







It’s Written All Over Your Face:Full-Face Appearance-Based Gaze Estimation论文翻译
1.摘要
眼睛注视是人类情感分析的重要非语言线索。 最近的注视估计工作表明,来自全脸区域的信息可以提高性能。 进一步推动这一想法,我们提出了一种基于外观的方法,与计算机视觉领域的长期工作相比,该方法仅将全脸图像作为输入。 我们的方法使用卷积神经网络对面部图像进行编码,空间权重应用于特征图,以灵活地抑制或增强不同面部区域的信息。 通过广泛的评估,我们表明我们的全脸方法在 2D 和 3D 凝视估计方面显着优于最先进的方法,在 MPIIGaze 上实现了高达 14.3% 的改进,在与人无关的 3D 凝视估计上实现了 27.7% 的 EYEDIAP 改进。 我们进一步表明,这种改进在不同的照明条件和凝视方向上是一致的,对于最具挑战性的极端头部姿势尤其明显。
1、介绍
鉴于人机交互 [21]、情感计算 [4] 和社会信号处理 [30] 等不同应用的重要性,计算机视觉领域的大量作品研究了估计人眼凝视 [7] 的问题。 .虽然早期的方法通常需要可以控制照明条件或头部姿势的设置 [17、22、27、31],但使用卷积神经网络 (CNN) 的最新基于外观的方法为日常环境中的注视估计铺平了道路以大量的照明和外观变化为特征[36]。尽管有这些进步,以前基于外观的方法只使用从一只或两只眼睛编码的图像信息。
Krafka 等人的最新结果。表明将眼睛和面部图像作为输入的多区域 CNN 架构可以有益于凝视估计性能 [13]。虽然直观上,人类注视与眼球姿势密切相关,因此眼睛图像应该足以估计注视方向,但确实可以想象,特别是基于机器学习的方法可以利用来自其他面部区域的附加信息。例如,这些区域可以在比眼睛区域可用的图像区域更大的图像区域上对头部姿势或照明特定信息进行编码。然而,(更有效和优雅的)仅面部方法是否可行,哪些面部区域对于这种基于全脸外观的方法最重要,以及当前的深层架构是否可以将信息编码在这些地区。此外,[13] 中的视线估计任务仅限于简单的 2D 屏幕映射,因此全脸方法用于 3D 视线估计的潜力仍不清楚。
这项工作的目标是通过对基于 2D 和 3D 外观的注视估计的全脸方法的潜力进行详细分析来阐明这些问题(见图 1)。这项工作的具体贡献有两个方面。首先,我们提出了一种用于凝视估计的全脸 CNN 架构,与凝视估计的长期传统形成鲜明对比,它将全脸图像作为输入并直接回归到 2D 或 3D 凝视估计。我们将我们的全脸方法与现有的仅眼睛 [36] 和多区域 [13] 方法进行定量比较,并表明它可以在具有挑战性的 MPIIGaze 数据集上实现 4.8° 的独立于人的 3D 凝视估计精度,从而提高比现有技术高 14.3%。其次,我们提出了一种空间权重机制,以将有关全脸不同区域的信息有效地编码到标准的 CNN 架构中。该机制在卷积层的激活图上学习空间权重,反映不同面部区域中包含的信息 [[...]] 通过进一步的定量和定性评估,我们表明所提出的空间权重网络有助于学习估计器对当前数据集中可用的照明条件以及头部姿势和注视方向的显着变化具有鲁棒性。
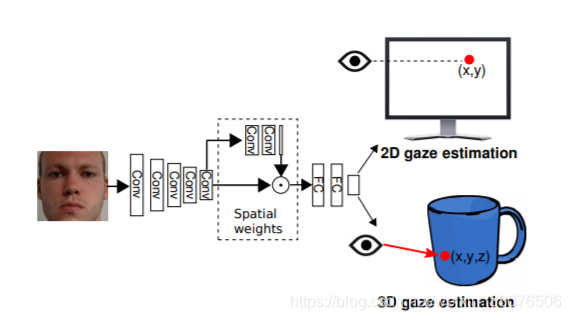
图 1:建议的基于全脸外观的凝视估计管道的概述。 我们的方法仅将人脸图像作为输入,并使用卷积神经网络对特征图应用空间权重来执行 2D 和 3D 凝视估计。
2、先关工作
我们的工作与之前针对 2D 和 3D 凝视估计任务的基于外观的凝视估计有关,特别是最近的多区域方法,以及在 CNN 中编码空间信息的方法。
Appearance-Based Gaze Estimation:注视估计方法通常分为基于模型或基于外观。虽然基于模型的方法使用眼睛和面部的几何模型来估计注视方向 [3, 29, 34],但基于外观的方法直接从眼睛图像回归到注视方向。早期的基于外观的方法假设每个用户都有固定的头部姿势和训练数据 [2, 27, 31]。后来的工作侧重于从单眼 RGB [16, 26] 或深度图像 [5] 进行的与姿势无关的注视估计,但仍需要针对个人的训练。实现姿势和个人独立的一个有希望的方向是基于学习的方法,但这些方法需要大量标记的训练数据 [13、20、25、36]。
因此,近年来在日常环境中收集的凝视估计数据集越来越多 [9, 19, 24],包括一些大规模 [13, 36],或由合成数据组成 [25, 32, 33]。在这项工作中,我们还使用留一人交叉验证方案专注于这一最具挑战性的姿势和个人独立凝视估计任务。
2D vs. 3D Gaze Estimation :基于外观的凝视估计方法可以根据回归目标是 2D 还是 3D 进一步分类。 早期的工作假设目标人的头部姿势是固定的 [2, 27, 29, 31],因此专注于 2D 凝视估计任务,其中训练估计器以输出屏幕上的凝视位置。 虽然最近的方法使用 3D 头部姿势 [18, 26] 或面部边界框 [13] 的大小和位置来允许头部自由移动,但它们仍将任务制定为直接映射到 2D 屏幕注视位置。 这些 2D 方法背后的基本假设是目标屏幕平面在相机坐标系中是固定的。 因此,它不允许在训练后自由移动相机,这可能是一个实际限制,尤其是对于基于学习的独立于人的估计器。
相比之下,在 3D 凝视估计中,估计器被训练为在相机坐标系中输出 3D 凝视方向 [5, 16, 18, 20, 33, 36]。 3D 公式与姿势和人无关的训练方法密切相关,最重要的技术挑战是如何在不需要太多训练数据的情况下有效地训练估计器。 为了促进模型训练,Sugano 等人。 提出了一种数据归一化技术,将外观变化限制在一个单一的、归一化的训练空间中 [25]。 虽然它需要额外的技术组件,例如 3D 头部姿势估计,但 3D 方法具有技术优势,因为它们可以估计任何目标对象和相机设置的注视位置。 由于这两种方法处理几何信息的方式不同,因此 2D 和 3D 方法之间全脸输入的作用也可能不同。
多区域注视估计: 尽管有这些进步,但以前的大多数工作都使用单眼图像作为回归
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4104
4104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









