







自动文档摘要评价方法大致分为两类:
(1)内部评价方法:提供参考摘要,以参考摘要为基准评价系统摘要的质量。系统摘要与参考摘要越吻合,质量越高。
(2)外部评价方法:不提供参考摘要,利用文档摘要代替原文档执行某个文档相关的应用。例如:文档检索、文档分类等,能够提高应用性能的摘要被认为是质量好的摘要。
下面介绍两种比较简单的,经常用到的内部评价方法:
Edmundson:
适于抽取式文本摘要,比较机械文摘(自动文摘系统得到的文摘)与目标文摘(从原文中抽取的句子)的句子重合率的高低对系统摘要进行评价。
计算公式:
重合率p = 匹配句子数/专家文摘句子数*100%
每一个机械文摘的重合率为按三个专家给出的文摘得到的重合率的平均值:
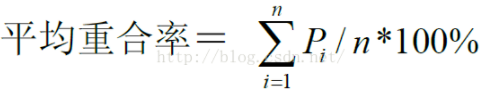
其中,pi为相对于第i个专家的重合率,n为专家文摘总数。
ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)基于摘要中n-gram的共现信息评价摘要,是一种面向n元词召回率的评价方法。

其中,Ref summaries表示标准摘要,count_match(n-gram)表示生成摘要和标准摘要中同时出现n-gram的个数,count(n-gram)表示参考摘要中出现的n-gram个数。
下图是ROUGE-L的公式,其中LCS(X,Y)是X和Y的最长公共子序列的长度,m和n分别表示人工标准摘要和机器自动摘要的长度,R_lcs和P_lcs分别表示召回率和准确率。F_lcs就是Rouge-L。最长公共子序列的一个优点是它不需要连续匹配,而且反映了句子级词序的顺序匹配。由于它自动包含最长的顺序通用n-gram,因此不需要预定义n-gram的长度。


法研杯2020年司法摘要的评估方式:

参考博客——https://blog.csdn.net/u012871493/article/details/52985307
https://blog.csdn.net/lime1991/article/details/42521029----ROUGE评价方法详解(一)
https://blog.csdn.net/lime1991/article/details/42613305----ROUGE评价方法详解(二)
后两个链接对ROUGE方法介绍的很详细,包括ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-S,并且都有示例。















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









