务中,智能体需要遵循给定的自然语言指令来导航到目标位置。
-
智能体在初始节点开始,每一步预测动作以移动到环境连通图中的相邻节点。
-
智能体的决策基于视觉观察、语言指令和之前的历史记录。
GSA-VLN任务
-
GSA-VLN任务引入了单场景适应的挑战,允许智能体在执行指令时不断改进其性能。
-
具体来说,GSA-VLN任务包括一个环境特定的记忆库,用于存储在给定环境中执行的所有指令的历史信息。
-
这个记忆库动态扩展,捕获视觉观察、指令、选择的动作和轨迹路径。
-
智能体可以利用记忆库中的历史信息来适应当前的工作环境,从而提高性能。
GSA-VLN与传统VLN任务的主要区别在于:
-
记忆库的使用:GSA-VLN允许智能体访问记忆库以检索长期历史信息,而不是每次导航时从头开始。
-
参数更新:智能体可以在导航过程中通过无监督学习技术更新其参数,以适应环境的变化。
GSA-R2R数据集

GSA-R2R数据集是为了评估智能体在ID和OOD上下文中的适应性而设计,扩展了R2R数据集的多样性和数量,提供了更多的环境和指令类型。
- 环境:
-
GSA-R2R数据集结合了Habitat-Matterport3D(HM3D)数据集中的环境,以提供更多样化的建筑类型和结构。
-
数据集中的建筑被分为住宅和非住宅两类,前者作为ID数据,后者作为OOD数据。
-
-
指令: 对于选定的环境,开发了一个三阶段指令编排流程来生成多样化的指令轨迹对。
-
首先,使用EnvDrop生成器生成初始指令,
-
然后通过大型视觉语言模型(VLMs)进行精炼,
-
最后通过大模型(LLMs)重新表述以模拟不同角色的说话风格。
-
-
数据集划分:
-
GSA-R2R数据集仅包含评估分割,使用R2R的训练集进行训练。
-
数据集设计了五个分割,分别针对验证和测试,以评估智能体在不同环境中的适应性。
-
-
数据集评估:
-
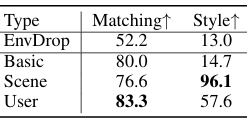
通过用户评估来验证生成指令的可靠性和多样性。
-
结果显示,生成的指令在描述路径和展现独特说话风格方面具有较高的准确性。
-
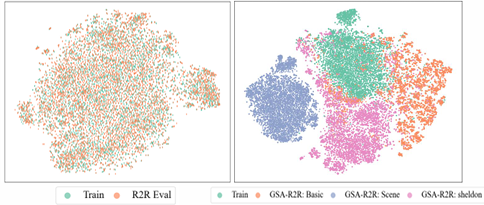
实验
GR-DUET方法
-
GR-DUET是一种基于记忆的方法,旨在通过维护全局拓扑图来增强智能体的环境适应能力。
-
GR-DUET在推理过程中使用单个全局图来更新拓扑地图,保留每个节点的观察信息。
- 这种方法允许智能体在多个场景中更有效地利用历史信息,从而实现更深层次的环境理解和更长期的行动规划,具体来说:
-
全局图的维护:通过在多个场景中使用同一个全局图,GR-DUET能够更好地捕捉历史信息。
-
环境特定训练策略:在预训练和微调阶段采用环境特定的训练策略,以减少输入分布的差异。
-
实验设置
-
实验中使用了多种基线方法,包括基于优化的方法和基于记忆的方法。
-
评估指标包括轨迹长度(TL)、导航误差(NE)、成功率(SR)、路径长度加权成功率(SPL)和归一化动态时间规整(nDTW)。
主要结果

- 当前VLN方法的性能:
-
实验比较了现有的VLN方法在GSA-R2R数据集上的表现。
-
结果表明,大多数基线方法在多样化环境和指令下的性能显著下降,突显了GSA-VLN任务的挑战。
-
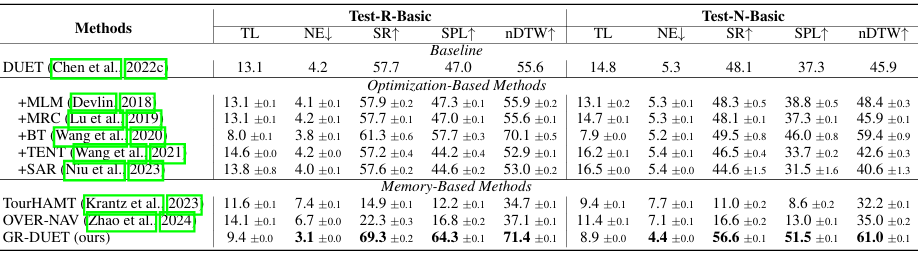
- 适应方法的性能:
-
测试了多种适应方法,包括优化方法和基于记忆的方法。
-
结果表明,tta方法在场景指令上有所提升,但在用户指令上效果不明显;
-
Back-Translation方法在环境适应上有效,但在指令适应上效果不佳;
-
TourHAMT和OVER-NAV方法的性能较差。
-
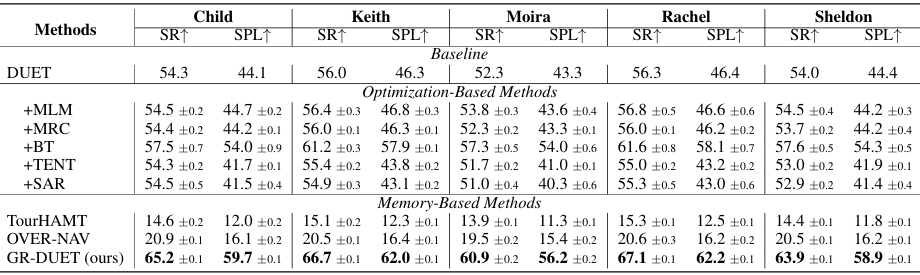
- GR-DUET方法:
-
GR-DUET方法在所有GSA-R2R分割上均取得了SOTA结果,成功率(SR)提高了8%。
-
该方法通过维护全局拓扑图来保留历史信息,从而在训练和评估过程中都能有效利用这些信息。
-
消融研究
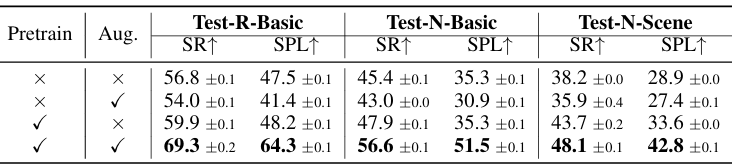
- 预训练和增强数据的消融:
-
仅添加PREVALENT数据:单独添加PREVALENT数据会导致性能下降,因为引入的指令噪声可能会干扰模型的学习过程。
-
仅使用完整图进行预训练:仅在预训练阶段使用完整的图会限制在微调阶段的路径多样性,导致性能受限。
-
结合预训练和增强数据:结合这两种方法可以显著提高性能,表明这种策略在提升模型适应性和泛化能力方面是有效的。
-
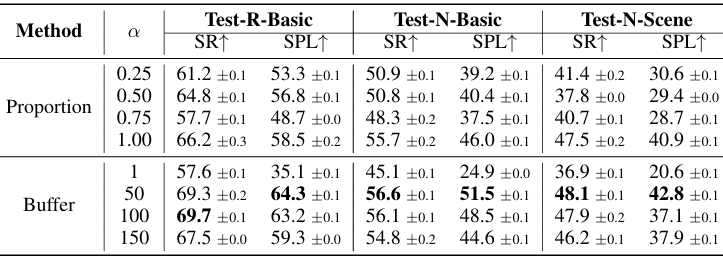
- 图构建机制的消融:
-
比例方法:随机提供特定比例的真实图给智能体。这种方法在某些情况下表现不佳,因为它可能无法充分覆盖图的结构。
-
缓冲方法:类似于GR-DUET中的实现,使用最大容量来记忆剧集。结果表明,缓冲方法在性能上优于比例方法,因为它更接近推理过程中全局图的逐步扩展。
-
缓冲大小的影响:缓冲大小对性能有显著影响。较小的缓冲可能导致图覆盖不足,而过大的缓冲则可能导致效率降低。最佳性能通常在中等大小的缓冲下实现。
-
总结
-
论文提出了GSA-VLN任务,旨在解决智能体在持续环境中的适应问题。
-
通过引入GSA-R2R数据集和GR-DUET方法,显著提高了智能体在多样环境和指令下的适应能力。
-
未来的工作将探索更多的无监督学习方法,以进一步增强智能体在GSA-R2R中的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









