








-
作者: Karan Wanchoo, Xiaoye Zuo, Hannah Gonzalez, Soham Dan, Georgios Georgakis, Dan Roth, Kostas Daniilidis, Eleni Miltsakaki
-
单位:宾夕法尼亚大学
-
论文标题:NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
-
论文链接:https://arxiv.org/pdf/2412.13026
主要贡献
-
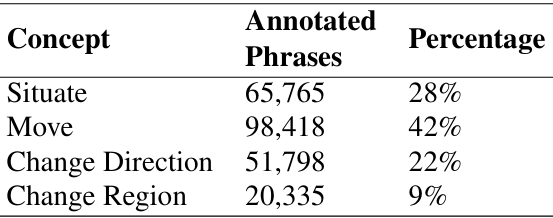
论文介绍了大规模的视觉语言导航语料库NAVCON,包含了对R2R和RxR数据集中超过30,000条指令进行的高层次导航概念标注。
-
训练了导航概念分类器(NCC),能够识别未见过的文本中的导航概念,在测试中表现出色,准确率高达96.53%,证明了标注的有效性和可靠性。
-
通过使用GPT-4o进行少样本学习实验,尽管GPT-4o的表现不如NCC,但其结果仍然表明了大型语言模型在处理此类任务时的能力。
-
通过人类评估研究和实验验证了标注的质量和实用性。人类评估显示,自动标注的方法在识别导航概念时准确率超过95%,进一步支持了NAVCON的可靠性和有效性。
研究背景
研究问题
论文旨在使机器人或其他智能体能够根据语言指令在各种空间中导航。
由于资源限制和环境的不可预测性,VLN模型需要具备实时处理语言和视觉输入的能力,并能将学习应用于新的物理环境中和未见过的指令。
研究难点
该问题的研究难点包括:
-
资源限制、
-
导航空间的不可预测性、
-
现有模型在跨模态对齐上的不平衡注意力。
研究内容
该问题的研究内容包括:
-
创建一个大规模的VLN语料库,包含对导航概念的自然语言实现的标注,并通过视频片段展示智能体在执行指令时所看到的内容。
-
提出了四个核心的导航概念,并开发了算法来生成这些概念的大规模标注。
相关工作
-
导航指令跟随:
-
导航指令跟随问题在多个领域引起了广泛关注,包括Google街景全景、四轴飞行器的模拟环境、多语言设置、交互式指令跟随任务、交互式视觉对话设置、现实世界场景以及室内场景的仿真。
-
早期的研究假设环境结构和语义是已知的,使用拓扑图和概率模型将指令映射到路径。这些方法通常依赖于语言解析系统来分解指令为空间描述子句或路径描述语言。
-
-
视觉语言导航:
-
随着视觉-语言导航任务的引入,研究者们开始在现实和未见过的环境中解决这个问题。尽管在映射和规划方面取得了显著进展,但有限的指令数据仍然是挑战。
-
为了缓解数据不足的问题,研究人员尝试从网络上收集大量非导航相关的图像-标题对,或者通过合成生成过程来丰富现有数据集。此外,一些研究利用大型视觉-语言模型的预训练表示来提高性能。
-
最近的研究尝试使用导航指令的依赖性分析来提高VLN智能体的性能,但这些方法依赖于噪声的指令依赖性解析,并且缺乏对指令中导航概念的分析。
-
-
NAVCON:
-
为了应对这些挑战,论文提出了NAVCON导航概念语料库,通过对指令进行高层次的认知启发的概念类别标注,提供可靠的通用资源。
-
认知启发的导航概念库

受到大脑映射研究的启发,基于对大脑中负责导航的区域的研究,定义了四个核心的导航概念类别,这些概念类别在动物和人类的导航行为中起着重要作用。具体来说:
- Situate Yourself:
-
这一概念类源自海马体中位置细胞的放电率变化。
-
位置细胞根据动物的位置增加或减少放电率,帮助动物确定自己在环境中的位置。
-
- Change Direction:
-
这一概念类与头方向细胞有关,这些细胞位于边缘系统中,根据动物的头部方向独立于其位置进行放电。
-
可以帮助动物在环境中调整方向。
-
- Change Region:
-
边界细胞根据环境中的边界进行放电。
-
这些细胞帮助动物识别和适应环境中的不同区域。
-
- Move along a Path:
-
这一概念类涉及空间导航和定向,依赖于运动及其激活的运动、前庭和本体感觉系统。
-
心理学家Lynch的分类中将“路径”视为个体移动的通道。
-
这些概念类别被识别为导航指令中的核心概念,帮助机器人在执行导航任务时理解和应用这些高层次的概念,提高机器人在复杂环境中的导航能力。
NAVCON
导航概念识别与标注

该部分的目标是识别语言中的导航概念,并对其进行标注。具体步骤包括:
-
根动词检索:运行一个完整的自然语言处理管道流程,包括分词、词形还原、词性标注和句法解析,以识别R2R和RxR指令中的根动词。
-
导航动词生成:从根动词生成导航动词列表,并清理由根动词锚定的动词短语及其句法子节点。
-
自动标注:通过分析语法解析输出,识别和标注导航概念的语言实例。最终得到236,316个导航概念的语言实例。
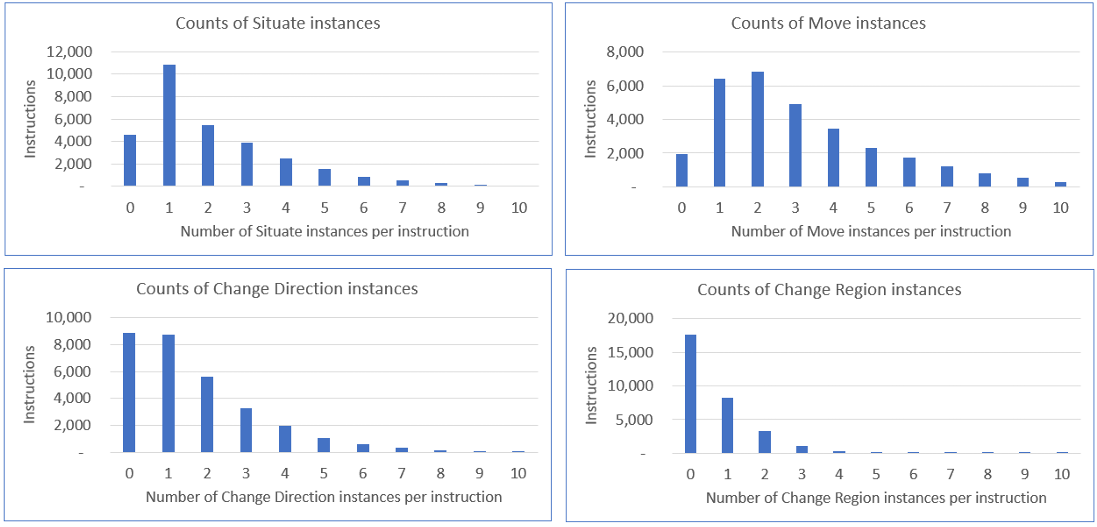
- 结果:
-
根动词:识别出348个根动词,经过人工评估后,确定了81个根导航动词。
-
概念分布:四个概念类别(Situate Yourself、Move along a Path、Change Direction、Change Region)在指令中的分布情况。
-
人类评估
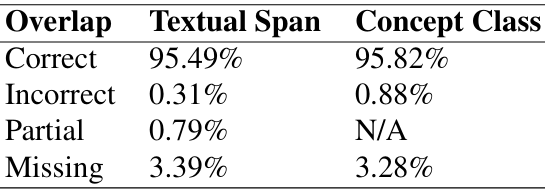
为了评估自动标注的质量,进行人类评估研究。具体步骤包括:
-
样本选择:随机抽取300个自动标注的概念实例进行评估。
-
评估标准:评估者判断检测到的文本和分配的概念标签的准确性。每个识别的概念被标记为正确、错误或缺失。
-
结果:自动方法识别概念实例的准确率超过95%,识别文本的准确率超过95%。
视频概念识别与标注
为了支持跨模态模型的训练,NAVCON还包括与标注的导航概念对应的视频帧。具体步骤包括:
-
视频帧提取:利用RxR数据集中包含的时间戳信息,从视频中提取与导航概念对应的帧。
-
时间戳映射:使用Habitat模拟器根据时间戳提取视频帧,并对齐语言实例和视频帧。
-
采样和存储:每10个连续的视频帧中采样1个,以减少数据集大小并保持视觉连续性。最终,生成了2.7百万个与概念对应的视频帧。
概念-视频配对评估

评估概念-视频配对的准确性。具体步骤包括:
-
样本选择:由人类标注员对100个随机采样的指令进行评估。
-
评估标准:标注员判断视频序列是否准确匹配相应的导航概念。匹配可以是完全匹配或部分匹配。
-
结果:结通过扩展提取窗口,准确率从73.6%提高到88.6%。这表明通过调整时间窗口可以显著提高概念-视频配对的准确性。
模型训练
导航概念分类器
训练一个导航概念分类器(NCC)模型,用于识别输入文本中的导航概念及其对应的短语。目标是验证NAVCON标注的质量和实用性。
方法
-
模型选择:使用轻量级通用目的模型DistilBERT(distilbert-base-uncased)进行微调。
-
数据准备:使用30,629条标注指令进行训练。每个单词被分配一个标签,表示它属于五个类别之一(四个导航概念和一个非类别)。
-
格式化:使用BIO格式进行训练数据的格式化。对于概念短语的第一个单词添加前缀"B-",表示短语的开始;对于短语中的其他单词添加前缀"I-"。
-
训练:使用学习率为,在6个epoch上进行微调。
-
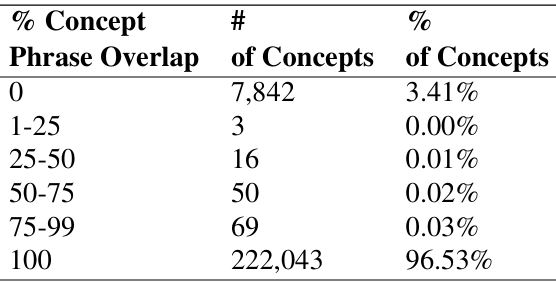
评估:
-
短语识别:评估预测的标签是否正确,并测量预测的短语与真实短语的重叠百分比。
-
结果:NCC模型在预测概念和对应短语方面的准确率达到96.53%。
-
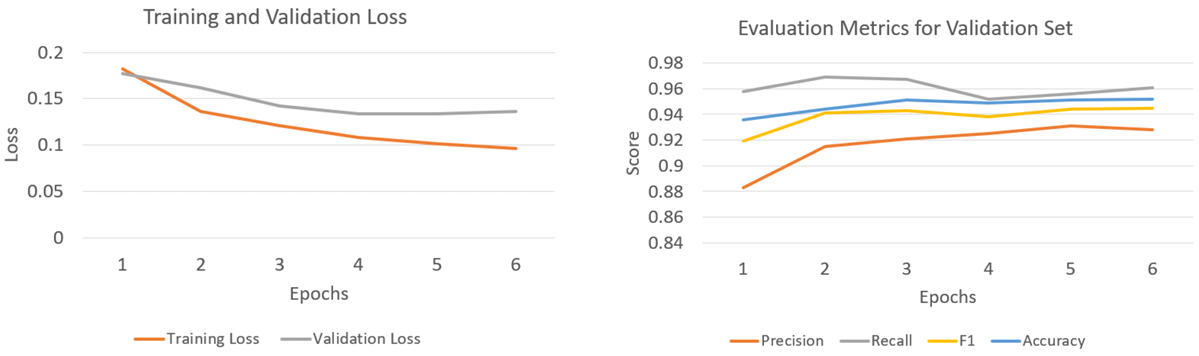
分析
NCC模型的成功训练验证了NAVCON标注的有效性和可靠性,表明该方法可以大规模生成高质量的导航概念标注。
GPT-4o少样本学习
探索使用大型语言模型(LLM)进行少样本学习,以生成高层次导航概念的标注。
方法
-
GPT-4o实验:
-
提示设计:设计一个提示,描述预测导航概念的任务,并提供3个示例。
-
训练:使用GPT-4o模型,通过提示和3个示例学习关键短语与导航概念之间的关联。
-
评估:使用190条未见过的指令(来自相同的金数据集)进行评估,测量GPT-4o的预测准确性。
-
-
结果:
-
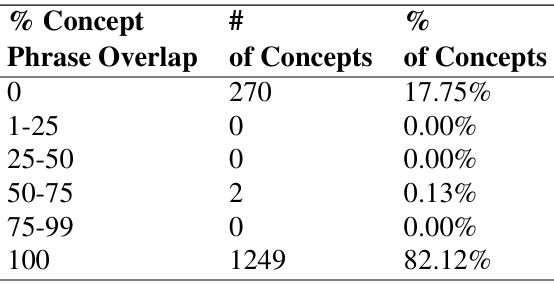
准确性:GPT-4o在预测完整概念和对应短语方面的准确率达到82.12%。
-
分析
尽管GPT-4o的性能不如NLP管道方法,但其表现仍然令人鼓舞,表明少样本学习在导航概念识别中的应用潜力。
总结
-
论文介绍了NAVCON,一个大规模标注的视觉语言导航数据集,包含了四个核心导航概念的标注和视频帧的对齐。
-
通过人类评估和少样本学习的实验,验证了标注的质量和有用性。
-
NAVCON的发布将为未来的VLN研究提供重要的资源,使结果更具可解释性,并简化语言指令到视觉输入的对齐过程。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









