








-
作者:Zihan Wang, Yaohui Zhu, Gim Hee Lee, Yachun Fan
-
单位:北京师范大学, 新加坡国立大学,北京化工大学
-
标题:NavRAG: Generating User Demand Instructions for Embodied Navigation through Retrieval-Augmented LLM
-
原文链接:https://arxiv.org/pdf/2502.11142
-
代码链接:https://github.com/MrZihan/NavRAG
-
数据集:https://www.terabox.app/chinese/sharing/link?surl=D5HEHsaW5AcWTjjIO15jpA
主要贡献
-
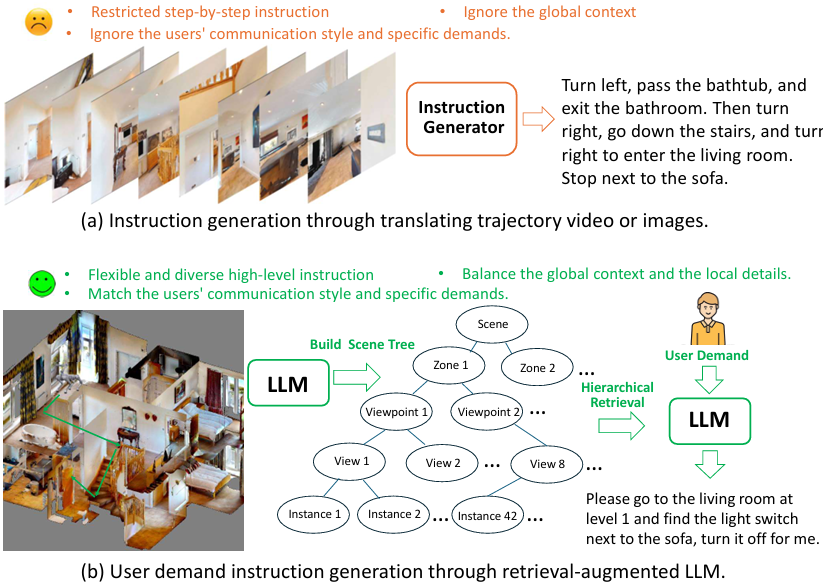
论文提出自底向上的方式构建层次化的场景描述树,用于对3D环境进行多层次的语义表示和理解,从全局布局到局部细节,帮助模型更好地理解场景。
-
NavRAG利用检索增强生成技术,结合大模型,生成符合用户需求的导航指令。通过从场景描述树中逐层检索相关信息,生成更详细和准确的指令。
-
标注了超过200万条高质量的导航指令,覆盖861个3D场景。这些数据用于训练和评估模型,显著提升了模型的导航性能。
-
通过模拟不同用户角色和需求,生成的指令更加多样化,能够更好地匹配用户的自然表达方式,还增强了模型在实际应用中的适用性和泛化能力。
研究背景
研究问题
视觉语言导航(VLN)要求智能体理解自然语言指令并在三维环境中导航到目标地点。
然而,手动标注数据的成本高昂,严重阻碍了这一领域的发展。
因此,论文主要解决的问题是VLN中存在的数据标注成本高的问题。
研究难点
该问题的研究难点包括:
-
生成的指令缺乏多样性;
-
步进式指令仅限于局部导航轨迹,忽略了全局上下文和高层次任务规划;
-
生成的指令与用户描述目的地或特定需求的方式不匹配。
相关工作
-
视觉语言导航:
-
VLN旨在使具身智能体能够根据自然语言指令在3D环境中导航。
-
早期的研究集中在离散环境中,如Matterport3D数据集,使用预定义的导航图和全景RGB及深度图像。
-
这些研究包括R2R、RxR、REVERIE和SOON等数据集。
-
尽管这些数据集在离散环境中高效,但缺乏现实世界的适用性。
-
-
导航指令生成:
-
为了应对训练数据的稀缺性,研究者们提出了多种导航指令生成方法。
-
这些方法包括基于LSTM的指令生成器(如Speaker-follower和Env-Drop),以及利用多个基础模型(如AutoVLN、MARVAL和ScaleVLN)来生成更简洁的子指令。
-
这些方法通常专注于识别导航轨迹中的地标并生成低级指令,但在整合全局上下文、匹配用户需求和规划高层任务方面存在局限性。
-
-
检索增强生成(RAG):
-
RAG最初被引入以增强大型语言模型(LLMs)的性能,通过检索相关文档片段提供领域特定知识。
-
随着时间的推移,RAG技术在机器人领域得到了扩展,用于构建非参数记忆或场景图以进行问答或导航。
-
然而,传统的RAG方法在平衡全局上下文与局部细节以及解释环境布局方面存在挑战。
-
-
NavRAG的创新:
-
论文指出,NavRAG通过构建场景描述树和使用层次化检索策略,实现了更好的场景理解和指令生成。
-
这种方法能够更好地整合全局上下文和用户需求,生成更符合实际应用的导航指令。
-
NavRAG方法
任务描述
-
在视觉语言导航(VLN)环境中,导航连接图 由Matterport3D模拟器提供,其中 表示可导航节点, 表示连接它们的边。
-
智能体配备有RGB摄像头和GPS传感器。智能体从起始节点开始,遵循自然语言指令,探索导航连接图 并移动到目标节点。
-
指令由词嵌入序列 表示,其中 是单词数量。
-
在每个时间步 ,智能体可以在当前节点 感知全景RGB观察 ,由 个视图图像组成。
构建场景描述树
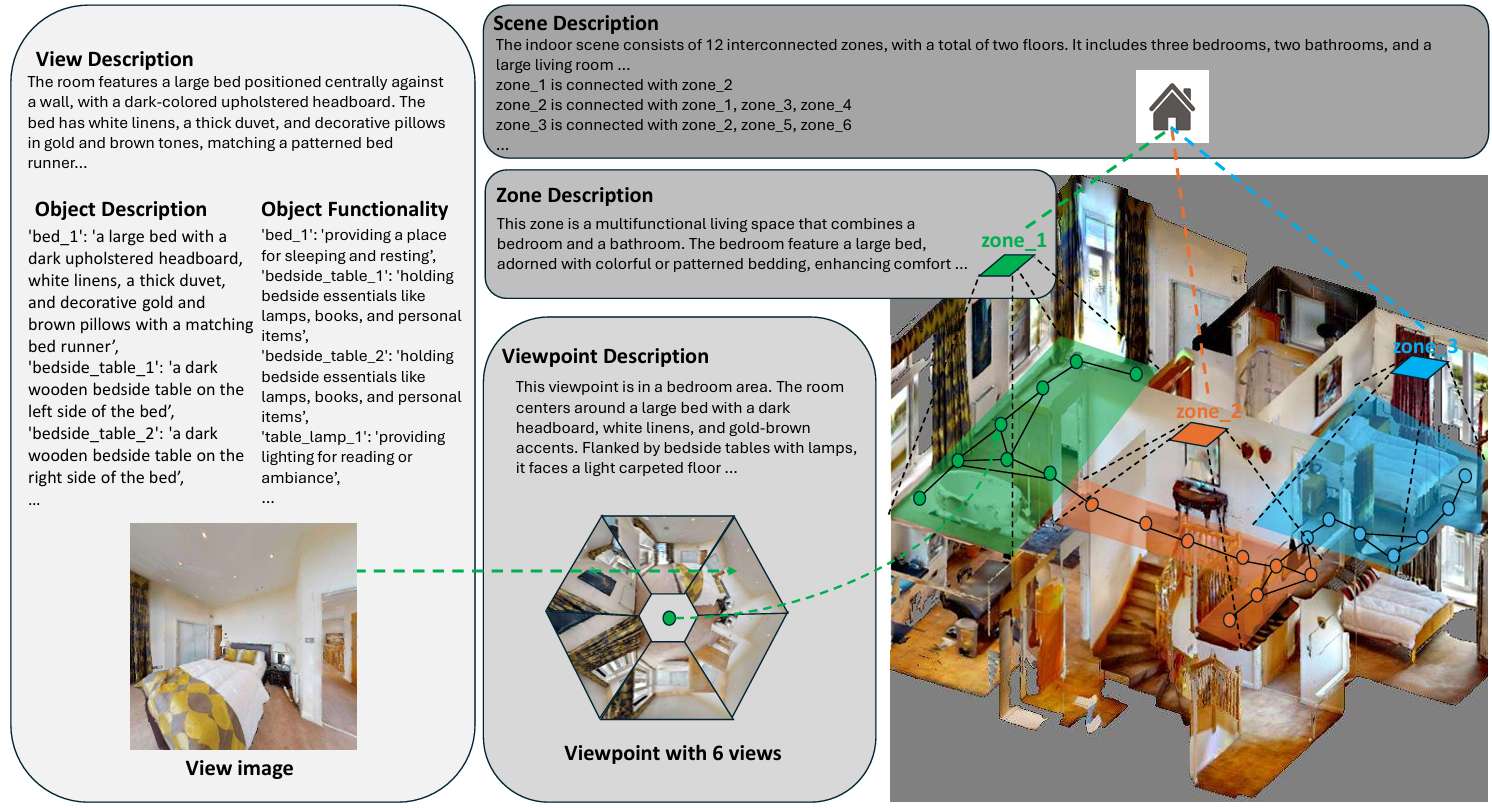
在生成指令之前,首先需要表示和理解环境。NavRAG采用自底向上的层次化方法构建场景描述树:
-
对象和视图级别:在视图和对象级别,每个对象用细粒度细节描述,包括其类别、属性和功能。空间关系在视图级别描述中被总结。
-
视点级别:在视点级别,将多个视图的描述和对象信息整合,生成视点周围环境的综合描述。这包括区域类型、空间布局和对象之间的关系。
-
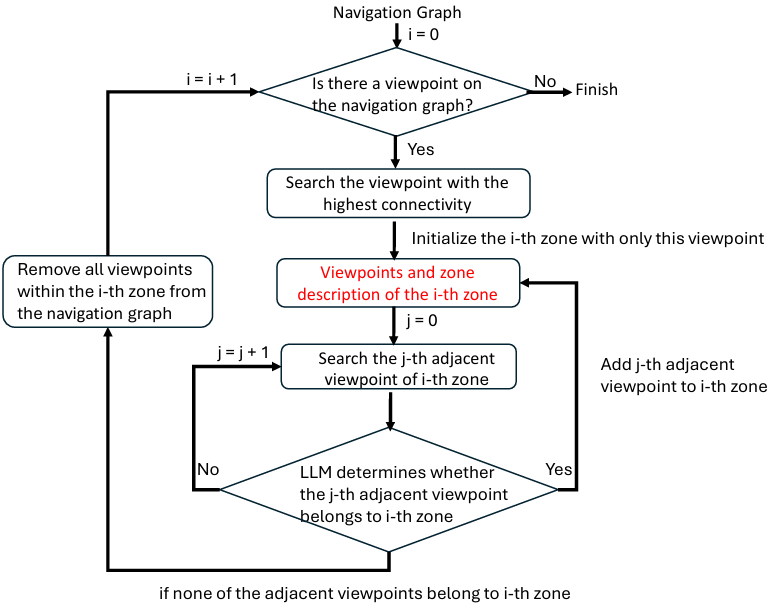
区域划分和标注:为了增强对场景空间布局的理解,NavRAG通过合并多个视点来构建区域。与基于空间位置的分层聚类不同,NavRAG的算法考虑了视点的连通性和环境语义,以确保准确识别场景的不同功能区域。
-
场景级别:场景级别的描述提供了整个场景的空间布局概述,包括不同区域之间的连通性、每个区域的类型和功能。
用户需求指令生成
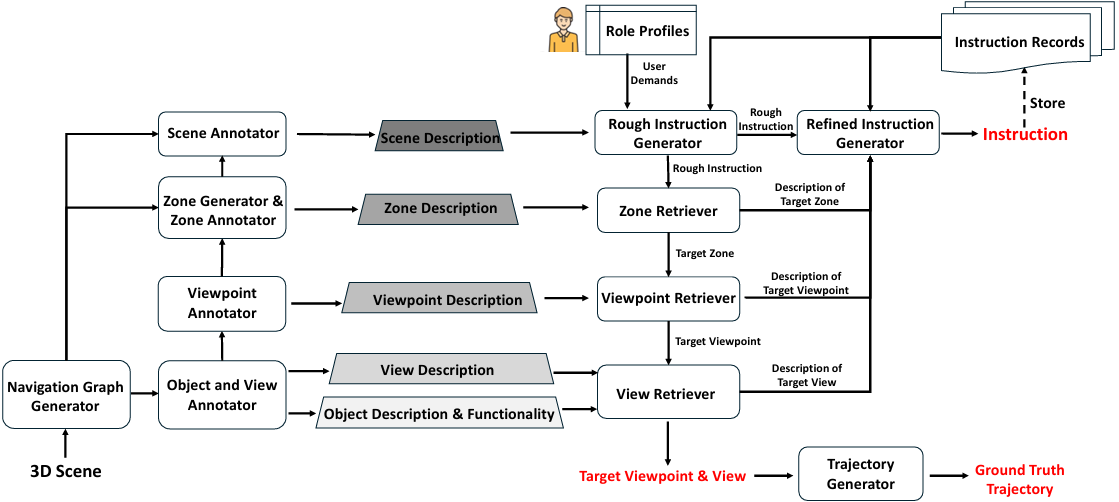
在构建场景描述树后,NavRAG利用场景级别描述、用户信息和需求生成粗略的导航指令。
然后,通过自顶向下的层次检索,从场景树中检索潜在的目标位置,并将不同层次的环境描述整合到LLM中,以细化粗略指令为精确和全面的指令。
-
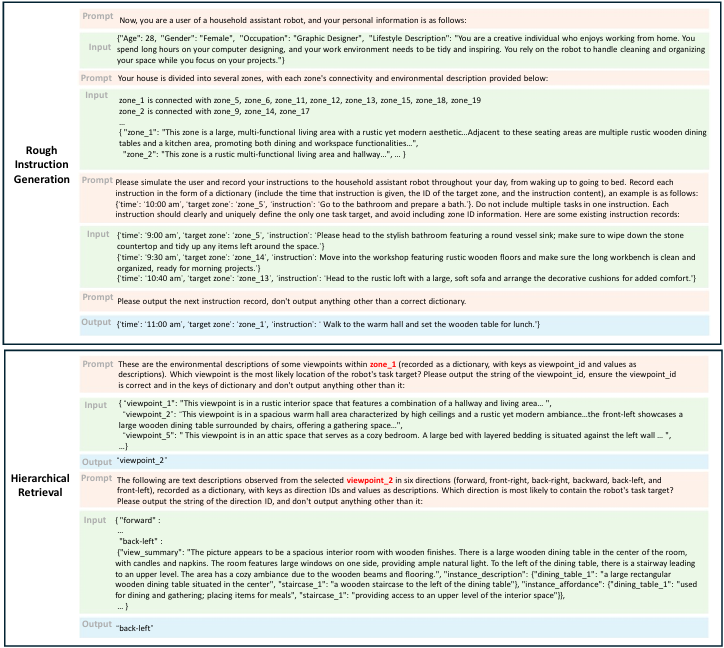
用户需求模拟:NavRAG通过模拟特定角色的行为来生成多样化的指令。为每个角色手动标注用户信息,指导LLM在给定场景描述树的情况下模拟角色的行为。
-
检索增强生成:NavRAG逐层检索场景描述树中的文本,逐步定位导航目标。初始时,LLM基于场景级别描述、用户信息和历史指令记录生成粗略指令。然后,通过检索区域级别和视点级别的描述,最终输出精确和全面的指令。
实验设置
数据集
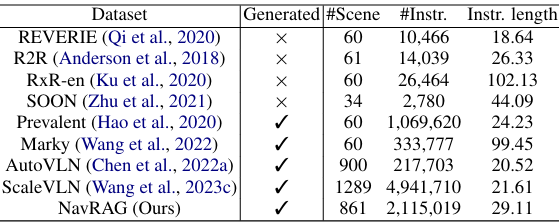
NavRAG在861个训练场景中生成了超过200万个高质量的导航指令。与其他数据集相比,NavRAG的指令长度更长,结构更多样。
评估指标
-
导航误差(NE):智能体最终位置与目标之间的最短路径距离的平均值。
-
Oracle成功率(OSR):智能体到达目标3米范围内的百分比。
-
成功率(SR):预测停止位置在目标3米范围内的百分比。
-
成功率的加权路径长度(SPL):用轨迹长度标准化成功率。
VLN基线模型
-
DUET:动态构建拓扑图的VLN模型,结合了全局探索和局部观察。
-
HAMT:集成长程历史的VLN模型,使用分层视觉变换器编码全景观察。
-
NavGPT:完全基于LLM的导航智能体,展示高阶规划和常识整合能力。
-
MapGPT:基于LLM的VLN智能体,集成在线语言形成的地图以实现全局探索。
结果分析
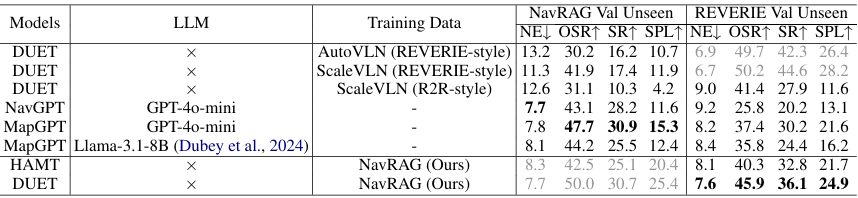
现有训练数据的局限性
-
实验结果表明,基于先前生成的大规模数据集(如AutoVLN和ScaleVLN)训练的模型在NavRAG基准上表现不佳,而基于LLM的方法表现出较强的性能。
-
NavRAG通过场景描述树和检索增强LLM生成更大语义空间的指令,更符合人类表达方式,从而提高了模型的理解能力。
NavRAG的泛化能力
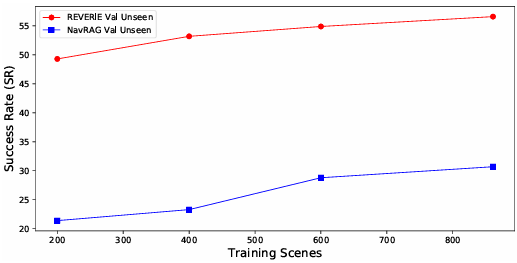
实验显示,基于NavRAG数据集训练的模型在NavRAG Val Unseen和REVERIE Val Unseen基准上表现出色,甚至超过了基于LLM的方法。这表明NavRAG数据集能够增强模型的泛化能力。
与SOTA方法的比较
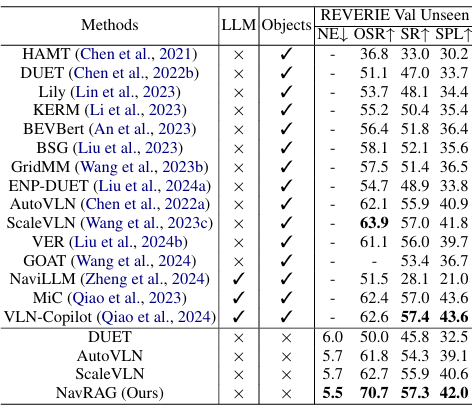
-
实验结果表明,DUET在NavRAG数据集上预训练并在REVERIE数据集上微调的表现优于其他SOTA方法。
-
NavRAG在去除对象边界框信息后仍表现出色,表明其在现实世界部署中的适用性。
消融研究
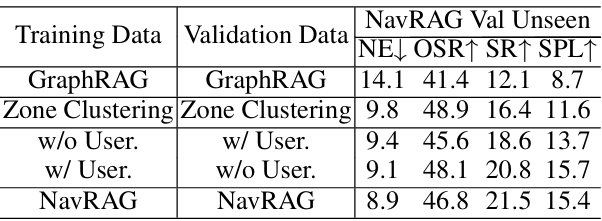
-
消融研究评估了NavRAG组件的有效性,包括检索增强生成、区域划分算法、用户需求模拟等。
-
结果表明,这些组件对提高指令质量和模型性能至关重要。
总结
-
论文提出了NavRAG,一种利用检索增强LLM生成用户需求导航指令的方法。
-
通过构建场景描述树和模拟用户角色,NavRAG有效提高了生成指令的质量和多样性。
-
实验结果表明,NavRAG训练的模型在多个VLN基准上表现出色,验证了该方法的有效性。
-
尽管NavRAG在生成指令的正确性评估上存在一定的局限性,但其在大规模生成导航数据方面的潜力得到了充分验证。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









