







 本文详细介绍了ConcurrentHashMap的实现原理,包括其分段锁技术、三次哈希定位策略,以及初始化过程。文中还提及了put、get、size等操作的内部逻辑,并讨论了哈希质量对性能的影响,强调了使用时的注意事项,如键值不可为null。
本文详细介绍了ConcurrentHashMap的实现原理,包括其分段锁技术、三次哈希定位策略,以及初始化过程。文中还提及了put、get、size等操作的内部逻辑,并讨论了哈希质量对性能的影响,强调了使用时的注意事项,如键值不可为null。
实现原理
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
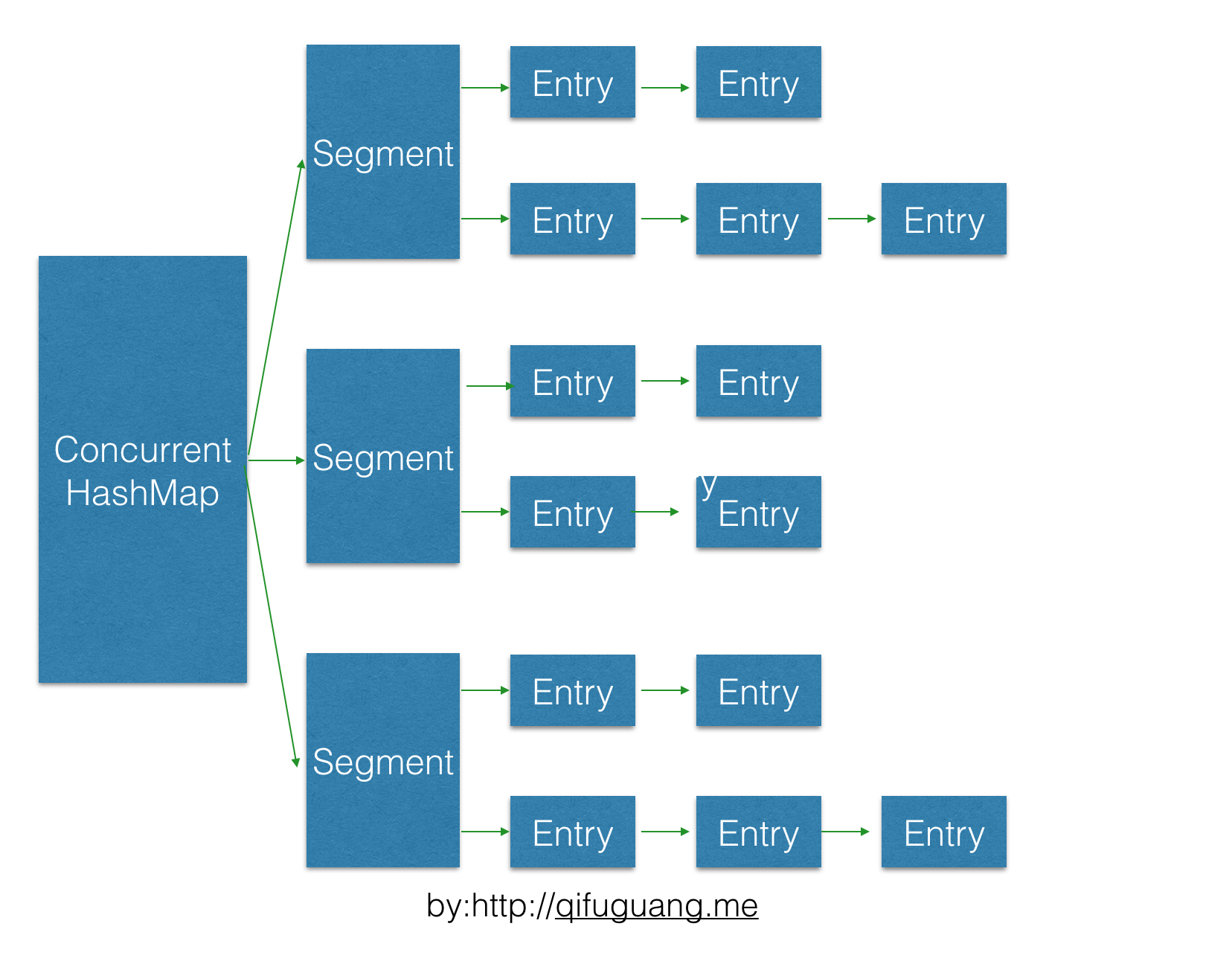
从图中可以看到,ConcurrentHashMap内部分为很多个Segment,每一个Segment拥有一把锁,然后每个Segment(继承ReentrantLock)下面包含很多个HashEntry列表数组。对于一个key,需要经过三次(为什么要hash三次下文会详细讲解)hash操作,才能最终定位这个元素的位置,这三次hash分别为:
- 对于一个key,先进行一次hash操作,得到hash值h1,也即h1 = hash1(key);
- 将得到的h1的高几位进行第二次hash,得到hash值h2,也即h2 = hash2(h1高几位),通过h2能够确定该元素的放在哪个Segment;
- 将得到的h1进行第三次hash,得到hash值h3,也即h3 = hash3(h1),通过h3能够确定该元素放置在哪个HashEntry。
初始化
构造函数的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; // create segments and segments[0] Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; } |
传入的参数有initialCapacity,loadFactor,conc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











