







原创文章第70篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。
百天100进行了2/3,期间有过一些反复。100天看似很短,但足以让你完成一件有意义的具体的事情。更何况1000天,也就是三年。
往回看看三年,弹指一挥间。
春去冬来又一年,随着惯性走,人生是没有掌控力的。
持续动动,不断复盘。
路上看到李笑来的一篇文章,回顾了他自己的成长史。他讲了在新东方的七年,身边每每有同事走向美国,寻求更大的空间。他当时也是一心想往外走,甚至觉得这些同事也未必比他强。后来三年,五年,他的想法变了。
“价值是需要很长时间才能显现出来的东西”。所以,一件事情,持续做,越到后边越有价值,才会领略到不一样的风景。
跳来跳去,其实你看到的世界都“类似”。然后你就得到一个看似深刻,其实非常“肤浅”的结论。
“悲观者往往正确,而乐观者成功”。因为乐观者行动,而悲观者都是事后诸葛,说看吧,股市又跌破三千点了。其实不说别人,这些年现金分红了多少,顶底之间有人套现了多少。
越到宏观越没有意义,人终有一死,那个折腾个啥。
但人生的意义本就在于过程,活出生命的宽度和深度。若一句有效市场,说全盘否定了技术面,基本面,甚至内幕消息,显然是不对的。这个市场上有多少抓住了一段时间的“失效”,而只要你用心,这个世界到处充满了无效,而正是这些行动者,才让市场变得有效,这个过程中,他们收获了财富,认知。
今天继续说backtrader,这个框架是真正可以实战且适用性很广。
01 backtrader
backtrader于 2015年开源,在众多的开源框架,bt算最为成熟的一个。
使用backtrader框架开发量化策略的基本步骤如下:

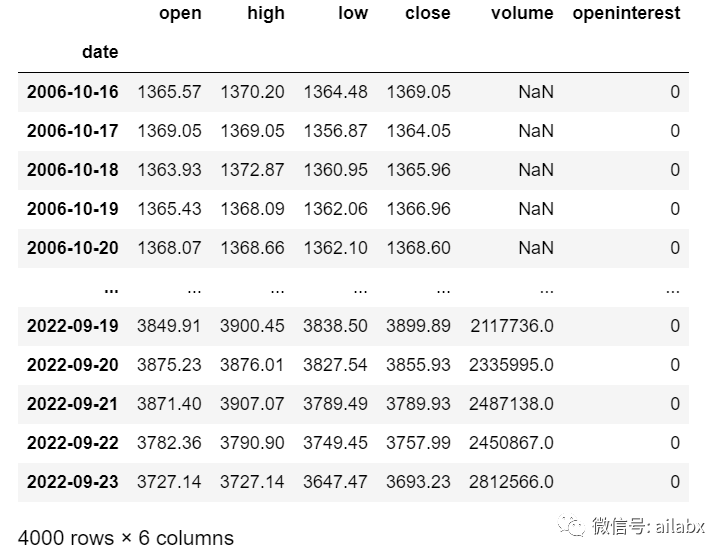
在cerebro准备好的基础上,我们要准备数据,从csv加载ohlcv数据之后,注意要转为bt的格式,index是pandas的datetime类型;openinterest列必须要存在。
def to_backtrader_dataframe(df):
df.index = pd.to_datetime(df.index)
df['openinterest'] = 0
df = df[['open', 'high', 'low', 'close', 'volume', 'openinterest']]
return df
加载后得到这样的数据格式即可:
而后把数据“喂”给“大脑”即可。这里使用bt.feeds.PandasData,可以自定义起始时间,可以添加多个数据。
from datetime import datetime start = datetime(2010,1,1) end = datetime.now().date() data = bt.feeds.PandasData(dataname=df, name='SPX', fromdate=start, todate=end) cerebro.adddata(data) # Add the data feed
02 编写策略
所有的交易策略都是写在自定义的策略类里,
如下面的 TestStrategy 类,自定义的策略类名称可以任意取,但必须继承 Backtrader 内置的 Strategy 类,即 bt.Strategy 。相当于是给大家提供了一个策略接口,大家只需调用这个接口,专心编写自己的策略,而无需关心接口的具体内容。
策略有两个函数__init__,做一些全局性的准备,比如计算指标;next相当于其它平台的onbar,逐个bar计算。
class MyStrategy(bt.Strategy):
# 定义我们自己写的这个 MyStrategy 类的专有属性
def __init__(self):
'''必选,策略中各类指标的批量计算或是批量生成交易信号都可以写在这里'''
pass
# 构建交易函数: 策略交易的主体部分
def next(self):
'''必选,在这里根据交易信号进行买卖下单操作'''
print(self.data.close[0])
03 数据篇
前面我们把标准的OHLCV的多个数据导入了。
我们更关心如何灵活地应用。
策略里的self.datas属性,就是我们传入的多个PandasData,以list的形式存在:self.datas[0] = self.data0 = self.data
还可以通过self.getdatabyname(‘spx’)来获取data对象。
这就是“约定大于配置”,以及元编程的厉害之处。
你如果使用debug看bt的数据结构是非常难看懂的,但用是真的好用,要熟悉它的逻辑。
如果说data就是一个表格的话,那data是由lines构成的,line就是一列。
print('line aliases', self.data0.getlinealiases())
使用getlinealiases()可以取到所有的列名。
line aliases ('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime')

这里有一点值得注意,如果添加了两上pandas data,两者的起始点不一样,最日期大的,就是日期上取交集。
line的取法和很多种表达,一般使用self.datas[X].close[0], 0表示当前日期,-1表达昨天,-2是前天,依此类推。取多个数据,可以使用self.datas[X].close.get(ago=0,size=N)来取,但如果超过当前已经有的bar,会返回空的array。
print(self.datas[0]._name)
print('datetime的使用', self.data0.datetime[0], self.data0.datetime.date(0), self.data0.datetime.date(1))
print(self.data1.close[1], self.data1.datetime.date(-5), self.data1.lines.datetime.date(0))
print('next===>data0.lines.close', self.data.datetime.date(0), self.datas[0].close[0], self.data[-1],
self.data[-2])
print('get====>data0.lines.close', self.data0.datetime.date(0),self.data0.get(ago=0,size=2))
datetime比较特殊,datetime这个line不是日期型,人读不出意思。需要使用datetime.date(0),注意这里是小括号。
如何添加额外的列,比如回测的时候,我们需要添加pe, pb,北向资金等。
class PandasData_more(bt.feeds.PandasData):
lines = ('amount', ) # 要添加的线
# 设置 line 在数据源上的列位置
params=(
('amount', -1),
)
# -1表示自动按列明匹配数据,也可以设置为线在数据源中列的位置索引 (('pe',6),('pb',7),)
明天继续说指标的使用。
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











