







Qlib的代码是以一个比较“松散”的结构,每一个模块都尽量做到可以最大程度的复用。这一点很好支撑我们的量化系统。即能够最大复用它的工程能力,又可以自主发展我们想要的功能。
今天看一下Qlib的投资组合策略。
传统的量化回测策略不同在于,Qlib的策略输出是由模型输出预测好的分数,由这个分数来构建投资组合。
策略的基类是qlib.strategy.base.BaseStrategy
class BaseStrategy:
"""Base strategy for trading"""
def __init__(
self,
outer_trade_decision: BaseTradeDecision = None,
level_infra: LevelInfrastructure = None,
common_infra: CommonInfrastructure = None,
trade_exchange: Exchange = None,
):
BaseStrategy是一个抽象类,就是定义了一些基础参数。
它的一个子类是ModelStrategy,顾名思义,基于模型的预测来交易的类。
它传入两个参数,一个是模型,一个是数据集。
class ModelStrategy(BaseStrategy):
"""Model-based trading strategy, use model to make predictions for trading"""
def __init__(
self,
model: BaseModel,
dataset: DatasetH,
outer_trade_decision: BaseTradeDecision = None,
level_infra: LevelInfrastructure = None,
common_infra: CommonInfrastructure = None,
**kwargs,
):
"""
Parameters
----------
model : BaseModel
the model used in when making predictions
dataset : DatasetH
provide test data for model
kwargs : dict
arguments that will be passed into `reset` method
"""
super(ModelStrategy, self).__init__(outer_trade_decision, level_infra, common_infra, **kwargs)
self.model = model
self.dataset = dataset
self.pred_scores = convert_index_format(self.model.predict(dataset), level="datetime")
if isinstance(self.pred_scores, pd.DataFrame):
self.pred_scores = self.pred_scores.iloc[:, 0]
使用model.predict(dataset)生成预测分数pred_scores。
源码中可以看出,qlib实现了两个关于强化学习的策略类,但它们都还没有具体的实现类。
传入重要参数是policy。
class RLStrategy(BaseStrategy):
"""RL-based strategy"""
def __init__(
self,
policy,
outer_trade_decision: BaseTradeDecision = None,
level_infra: LevelInfrastructure = None,
common_infra: CommonInfrastructure = None,
**kwargs,
):
"""
Parameters
----------
policy :
RL policy for generate action
"""
super(RLStrategy, self).__init__(outer_trade_decision, level_infra, common_infra, **kwargs)
self.policy = policy
还有一个子类,带state和action的翻译器的类。
class RLIntStrategy(RLStrategy):
"""(RL)-based (Strategy) with (Int)erpreter"""
def __init__(
self,
policy,
state_interpreter: Union[dict, StateInterpreter],
action_interpreter: Union[dict, ActionInterpreter],
outer_trade_decision: BaseTradeDecision = None,
level_infra: LevelInfrastructure = None,
common_infra: CommonInfrastructure = None,
**kwargs,
):
"""
Parameters
----------
state_interpreter : Union[dict, StateInterpreter]
interpretor that interprets the qlib execute result into rl env state
action_interpreter : Union[dict, ActionInterpreter]
interpretor that interprets the rl agent action into qlib order list
start_time : Union[str, pd.Timestamp], optional
start time of trading, by default None
end_time : Union[str, pd.Timestamp], optional
end time of trading, by default None
"""
super(RLIntStrategy, self).__init__(policy, outer_trade_decision, level_infra, common_infra, **kwargs)
self.policy = policy
self.state_interpreter = init_instance_by_config(state_interpreter, accept_types=StateInterpreter)
self.action_interpreter = init_instance_by_config(action_interpreter, accept_types=ActionInterpreter)
当前qlib仅有一个真正的策略实现类:TopKDropoutStrategy,继承自ModelStrategy。
class TopkDropoutStrategy(ModelStrategy):
# TODO:
# 1. Supporting leverage the get_range_limit result from the decision
# 2. Supporting alter_outer_trade_decision
# 3. Supporting checking the availability of trade decision
def __init__(
self,
model,
dataset,
topk,
n_drop,
method_sell="bottom",
method_buy="top",
risk_degree=0.95,
hold_thresh=1,
only_tradable=False,
trade_exchange=None,
level_infra=None,
common_infra=None,
**kwargs,
):
它的核心逻辑如下:
TopK=5,表示持有分数最高的前5支股票;Drop=3,TopK好理解,就是得分最高的前N个,但DropN这个有点奇怪,代码里解释是要提高换手率,这有点不符合交易逻辑,可以把这个设置成零。
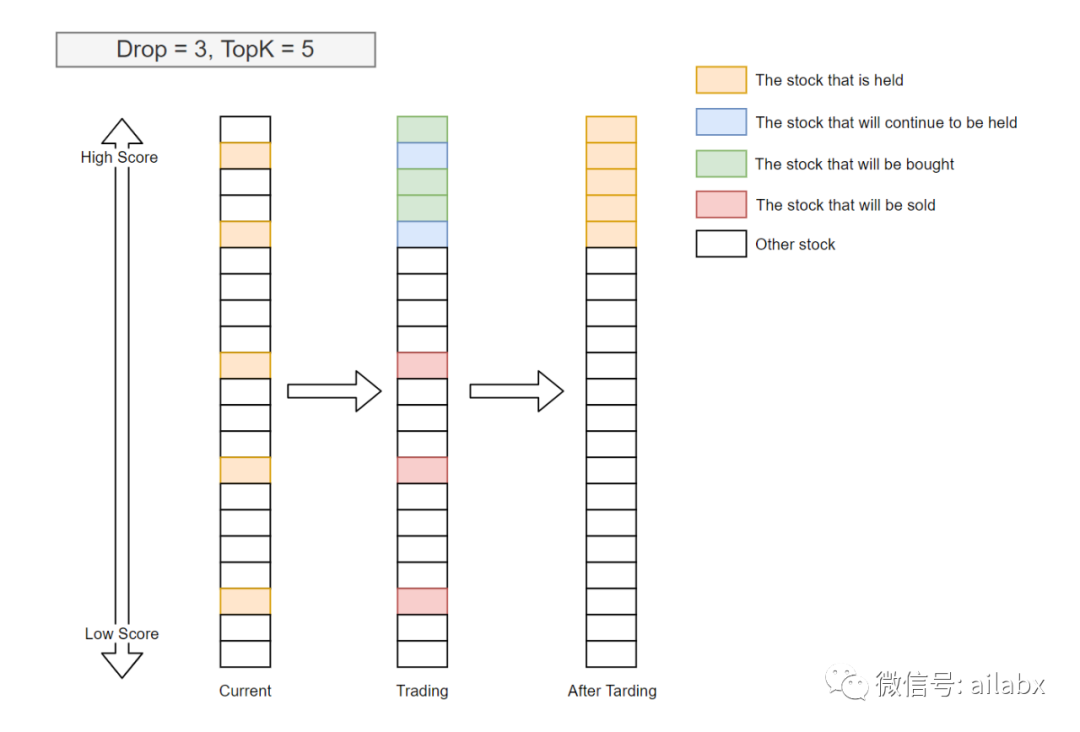
它的核心函数是generate_trade_decision,类似传统回测系统里的on_bar。
传统回测系统里的on_bar会自己调api执行这些订单,而qlib只是返回这些order_list,这样倒也简洁。
def generate_trade_decision(self, execute_result=None):
# get the number of trading step finished, trade_step can be [0, 1, 2, ..., trade_len - 1]
其实,这里的逻辑,就是“轮动”策略,传统量化里的动量轮动,我们就是取动量最大的前N名持有。区别在于,根据当前的bar的指标,规则选择,但多支股票轮动最终一定会有一个排序,就是类似这个topK的逻辑。而规则就是模型给出的pred_score。
最后backtest_loop,调用strategy每一步产生交易订单,交给执行器去执行。
with tqdm(total=trade_executor.trade_calendar.get_trade_len(), desc="backtest loop") as bar:
_execute_result = None
while not trade_executor.finished():
_trade_decision: BaseTradeDecision = trade_strategy.generate_trade_decision(_execute_result)
_execute_result = yield from trade_executor.collect_data(_trade_decision, level=0)
bar.update(1)
客观讲,qlib这一块写得不好,也是我打算使用自己的回测引擎的原因。我仔细读过像Backtrader,PyalgoTrade的源码,不知为何qlib重新造了一个逻辑不太一样的轮子。
















 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











