






https://daiwk.github.io/posts/nlp-bert.html
目录
参考最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
参考https://www.zhihu.com/question/298203515/answer/509703208
概述
本文介绍了一种新的语言表征模型BERT——来自Transformer的双向编码器表征。与最近的语言表征模型不同,BERT旨在基于所有层的左、右语境来预训练深度双向表征。BERT是首个在大批句子层面和token层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统,刷新了11项NLP任务的当前最优性能记录。
目前将预训练语言表征应用于下游任务存在两种策略:feature-based的策略和fine-tuning策略。
- feature-based策略(如 ELMo)使用将预训练表征作为额外特征的任务专用架构。
- fine-tuning策略(如生成预训练 Transformer (OpenAI GPT))引入了任务特定最小参数,通过简单地微调预训练参数在下游任务中进行训练。
在之前的研究中,两种策略在预训练期间使用相同的目标函数,利用单向语言模型来学习通用语言表征。
作者认为现有的技术严重制约了预训练表征的能力,微调策略尤其如此。其主要局限在于标准语言模型是单向的,这限制了可以在预训练期间使用的架构类型。例如,OpenAI GPT使用的是从左到右的架构,其中每个token只能注意Transformer自注意力层中的先前token。这些局限对于句子层面的任务而言不是最佳选择,对于token级任务(如 SQuAD 问答)则可能是毁灭性的,因为在这种任务中,结合两个方向的语境至关重要。
BERT(Bidirectional Encoder Representations from Transformers)改进了基于微调的策略。
BERT提出一种新的预训练目标——遮蔽语言模型(masked language model,MLM),来克服上文提到的单向局限。MLM 的灵感来自 Cloze 任务(Taylor, 1953)。MLM随机遮蔽输入中的一些token,目标在于仅基于遮蔽词的语境来预测其原始词汇id。与从左到右的语言模型预训练不同,MLM目标允许表征融合左右两侧的语境,从而预训练一个深度双向Transformer。除了 MLM,我们还引入了一个“下一句预测”(next sentence prediction)任务,该任务联合预训练文本对表征。
贡献:
- 展示了双向预训练语言表征的重要性。不同于 Radford 等人(2018)使用单向语言模型进行预训练,BERT使用MLM预训练深度双向表征。本研究与 Peters 等人(2018)的研究也不同,后者使用的是独立训练的从左到右和从右到左LM的浅层级联。
- 证明了预训练表征可以消除对许多精心设计的任务特定架构的需求。BERT是首个在大批句子层面和token层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统。
- BERT 刷新了11项NLP任务的当前最优性能记录。本论文还报告了BERT的模型简化测试(ablation study),证明该模型的双向特性是最重要的一项新贡献。代码和预训练模型将发布在goo.gl/language/bert。
BERT
模型架构
BERT 旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的 BERT 表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推断任务)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT 的模型架构是一个多层双向Transformer编码器,基于Vaswani 等人 (2017)描述的原始实现,在tensor2tensor库中发布(当然,可以抽空看看https://daiwk.github.io/posts/platform-tensor-to-tensor.html和https://daiwk.github.io/posts/platform-tensor-to-tensor-coding.html)。
本文中,我们将层数(即Transformer块)表示为\(L\),将隐层的size表示为\(H\)、自注意力头数表示为\(A\)。在所有实验中,我们将feed-forward/filter的size设置为\(4H\),即H=768时为3072,H=1024时为4096。我们主要看下在两种模型尺寸上的结果:
\(BERT_{BASE}\): L=12, H=768, A=12, Total Parameters=110M\(BERT_{LARGE}\): L=24, H=1024, A=16, Total Parameters=340M
其中,\(BERT_{BASE}\)和OpenAI GPT的大小是一样的。BERT Transformer使用双向自注意力机制,而GPT Transformer使用受限的自注意力机制,导致每个token只能关注其左侧的语境。双向Transformer在文献中通常称为“Transformer 编码器”,而只关注左侧语境的版本则因能用于文本生成而被称为“Transformer 解码器”。
下图显示了BERT/GPT Transformer/ELMo的结构区别:
- BERT 使用双向Transformer
- OpenAI GPT 使用从左到右的Transformer
- ELMo 使用独立训练的从左到右和从右到左LSTM的级联来生成下游任务的特征。
三种模型中,只有BERT表征会基于所有层中的左右两侧语境。
Input Representation
论文的输入表示(input representation)能够在一个token序列中明确地表示单个文本句子或一对文本句子(例如, [Question, Answer])。对于给定token,其输入表示通过对相应的token、segment和position embeddings进行求和来构造:
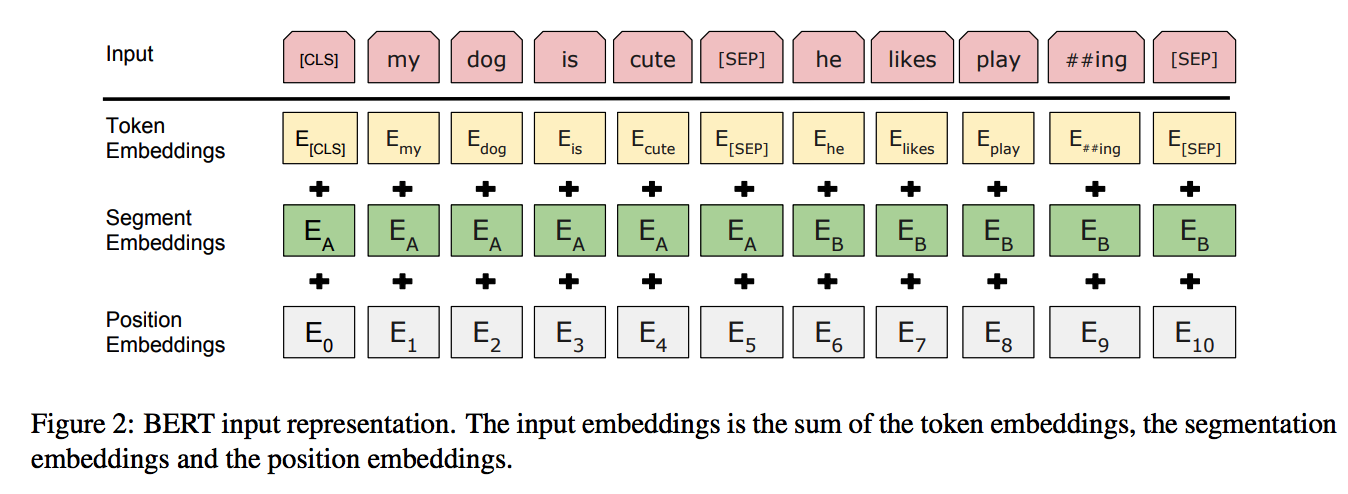
- 使用WordPiece嵌入【GNMT,Google’s neural machine translation system: Bridging the gap between human and machine translation】和30,000个token的词汇表。用##表示分词。
- 使用learned positional embeddings,支持的序列长度最多为512个token。
- 每个序列的第一个token始终是特殊分类嵌入([CLS])。对应于该token的最终隐藏状态(即,Transformer的输出)被用作分类任务的聚合序列表示。对于非分类任务,将忽略此向量。
- 句子对被打包成一个序列。以两种方式区分句子。
- 首先,用特殊标记([SEP])将它们分开。
- 其次,添加一个learned sentence A嵌入到第一个句子的每个token中,一个sentence B嵌入到第二个句子的每个token中。
- 对于单个句子输入,只使用 sentence A嵌入。
Pre-training Tasks
- 它在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。感觉其目的在于使模型被迫增加对上下文的记忆。(知乎的回答)
- 增加了一个预测下一句的loss。
Task #1: Masked LM
标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件作用将允许每个单词在多层上下文中间接地“see itself”。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。论文将这个过程称为“masked LM”(MLM),尽管在文献中它经常被称为Cloze任务(Taylor, 1953)。
在这个例子中,与masked token对应的最终隐藏向量被输入到词汇表上的输出softmax中,就像在标准LM中一样。在团队所有实验中,随机地屏蔽了每个序列中15%的WordPiece token。与去噪的自动编码器(Vincent et al., 2008)相反,只预测masked words而不是重建整个输入。
虽然这确实能让团队获得双向预训练模型,但这种方法有两个缺点。
- 缺点1:预训练和finetuning之间不匹配,因为在finetuning期间从未看到
[MASK]token。
为了解决这个问题,团队并不总是用实际的[MASK]token替换被“masked”的词汇。相反,训练数据生成器随机选择15%的token。
例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
- 80%的时间:用
[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK] - 10%的时间:用一个随机的单词替换该单词,例如,
my dog is hairy → my dog is apple - 10%的时间:保持单词不变,例如,
my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
- 缺点2:每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。
团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
Task #2: Next Sentence Prediction
在为了训练一个理解句子的模型关系,预先训练一个二分类的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。例如:
Input =
[CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP] Label = IsNext Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext 完全随机地选择了NotNext语句,最终的预训练模型在此任务上实现了97%-98%的准确率。
Pre-training Procedure
使用gelu激活函数(Bridging nonlinearities and stochastic regularizers with gaus- sian error linear units),在pytorch里实现如下:
class GELU(nn.Module): """ Paper Section 3.4, last paragraph notice that BERT used the GELU instead of RELU """ def forward(self, x): return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Fine-tuning Procedure
Comparison of BERT and OpenAI GPT
实验
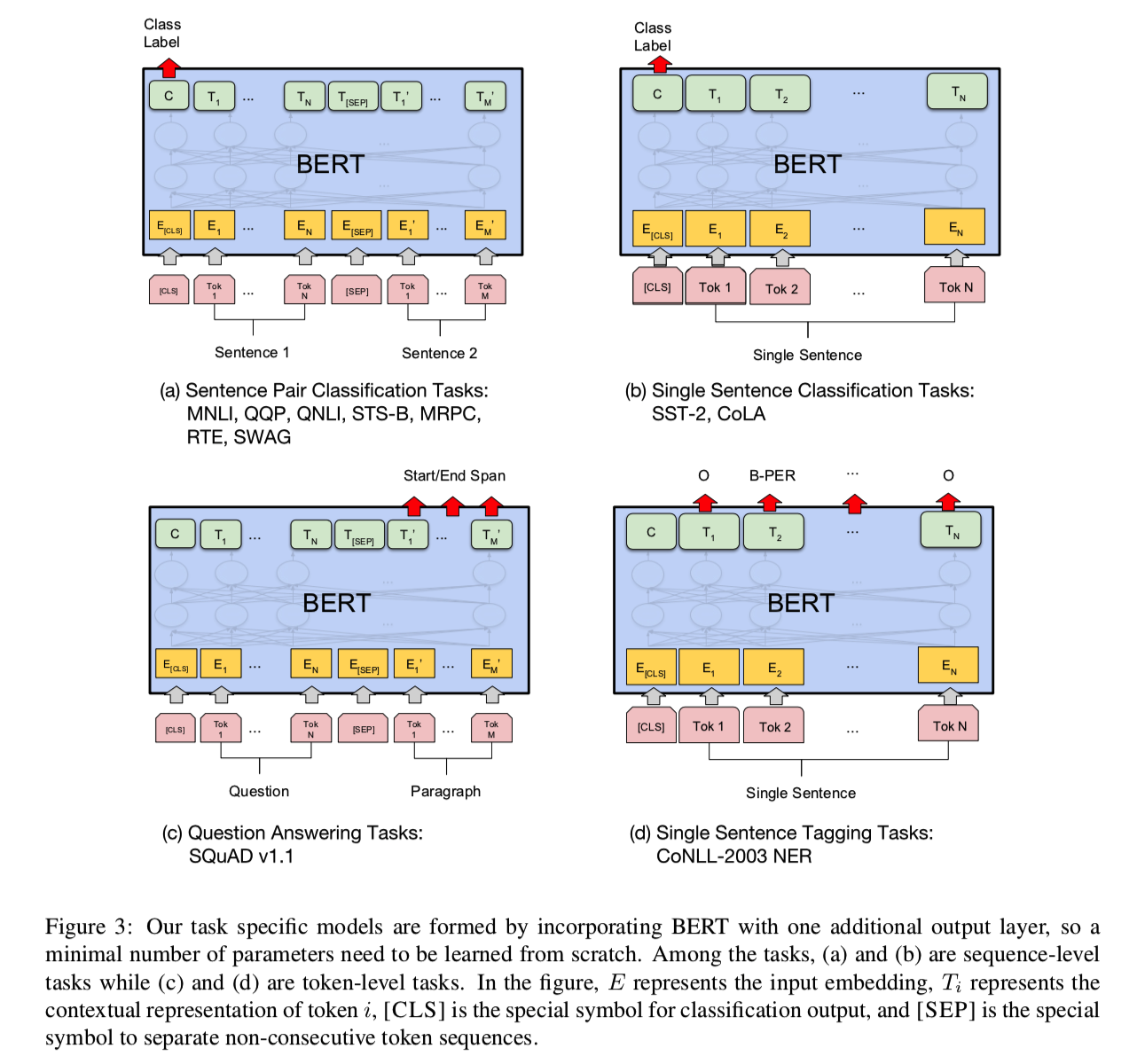
网络结构如下:
GLUE Datasets
GLUE Results
SQuAD v1.1
Named Entity Recognition
SWAG
Ablation Studies
Effect of Pre-training Tasks
Effect of Model Size
Effect of Number of Training Steps
Feature-based Approach with BERT
代码实现
pytorch版本
https://github.com/codertimo/BERT-pytorch
fork了一份:https://github.com/daiwk/BERT-pytorch
输入data/corpus.small:
Welcome to the \t the jungle \n
I can stay \t here all night \n
可视化,需要:
brew install graphviz # mac
pip3 install git+https://github.com/szagoruyko/pytorchviz
画出bert的架构图的方法(先生成vocab,如果机器的dot不支持pdf,只支持png/jpg等,需要在lib/python3.6/site-packages/torchviz/dot.py中把dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"))改成dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"), format="png")):
import torch
from torch import nn from torchviz import make_dot, make_dot_from_trace import sys sys.path.append("./bert_pytorch-0.0.1a4.src/") #from trainer import BERTTrainer from model import BERTLM, BERT from dataset import BERTDataset, WordVocab from torch.utils.data import DataLoader def demo(): lstm_cell = nn.LSTMCell(128, 128) x = torch.randn(1, 128) dot = make_dot(lstm_cell(x), params=dict(list(lstm_cell.named_parameters()))) file_out = "xx" dot.render(file_out) def bert_dot(): """ """ vocab_size = 128 train_dataset_path = "data/bert_train_data.xxx" vocab_path = "data/vocab.all.xxx" vocab = WordVocab.load_vocab(vocab_path) train_dataset = BERTDataset(train_dataset_path, vocab, seq_len=20, corpus_lines=2000, on_memory=True) train_data_loader = DataLoader(train_dataset, batch_size=8, num_workers=8) bert = BERT(len(vocab), hidden=256, n_layers=8, attn_heads=8) device = torch.device("cpu") mymodel = BERTLM(bert, vocab_size).to(device) data_iter = train_data_loader out_idx = 0 for data in data_iter: data = {key: value.to(device) for key, value in data.items()} if out_idx == 0: g = make_dot(mymodel(data["bert_input"], data["segment_label"]), params=dict(mymodel.














 5537
5537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









