






参考博客:https://blog.csdn.net/auto1993/article/details/78514071
为什么需要RoI Pooling?
答:在FAST R-CNN中,特征被共享卷积层一次性提取,因此对于每个roi而言,需要从共享卷积层上摘取对应的特征,并且送入全连接层进行分类。因此,ROI Pooling做2件事
task 1: 为每个roi选取对应的特征,
task 2: 满足全连接层的输入需求,将每个roi对应的特征的维度转化为某个定值,
具体操作如下:
1.根据输入image, 将ROI映射到feature map对应位置;
2. 将映射后的区域划分成相同大小的settions(这个的具体值由后面的全连接层决定)
3. 对每个sections进行max pooling操作
例子:
假设我们有一个8x8的feature map, 一个ROI=[0,3,7,8],以及FPN要求的输出维度为mxn=2*2
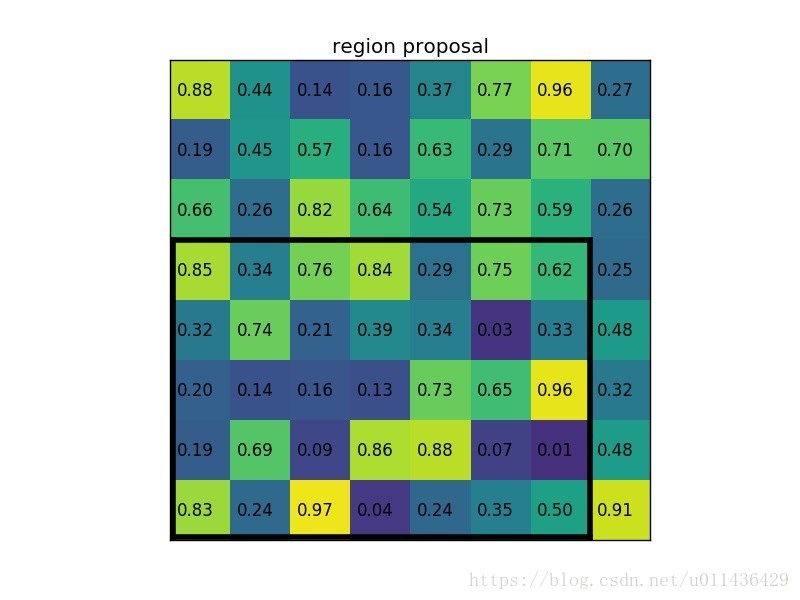
step 1: 将其划分为mxm=2x2=4个sections,
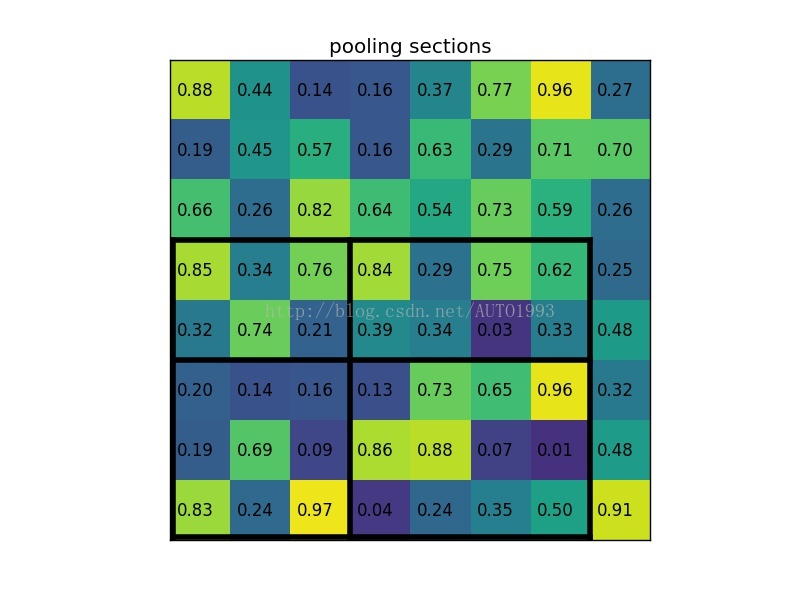
注意:这个例子中region proposal 即roi是5x7大小的,在pooling之后需要得到2x2的,所以5x7的特征图划分成2x2的时候不是等分的,行是5//2=2(这里是整除//,即普通除法得到的商向下取整5/2=2.5=2), 第一行得到 2,剩下的哪一行是3,列是7//2=3,第一列得到3,剩下一列是4
step 2: 对每个section做max pooling
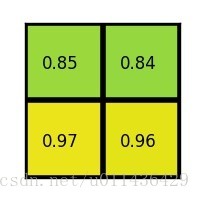
ROI Pooling 就是将大小不同的feature map池化成大小相同的feature map, 利于输出到下一层网络中
存在的问题:
step 1: 比如原来的输入图像为800*800, 经过卷积层(stride=32,表示网络层后图片缩小为原图的1/32)提取特征后,feature map 25*25
step 2:假设原图中有一个proposal 665*665, 映射到feature map的大小为 665/32=20.79取整后为20,即映射的特征图为20*20,
step 3: 假定池化层后固定为7*7大小,所以上面的proposal经过池化层后,变成了20//7=2,即变成了2*2
可以看出,上面的取整操作,会造成实际proposal(665*665)在特征图 上的位置与大小(2*2)的偏差,这样的像素偏差势必会对后面的回归定位产生影响,所以产生了替代方案ROIAlign
针对上述缺陷,mask rcnn给出了改进
step 1: 比如原来的输入图像为800*800, 经过卷积层(stride=32,表示网络层后图片缩小为原图的1/32)提取特征后,feature map 25*25
step 2:假设原图中有一个proposal 665*665, 映射到feature map的大小为 665/32=20.79*20.79,此时没有进行取整操作,四舍五入保留浮点数
step 3: 假定池化层后固定为7*7大小,所以上面的proposal经过池化层后,变成了20.79/7=2.97,即变成了2.97*2.97
step 4:假设采样点数为4,即表示对于每一个2.97*2.97的小区域,平分成4份,每一份取其中心点位置的像素,采用双线性插值法进行计算,这样,就得到4个点的像素值,
上图中,四个红色叉叉的像素值是通过双线性插值算法计算得到的,最后取四个像素值中最大值作为这个小区域即2.97*2.97的像素值。
总结:知道了ROIPooling 和ROIAlign的实现原理,在以后的项目中可以根据实际情况进行方案的选择,对于检测图片中大目标物体时,两种方案的差别不大,而如果是图片中有较多小目标物体需要检测,则优先选择ROIAlign更精准些















 4423
4423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









