









![]()
![]()
-
作者:Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, Yizhou Wang
-
单位:北京师范大学,北京航空航天大学,北京大学,BIGAI,澳门城市大学,新加坡国立大学
-
论文标题:UNREALZOO: ENRICHING PHOTO-REALISTIC VIRTUAL WORLDS FOR EMBODIED AI
-
论文链接:https://arxiv.org/abs/2412.20977
-
项目主页:http://unrealzoo.site/
-
代码链接:https://github.com/UnrealZoo/unrealzoo-gym
主要贡献
-
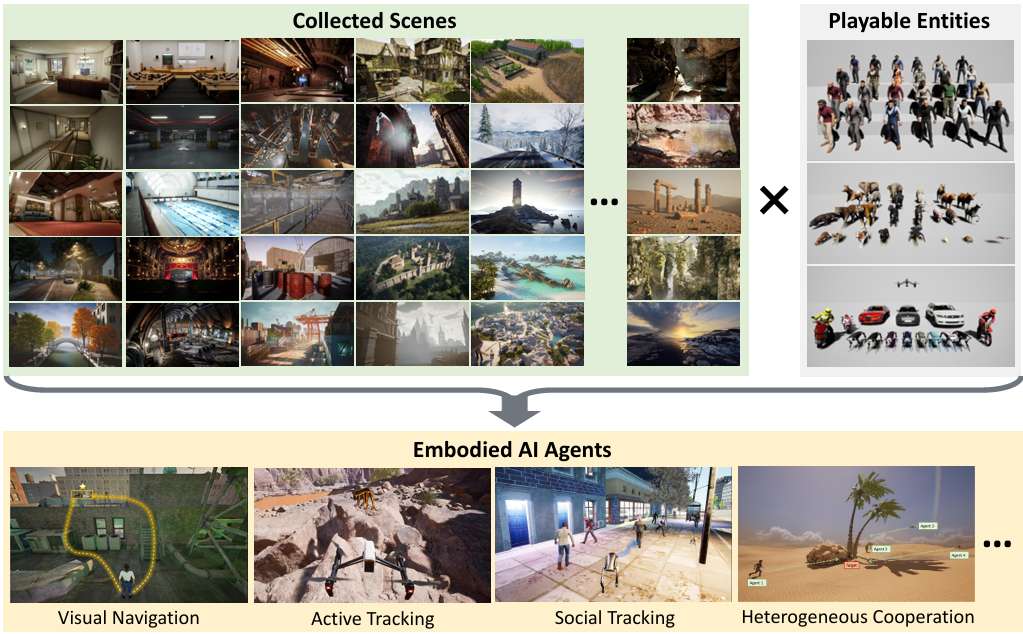
论文介绍了UnrealZoo,包含100个高质量、照片级真实感场景的合集,并提供了一系列具有多样化特征的实体,旨在应对开放世界中具身智能(Embodied AI)智能体所面临的挑战。
-
对UnrealCV进行了优化,提供了易于使用的Python API和工具(称为UnrealCV+),以提高渲染和多智能体交互的效率。
-
通过实验展示了UnrealZoo在具身AI中的应用,特别是在视觉导航和跟踪任务中的表现。实验结果强调了多样化的训练环境对于增强智能体泛化能力和鲁棒性的重要性。
-
提供了易于使用的OpenAI Gym接口和工具包,用于定制和扩展环境以满足未来应用的需求。
研究背景
研究问题
-
当前,具身AI智能体通常局限于受控的室内环境,很少探索开放世界的多样性。
-
论文主要解决的问题是如何增强具身智能(Embodied AI)智能体在开放世界中的适应性和泛化能力。
研究难点
该问题的研究难点包括:
-
在动态场景中闭环控制的延迟、
-
在非结构化地形中推理3D空间结构、
-
多智能体交互的复杂性等。
相关工作
现实模拟器用于具身智能
-
模拟器的优势:
-
高质量渲染:现实模拟器因其高质量渲染而广泛用于具身智能,能够生成高保真度的图像。
-
低成本生成:这些模拟器可以以较低的成本生成真实世界的基准数据。
-
低成本的交互:它们允许以低成本进行交互,便于训练和测试AI智能体。
-
环境可控性:模拟器提供了对环境的控制能力,使得研究人员可以在受控的环境中进行实验。
-
-
特定应用:
-
室内导航:模拟器被用于室内导航任务,如VirtualHome、AI2THOR等。
-
机器人操作:用于机器人操作任务,如Yu等人(2020)、Ehsani等人(2021)和Chen等人(2024)的工作。
-
自动驾驶:用于自动驾驶任务,如Gaidon等人(2016)、Shah等人(2018)和Dosovitskiy等人(2017)的研究。
-
-
通用虚拟世界:
-
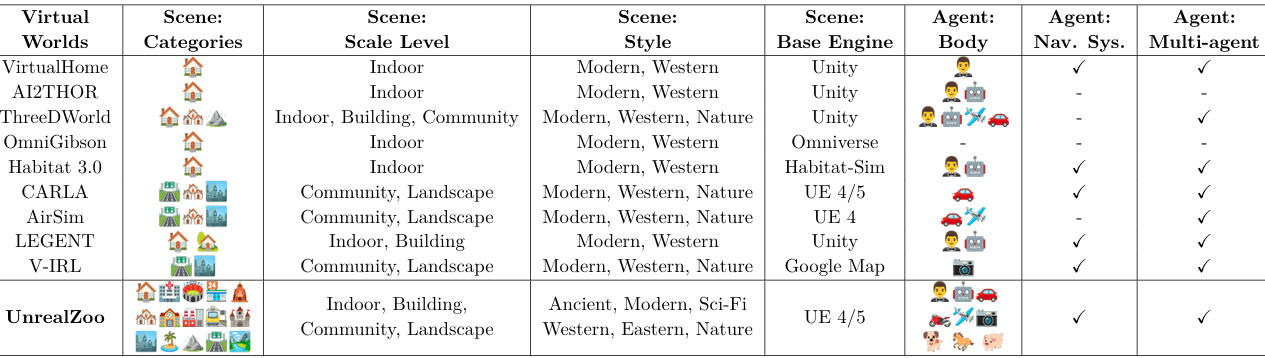
多模态平台:近年来,研究者们开始开发具有照片级渲染的通用虚拟世界,如ThreeDWorld和LEGENT,这些平台基于Unity引擎,提供多模态交互。
-
动态环境:V-IRL利用Google Maps的API来模拟具有真实世界街景图像的智能体,减少了虚拟与现实之间的差距,但缺乏物理世界的动态模拟能力。
-
-
UnrealZoo的优势:
-
多样化的场景:UnrealZoo提供了各种不同规模、情境、时代和文化背景的场景,覆盖了从古代到科幻的各种风格。
-
高性能渲染:通过优化Unreal Engine和UnrealCV,UnrealZoo能够在大规模场景中实现实时性能,并支持多个智能体的互动。
-
具身视觉智能体
-
任务类型:
-
导航:具身视觉智能体执行的任务包括导航(如Zhu等人,2017;Gupta等人,2017;Yokoyama等人,2024;Long等人,2024)。
-
主动跟踪:还包括主动对象跟踪(如Luo等人,2018;Zhong等人,2019、2021、2023、2024)和其他交互任务(如Chaplot等人,2020;Weihs等人,2021;Ci等人,2023;Wang等人,2023)。
-
-
方法:
-
状态表示学习:涉及状态表示学习(如Yadav等人,2023;Yuan等人,2022;Gadre等人,2022;Yang等人,2023)。
-
强化学习(RL):使用强化学习方法(如Schulman等人,2017;Xu等人,2024;Ma等人,2024)。
-
大视觉语言模型(VLMs):利用大视觉语言模型(如Zhang等人,2024;Zhou等人,2024a)。
-
-
挑战:
-
泛化能力:尽管取得了显著进展,但RL方法通常需要大量的试错交互和计算资源进行训练,并且在泛化到新环境时表现不佳。
-
推理成本:VLM方法在解释语言指令和图像方面表现出色,但在实时交互中可能缺乏必要的细粒度控制和适应性。
-
开放世界挑战:现有的模拟器主要集中在室内房间或城市道路上,掩盖了在开放世界中部署时具身智能体面临的潜在挑战,如非结构化地形、动态变化因素、感知控制回路的推理成本以及与其他智能体的社会互动。
-
UnrealZoo
UnrealZoo是一个基于Unreal Engine构建的多样化、照片级逼真的开放世界合集。
环境合集
场景来源与构建
-
来源:UnrealZoo包含100个基于Unreal Engine 4和5的场景,这些场景来源于Unreal Engine Marketplace,由艺术家提供的高质量内容组成。
-
积累过程:这些环境是在两年内积累的,成本超过10,000美元。
-
多样性:环境涵盖了从古代到现代、从西方到东方、从自然景观到人造环境的广泛风格,确保了多样性和复杂性。
场景标签与分类
-
标签系统:每个场景都被标记为不同的特征标签,以便研究人员可以根据场景的标签选择合适的场景进行测试或训练。
-
分类:场景根据其类别、规模、空间结构、动态和风格进行分类。例如,场景分为室内、室外和两者兼有的类型,规模分为室内、建筑、社区和景观等级别。
场景集成
-
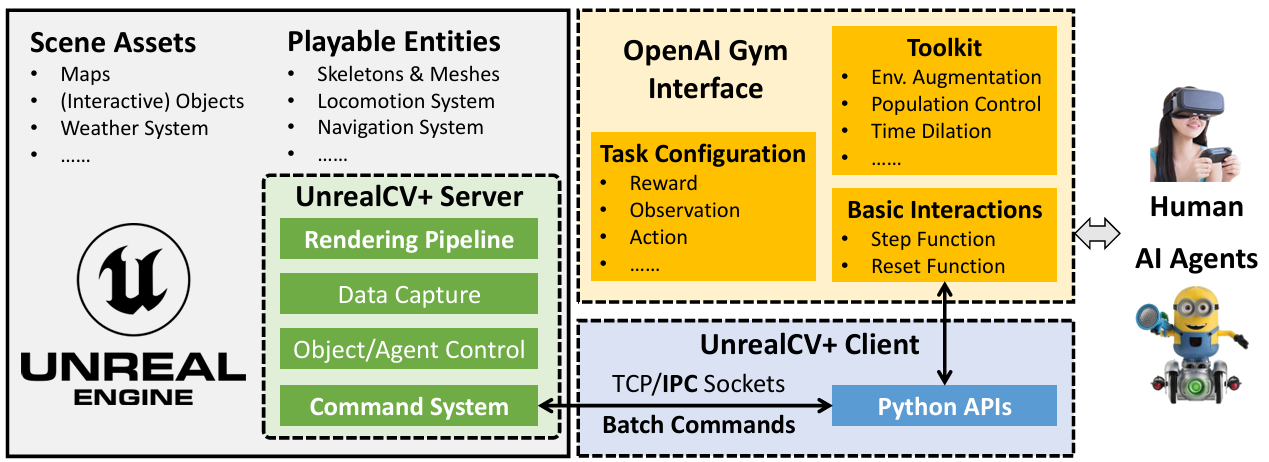
UnrealCV+集成:将UnrealCV+集成到Unreal Engine项目中,添加可控制的玩家资产到每个场景。
-
二进制包:由于市场购买的内容不能开源,项目被打包成可执行二进制文件,以便社区共享。这些二进制文件兼容Windows、Linux和macOS操作系统。
可控实体
实体类型
-
实体种类:UnrealZoo包括七种可控实体:人类、动物、汽车、摩托车、无人机、移动机器人和飞行相机。
-
实体数量:具体包括19个人类实体、27种动物实体、3辆汽车、14个四足机器人、3辆摩托车和1架四轴飞行器。

功能与控制
-
骨架与纹理:每个实体都有骨架、适当的网格和纹理,以及一个本地运动系统和导航系统。
-
API控制:提供一套可调用的函数,允许用户修改实体的属性,如大小、外观和相机位置,并控制运动。
-
导航系统:基于NavMesh,允许智能体自主导航,具备路径规划和避障能力。
视觉数据采集
-
摄像机系统:每个实体都配备了一个自我中心的摄像机,允许用户从智能体的第一人称视角捕捉RGB、深度、表面法线和实例级分割(对象掩码)等多种类型的图像数据。
编程接口
UnrealCV+
-
API优化:提供基于Python的应用编程接口(API),用于捕获数据和控制实体及场景。UnrealCV+是UnrealCV的改进版本,优化了渲染管道和通信协议以提高帧率。
-
并行处理:在渲染对象掩码和深度图像时启用并行处理,显著提高了大规模场景中的帧率。
-
批处理命令:引入批量命令协议,客户端可以同时发送一批命令到服务器,减少服务器-客户端通信的时间。

OpenAI Gym接口
-
标准交互:提供标准的智能体-环境交互界面,定义了交互任务并标准化了智能体-环境交互。
-
任务配置:用户可以通过JSON文件配置任务特定的参数,如连续和离散动作空间、绑定摄像机的位置等。
-
工具包:提供了一套工具包,包括环境增强、人口控制、时间膨胀等功能,帮助用户自定义环境以满足各种任务需求。
实验
视觉导航
实验设置
-
复杂环境:视觉导航在野外环境中引入了比传统室内场景或自动驾驶任务更高的复杂性。实验中,智能体被放置在开放世界环境中,需要通过一系列动作(如奔跑、攀爬、跳跃、蹲下)来克服无结构地形中的各种障碍,以到达目标物体。
- 评估指标: 使用两个关键指标来评估视觉导航智能体:
-
平均回合长度(Average Episode Length, EL),表示每回合的平均步数;
-
成功率(Success Rate, SR),测量智能体成功导航到目标物体的百分比。
-
基线方法
-
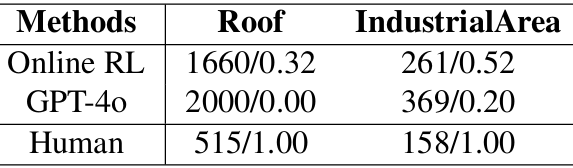
在线强化学习(Online RL):在Roof和Factory环境中分别训练RL智能体,使用分布式在线强化学习方法(如A3C)。模型输入第一人称视角的分割掩码和智能体与目标之间的相对位置,并输出直接控制信号进行导航。
-
GPT-4o:使用GPT-4o模型来采取行动,利用其强大的多模态推理能力。模型输入第一人称视角的图像和智能体与固定目标之间的相对位置,根据预定义的控制空间推理适当的动作。
-
人类玩家:人类玩家使用键盘控制智能体,类似于第一人称视频游戏。玩家从随机起点导航到固定目标,基于视觉观察做出决策。
结果
-
RL智能体在较简单环境中表现较好,但在复杂环境中表现不佳。
-
GPT-4o在两种场景中都表现不佳,表明其在复杂3D场景推理中的局限性。
-
人类玩家在两个任务中都表现出色,显示出当前智能体与人类之间的显著差距。
主动视觉跟踪
环境选择
-
环境多样性:选择四个环境类别(室内场景、宫殿、荒野、现代场景)进行评估,每个类别包含4个独立环境。实验旨在捕捉环境合集中的广泛特征,确保对智能体能力的全面评估。
评估指标
使用三个关键指标评估:
-
平均回合回报(Average Episodic Return, ER),提供整体跟踪性能的洞察;
-
平均回合长度(Average Episode Length, EL),反映长期跟踪效果;
-
成功率(Success Rate, SR),测量完成500步的回合百分比。
基线方法
-
离线强化学习(Offline RL):扩展自最近的离线RL方法,收集离线数据集并采用原始网络架构。通过收集不同数量环境的离线数据集来分析数据多样性的影响。
-
VLM-based智能体:使用GPT-4o模型直接生成基于观察图像的动作,以跟踪目标人物。设计了系统提示来帮助模型理解任务并标准化输出格式。
结果分析

-
随着训练环境数量的增加,智能体在所有类别中的长期跟踪性能普遍提高。
-
在Wilds中,使用8 Envs.数据集的成功率显著提高,表明多样化的环境暴露对提高智能体在更复杂的开放世界环境中的泛化能力至关重要。
社会跟踪
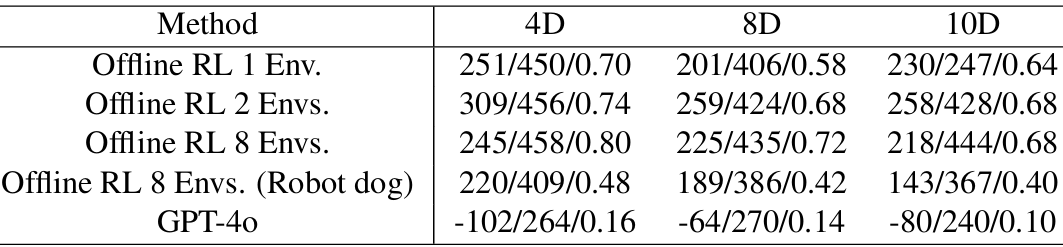
动态干扰下的鲁棒性
-
动态干扰:在人群中进行跟踪时,智能体需要处理动态干扰。实验中,生成具有不同数量人类角色的群体作为干扰。
-
结果:随着干扰数量的增加,离线RL方法保持相对稳定的成功率,而GPT-4o模型在动态环境中表现不佳,显示出其在动态干扰下的局限性。
跨实体泛化
-
跨实体泛化:将针对人类角色训练的智能体转移到机器人狗上进行评估。结果显示成功率下降,表明研究社区应更多关注跨实体泛化。
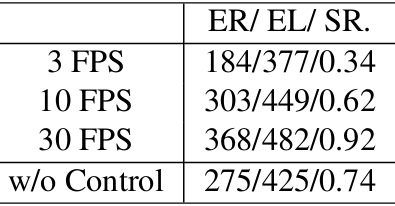
控制频率的影响
-
控制频率:使用时间膨胀包装器模拟不同的控制频率。结果表明,当感知-控制循环的频率低于10 FPS时,性能显着下降。高控制频率使RL智能体在社会跟踪中表现更好,强调了在动态开放世界中完成任务时构建高效模型的重要性。
总结
-
论文提出了UnrealZoo,一个多样化的照片级虚拟世界合集,旨在推动具身AI研究的发展。
-
通过提供高质量的虚拟环境和优化的编程接口,UnrealZoo能够支持高效的单智能体和多智能体系统交互。
-
实验结果表明,多样化的训练环境对智能体的泛化能力和鲁棒性至关重要,而基于RL的方法在处理动态环境和社交互动方面表现出色。
-
未来的工作将继续丰富虚拟世界的场景、实体和交互任务,推动具身AI在现实世界中的应用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









