






原创内容第807篇,专注量化投资、个人成长与财富自由。
昨天各位分享了一个策略思路:近五年年化23%,最大回撤14.26%,基于历史评分因子和EPO优化权重的ETF轮动策略(python代码+数据)
历史评分因子策略,咱们之前用python实现过:年化29.6%:基于ETF评分的轮动策略加止损风控版本,更稳健(python代码+数据)
咱们今天重点来实现一下EPO。
标的池是以下这些——全球大类资产以及国内市场的核心行业:
t.symbols = [ '518880.SH', # 黄金ETF '513100.SH', # 纳指ETF '159985.SZ', # 豆粕ETF '159919.SZ', # 沪深300ETF '159992.SZ', # 创新药ETF '560080.SH', # 中药ETF '515700.SH', # 新能车ETF '515790.SH', # 光伏ETF '515880.SH', # 通信ETF '512720.SH', # 计算机ETF '159740.SZ', # 恒生科技ETF ] t.benchmark = '510300.SH'
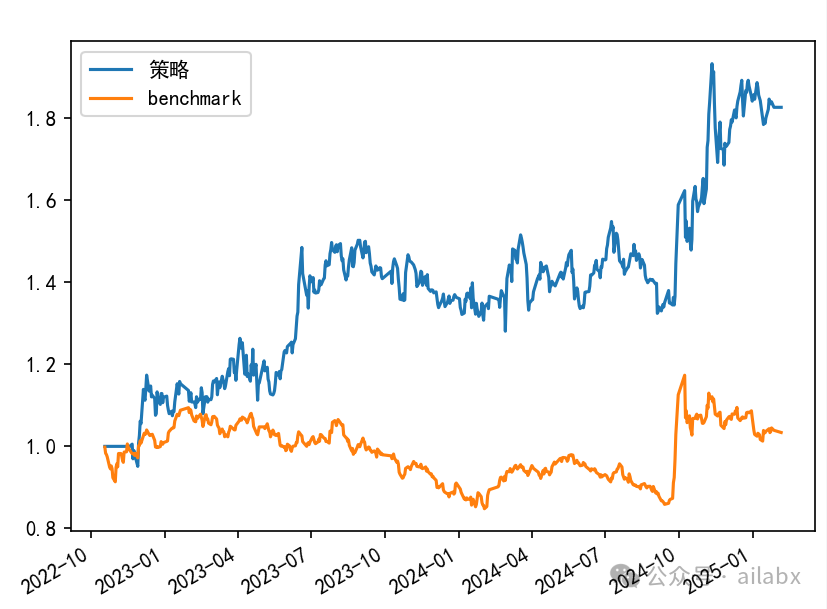
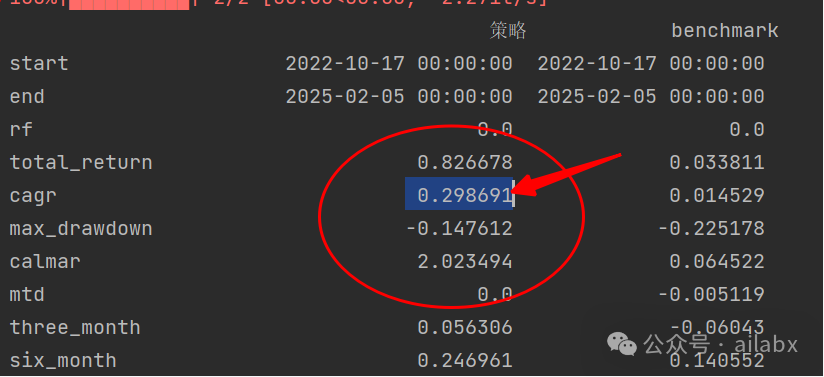
EPO算子挺复杂,我让deepseek来写:
class WeighEPO(Algo):
"""
内置锚定向量的EPO权重分配算子
Args:
* anchor_method (str): 锚定向量生成方法
- 'equal' : 等权重 (默认)
- 'vol' : 波动率倒数权重
- 'mean' : 历史收益率均值权重
- 'rvrp' : 风险平价权重
* anchor_lookback (DateOffset): 锚定向量计算窗口
* other原有参数保持不变...
"""
def __init__(self, lambda_=1.0, method="simple", w=0.5,
anchor_method='equal', anchor_lookback=None,
normalize=True, endogenous=True,
lookback=pd.DateOffset(months=3), lag=pd.DateOffset(days=0)):
super(WeighEPO, self).__init__()
# 参数验证
valid_anchor_methods = ['equal', 'vol', 'mean', 'rvrp']
if anchor_method not in valid_anchor_methods:
raise ValueError(f"Anchor method must be in {valid_anchor_methods}")
self.lambda_ = lambda_
self.method = method
self.w = w
self.anchor_method = anchor_method
self.anchor_lookback = anchor_lookback or lookback # 默认使用主lookback
self.normalize = normalize
self.endogenous = endogenous
self.lookback = lookback
self.lag = lag
def _get_anchor_data(self, target, selected):
"""获取锚定向量计算所需数据"""
t0 = target.now - self.lag
start = t0 - self.anchor_lookback
prices = target.universe.loc[start:t0, selected]
return prices.to_returns().dropna()
def _generate_anchor(self, target, selected):
"""核心锚定向量生成逻辑"""
if len(selected) == 0:
return pd.Series()
# 等权重
if self.anchor_method == 'equal':
n = len(selected)
return pd.Series(1 / n, index=selected)
# 需要收益数据的方法
returns = self._get_anchor_data(target, selected)
# 波动率倒数权重
if self.anchor_method == 'vol':
vol = returns.std()
inv_vol = 1 / vol.replace(0, 1e-6) # 防止除零
return inv_vol / inv_vol.sum()
# 收益率均值权重
if self.anchor_method == 'mean':
mean_ret = returns.mean()
return mean_ret / mean_ret.abs().sum()
# 风险平价权重
if self.anchor_method == 'rvrp':
cov = returns.cov()
try:
return pd.Series(bt.ffn.calc_risk_parity_weights(cov), index=selected)
except:
return pd.Series(1 / len(selected), index=selected)
raise ValueError("Unknown anchor method")
def __call__(self, target):
# Get selected assets and check minimum requirements
selected = target.temp.get("selected", [])
if len(selected) == 0:
target.temp["weights"] = {}
return True
if len(selected) == 1:
target.temp["weights"] = {selected[0]: 1.0}
return True
# Get required data from target
t0 = target.now - self.lag
prices = target.universe.loc[t0 - self.lookback:t0, selected]
returns = prices.to_returns().dropna()
# Get signal vector from target temp
signal = target.temp.get("signal", pd.Series(1, index=selected))
if len(signal) != len(selected):
raise ValueError("Signal vector length mismatch with selected assets")
# Covariance matrix calculation
vcov = returns.cov()
corr = returns.corr()
n = len(selected)
I = np.eye(n)
# Shrinkage correlation matrix
shrunk_cor = (1 - self.w) * corr + self.w * I # Adjusted formula
# Compute shrunk covariance matrix
std = np.diag(np.sqrt(np.diag(vcov)))
cov_tilde = std @ shrunk_cor @ std
try:
inv_shrunk_cov = np.linalg.inv(cov_tilde)
except np.linalg.LinAlgError:
raise ValueError("Singular matrix - cannot compute inverse covariance")
# Compute EPO weights
if self.method == "simple":
epo_weights = (1 / self.lambda_) * inv_shrunk_cov @ signal.values
elif self.method == "anchored":
if self.anchor is None:
raise ValueError("Anchor vector required for anchored method")
a = self.anchor.values
if self.endogenous:
gamma = np.sqrt(a.T @ cov_tilde @ a) / np.sqrt(
signal.T @ inv_shrunk_cov @ cov_tilde @ inv_shrunk_cov @ signal
)
epo_weights = inv_shrunk_cov @ ((1 - self.w) * gamma * signal + self.w * std @ a)
else:
epo_weights = inv_shrunk_cov @ (
(1 - self.w) * (1 / self.lambda_) * signal + self.w * std @ a
)
# Normalization
if self.normalize:
epo_weights = np.clip(epo_weights, 0, None) # Set negative weights to 0
epo_weights /= epo_weights.sum()
# Convert to dictionary format
target.temp["weights"] = dict(zip(selected, epo_weights))
return True
吾日三省吾身
代码和数据下载:AI量化实验室——2025量化投资的星辰大海
AI量化实验室 星球,已经运行三年多,1500+会员。
aitrader代码,因子表达式引擎、遗传算法(Deap)因子挖掘引擎等,支持vnpy,qlib,backtrader和bt引擎,内置多个年化30%+的策略,每周五迭代一次,代码和数据在星球全部开源。

扩展 • 历史文章
EarnMore(赚得更多)基于RL的投资组合管理框架:一致的股票表示,可定制股票池管理。(附论文+代码)
deap系统重构,再新增一个新的因子,年化39.1%,卡玛提升至2.76(附python代码)
低风险中等收益(年化15.59%,夏普比1.12)的投资策略,主要投资于小市值股票和基金(python代码+数据)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











