









本篇是迁移学习专栏介绍的第四篇论文,最初发表于NIPS 2014,本篇论文的作者是Jason Yosinski博士(当时是康奈尔大学的博士生),Uber AI联合创始人。同时三作是Yoshua Bengio,也是刚刚获得了图灵奖。
Abstract
许多以自然图像为训练对象的深度神经网络都表现出一个奇怪的共同现象:在第一层,它们学习到类似Gabor过滤器和色块的特征。这些第一层特性似乎不是特定于特定的数据集或任务,而是通用的,因为它们适用于许多数据集和任务。特性最终必须由网络的最后一层从一般特性过渡到特定特性,但是这种过渡还没有得到广泛的研究。本文对深卷积神经网络各层神经元的通用性和特异性进行了实验量化,得到了一些令人惊讶的结果。可迁移性受到两个不同问题的负面影响:
- 较高层次神经元对其原始任务的专门化,以牺牲目标任务的性能为代价,这是预期的;
- 与共适应神经元之间的网络分裂相关的优化困难,这是预期不到的。在一个基于ImageNet的示例网络中,我们演示了这两个问题中的一个可能占主导地位,这取决于特性是从网络的底部、中部还是顶部传输的。
我们还记录了随着基本任务和目标任务之间距离的增加,特征的可移植性降低,但是即使是从遥远的任务迁移特征也比使用随机特征要好。最后一个令人惊讶的结果是,初始化一个具有几乎任意层传输的特性的网络可以提高泛化能力,即使在对目标数据集进行微调之后,泛化仍然存在。
1 Introduction
现代深度神经网络呈现出一种奇怪的现象:当对图像进行训练时,它们都倾向于学习与Gabor过滤器或色块类似的第一层特征。这些过滤器的出现是如此常见,以至于在自然图像数据集中获取任何其他内容都会引起对选择不当的超参数或软件错误的怀疑。这种现象不仅发生在不同的数据集上,甚至出现在训练目标非常不同的情况下,包括监督图像分类(Krizhevsky et al., 2012)、无监督密度学习(Lee et al., 2009)和稀疏表示的无监督学习(Le et al., 2011)。
由于在第一层找到这些标准特性似乎与精确的成本函数和自然图像数据集无关,所以我们将这些第一层特性称为通用特性。另一方面,我们知道训练网络的最后一层所计算的特征在很大程度上依赖于所选择的数据集和任务。例如,在一个具有n维softmax输出层的网络中,每个输出单元都是特定于一个特定的类的。因此,我们称最后一层特性为特定的。这些都是一般和具体的直观概念,我们将在下面提供更严格的定义。如果第一层的特性是通用的,而最后一层的特性是特定的,那么必须在网络的某个地方从通用特性过渡到特定特性。这一观察提出了几个问题。
- 我们能否量化某个特定层是通用的还是特定的?
- 这种转变是突然发生在单个图层上,还是分散在多个图层上?
- 这种转换发生在哪里:网络的第一层、中间层或最后一层附近?
我们对这些问题的答案很感兴趣,因为只要网络中的特性是通用的,我们就可以将它们用于迁移学习(Caruana, 1995;Bengio,2011;Bengio, 2011)。在迁移学习中,我们首先在一个基本数据集和任务上训练一个基本网络,然后我们将学习到的特性重新使用,或者将它们迁移到第二个目标网络上,以便在一个目标数据集和任务上进行训练。如果这些特性是通用的,即同时适用于基本任务和目标任务,而不是特定于基本任务,则此过程将趋向于工作。
当目标数据集明显小于基本数据集时,迁移学习可以成为训练大型目标网络而不过度拟合的有力工具;最近的研究利用这一事实,从更高的层次迁移时获得了最先进的结果(Donahue et al., 2013a; Zeiler and Fergus, 2013; Sermanet et al., 2014),共同表明这些神经网络层确实计算出相当普遍的特征。这些结果进一步强调了研究这种普遍性的确切性质和范围的重要性。
通常的迁移学习方法是训练一个基本网络,然后将它的前n层复制到目标网络的前n层。然后随机初始化目标网络的其余层,并针对目标任务进行训练。可以选择将错误从新任务反向传播到基本(复制的)特性中,以便将它们微调到新任务中,或者保留已传输的特性层,这意味着在对新任务进行培训期间它们不会发生变化。是否微调目标网络的前n层取决于目标数据集的大小和前n层中的参数数量。如果目标数据集很小,而参数数量很大,微调可能会导致过度拟合,因此特性常常被冻结。另一方面,如果目标数据集很大或参数数量很少,因此过度拟合不是问题,那么可以根据新任务对基本特性进行微调,以提高性能。当然,如果目标数据集非常大,则几乎不需要进行传输,因为较低级别的过滤器可以在目标数据集上从头开始学习。在下面的部分中,我们将比较这两种技术中微调特性和冻结特性的结果。
在本文中,我们做了一些贡献:
- 我们定义了一个特定的方法来量化程度层一般或特定,即功能如何在这一层迁移从一个任务到另一个(第二节)。我们对卷积神经网络训练ImageNet数据集,描述层过渡从一般到具体的(4节),会产生以下四个结果。
- 我们在实验中发现,在不进行微调的情况下使用传输的特性会导致性能下降,这是两个独立的问题:(i)特性本身的特异性,以及(ii)由于相邻层上的共适应神经元之间的基网络分裂而导致的优化困难。我们展示了这两种效应如何在网络的不同层中占据主导地位。(4.1节)
- 我们量化了基本任务和目标任务越不相似,迁移特性的性能优势就越小。(4.2节)
- 在相对较大的ImageNet数据集上,我们发现,当使用随机下层权重与训练权重计算的特性时,对于较小的数据集(Jarrett et al., 2009),性能比以前报道的要低。我们将随机权重与经过冻结和微调的迁移权重进行比较,发现迁移权重的性能更好(4.3节)。
- 最后,我们发现,初始化具有几乎任意层传输的特性的网络可以在对新数据集进行微调后提高泛化性能。这尤其令人惊讶,因为即使在进行了广泛的微调之后,看到第一个数据集的效果仍然存在。(4.1节)
2 Generality vs. Specificity Measured as Transfer Performance
我们注意到Gabor过滤器和色块在自然图像训练的神经网络的第一层出现的奇怪趋势。在这项研究中,我们定义了一组特性的程度的普遍性学习任务上的程度的特性可用于另一个任务。重要的是要注意,这个定义取决于之间的相似性和B。创建对分类任务A和B通过构建双重叠ImageNet数据集的子集。这些子集可以被选择为彼此相似或不同。

为了创建任务A和任务B,我们将1000个ImageNet类随机分成两组,每组包含500个类和大约一半的数据,或者每组包含大约64.5万个示例。我们在A上训练一个八层卷积网络,在b上训练另一个八层卷积网络。这些网络,我们称为baseA和baseB,如图1的前两行所示。然后我们从{1, 2, . . . , 7}和训练几个新的网络。在下面的解释和图1中,我们使用层n = 3作为选择的示例层。首先,我们定义并训练以下两个网络:
- selffer网络B3B:前3层是从baseB复制并冻结的。5个更高的层(4 - 8)被随机初始化,并在数据集b上进行训练。这个网络是下一个传输网络的控制。(图1,第3行)
- transfer网络A3B:前3层从baseA复制并冻结。五层(4 - 8)随机初始化和训练数据集B。直观,我们复制前3层网络训练数据集,然后学习更高一层功能上的新目标数据集分类如果A3B执行以及baseB,有证据表明,第三层特性一般,至少对b,如果性能受到损害时,有证据表明,第三层的功能是特定于A(图1中,行4)
我们对和双向(即AnB和BnA)。在上述两个网络中,传输层被冻结。我们还创建了上述两个网络的版本,其中传输的层被微调:
- selffer网络
:就像B3B,但是所有层都可以学习。
- transfer网络
:就像A3B,但是所有层都可以学习。
创建基础和目标数据集相似,我们随机给AB各分配的500个ImageNet类,ImageNet包含集群类似的课程,尤其是狗和猫,像这些13类生物家族的猫科:{虎斑猫、虎猫、波斯猫、暹罗猫、埃及猫、美洲狮、猞猁、豹、雪豹、捷豹、狮子、老虎、豹}。平均而言,A和B将各自包含大约6或7个这种猫科动物类,这意味着在每个数据集上训练的基础网络将具有有助于对某些猫科动物分类的所有级别的特征。当推广到其他数据集时,我们期望在旧的低级felix检测器的基础上训练的新的高级felix检测器能够很好地工作。因此,通过随机为每个类分配类创建的A和B是相似的,并且我们期望传输的特性将比A和B不太相似时表现得更好。
幸运的是,在ImageNet中,我们还提供了父类的层次结构。这一信息允许我们创建一个特殊的数据集分割为两部分,这两部分在语义上尽可能不同:数据集a只包含人工实体,而数据集B包含自然实体。这种分化并不十分均衡,人工组有551个职业,自然组有449个职业。在补充材料中有关于这部分的进一步细节和每一半的课程。在第4.2节中,我们将展示当数据集不太相似时,特征传递得更差(即它们更具体)。
3 Experimental Setup
自Krizhevsky等人(2012)在ImageNet 2012竞赛中获胜以来,人们对大卷积模型超参数的调整产生了极大的兴趣和努力。然而,在本研究中,我们的目标不是最大化绝对性能,而是研究一个著名架构上的传输结果。我们使用Caffe (Jia et al., 2014)提供的参考实现,使我们的结果具有可比性、可扩展性,并且对大量研究人员有用。有关训练设置(学习率等)的详细资料载于补充资料,复制这些实验的代码和参数文件载于http://yosinski.com/transfer
4 Results and Discussion
我们做了三组实验。主要实验有随机的A/B分裂,将在4.1节中讨论。第4.2节给出了一个人造/自然分裂的实验。第4.3节描述了一个随机权重的实验。
4.1 Similar Datasets: Random A/B splits
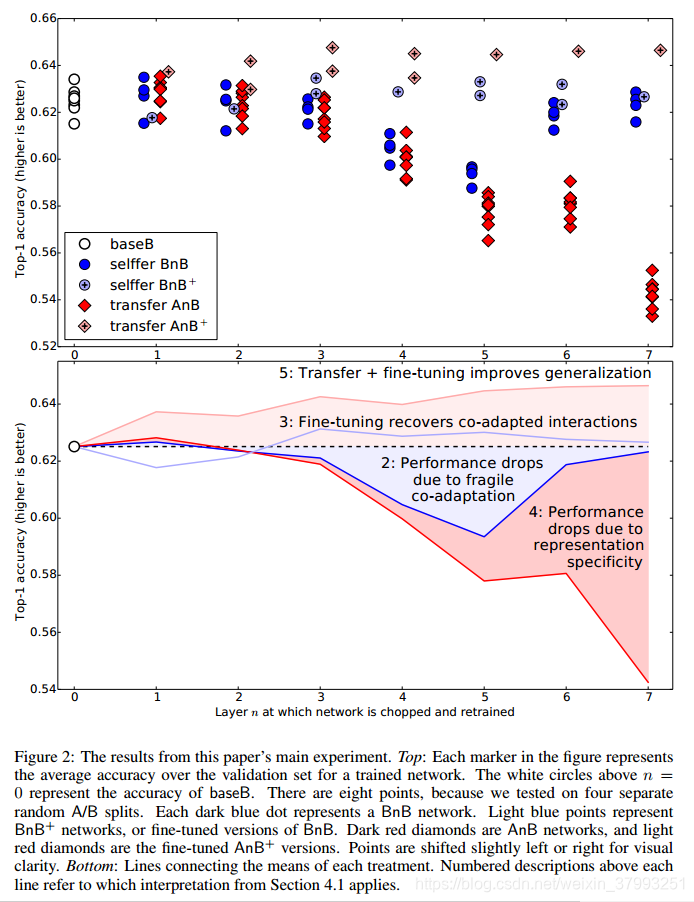
- 所有A/B迁移学习实验在随机分割(即相似)数据集上的结果如图2所示。这些结果得出了许多不同的结论。在下面的每一种解释中,我们都将性能与基本情况进行比较(图2中的白色圆圈和虚线)。
- 白色的baseB圆圈表示,训练有素的网络对500个类的随机子集进行分类,其最高1级精度为0.625,即37.5%的错误。该误差小于1000级网络的42.5%的前1位误差。虽然错误可能更高,因为网络只训练了一半的数据,这可能导致更多的过度拟合,但最终的结果是错误更低,因为只有500个类,所以出错的方法只有一半。
- 深蓝色泡泡堂点表现出一种奇特的行为。正如预期的那样,第一层的性能与baseB点相同。也就是说,如果我们学习了八层特性,保存第一层已学习的Gabor特性和色块,重新初始化整个网络,并将其重新训练到相同的任务,它也会做得很好。这个结果同样适用于第2层。然而,第3层、第4层、第5层和第6层,尤其是第4层和第5层,表现出更差的性能。这种性能下降证明了原始网络在连续层上包含脆弱的协同适应特性,即以复杂或脆弱的方式相互交互的特性,使得这种协同适应不能仅由上层重新学习。梯度下降法第一次就能找到一个很好的解,但这是可能的,因为层是联合训练的。到第6层时,性能几乎回到了基本水平,第7层也是如此。当我们越来越接近最后的、500路softmax输出层8时,需要重新学习的东西就越来越少了,显然,重新学习这一两层就足够简单,足以让梯度下降找到一个好的解决方案。换句话说,我们可以说层与层之间的特征相互适应较少。7和7与7之间;8 .比之前的图层之间。据我们所知,在以前的文献中还没有观察到这样的优化困难可能在网络的中间比接近底部或顶部更糟。
- 淡蓝色泡泡堂+点表示,当复制低层特征时,也学习目标数据集(这里与基本数据集相同),性能与基本情况相似。这样的微调可以防止在BnB网络中观察到的性能下降。
- 暗红色的AnB钻石显示了我们首先要测量的效果:特征在每一层从一个网络到另一个网络的可迁移性。第1层和第2层几乎完美地从A迁移到B,这表明,至少对于这两个任务,第1层Gabor和color blob特性是通用的,第2层特性也是通用的。第三层的性能略有下降,而第4-7层的性能下降更为显著。多亏了BnB,我们可以看出这种下降是由两种不同效果的组合造成的:一种是来自于失去的协同适应,另一种是来自于越来越不通用的特性。在第3层、第4层和第5层上,第一个效应占主导地位,而在第6层和第7层上,第一个效应减弱,表现的特异性占主导地位,性能下降。虽然在其他文献中也有成功的特征迁移的例子(Girshick et al., 2013;Donahue et al ., 2013 b),据我们所知这些结果仅限于注意到从一个给定的层是比另一种更好的训练严格的目标任务,即注意到美点在某一层比从头培训所有层。我们认为,这是第一次(1)成功迁移的程度已经被仔细地逐层量化,(2)这两个独立的效应已经解耦,表明每个效应在一定程度上占主导地位
- 淡红色的AnB+菱形显示出一种特别令人惊讶的效果:传输特征并对其进行微调,得到的网络泛化效果比直接在目标数据集上训练的网络更好。以前,人们可能想要传输学习到的特性是为了在不过度拟合小目标数据集的情况下启用训练,但是这个新结果表明,即使目标数据集很大,传输特性也会提高泛化性能。注意,这种效果不应该归因于较长的总培训时间(AnB+的450k base iteration + 450k finetuned iteration vs. baseB的450k),因为BnB+网络的培训时间也同样较长,并且没有表现出相同的性能改进。因此,一个合理的解释是,即使经过450k次微调迭代(从完全随机的顶层开始),看到基本数据集的效果仍然存在,从而提高了泛化性能。令人惊讶的是,这种影响在如此多的再培训中仍然存在。这种泛化改进似乎不太依赖于我们保留多少第一个网络来初始化第二个网络:保留从1层到7层的任何位置都会提高性能,随着保留更多的层,性能会略有提高。第1层到第7层的平均增长是1.6%,如果我们保持至少5层的平均增长是2.1%。4性能提升程度如表1所示。
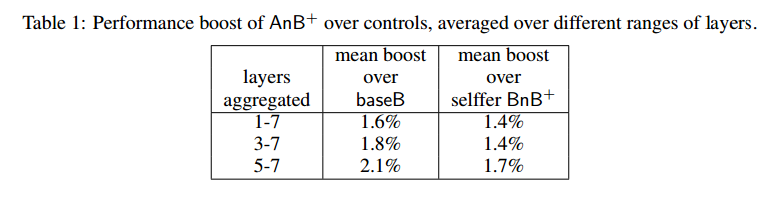
4.2 Dissimilar Datasets: Splitting Man-made and Natural Classes Into Separate Datasets
如前所述,随着基础任务和目标任务的相似性降低,特征迁移的有效性预计会下降。我们通过比较相似数据集(上面讨论的随机A/B分割)和不同数据集上的传输性能来测试这个假设,这些数据集是通过将人工对象类分配给A和自然对象类分配给B来创建的。
图3左上角的子图显示了baseA和baseB网络(白色圆圈)以及BnA和AnB网络(橙色六边形)的准确性。行连接常见的目标任务。这两行代码的上半部分包含了针对包含自然类别(baseB和AnB)的目标任务所训练的网络。这些网络比那些训练人为类别的网络表现得更好,这可能是因为只有449个类而不是551个类,或者仅仅是任务更简单,或者两者兼而有之。
4.3 Random Weights
我们还比较了随机的、未经训练的权重,因为Jarrett et al.(2009)相当惊人地显示,随机卷积滤波器、校正、池化和局部归一化的组合几乎可以像学习到的特性一样有效。他们在相对较小的两个或三个学习层的网络和较小的Caltech-101数据集中报告了这一结果(Fei-Fei et al., 2004)。人们很自然地会问,他们报告的近乎最优的随机过滤器性能,是否会传递到一个针对更大数据集训练的更深层次的网络。
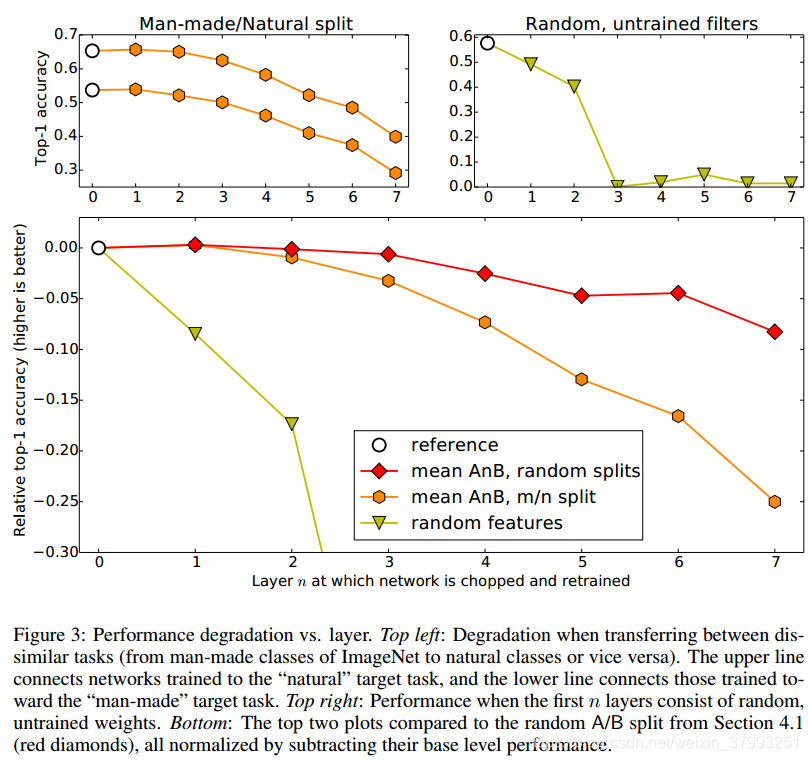
右上方的次要情节,图3显示了使用随机过滤器时精度获得第n层的各种选择。性能下降很快在层1和2中,然后滴near-chance水平层3 +,这表明获得随机权重在卷积神经网络工作可能不是一样直接使用的网络规模和小数据集Jarrett et al。(2009)。然而,这种比较并不简单。虽然我们的网络在第1层和第2层上具有最大池化和局部标准化,就像Jarrett et al.(2009)所做的那样,但是我们使用了不同的非线性(relu(x)而不是abs(tanh(x)),不同的层大小和层数,以及其他差异。此外,他们的实验只考虑了两层随机权重。我们的网络的超参数和体系结构选择共同提供了一个新的数据点,但是很有可能调整层大小和随机初始化细节,从而为随机权重提供更好的性能。
图3底部的子图显示了前两部分的实验结果,减去各自基本用例的性能。这些标准化的性能是在n个层之间绘制的,这些层要么是随机的,要么是在不同的基础数据集上训练的。这种比较使两件事显而易见。首先,当使用冻结特征时,不同任务(六边形)的可迁移性缺口比相似任务(菱形)的可迁移性缺口增长得更快,相似任务(六边形)的可迁移性缺口仅为8%,而不同任务(菱形)的可迁移性缺口为25%。其次,即使是从一个遥远的任务迁移,也比使用随机过滤器要好。后一种结果可能与Jarrett et al.(2009)不同的一个原因是,他们的完全训练(非随机)网络在较小的Caltech-101数据集上比我们在较大的ImageNet上拟合得更多,通过比较,使它们的随机过滤器执行得更好。在补充材料中,我们提供了一个额外的实验,表明我们的网络过度拟合的程度。
5 Conclusions
我们演示了一种量化神经网络各层特征的可迁移性的方法,揭示了它们的共性或特殊性。我们展示了可迁移性如何受到两个截然不同的问题的负面影响:在脆弱的共适应层中间进行网络分裂的优化困难,以及以牺牲目标任务的性能为代价将更高层次的特性专门化到原始任务。我们观察到,这两个问题中的一个可能占主导地位,这取决于特性是从网络的底部、中部还是顶部传输的。我们还量化了任务之间的可迁移性差距是如何随着任务之间距离的增大而增大的,尤其是在传输更高的层时,但是我们发现即使是来自遥远任务的特征传输也比随机权重要好。最后,我们发现,即使对新任务进行了大量的微调,使用传递的特征进行初始化也可以提高泛化性能,这对于提高深度神经网络性能是一种普遍有用的技术。

















 7615
7615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









