







目录
5.switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String上?
6.如何取得从 1970 年 1 月 1 日 0 时 0 分 0 秒到现在的毫秒数?
1.静态内部类加载案例
public class Oauth {
static class Inner {
static long param1 = 6;
static final long param2 = 6;
static final long param3 = new Long(6);
}
public static void main(String[] args) {
System.out.println(Oauth.Inner.param1);
System.out.println(Oauth.Inner.param2);
System.out.println(Oauth.Inner.param3);
}
}结果是输出6,6,6.
考察点:是否了解类加载机制在处理类内部类时的处理方式,虚拟机当加载静态内部类时如果是确定的属性值时,虚拟机会直接将值存放到元存储中(静态方法区),其他未确定值需要在运行时动态计算,由虚拟机分配地址和值。如果设置的值不是static,那么不能直接访问,因为此时值属于对象而不是类。
| 类 | 对象 | |
|---|---|---|
| 抽象和具体 | 抽象 | 具体 |
| 状态 | 静态(属性和方法适用于本类的所有对象) | 动态(属性随着方法而变化) |
| 使用 | 不能直接使用 | 可直接使用 |
2.堆栈数据赋值
public static void main(String[] args) {
int j = 0;
for (int i = 0; i < 3; i++) {
j = j++;
}
System.out.println(j);
}JVM里面有两个存储区,一个是暂存区(堆栈),另一个是变量区。j=j++是先将j的值0存入堆栈中,然后对变量区中j自加1,这时j的值确实是1,但随后将堆栈中的值赋给变量区的j,所以最后j=0; 而j=++j,是先对变量区中的j加1,再将变量区中的j值(1)存入堆栈,最后将堆栈中的值赋给自变量区的j,所以j=1;
3.基本类型数组和引用类型数组转list
int[] inArray = new int[]{1, 2, 3};
List list = Arrays.asList(inArray);
System.out.println(list.size() + " * " + list.get(0));结果:1 * 1
考察基本类型数组和引用类型数组,基本数据类型数组在转换为列表时,如果直接传递数组,基本类型数组将被视为一个对象而不会被解析成数组,如果直接传递参数将能正常解析。
4.理解equals
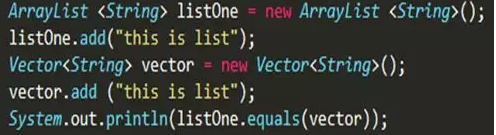
答案:true 两个类型都重写了equals方法,比较了内容和元素长度,并未对类型进行首要比对。
5.switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String上?
视JDK版本而定:支持byte,1.7(含)以后支持string,但是不支持long。
6.如何取得从 1970 年 1 月 1 日 0 时 0 分 0 秒到现在的毫秒数?
- System.currentTimeMillis()
- new Date().getTime()
- Calendar.getInstance().getTimeInMillis()
7.获取java类字节码的方法
- Class.class
- object.getClass()
- 通过反射实现
Class<Oauth> oauthClass = null;
try {
oauthClass = (Class<Oauth>) Class.forName("com.test.Oauth");
System.out.println(oauthClass);
} catch (ClassNotFoundException e) {
}8.堆(heap)和栈(stack)的区别、JVM内存
/** 在Java代码中,常常会使用到这样的类的声明实例化: */
Person per = new Person();
//这其实是包含了两个步骤,声明和实例化
Person per = null; //声明一个名为Person类的对象per 声明 指的是创建类的对象的过程;
per = new Person(); // 实例化这个per对象 实例化 指的是用关键词new来开辟内存空间。
//它们在内存中的划分如下: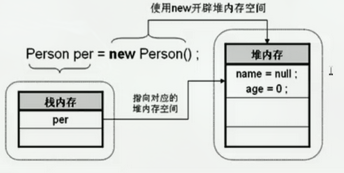
栈内存:
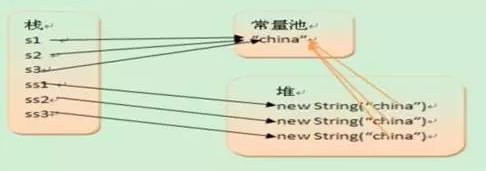
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。栈内存主要存放的是基本类型类型的数据 如( int, short, long, byte, float, double, boolean, char) 和对象句柄。注意:并没有String基本类型、在栈内存的数据的大小及生存周期是必须确定的、其优点是寄存速度快、栈数据可以共享、缺点是数据固定、不够灵活。
栈的共享:
String str1 = "myString";
String str2 = "myString";
System.out.println(str1 == str2);//true 两个引用都指向了同一个对象时==号才返回真值
System.out.println(str1.equals(str2));//true 比较两个字符串是否相等
// 原理:首先在栈中创建一个变量为str1的引用,然后查找栈中是否有myString这个值,如果没找到,
// 就将myString存放进来,然后将str1指向myString。接着处理String str2 = "myString";
// 在创建完str2 的引用变量后,因为在栈中已经有myString这个值,便将str2 直接指向myString。
// 这样,就出现了str1与str2 同时指向myString。
堆内存:
堆内存用来存放所有new 创建的对象和 数组的数据
String str1 = new String ("myString");
String str2 = "myString";
System.out.println(str1 ==str2 ); //false
// 创建了两个引用,创建了两个对象。两个引用分别指向不同的两个对象。
// 以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建。
// 而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。补充:
- 基础数据类型:直接在栈空间分配, 方法的形式参数,直接在栈空间分配,当方法调用完成后从栈空间回收。
- 引用数据类型:需要用new来创建,既在栈空间分配一个地址空间,又在堆空间分配对象的类变量 。
- 方法的引用参数,在栈空间分配一个地址空间,并指向堆空间的对象区,当方法调用完成后从栈空间回收。
- 局部变量:new 出来时,在栈空间和堆空间中分配空间,当局部变量生命周期结束后,栈空间立刻被回收,堆空间区域等待GC回收。
- 常量(literal ):方法调用时传入的 literal 参数,先在栈空间分配,在方法调用完成后从栈空间分配。
- 字符串常量:在 DATA 区域分配 ,this 在堆空间分配 。
- 数组:既在栈空间分配数组名称, 又在堆空间分配数组实际的大小!
- static:在DATA区域分配。
堆栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。
每一个Java应用都唯一对应一个JVM实例,每一个实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或数组都放在这个堆中,并由应用所有的线程共享,Java中分配堆内存是自动初始化的。Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,也就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
JAVA的JVM的内存可分为3个区:堆(heap)、栈(stack)和方法区(method)
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
方法区:
1.又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
public class HeapStack { //运行时, jvm 把HeapStack的信息都放入方法区
public void main(String[] args) {//main 方法本身放入方法区。
Sample test1 = new Sample("你想"); //test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
test1.printName();
}
public class Sample { //运行时, jvm 把appmain的信息都放入方法区
private String name; //new Sample实例后, name 引用放入栈区里, name 对象放入堆里
public Sample(String name) {
this.name = name;
}
public void printName() //print方法本身放入 方法区里。
{
System.out.println(name);
}
}
}
// 系统收到指令,启动了一个Java虚拟机进程,这个进程首先从classpath中找到HeapStack.class文件,读取这个文件中的二进制数据
// 然后把Appmain类的类信息存放到运行时数据区的方法区中。这一过程称为AppMain类的加载过程。
// 接着,Java虚拟机定位到方法区中HeapStack类的Main()方法的字节码,开始执行它的指令。
// Sample test1 = new Sample("你想");
// java虚拟机创建一个Sample实例,并且呢,使引用变量test1引用这个实例。
// 1.找到Sample类的类型信息:最初方法区内无Sample类的类型信息,虚拟机找不到Sample类就加载Sample类的类型信息存放到方法区
// 2.在堆区中为一个新的Sample实例分配内存, 这个Sample实例持有着指向方法区的Sample类的类型信息的引用。
// 这里所说的引用,实际上指的是Sample类的类型信息在方法区中的内存地址,而这个地址呢,就存放了在Sample实例的数据区里。
// 3.在JAVA虚拟机进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素就被称
// 为栈帧,每当线程调用一个方法的时候就会向方法栈压入一个新帧。帧用来存储方法的参数、局部变量和运算过程中的临时数据。
// Test1是一个局部变量,指向堆区中的Sample实例,即它持有指向Sample实例的引用。
// 执行test1.printName()方法时,JAVA虚拟机根据局部变量test1持有的引用,定位到堆区中的Sample实例,再根据Sample实例持有
// 的引用,定位到方法去中Sample类的类型信息,从而获得printName()方法的字节码,接着执行printName()方法包含的指令。
9.聊聊HTTP/1.1 与 HTTP/1.0 的区别

10.POST方法和GET方法区别
两者在与服务端发生交互时有所不同,POST方法会请求服务端两次,第一次先发送头部进行确认,服务端返回成功后再次发送数据,而GET只需要请求服务端一次。同时强调一下GET方法中http协议并未做参数长度限制,只是不同浏览器和服务端做了限制而已。
11.Java中的对象、实例、句柄、直接指针的理解
虚拟机在创建对象的时候,会优先查询常量池中是否有该对象的实例,如果没有则需要加载、解析、初始化class,然后分配内存,初始化内存,设置对象(HASH CODE 、 GC年代等),最后执行init才算是创建完对象。
对象即实例。
String str;
以上的str就是一个句柄,但是并没有指向任何对象,好比这是一个客服中心,告诉你打400号码联系客服中心,但是没有指明是哪个客服人员,如果String str = "9527";这个时候就是说明了编号9527为您服务,可以通过句柄访问对象。
直接指针,我理解的:
class Test{
public void doSth();
}
new Test().doSth();//直接指针
Test() test = new Test();//句柄引用
test.doSth();
当然直接指针肯定是速度更快的,但是如果用句柄,对象被移动(比如GC),只需要改变指针而不会改变引用;如果是直接指针的方式,速度那是杠杠的,不用多余的一次指针的定位。综上,写JVM多用直接指针,写应用更多的是句柄。
原文:https://blog.csdn.net/CUG_ZG/article/details/79411591















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









