






一、将虚拟环境加载至pycharm
1、进入pycharm,新建项目
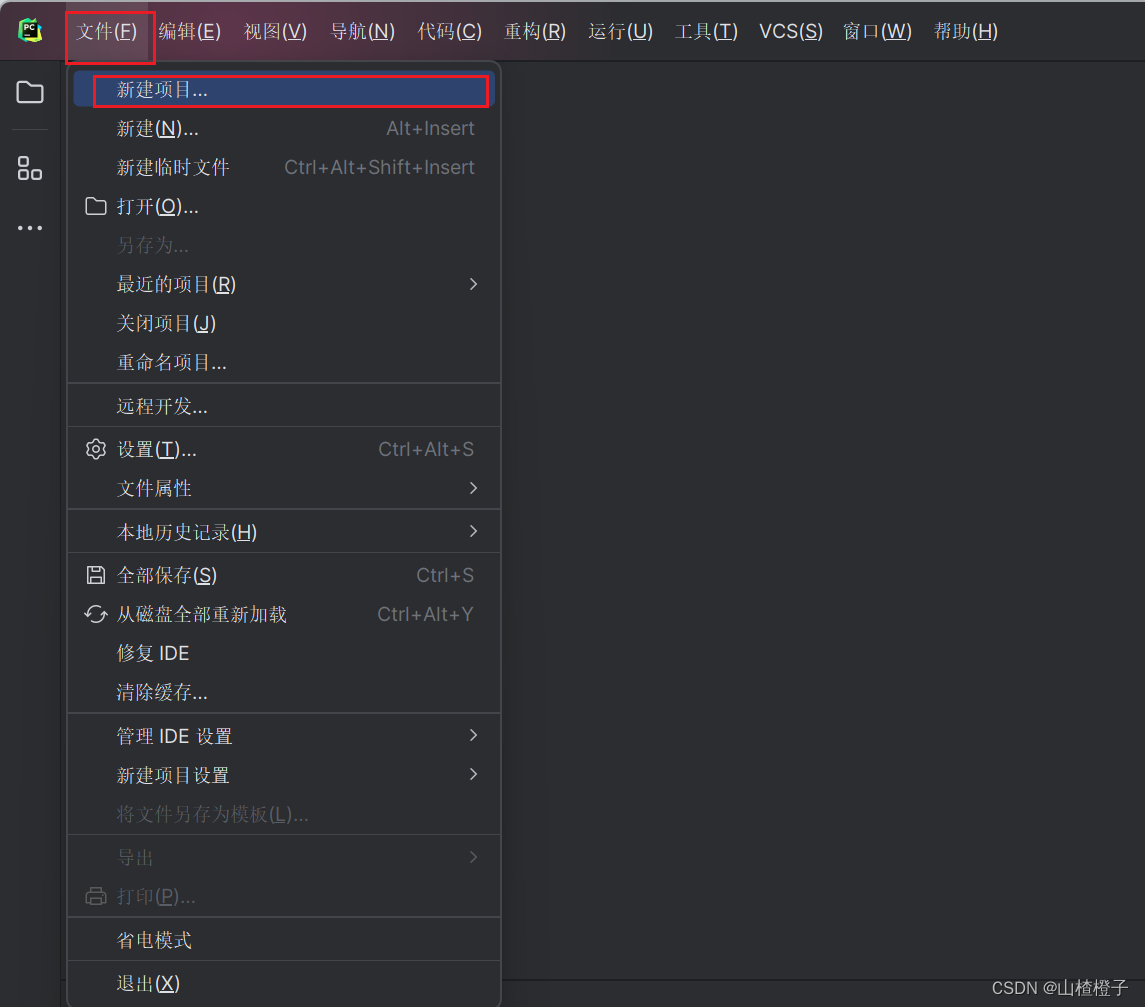
2、输入项目信息
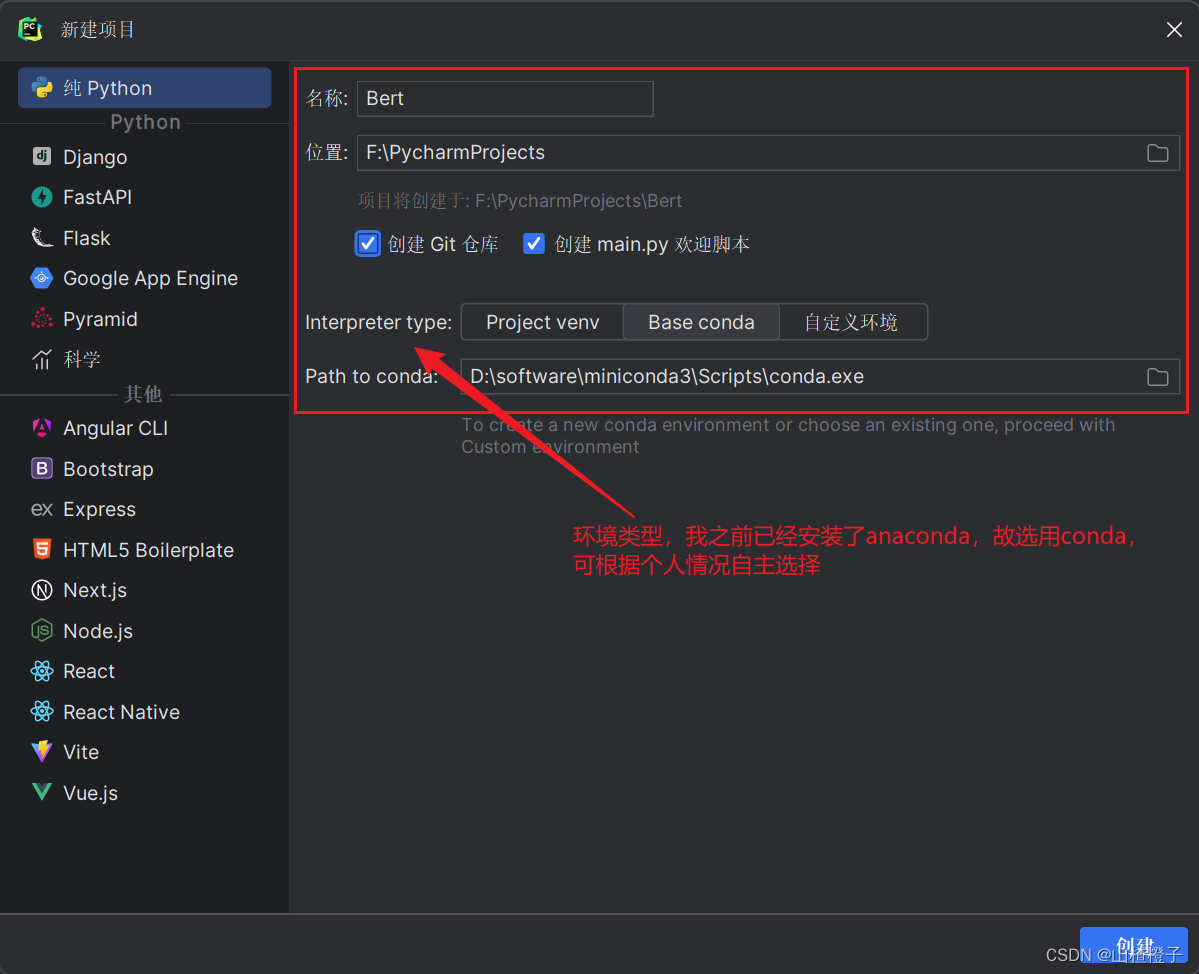
二、使用示例
import torch
def test():
from transformers import BertTokenizer, BertModel, BertForMaskedLM
from transformers import BertModel, BertTokenizer
BERT_PATH = './model/chinese_wwm_L-12_H-768_A-12/publish/'
tokenizer = BertTokenizer.from_pretrained(BERT_PATH)
print(tokenizer.tokenize('I have a good time, thank you.'))
bert = BertModel.from_pretrained(BERT_PATH)
print('load bert model over')
if __name__ == '__main__':
test()
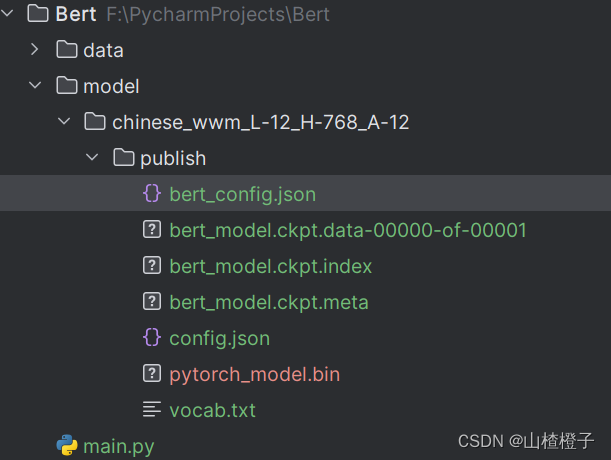
文件结构
结果

可以看到bert模型成功使用,且使用了掩码,将“than”掩盖为“##”
三、初步使用
1、预处理数据
现在我们基本熟悉了 BERT 的基本使用,接下来为其准备输入数据。一般情况下,在训练模型前,都需要对手上的数据进行预处理,以满足模型需要。
为了更容易理解得到的输出tokenization,我们以一个简短的文本为例。
from transformers import BertTokenizer
BERT_PATH = './model/chinese_wwm_L-12_H-768_A-12/publish/'
tokenizer = BertTokenizer.from_pretrained(BERT_PATH)
# tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
example_text = 'I will watch Memento tonight'
bert_input = tokenizer(example_text, padding='max_length',
max_length=15,
truncation=True,
return_tensors="pt")
# ------- bert_input ------
print(bert_input['input_ids'])
print(bert_input['token_type_ids'])
print(bert_input['attention_mask'])
下面是对上面BertTokenizer参数的解释:
padding:将每个sequence填充到指定的最大长度。max_length: 每个sequence的最大长度。本示例中我们使用 15,但对于本文实际数据集,我们将使用 512,这是 BERT 允许的sequence 的最大长度。truncation:如果为True,则每个序列中超过最大长度的标记将被截断。return_tensors:将返回的张量类型。由于我们使用的是 Pytorch,所以我们使用pt;如果你使用 Tensorflow,那么你需要使用tf。
从上面的变量中看到的输出bert_input,是用于稍后的 BERT 模型。但是这些输出是什么意思?
1. 第一行是 input_ids,它是每个 token 的 id 表示。实际上可以将这些输入 id 解码为实际的token,如下所示:
example_text = tokenizer.decode(bert_input.input_ids[0])
print(example_text)
由上述结果所示,BertTokenizer负责输入文本的所有必要转换,为 BERT 模型的输入做好准备。它会自动添加 [CLS]、[SEP] 和 [PAD] token。由于我们指定最大长度为 15,所以最后有五个 [PAD] token。
2. 第二行是 token_type_ids,它是一个 binary mask,用于标识 token 属于哪个 sequence。如果我们只有一个 sequence,那么所有的 token 类型 id 都将为 0。对于文本分类任务,token_type_ids是 BERT 模型的可选输入参数。
3. 第三行是 attention_mask,它是一个 binary mask,用于标识 token 是真实 word 还是只是由填充得到。如果 token 包含 [CLS]、[SEP] 或任何真实单词,则 mask 将为 1。如果 token 只是 [PAD] 填充,则 mask 将为 0。
2、数据集类
现在我们知道从BertTokenizer中获得什么样的输出,接下来为新闻数据集构建一个Dataset类,该类将作为一个类来将新闻数据转换成模型需要的数据格式。
import torch
import numpy as np
from transformers import BertTokenizer
BERT_PATH = './model/chinese_wwm_L-12_H-768_A-12/publish'
tokenizer = BertTokenizer.from_pretrained(BERT_PATH)
labels = {'business':0,
'entertainment':1,
'sport':2,
'tech':3,
'politics':4
}
class Dataset(torch.utils.data.Dataset):
def __init__(self, df):
self.labels = [labels[label] for label in df['category']]
self.texts = [tokenizer(text,
padding='max_length',
max_length = 512,
truncation=True,
return_tensors="pt")
for text in df['text']]
def classes(self):
return self.labels
def __len__(self):
return len(self.labels)
def get_batch_labels(self, idx):
# Fetch a batch of labels
return np.array(self.labels[idx])
def get_batch_texts(self, idx):
# Fetch a batch of inputs
return self.texts[idx]
def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y在上面实现的代码中,我们定义了一个名为 labels的变量,它是一个字典,将DataFrame中的 category 映射到 labels的 id 表示。注意,上面的__init__函数中,还调用了BertTokenizer将输入文本转换为 BERT 期望的向量格式。
定义Dataset类后,将数据框拆分为训练集、验证集和测试集,比例为 80:10:10。
np.random.seed(112)
df = pd.read_csv('./data/train.csv')
df_train, df_val, df_test = np.split(df.sample(frac=1, random_state=42),
[int(.8 * len(df)), int(.9 * len(df))])
print(len(df_train), len(df_val), len(df_test))
3、构建模型
至此,我们已经成功构建了一个 Dataset 类来生成模型输入数据。现在使用具有 12 层 Transformer 编码器的预训练 BERT 基础模型构建实际模型。
from torch import nn
from transformers import BertModel
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
BERT_PATH = './model/chinese_wwm_L-12_H-768_A-12/publish'
self.bert = BertModel.from_pretrained(BERT_PATH)
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 5)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer从上面的代码可以看出,BERT 模型输出了两个变量:
- 在上面的代码中命名的第一个变量
_包含sequence中所有 token 的 Embedding 向量层。 - 命名的第二个变量
pooled_output包含 [CLS] token 的 Embedding 向量。对于文本分类任务,使用这个 Embedding 作为分类器的输入就足够了。
然后将pooled_output变量传递到具有 ReLU 激活函数的线性层。在线性层中输出一个维度大小为 5 的向量,每个向量对应于标签类别。
4、训练模型
接下来是训练模型。使用标准的 PyTorch 训练循环来训练模型。
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_data, val_data, learning_rate, epochs):
# 通过Dataset类获取训练和验证集
train, val = Dataset(train_data), Dataset(val_data)
# DataLoader根据batch_size获取数据,训练时选择打乱样本
train_dataloader = torch.utils.data.DataLoader(train, batch_size=2, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2)
# 判断是否使用GPU
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
# 开始进入训练循环
for epoch_num in range(epochs):
# 定义两个变量,用于存储训练集的准确率和损失
total_acc_train = 0
total_loss_train = 0
# 进度条函数tqdm
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
# 通过模型得到输出
output = model(input_id, mask)
# 计算损失
batch_loss = criterion(output, train_label)
total_loss_train += batch_loss.item()
# 计算精度
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
# 模型更新
model.zero_grad()
batch_loss.backward()
optimizer.step()
# ------ 验证模型 -----------
# 定义两个变量,用于存储验证集的准确率和损失
total_acc_val = 0
total_loss_val = 0
# 不需要计算梯度
with torch.no_grad():
# 循环获取数据集,并用训练好的模型进行验证
for val_input, val_label in val_dataloader:
# 如果有GPU,则使用GPU,接下来的操作同训练
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_data): .3f}
| Train Accuracy: {total_acc_train / len(train_data): .3f}
| Val Loss: {total_loss_val / len(val_data): .3f}
| Val Accuracy: {total_acc_val / len(val_data): .3f}''') 我们对模型进行了 5 个 epoch 的训练,我们使用 Adam 作为优化器,而学习率设置为1e-6。因为本案例中是处理多类分类问题,则使用分类交叉熵作为我们的损失函数。
建议使用 GPU 来训练模型,因为 BERT 基础模型包含 1.1 亿个参数。
EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)排查了三个小时错误之后,我的模型它终于在跑了,我好欣慰。
 进度条终于进了!!!!!!!!!!!
进度条终于进了!!!!!!!!!!!
训练结果
100%|██████████| 4000/4000 [09:37<00:00, 6.93it/s]
0%| | 0/4000 [00:00<?, ?it/s]Epochs: 1
| Train Loss: 0.590
| Train Accuracy: 0.518
| Val Loss: 0.446
| Val Accuracy: 0.686
100%|██████████| 4000/4000 [09:47<00:00, 6.81it/s]
Epochs: 2
| Train Loss: 0.305
| Train Accuracy: 0.810
| Val Loss: 0.270
| Val Accuracy: 0.842
100%|██████████| 4000/4000 [09:36<00:00, 6.93it/s]
0%| | 0/4000 [00:00<?, ?it/s]Epochs: 3
| Train Loss: 0.163
| Train Accuracy: 0.910
| Val Loss: 0.223
| Val Accuracy: 0.878
100%|██████████| 4000/4000 [09:45<00:00, 6.83it/s]
Epochs: 4
| Train Loss: 0.092
| Train Accuracy: 0.953
| Val Loss: 0.208
| Val Accuracy: 0.882
100%|██████████| 4000/4000 [09:52<00:00, 6.76it/s]
Epochs: 5
| Train Loss: 0.058
| Train Accuracy: 0.970
| Val Loss: 0.196
| Val Accuracy: 0.898
Test Accuracy: 0.932显然,由于训练过程的随机性,每次可能不会得到与上面截图类似的损失和准确率值。如果在 5 个 epoch 之后没有得到好的结果,可以尝试将 epoch 增加到 10 个,或者调整学习率。
5、在测试数据上评估模型
现在我们已经训练了模型,我们可以使用测试数据来评估模型在未见数据上的性能。下面是评估模型在测试集上的性能的函数。
def evaluate(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')![]()
精确度为0.932,已然不低
四、下一步目标
1、保存训练后的模型,方便下次直接调用
2、学习如何加快模型训练速度
3、直接调用模型
4、保存分类后的结果
五、全部代码(包含bert中文模型、数据集)
GitHub地址:
GitHub - YZXqqq/first_bert: 第一次尝试bert模型训练及测试,结果为0.9+
百度网盘下载链接:
链接: https://pan.baidu.com/s/1BddRqHZAP6yWwLSxr7CgOg?pwd=rxff 提取码: rxff 复制这段内容后打开百度网盘手机App,操作更方便哦
如有失效或者需要阿里云盘链接的,可以留言告知,也可以私信我,也可以关注个人公众号【机器学习之NLP爬坡之旅】后台私信【001】获取下载链接
注:压缩包有1G
参考文章:
保姆级教程,用PyTorch和BERT进行文本分类 - 知乎
关于封面
封面提示词来自智谱清言旗下的GLM-4

封面来自智谱清言旗下的AI画图

















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











