







原文链接:https://zhanghan.xyz/posts/1559/
深度网络的可迁移性
随着AlexNet在2012年的ImageNet大赛上获得冠军,深度学习开始在机器学习的研究和应用领域大放异彩。尽管取得了很好的结果,但是神经网络本身就像一个黑箱子,解释性不好。由于神经网络具有良好的层次结构,很自然地就有人开始关注,能否通过这些层次结构来很好地解释网络?
假设一个网络要识别人脸,那么一开始它只能检测到一些边边角角的东西,和人脸根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有人脸的区域,下图是一个简单的示例。
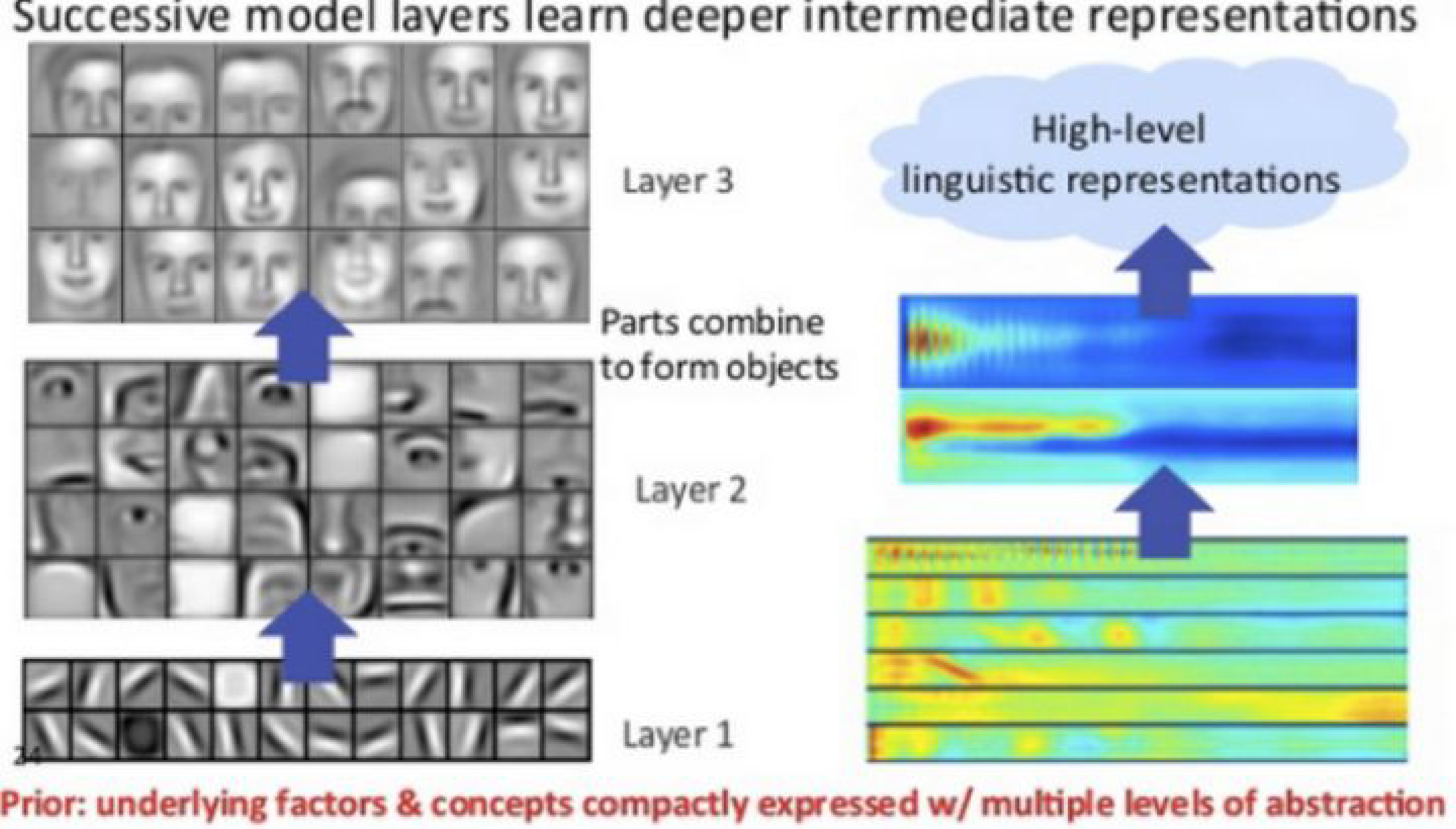
这表达了一个什么事实呢?概括来说就是:前面几层都学习到的是通用的特征(general feature);随着网络层次的加深,后面的网络更偏重于学习任务特定的特征(specific feature)。
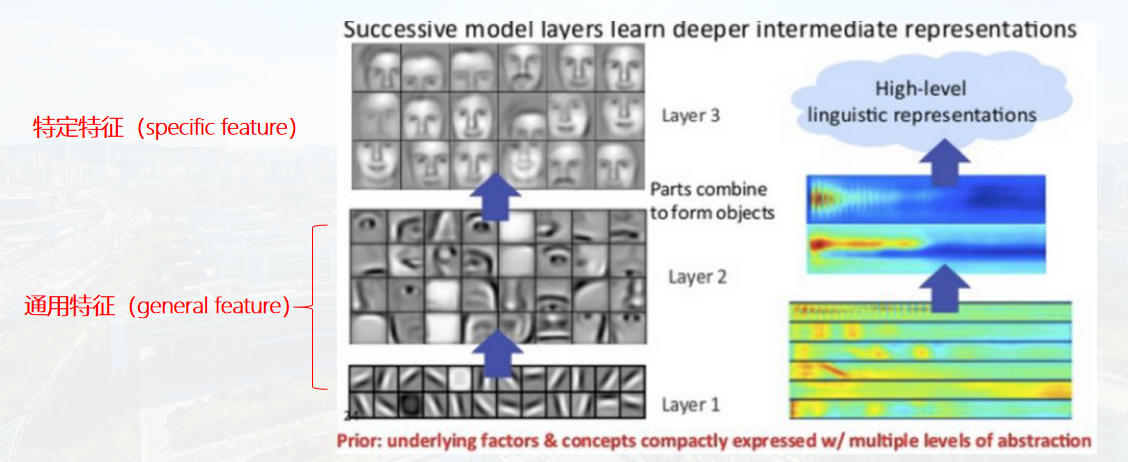
这非常好理解,我们也都很好接受。那么问题来了:如何得知哪些层能够学习到general feature,哪些层能够学习到specific feature。更进一步:如果应用于迁移学习,如何决定该迁移哪些层、固定哪些层?
一、研究问题

- 我们可以量化模型的某一层的特征到底是通用的还是具体的吗?
- 转换是在某一层上突然发生,还是在几层上展开?
- 这种转换发生在网络的什么地方:网络顶端,网络中间,还是网络底端?
二、方法简介
在ImageNet的1000类上,作者把1000类分成两份(A和B),每份500个类别。然后,分别对A和B基于Caffe训练了一个AlexNet网络。一个AlexNet网络一共有8层,除去第8层是类别相关的网络无法迁移以外,作者在1到7这7层上逐层进行finetune实验,探索网络的可迁移性。
文章进行了如下图所示的实验,总计有六种模型
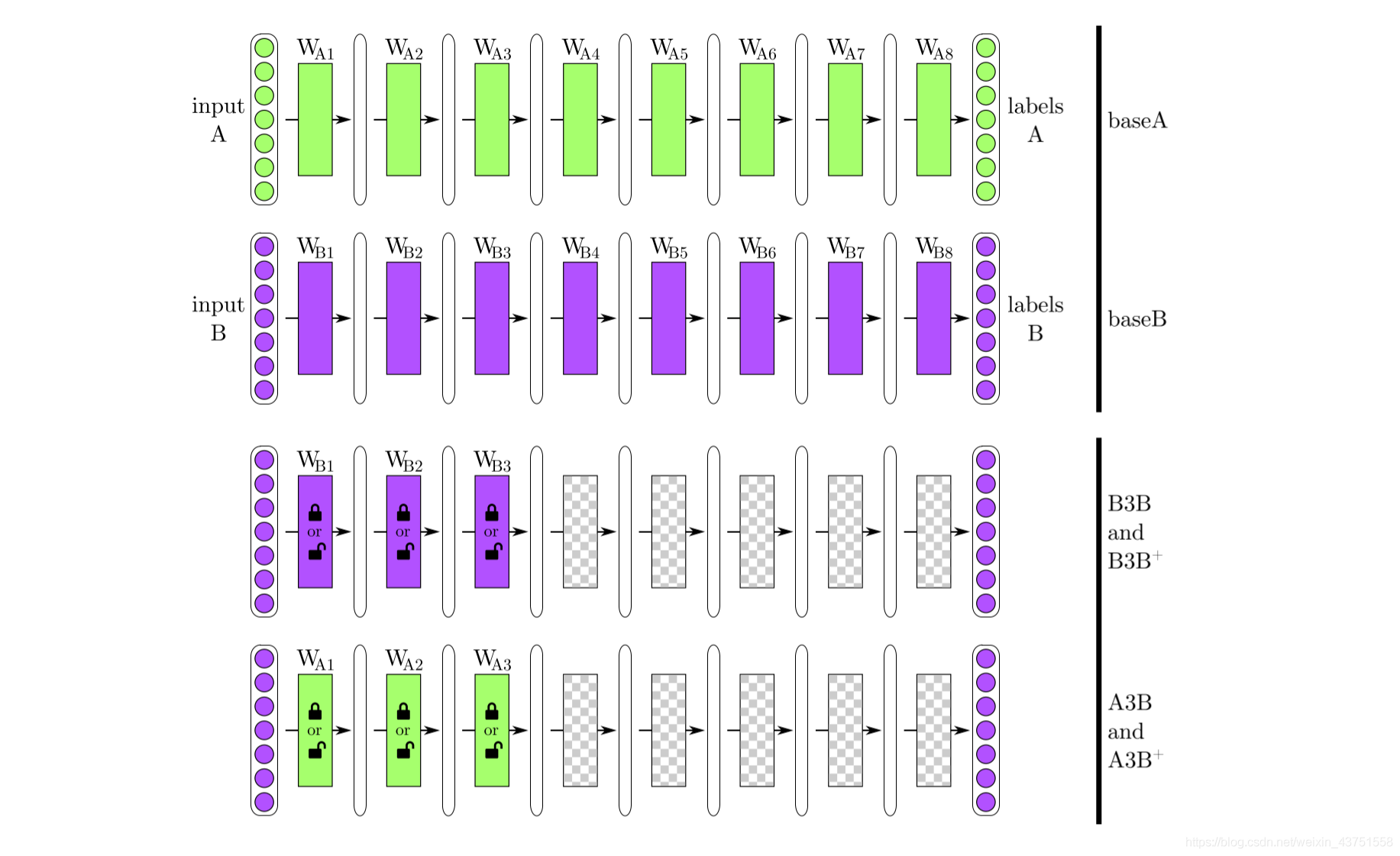
- A上的基本模型BaseA
- B上的基本模型BaseB
- BnB:把训练好的B网络的前
n
n
n层拿来并将它固定(
frozen),剩下的 8 − n 8-n 8−n层随机初始化,然后对B进行分类 - AnB:将A网络的前
n
n
n层拿来并将它固定(
frozen),剩下的 8 − n 8-n 8−n层随机初始化,然后对B进行分类。 - BnB+:类似于BnB,但是不固定前n层,对前n层进行微调(·
fine-tuning) - AnB+:类似于AnB,但是不固定前n层,对前n层进行微调(·
fine-tuning)‘
三、实验与评估
1.数据集被随机划分为A和B,这时两个子数据集的分布相似
实验结果如下图所示:

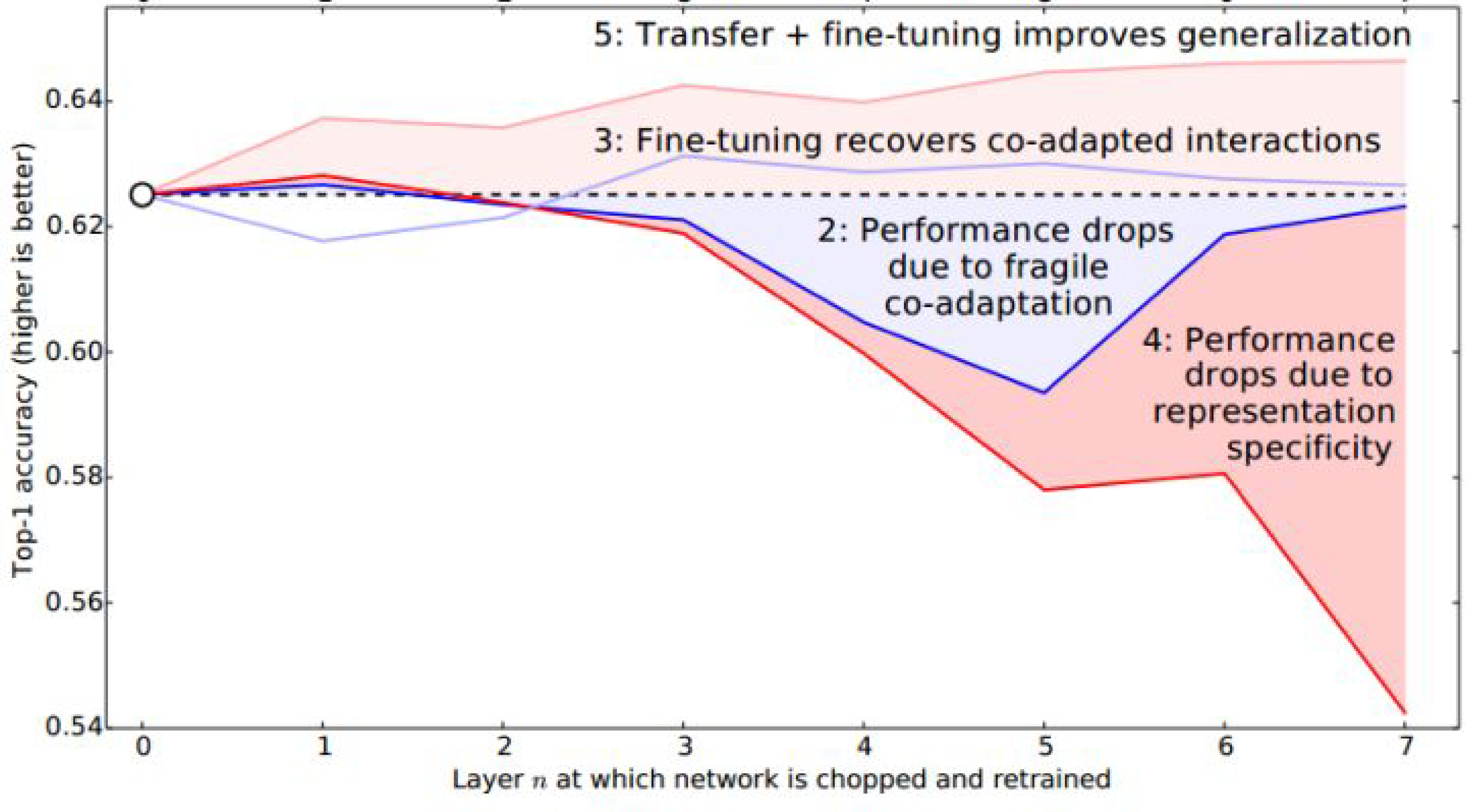
- 白色圆圈baseB表明,神经网络经过训练,对500个类别进行分类,top1的准确率0.625(37.5%的错误率)。
- 对BnB而言,原训练好的B模型的前3层直接拿来就可以用而不会对模型精度有什么损失。到了第4和第5层,精度略有下降,不过还是可以接受。然而到了第6层、第7层,精度居然回升了,原因如下:对于一开始精度下降的第4第5层来说,确实是到了这一步,
feature变得越来越specific,所以下降了。那对于第6第7层为什么精度又不变了?那是因为,整个网络就8层,我们固定了第6第7层,这个网络还能学什么呢?所以很自然地,精度和原来的B网络几乎一致。 - 浅蓝色圆圈BnB+表明,微调复制过来的参数可以防止在BnB网络中观察到的性能下降。
- 对AnB来说,直接将A网络的前3层迁移到B,貌似不会有什么影响,再一次说明,网络的前3层学到的几乎都是
general feature。往后,到了第4第5层的时候,精度开始下降,我们直接说:一定是feature不general了然而,到了第6第7层,精度出现了小小的提升后又下降,原因作者在这里提出两点:co-adaptation和feature representation。就是说,第4第5层精度下降的时候,主要是由于A和B两个数据集的差异比较大,所以会下降;到了第6第7层,由于网络几乎不迭代了,学习能力太差,此时feature学不到,所以精度下降得更厉害。 - 再看AnB+。加入了
finetune以后,AnB+的表现对于所有的 n n n几乎都非常好,甚至比baseB(最初的B)还要好一些,这说明:finetune对于深度迁移有着非常好的促进作用。效果的优异源自于:数据A和B的相似度很高,此实验相当于接触了更多的训练数据,基础数据集的效果仍然存在,因此更加优异。
把上面的结果合并就得到了下面一张图:
2.数据集被分为人工图像集和自然图像集,这时两个子数据集分布差异很大(采用随机权重)
AnB和BnB基本完成。作者又想,是不是我分A和B数据的时候,里面存在一些比较相似的类使结果好了?比如说A里有猫,B里有狮子,所以结果会好?为了排除这些影响,作者又分了一下数据集,文章在ImageNet中创建两个不相似的数据集A(人造对象类)和B(自然对象类),这次使得A和B里几乎没有相似的类别。在这个条件下再做AnB。
下图的左上方子图显示了baseA和baseB网络(白色圆圈)和BnA和AnB网络(橙色六边形)的准确性。
下图的右上子图显示了随机初始化前n层(n=1,2,…,7)的卷积核参数后,获得的精度。
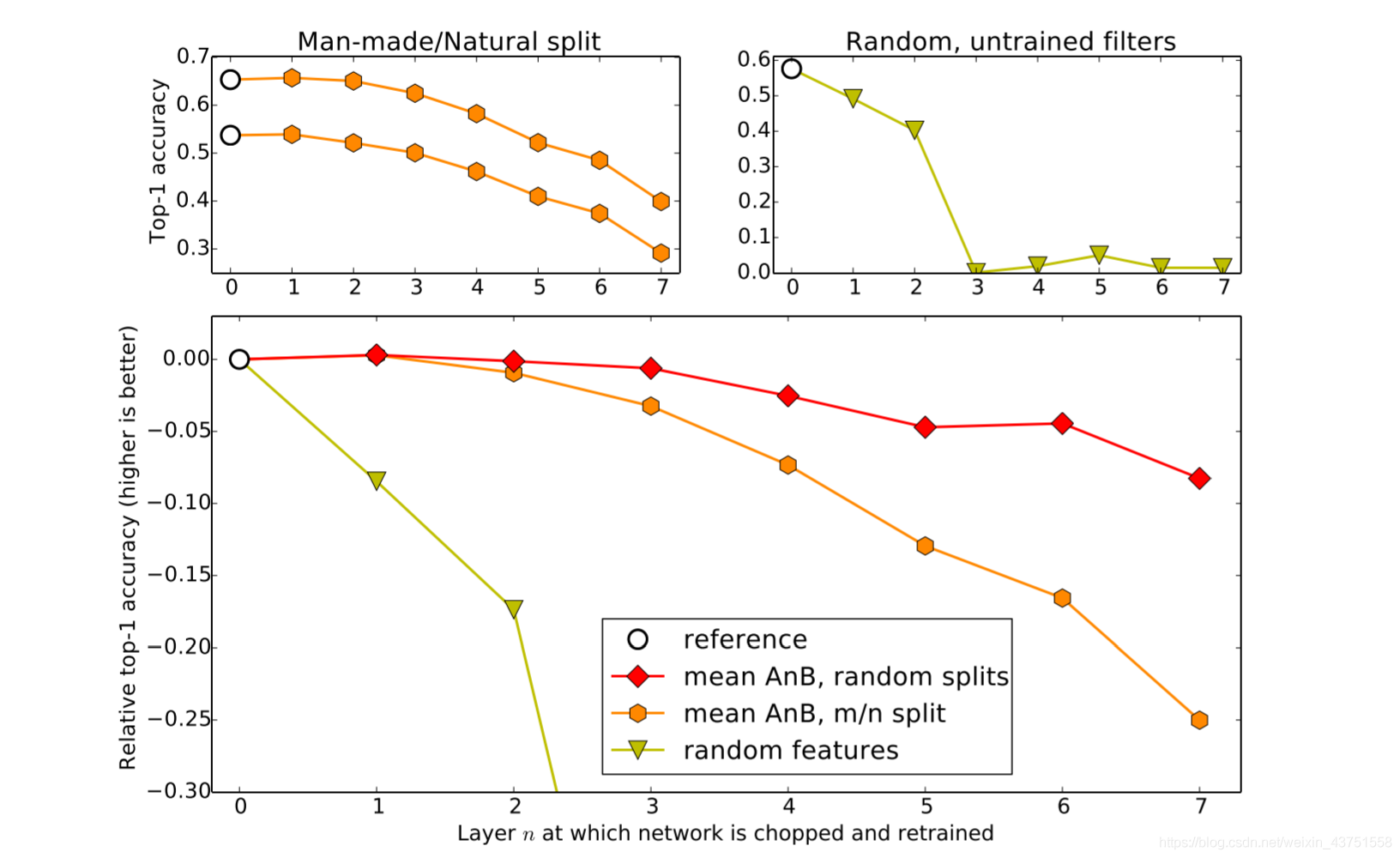
这个图说明了什么呢?简单:随着可迁移层数的增加,模型性能下降。但是,前3层仍然还是可以迁移的!同时,与随机初始化所有权重比较,迁移学习的精度是很高的。
总结
虽然该论文并没有提出一个创新方法,但是通过实验得到了以下几个结论,对以后的深度学习和深度迁移学习都有着非常高的指导意义:
- 神经网络的前3层基本都是general feature,进行迁移的效果会比较好;
- 深度迁移网络中加入fine-tune,效果会提升比较大,可能会比原网络效果还好;
- Fine-tune可以比较好地克服数据之间的差异性;
- 深度迁移网络要比随机初始化权重效果好;
- 网络层数的迁移可以加速网络的学习和优化。
















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











