







持续行动1期 57/100,“AI技术应用于量化投资研究”。
上一周,我们把backtrader快速介绍了一下,基础功能和一些有用的扩展。可以这么说,传统量化使用backtrader就够了,而前沿的机器学习量化qlib更合适。但qlib的回测功能偏弱。
之前在lightGBM+158个技术因子实证A股十年数据:年化24%,回撤10%,我们介绍了多因子模型,然后lightGBM有效因子筛选与qlib自定义handler把158个因子“精简”为15个,依然取得不错的超额收益。
但上述的模型在实盘中仍然不好操作,原因是它经常交易50支以上的股票,而且由于计算量大,单机训练已经很吃力了。
今天我们要把沪深300的股票池换成全球指数,A股,港股,美股等以及A股里重要的行业指数,像消费、科技、医药、证券等等。
01 数据准备
如所有机器学习项目一样,数据准备都是一项耗费精力的事情。
好在我们把数据聚焦在OHLCV上,而且专注在指数上,那么数据量就少很多,使用csv就可以轻松管理——很多时候,工程复杂性是随数据量级攀升的。
tushare上的指数有8000多支,还未必全。像基金一样,指数是股票的各种排列组合,数量比股票多得多。
我们选几支核心指数就够了,取A股指数日线:
def get_index_daily(code):
# 拉取数据
df = pro.index_daily(**{
"ts_code": code,
"trade_date": "",
"start_date": "",
"end_date": "",
"limit": "",
"offset": ""
}, fields=[
"ts_code",
"trade_date",
"close",
"open",
"high",
"low",
# "pre_close",
# "change",
# "pct_chg",
"vol",
"amount"
])
df.rename(columns={'vol': 'volume', 'ts_code': 'code', 'trade_date': 'date'}, inplace=True)
df['_id'] = df['code'] + '_' + df['date']
return df
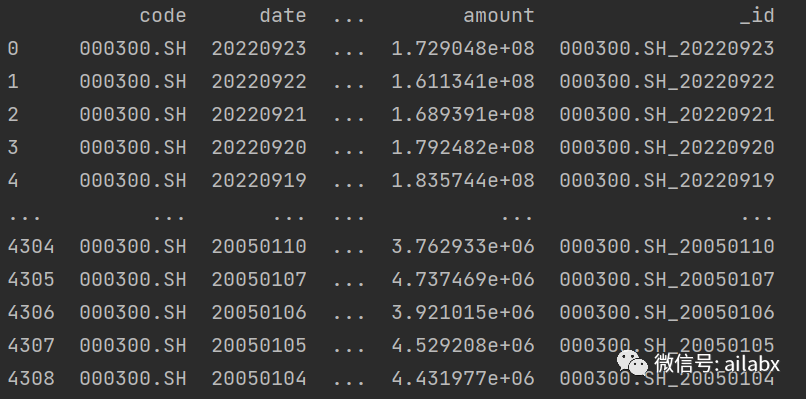
取国际主要指数日线:
def get_global_index_daily(code):
# 拉取数据
df = pro.index_global(**{
"ts_code": code,
"trade_date": "",
"start_date": "",
"end_date": "",
"limit": "",
"offset": ""
}, fields=[
"ts_code",
"trade_date",
"open",
"close",
"high",
"low",
# "pre_close",
# "change",
# "pct_chg",
"swing",
"vol"
])
df.rename(columns={'vol': 'volume', 'ts_code': 'code', 'trade_date': 'date'}, inplace=True)
df['_id'] = df['code'] + '_' + df['date']
return df
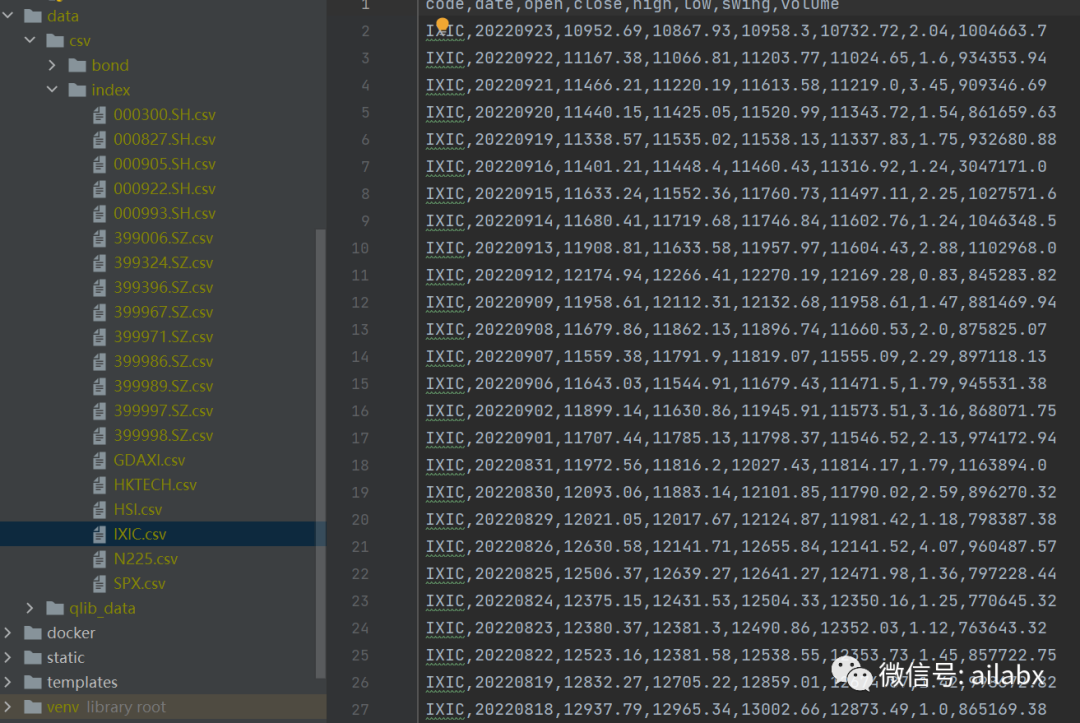
恒生指数:
国际指数6支(都是我们可以在A股市场买到的):
global_index = {
'HSI': '恒生指数',
'HKTECH': '恒生科技指数',
'SPX': '标普500指数',
'IXIC': '纳斯达克指数',
'GDAXI': '德国DAX指数',
'N225':'日经225指数'
}
A股宽基、策略及行业指数:
index = {
'000300.SH': '沪深300',
'000905.SH': '中证500',
'399006.SZ': '创业板指数',
'399324.SZ': '深证红利',
'000922.SH': '中证红利',
'399396.SZ': '食品饮料',
'399967.SZ': '中证军工',
'399997.SZ': '中证白酒',
'399998.SZ': '中证煤炭',
'000827.SH': '中证环保',
'399989.SZ': '中证医疗',
'399986.SZ': '中证银行',
'399971.SZ': '中证传媒',
'000993.SH': '全指信息',
}
全部保存成csv文件即可。
02 csv dump成qlib格式
from common.scripts.dump_bin import DumpDataAll, DumpDataUpdate
from core.config import DATA_DIR_QLIB_INDEX, DATA_DIR_CSV_INDEX
# 要写在main里,因为使用了多进程
if __name__ == '__main__':
dump = DumpDataAll(csv_path=DATA_DIR_CSV_INDEX, qlib_dir=DATA_DIR_QLIB_INDEX, exclude_fields=['code'])
dump.dump()
03 使用158因子集进行训练与回测
一共花了24s的时间加载并处理数据,若是沪深300,需要几分钟。
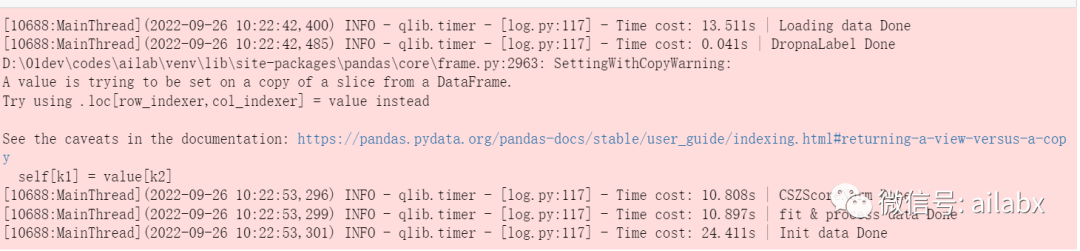
然后训练过程与之前的文章相同,目前看效果不理想。是因子的问题,还是模型参数的问题,这就是我们要解决的核心关键。
04 lightGBM回归
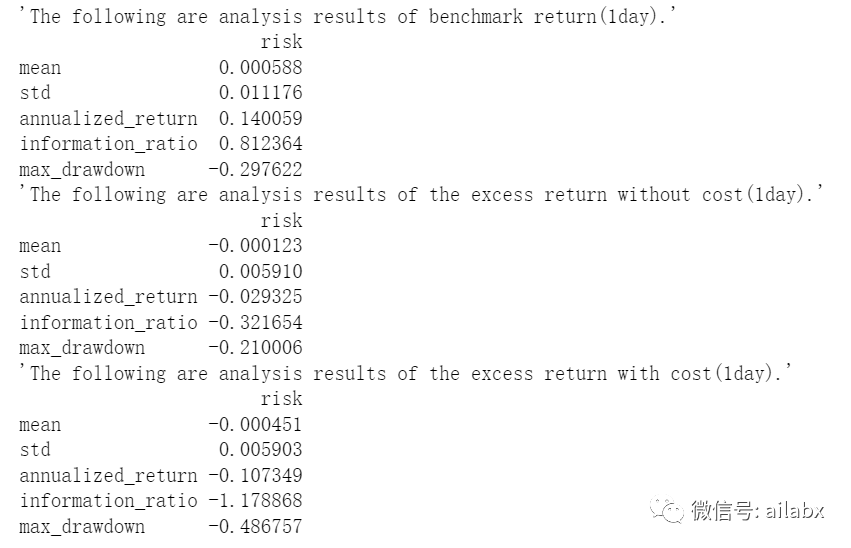
结果如预期不好。
下一步的就是机器学习应用于量化的重中之重,如何找到有效的特征,如何调优查模型等。
公众号:ailabx(七年实现财富自由)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











