







1、numpy与pandas区别
numpy是一个序列化好了的矩阵
pandas是一个字典化的numpy
2、pandas里面none就是nan
>>> import pandas as pd
>>> import numpy as np
>>> s = pd.Series([1,3,6,np.nan,44,1])
>>> s
0 1.0
1 3.0
2 6.0
3 NaN # 空
4 44.0
5 1.0
dtype: float64 #一般都是float64或者32
3、
>>> import pandas as pd
>>> import numpy as np
>>>> dates = pd.date_range('20160101',periods = 6)
>>> dates
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06'],
dtype='datetime64[ns]', freq='D')
>>> df = pd.DataFrame(np.random.randn(6,4),index = dates,columns = ['a','b','c','d']) #abcd是列名,随机生成6乘以4的矩阵,行是日期
>>> df
a b c d
2016-01-01 -0.249836 0.326775 0.221440 0.515402
2016-01-02 -0.113198 0.450847 -0.509338 -1.502132
2016-01-03 -0.034948 -0.223488 1.539594 0.155080
2016-01-04 0.552702 -0.303256 1.043668 0.272115
2016-01-05 -0.598486 0.313268 -0.117625 0.687375
2016-01-06 0.418921 0.057993 0.356467 -0.596935
如果没有给定后面的列和行名字,它会默认排0123这样。。接上一步操作:
>>> df1 = pd.DataFrame(np.random.randn(6,4))
>>> df1
0 1 2 3
0 1.398953 -1.239749 -1.823533 -0.439629
1 -0.663234 0.278977 -1.131152 0.543379
2 1.341353 -1.759974 0.012863 -1.706253
3 -0.209165 0.034281 -0.678030 -0.196939
4 -0.023134 -2.522720 -0.031831 -0.922848
5 -1.105311 -2.237579 1.319545 0.156853
你还可以分别制定内容(用字典的形式定义每一行的内容):
>>> sddf2 = pd.DataFrame({'A':1.,'B':pd.Timestamp('20130101'),'C':pd.Series(1,index= list(range(4)),dtype = 'float32')})
>>> sddf2
A B C
0 1.0 2013-01-01 1.0
1 1.0 2013-01-01 1.0
2 1.0 2013-01-01 1.0
3 1.0 2013-01-01 1.0
>>>
查看每一列的类型:
>>> sddf2.dtypes
A float64
B datetime64[ns]
C float32
dtype: object
>>>
输出列名字:
>>> sddf2.index
Int64Index([0, 1, 2, 3], dtype='int64')
输出行名字有什么:
>>> sddf2.columns
Index(['A', 'B', 'C'], dtype='object')
查看刚才那个表的内容:
>>> sddf2.values
array([[1.0, Timestamp('2013-01-01 00:00:00'), 1.0],
[1.0, Timestamp('2013-01-01 00:00:00'), 1.0],
[1.0, Timestamp('2013-01-01 00:00:00'), 1.0],
[1.0, Timestamp('2013-01-01 00:00:00'), 1.0]], dtype=object)
对这个表进行描述(只能显示表中数字数据的资料)
>>> sddf2.describe()
A C
count 4.0 4.0
mean 1.0 1.0
std 0.0 0.0
min 1.0 1.0
25% 1.0 1.0
50% 1.0 1.0
75% 1.0 1.0
max 1.0 1.0
>>>
吧那个表当成矩阵转置:
>>> sddf2.T
0 1 2 3
A 1 1 1 1
B 2013-01-01 00:00:00 2013-01-01 00:00:00 2013-01-01 00:00:00 2013-01-01 00:00:00
C 1 1 1 1
>>>
对索引排序:
ascending =False 倒着排序
ascending =True 正着排序
axis = 1 横着排序
axis = 0 竖着排序
>>> sddf2.sort_index(axis = 1,ascending = False)
C B A
0 1.0 2013-01-01 1.0
1 1.0 2013-01-01 1.0
2 1.0 2013-01-01 1.0
3 1.0 2013-01-01 1.0
>>>
>>> sddf2.sort_index(axis = 0,ascending = False)
A B C
3 1.0 2013-01-01 1.0
2 1.0 2013-01-01 1.0
1 1.0 2013-01-01 1.0
0 1.0 2013-01-01 1.0
对值排序(指定对于C那一列排序,但是我这里都是1,看不出来):
>>> sddf2.sort_values(by = 'C')
A B C
0 1.0 2013-01-01 1.0
1 1.0 2013-01-01 1.0
2 1.0 2013-01-01 1.0
3 1.0 2013-01-01 1.0
>>>
4、
import numpy as np
import pandas as pd
>>> dates = pd.date_range('20130101',periods = 6)
>>> df = pd.DataFrame(np.arange(24).reshape((6,4)),index = dates,columns = ['A','B','C','D'])
>>> df
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
继续操作,按照列打印,只需要指定列的名字:
>>> print(df['A'],df.A)
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int32 2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int32
>>>
指定范围输出:
>>> print(df[0:3],df['20130101':'20130104'])
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11 A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
>>>
根据标签输出:loc,比如日期:
>>> print(df.loc['20130101'])
A 0
B 1
C 2
D 3
Name: 2013-01-01 00:00:00, dtype: int32
>>>
不仅可以选择横向的标签,还可以选择纵向的标签:
>>> print(df.loc[:,['A','B']]) #所有行用:表示
A B
2013-01-01 0 1
2013-01-02 4 5
2013-01-03 8 9
2013-01-04 12 13
2013-01-05 16 17
2013-01-06 20 21
>>>
行和列的标签都选:
>>> print(df.loc['20130102',['A','B']])
A 4
B 5
Name: 2013-01-02 00:00:00, dtype: int32
根据位置选:iloc
>>> print(df.iloc[3]) #选择第三行的数据
A 12
B 13
C 14
D 15
Name: 2013-01-04 00:00:00, dtype: int32
>>> print(df.iloc[3,1]) #选择第三行第一位的数据
13
>>> print(df.iloc[3:5,1:2]) #第3行到第5行,并且在第1列到第2列之间的数据
B
2013-01-04 13
2013-01-05 17
>>> print(df.iloc[[3,5],1:2]) #不连续的筛选,第3行和第5行,且在第1列到第2列的数据
B
2013-01-04 13
2013-01-06 21
mixed selection :ix(标签加位置)
>>> print(df.ix[:3,['A','C']])
A C
2013-01-01 0 2
2013-01-02 4 6
2013-01-03 8 10
>>>
根据条件进行筛选:
>>> print(df[df.A>8])
A B C D
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
>>>
5、pandas设置值
初始数据和前一部分一样,然后我们继续进行举例:
>>> df
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
>>> df.iloc[1,3] = 455 #指定位置(1,3)这个坐标,修改数据,就像列表
>>> df
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 455
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
>>>
>>> df.loc['20130101','B'] = 323 #横向标签为20130101,纵向是B,这个数据改为323
>>> df
A B C D
2013-01-01 0 323 2 3
2013-01-02 4 5 6 455
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
>>>
>>> df[df.A>5] = 0 #所以A大于5的行,全部赋值为0
>>> df
A B C D
2013-01-01 0 323 2 3
2013-01-02 4 5 6 455
2013-01-03 0 0 0 0
2013-01-04 0 0 0 0
2013-01-05 0 0 0 0
2013-01-06 0 0 0 0
>>> df.D[df.A>1] = 6 #在D这一列,凡是A这一列上面大于1 的行,都要变成6
>>>
>>> df
A B C D
2013-01-01 0 323 2 3
2013-01-02 4 5 6 6
2013-01-03 0 0 0 0
2013-01-04 0 0 0 0
2013-01-05 0 0 0 0
2013-01-06 0 0 0 0
>>>
添加空列
>>> df['F'] = np.nan
>>> df
A B C D F
2013-01-01 0 323 2 3 NaN
2013-01-02 4 5 6 6 NaN
2013-01-03 0 0 0 0 NaN
2013-01-04 0 0 0 0 NaN
2013-01-05 0 0 0 0 NaN
2013-01-06 0 0 0 0 NaN
添加指定内容的列:
>>> df['E'] = pd.Series([1,2,3,4,5,6],index = pd.date_range('20130101',periods = 6))
>>> df
A B C D F E
2013-01-01 0 323 2 3 NaN 1
2013-01-02 4 5 6 6 NaN 2
2013-01-03 0 0 0 0 NaN 3
2013-01-04 0 0 0 0 NaN 4
2013-01-05 0 0 0 0 NaN 5
2013-01-06 0 0 0 0 NaN 6
删除指定的内容(dropna删除nan,就是空):
#how = {‘any’,‘all’} all代表必须是这一行或者这一列都满足条件才可以删除
>>> df.dropna(axis = 1,how = 'any')
A B C D E
2013-01-01 0 323 2 3 1
2013-01-02 4 5 6 6 2
2013-01-03 0 0 0 0 3
2013-01-04 0 0 0 0 4
2013-01-05 0 0 0 0 5
2013-01-06 0 0 0 0 6
>>>
将刚才删除的那一行填充,填充值为0
>>> df.fillna(value = 0)
A B C D F E
2013-01-01 0 323 2 3 0.0 1
2013-01-02 4 5 6 6 0.0 2
2013-01-03 0 0 0 0 0.0 3
2013-01-04 0 0 0 0 0.0 4
2013-01-05 0 0 0 0 0.0 5
2013-01-06 0 0 0 0 0.0 6
判断表里面数据是否非零:
>>> df.isnull()
A B C D F E
2013-01-01 False False False False True False
2013-01-02 False False False False True False
2013-01-03 False False False False True False
2013-01-04 False False False False True False
2013-01-05 False False False False True False
2013-01-06 False False False False True False
判断表中至少有一个是空:
>>> np.any(df.isnull())== True
True
>>>
6、导出导出数据
pandas读取的格式:(就是read下划线加括号里面的格式)
read_ (cvs\excel\hdf\sql\json\masgpack\html\gbq\stata\sas\clipboard\pickle)
假装我们这里有student.csv
读取:
import pandas as pd
data = pd.read_csv('student.csv')
print(data)#这时候就可以在idle里面显示文件内容
data.to_pickle('student.pickle') #保存在pickle文件中
7、合并concatebating
>>>import pandas as pd
>>>import numpy as np
>>> df1 = pd.DataFrame(np.ones((3,4))*0,columns = ['a','b','c','d'])
>>> df2 = pd.DataFrame(np.ones((3,4))*1,columns = ['a','b','c','d'])
>>> df3 = pd.DataFrame(np.ones((3,4))*2,columns = ['a','b','c','d'])
>>> df1
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
>>> df2
a b c d
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
>>> df3
a b c d
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
>>>
进行合并:
>>> res = pd.concat([df1,df2,df3],axis = 0) #竖向合并
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
如果想要让左边的序号变成012345678:
>>> res = pd.concat([df1,df2,df3],axis = 0,ignore_index = True) #忽略index
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
join,[‘inner’,‘outer’]
>>> df1
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
>>> df2
b c d e
2 1.0 1.0 1.0 1.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
>>> res= pd.concat([df1,df2])
#如果没有加join参数,会自动对齐,不全的地方会添加nan
>>> res
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
>>>
join = 'inner’就是只考虑二者的共同点,不一样的地方进行裁剪
>>> res= pd.concat([df1,df2],join = 'inner')
>>> res
b c d
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 0.0 0.0 0.0
2 1.0 1.0 1.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
>>>
join = 'outer’不管不一样的是啥,都黏在一起
>>> res= pd.concat([df1,df2],join = 'outer')
>>> res
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
和上面一样,想要让他左边的序列不是123234,变成按序的:
>>> res= pd.concat([df1,df2],join = 'outer',ignore_index = 'Ture')
>>> res
a b c d e
0 0.0 0.0 0.0 0.0 NaN
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
5 NaN 1.0 1.0 1.0 1.0
#join_axes
>>> df1
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
>>> df2
b c d e
2 1.0 1.0 1.0 1.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
>>> res = pd.concat([df1,df2],axis = 1,join_axes = [df1.index])
#按照df1的序号进行左右合并,df1序号是123.df2是234,那么df2没有1,所以在1这一行用nan填充
>>> res
a b c d b c d e
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
反之,参照df2的序号进行左右合并,也一样:
>>> res = pd.concat([df1,df2],axis = 1,join_axes = [df2.index])
>>> res
a b c d b c d e
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
4 NaN NaN NaN NaN 1.0 1.0 1.0 1.0
#append
向下添加一个:
>>> df2 = pd.DataFrame(np.ones((3,4))*1,columns = ['a','b','c','d'])
>>> res = df1.append(df2,ignore_index = 'True') #吧df2添加到df1下面,忽略序号
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
向下添加,如果是2个及以上,就得用列表:
>>> df2
a b c d
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
>>> df3
a b c d
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
>>> df1
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
>>> res = df1.append([df2,df3],ignore_index = 'True')
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
在表最下面添加一行,就是添加一个列表:
>>> s1 = pd.Series([1,2,3,4],index= ['a','b','c','d'])
>>> res = df1.append(s1,ignore_index = 'True')
>>> res
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 2.0 3.0 4.0
>>>
8、合并:merge
>>> left = pd.DataFrame({'key':['k0','k1','k2','k3'],'A':['a0','a1','a2','a3'],'B':['b0','b1','b2','b3']})
>>> right = pd.DataFrame({'key':['k0','k1','k2','k3'],'C':['c0','c1','c2','c3'],'D':['d0','d1','d2','d3']})
>>> left
key A B
0 k0 a0 b0
1 k1 a1 b1
2 k2 a2 b2
3 k3 a3 b3
>>> right
key C D
0 k0 c0 d0
1 k1 c1 d1
2 k2 c2 d2
3 k3 c3 d3
>>> res = pd.merge(left,right,on ='key') #共同的是key,然后进行合并
>>> res
key A B C D
0 k0 a0 b0 c0 d0
1 k1 a1 b1 c1 d1
2 k2 a2 b2 c2 d2
3 k3 a3 b3 c3 d3
两个key:
>>> left = pd.DataFrame({'key1':['k0','k0','k1','k2'],'key2':['k0','k1','k0','k1'],'A':['a0','a1','a2','a3'],'B':['b0','b1','b2','b3']})
>>> right = pd.DataFrame({'key1':['k0','k0','k1','k2'],'key2':['k0','k0','k0','k0'],'A':['a0','a1','a2','a3'],'B':['b0','b1','b2','b3']})
>>> right
key1 key2 A B
0 k0 k0 a0 b0
1 k0 k0 a1 b1
2 k1 k0 a2 b2
3 k2 k0 a3 b3
>>> left
key1 key2 A B
0 k0 k0 a0 b0
1 k0 k1 a1 b1
2 k1 k0 a2 b2
3 k2 k1 a3 b3
>>> res = pd.merge(left,right,on = ['key1','key2'])
>>> res
key1 key2 A_x B_x A_y B_y #因为left和right都有A和B,这里默认加了区分
0 k0 k0 a0 b0 a0 b0
1 k0 k0 a0 b0 a1 b1
2 k1 k0 a2 b2 a2 b2
how = [‘left’,‘right’,‘inner’,‘outer’]四种方式可取
>>> res = pd.merge(left,right,on = ['key1','key2'],how = 'inner')
>>> res
key1 key2 A_x B_x A_y B_y
0 k0 k0 a0 b0 a0 b0
1 k0 k0 a0 b0 a1 b1
2 k1 k0 a2 b2 a2 b2
>>>
>>> res = pd.merge(left,right,on = ['key1','key2'],how = 'outer')
>>> res
key1 key2 A_x B_x A_y B_y
0 k0 k0 a0 b0 a0 b0
1 k0 k0 a0 b0 a1 b1
2 k0 k1 a1 b1 NaN NaN
3 k1 k0 a2 b2 a2 b2
4 k2 k1 a3 b3 NaN NaN
5 k2 k0 NaN NaN a3 b3
>>> res = pd.merge(left,right,on = ['key1','key2'],how = 'left')
>>> res
key1 key2 A_x B_x A_y B_y
0 k0 k0 a0 b0 a0 b0
1 k0 k0 a0 b0 a1 b1
2 k0 k1 a1 b1 NaN NaN
3 k1 k0 a2 b2 a2 b2
4 k2 k1 a3 b3 NaN NaN
#indicator,默认是False
>>> res = pd.merge(df1,df2,on = 'col1',how = 'outer',indicator = True)
>>> res
col1 col_left col_right _merge
0 0 a NaN left_only #只有left有这个数据
1 1 b 2.0 both
2 2 NaN 2.0 right_only #只有right有这个数据
3 2 NaN 2.0 right_only
#merged by index
right_index和left_index默认值都是none
>>> right = pd.DataFrame({'c':['c0','c1','c2'],'d':['d0','d1','d2']},index=['k0','k2','k3'])
>>> left = pd.DataFrame({'A':['a0','a1','a2'],'B':['b0','b1','b2']},index=['k0','k1','k2'])
>>> res
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
>>> res = pd.merge(left,right,left_index = True,right_index = True,how = 'outer')
>>> res
A B c d
k0 a0 b0 c0 d0
k1 a1 b1 NaN NaN
k2 a2 b2 c1 d1
k3 NaN NaN c2 d2
#handle overlapping
>>> boys =pd.DataFrame({'k':['k0','k1','k2'],'age':[1,2,3]})
>>> girls = pd.DataFrame({'k':['k0','k0','k3'],'age':[4,5,6]})
>>> res = pd.merge(boys,girls, on = 'k',suffixes = ['_boy','_girl'],how = 'inner')
>>> res
k age_boy age_girl
0 k0 1 4
1 k0 1 5
>>> boys
k age
0 k0 1
1 k1 2
2 k2 3
>>> girls
k age
0 k0 4
1 k0 5
2 k3 6
9、pandas 可视化
将数据线性化
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> import pandas as pd
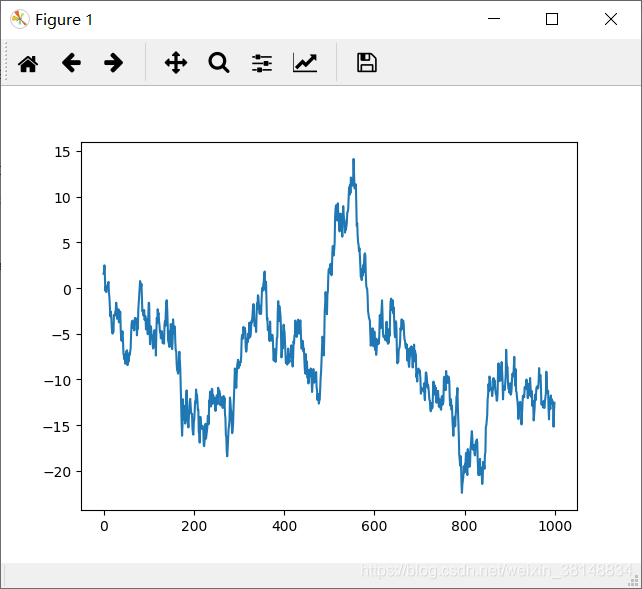
>>> data = pd.Series(np.random.randn(1000),index = np.arange(1000))
>>> data = data.cumsum()#进行累加
>>> data.plot()
<matplotlib.axes._subplots.AxesSubplot object at 0x0000023B6F9B58D0>
>>> plt.show()
结果:
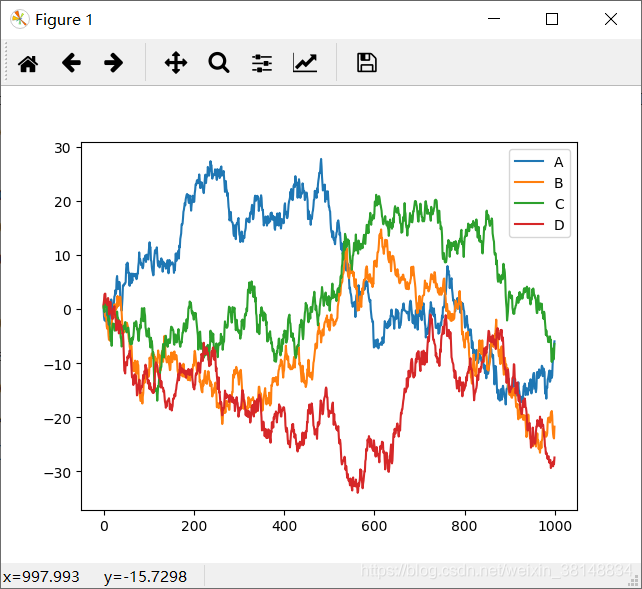
>>> data = pd.DataFrame(np.random.randn(1000,4),index = np.arange(1000),columns = list("ABCD"))
>>> data.head()
A B C D
0 0.361954 0.253040 0.589226 0.850775
1 -1.737184 0.653004 -0.523011 0.668515
2 -0.681178 -0.939557 -0.638712 1.149105
3 -0.031436 -1.227140 1.589034 0.159923
4 0.002158 -0.163007 0.351010 0.002592
>>> data = data.cumsum()
>>> data.plot()
<matplotlib.axes._subplots.AxesSubplot object at 0x0000023B72E23A20>
>>> plt.show()
结果:
#plot method
‘bar’,‘hist’,‘box’,‘kde’,‘area’,‘scatter’,‘hexbin’,‘pie’
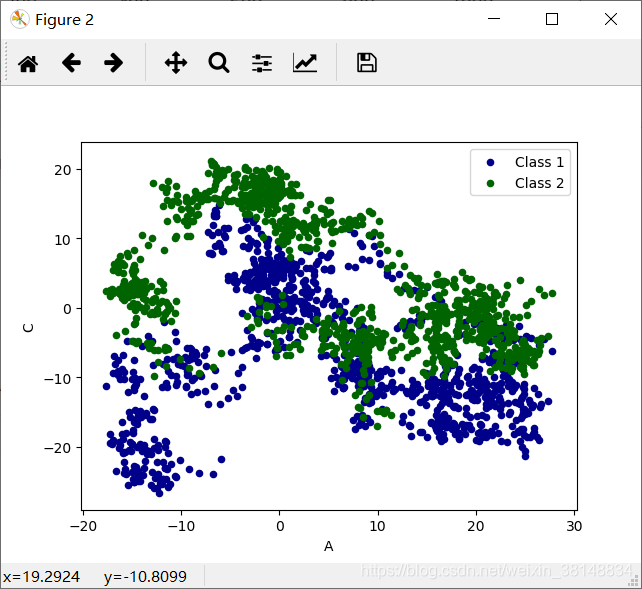
同时打印两张表:
>>> ax =data.plot.scatter(x = 'A',y = 'B',color = 'DarkBlue',label = 'Class 1')
>>> data.plot.scatter(x = 'A',y = 'C',color = 'DarkGreen',label = 'Class 2',ax = ax)
<matplotlib.axes._subplots.AxesSubplot object at 0x0000023B6FD04B70>
>>> plt.show()
结果:














 3061
3061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









