






原创文章第626篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。
我们目前投入使用的因子挖掘,基于两个框架,deap和gplearn,deap做一点点改动,就可以完美应用于多标的截面因子挖掘。而gplearn如果要支持三维数据,则需要很多改动,但gplearn的优点是代码读起来很顺畅。
——也许我会考虑把gplearn应用于单标的,比如CTA的时序因子挖掘。
从结果来看,传统研报里说的IC分析,其实不科学。IC就是因子与收益率的平均相关系数。这个相关系数只能说,可能说能解释一部分,有一定的关系,但关系是什么?如果你把时间分成两段来看,有可能前半段正相关,后半段负相关,然后一平均,看起来这个值还可以。
数据说话,我用全球大类资产,使用咱们quantlab的deap框架挖掘出来的。
直接使用单因子回测来挖掘因子——metrics为年化收益和卡玛比率:
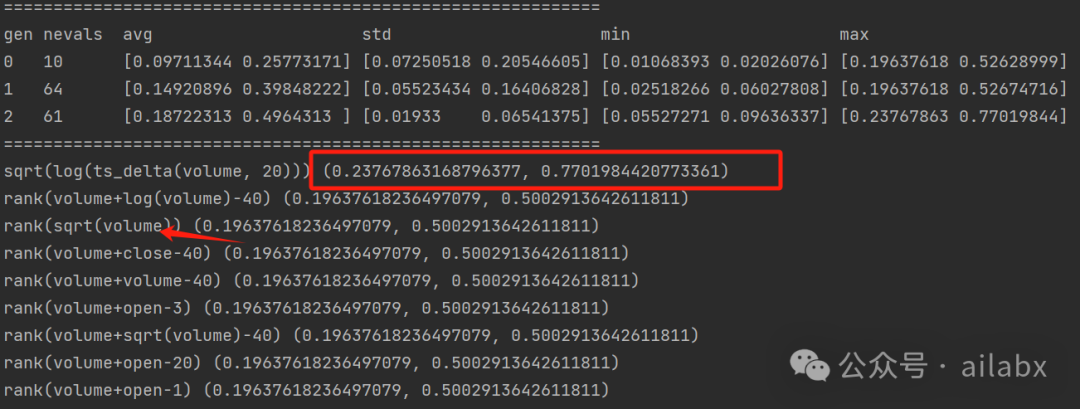
直接回测看收益表现:
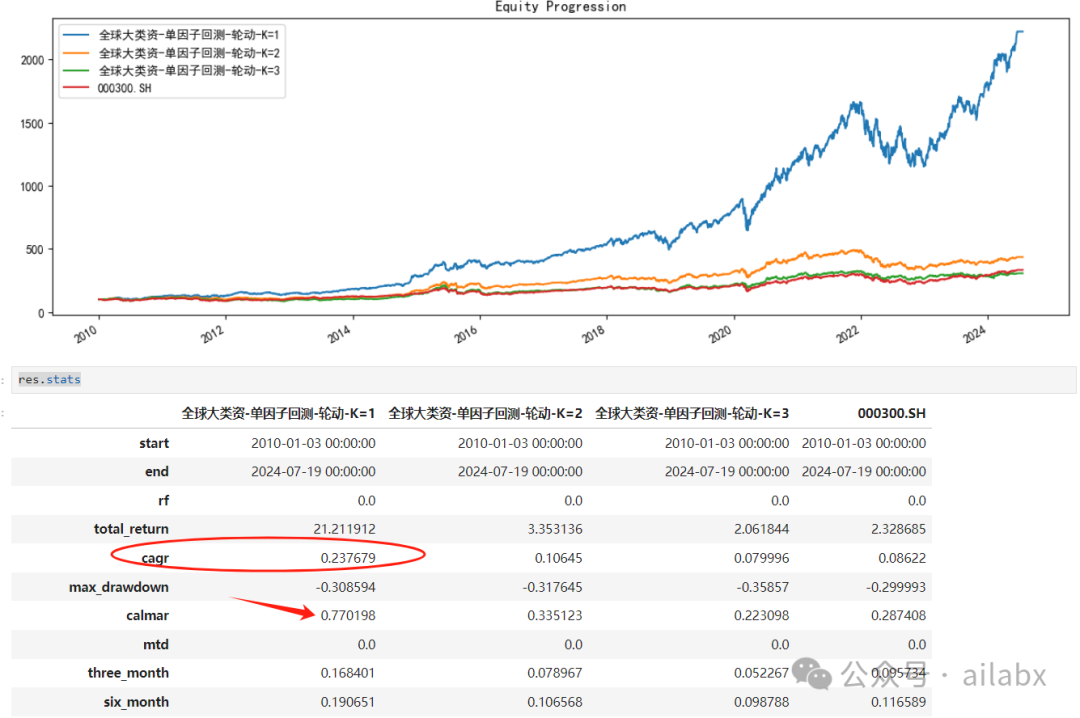
这个因子是:'sqrt(log(ts_delta(volume, 20)))'
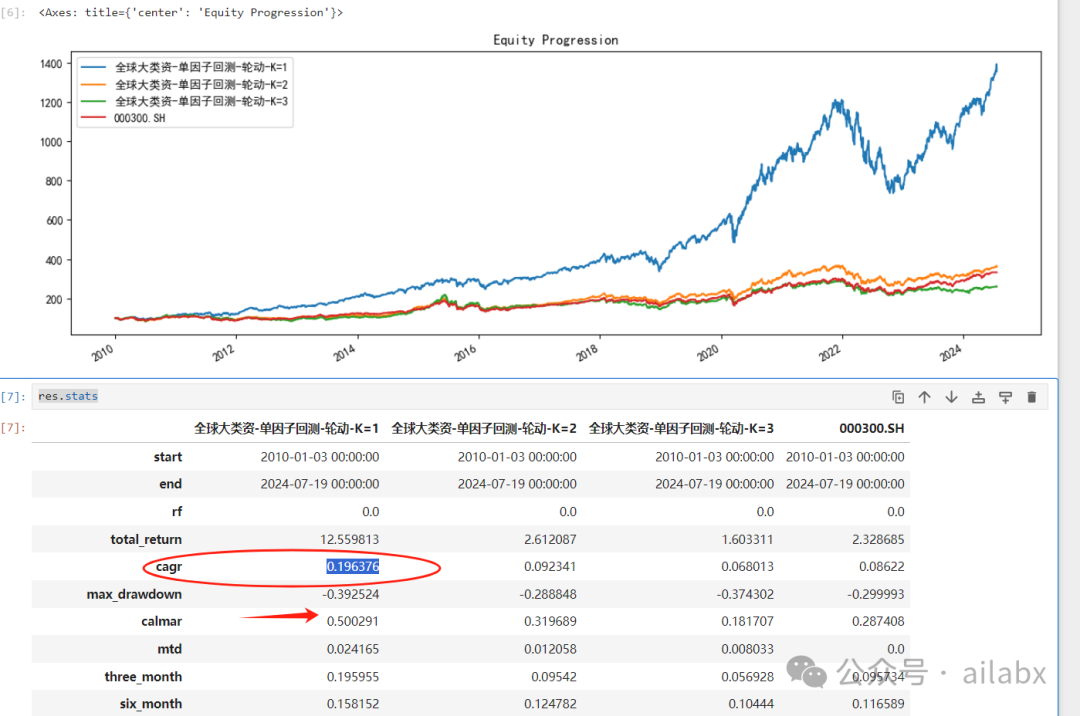
再来一个因子:rank(sqrt(volume))——成交额的截面排序因子。
这部分代码在:
更新后的回测函数:
def backtester(self,evaluate, inds):
names, features = [], []
for i, expr in enumerate(inds):
names.append(f'GP_{i:04d}')
features.append(stringify_for_sympy(expr))
features = [f.lower() for f in features]
df = CSVDataloader.calc_expr(self.df.copy(deep=True), fields=features, names=names)
# df.set_index([df['symbol'], df.index], inplace=True)
import bt
from bt_algos_extend import SelectTopK
close = CSVDataloader.get_col_df(df, 'close')
all = []
for f in names:
if f in df.columns:
signal = CSVDataloader.get_col_df(df, f)
for K in [1]:
s = bt.Strategy('{}'.format(f), [
bt.algos.RunWeekly(),
SelectTopK(signal, K),
bt.algos.WeighEqually(),
bt.algos.Rebalance()])
all.append(s)
stras = [bt.Backtest(s, close) for s in all]
res = bt.run(*stras)
stats = res.stats
print(stats.loc['cagr'])
results = []
for name in names:
if name not in df.columns:
results.append((0,0))
else:
results.append((stats.loc['cagr'][name],stats.loc['calmar'][name]))
return results
后续我们再扩展更多算子,talib的函数来提升因子挖掘效果。
吾日三省吾身
人生是旷野,而不是轨道。
时间一路向前,但人生并不是一条既定的轨道——你永远有的选。
这是上次我同一个创业的朋友说起的话题。
我的建议是,如果你是因为看好这个事情,那就坚持,但如果是因为没有选择,那就需要重新思考。人生永远有的选,至少你可以提前开始准备。
我们当下的状态,位置,是三年前或者五年前的认知、行动所决定的。
你不可能迅速改变它。
但你可以让三年、五年后的生活,如你所愿。
也许你要问,如此不确定的当下,计划都赶不上变化,大家又都说选择大于努力,那要做什么呢?
未来是一个开阔的旷野,你不必执着于某一个目标。
这里分享一个“人生设计课”里的“奥德赛计划”(《奥德赛》是古希腊诗人荷马的代表作,讲述了奥德修斯海上漂流的故事,作者借此隐喻人生如一场探险。)。

制定自己的三个五年计划,每个计划提出2-3个问题。
比如,当前的工作状态,继续往前走,这是一个最常规的计划(需要考虑如果环境有一些变动,如何应对,比如新的方向人工智能大模型——让AI发挥价值)。
比如计划2,你还可以加入量化私募公司,成为职业投资者(让AI在投资里发挥价值,当然不只是AI)。
计划3:成为自由作家(金融,财经,科技,成长),讲书人,独立研究者?——不是所谓自媒体那种,而是作品驱动,比如通过海量阅读,观察,思考,产出有价值的系列作品。
这就是旷野的逻辑,比如计划1里方向还可以有特别多,但这就算一种计划。
也许都不容易,但你会让自己感觉永远有的选,而且看起来差异很大,人就是这么有弹性,你能做的事情,比你想象中要多得多。
早上有同学问,关于续期的事情(提前90天有福利):

历史文章:
















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











