






原创内容第797篇,专注量化投资、个人成长与财富自由。
今天核心完成几件事:
1、发布aitrader4.3,带ccxt实盘接口。
2、均线能量指标及策略。
3、APP核心流程收尾:策略订阅,详情页美化。
4、生产预发布。
5、从零训练大模型之开始训练。
01 aitrader v4.3系统代码与数据更新
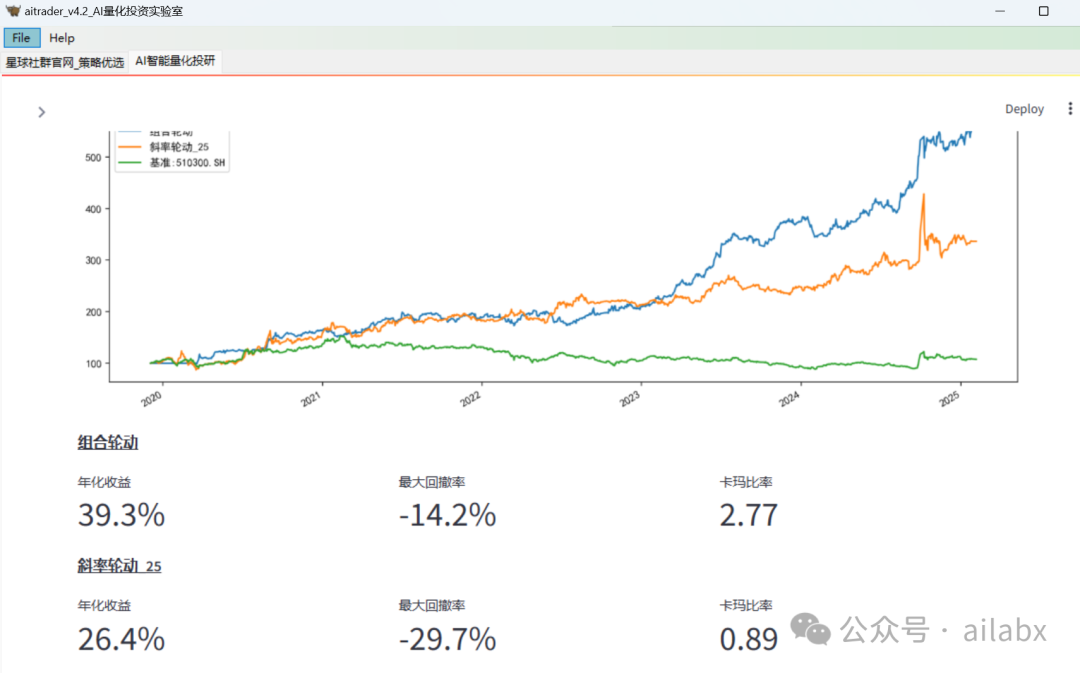
(系统运行界面)
代码包已经上传:

新增:均线能量行业轮动策略代码及数据:
from bt_algos_extend import Task, Engine
def ranking_ETFs():
t = Task()
t.name = '均线能量行业轮动'
# 排序
t.period = 'RunDaily'
t.weight = 'WeighEqually'
t.select_buy = ['ma_energy(close,20)>0']
t.select_sell = ['ma_energy(close,20)<0']
t.order_by_topK = 2
t.order_by_signal = 'ma_energy(close,20)'
t.order_by_signal = 'ts_median(ts_rank(low, 20), 10)'
t.symbols = [
'399975.SZ', # '512880.SH', # 证券ETF
'H30184.CSI', # '512480.SH', # 半导体ETF
'399976.SZ', # '515030.SH', # 新能车
'930697.CSI', # '159996.SZ', # 家电ETF
'399989.SZ', # '512170.SH', # 医药ETF
'000922.SH' # '515080.SH', # 中证红利
]
t.benchmark = '000300.SH'
return t
from config import DATA_DIR_QUOTES_INDEX
res = Engine(path='quotes_index').run(ranking_ETFs())
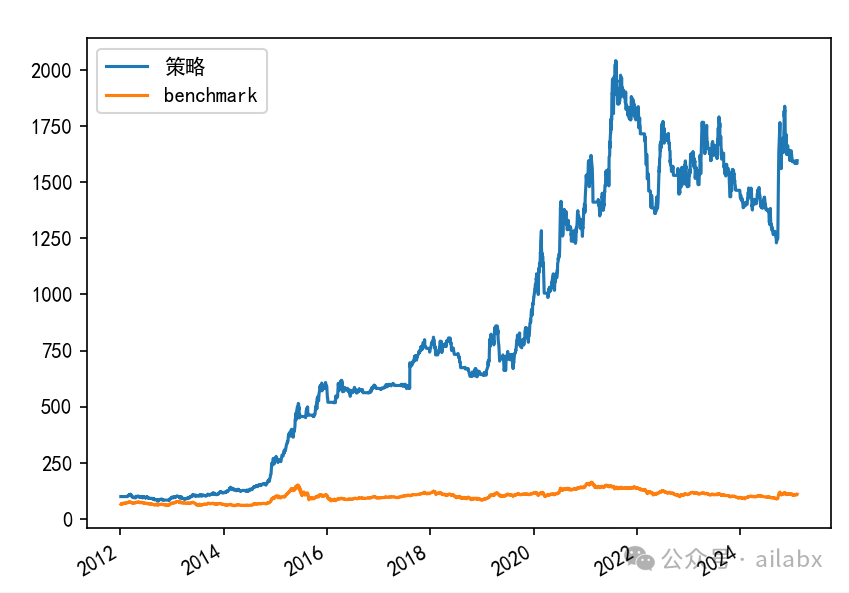
import matplotlib.pyplot as plt
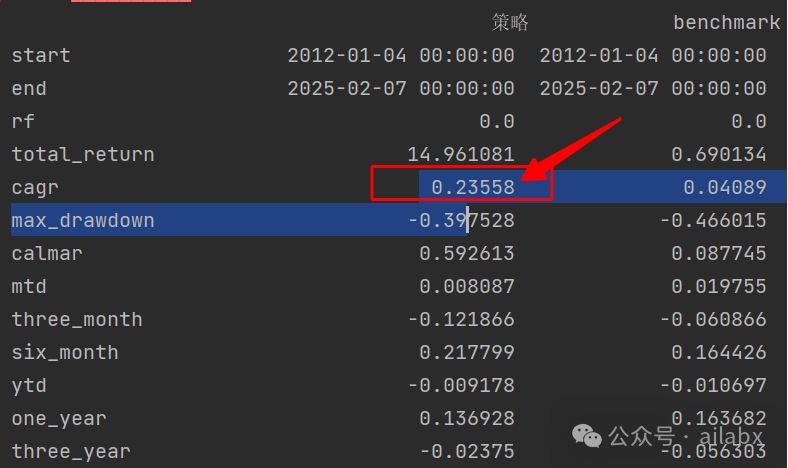
print(res.stats)
from matplotlib import rcParams
rcParams['font.family'] = 'SimHei'
# res.plot_weights()
res.prices.plot()
plt.show()
策略代码在如下位置:
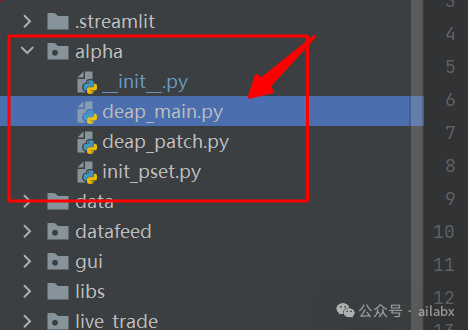
基于deap进行行业轮动的因子挖掘代码:
实盘接口补全了,可能跟很多同学想得有点不一样。大家老说能不能实盘,好像实盘接通就如何如何。
其实我们一直说,实盘其实是量化里最简单的事情,它就是工程上的事情,技术上完全是确定的。
难在你的投资体系,认知,风险把控的能力,然后对应到量化里就是因子、策略,回测,模拟盘,然后实盘。
同一个策略,有人能赚钱,有人会亏钱,不一定的策略的问题。
新增了全量指数数据:
从零训练一个类GPT大模型
首先我们确定参数量及网络结构,使用GPT2的网络结构(124M,也就是0.124B或者说1亿2千4百万参数量):
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
124M的参数量来自词嵌入、位置嵌入和12层Transformer的参数总和,其中Transformer层占主要部分(约68.4%),词嵌入次之(约31.1%)。
GPT2的代码架构如下:主体三个层 词嵌入层,位置嵌入层和12个transformer层。
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
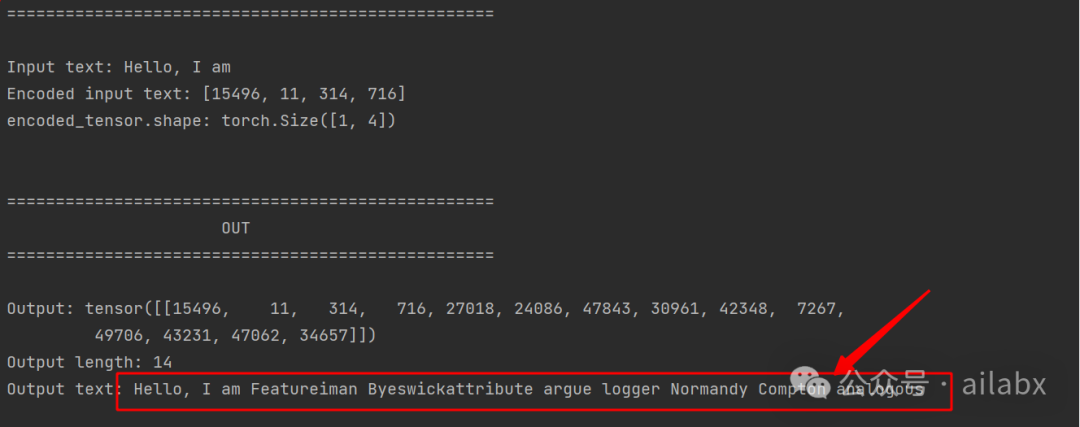
通过这个网络就可以生成文本:
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_token, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Get the idx of the vocab entry with the highest logits value
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
当然现在还是随机的值:我们需要通过语料去训练它,明天继续。
代码下载地址:

吾日三省吾身
做年初计划时,想着今年要找一些朋友聊聊天。
连接毕竟是一个很重要的事情,听听大家的近况,激发一下思绪。
有一点小感触,就是人到中年,大家都处于一个“自洽”的过程或者结果,人终究要也必须与自己和解。
“小马过河”,自己的路终归是需要自己走。
很多事情,本身没有对与不对,适合自己的,才是对的。
连接其实是价值互换,你先要有价值,自然会有有价值的连接,尤其是现在自媒体的时代。
代码和数据下载:AI量化实验室——2025量化投资的星辰大海
AI量化实验室 星球,已经运行三年多,1400+会员。
aitrader代码,因子表达式引擎、遗传算法(Deap)因子挖掘引擎等,支持vnpy,qlib,backtrader和bt引擎,内置多个年化30%+的策略,每周五迭代一次,代码和数据在星球全部开源。

扩展 • 历史文章
EarnMore(赚得更多)基于RL的投资组合管理框架:一致的股票表示,可定制股票池管理。(附论文+代码)
deap系统重构,再新增一个新的因子,年化39.1%,卡玛提升至2.76(附python代码)
deap时间序列函数补充,挖掘出年化39.12%的轮动因子,卡玛比率2.52
年化19.3%,回撤仅8%的实盘策略,以及backtrader整合CTPBee做实盘(附python代码和数据)
近四年年化收益19.3%,而最大回撤仅8%,卡玛比率2.34,投资应该是一件简单的事情。(附python代码+数据)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











