







1 cgroup 介绍
1.1 cgroup 介绍
cgroup 全称 control group,控制组。通过 cgroup 可以限制应用使用的资源,资源包括 cpu、内存、磁盘 io、网络等。
工作中经常使用的 docker 容器就使用了 cgroup 进行资源限制和隔离,cgroup 是 docker 的基础。
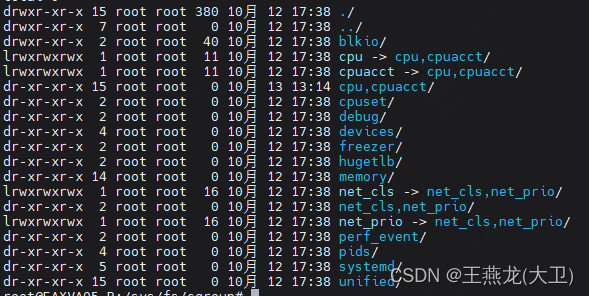
cgroup 相关的配置在 /sys/fs/cgroup 目录下,如下图所示,blkio 用于限制应用的磁盘 io,cpu 用来限制 cpu,memory 用来限制内存,cpuset 用来限制应用可以运行在哪几个核上,net_cls 可以限制应用的网络带宽。
在 cgroup 中 blkio、 cpu、 memory、 cpuset、net_cls,netprio 这些被称为一个 controller。
1.2 树状结构
cgroup 是树状结构,以 cpu 为例,/sys/fs/cgroup/cpu 是 cpu 资源限制的根节点,cpu 根节点中的 cpu.cfs_quota_us 是 -1,表示不对普通调度策略的线程做限制。
如果我们在 cpu 目录下创建一个目录 cgroup1,然后在 cgroup1 目录下创建 3 个目录,分别是 cgroup3,cgroup4,cgroup5。那么 cgroup3 ~ cgroup5 中的应用使用的 cpu 资源之和不会大于 cgroup1 中配置的资源。
树状结构的子节点的资源之和,不能大于它们的父节点的资源。假如 cgroup1 中限制的 cpu 是 100%,那么 cgroup1, cgroup3, cgroup4, cgroup5 这 4 个控制组中的进程所使用的 cpu 之和就不会超过 100%。

1.3 cgroup 使用示例
下边以 cpu 资源为例,说明 cgroup 使用的方式:
下边的代码,里边只有一个 while(1) 死循环,这个程序跑起来之后默认情况下会占用 100% 的 cpu。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main() {
while(1);
return 0;
}如果我们不想让这个代码的 cpu 使用率在 100%,想把这个程序占用的 cpu 限制在 10% 以内,那应该怎么做呢 ?
① 进入目录
cd /sys/fs/cgroup/cpu,cpuacct/
② 创建并进入 hello 文件夹
mkdir hello
cd hello/
从下图中可以看到,在 cgroup 下创建一个文件夹,和在一个普通目录下创建一个文件夹不一样,在普通目录下创建的文件夹是空的,而在 cgroup 下创建的文件夹内部默认生成了一些文件,对 cgroup 的配置就是通过操作这些配置文件来完成。linux 中很多配置都是这么实现的,一个配置文件对应一个配置,通过 echo 写配置文件的方式来修改配置。
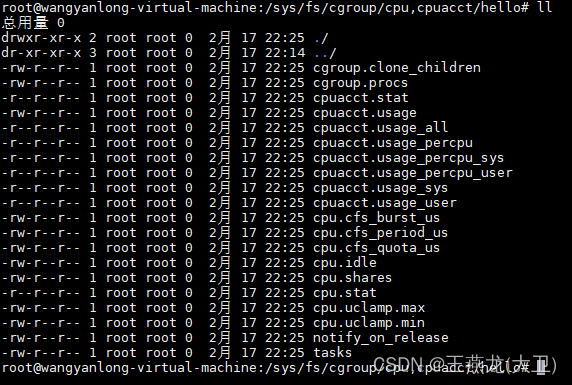
③ 设置 cpu 限制
echo 10000 >cpu.cfs_quota_us
cat cpu.cfs_period_us
100000
cpu.cfs_quota_us 和 cpu.cfs_period_us 的比值就是这个 cgroup 的 cpu 使用率。
cpu 使用率为 100% 表示应用占满了一个 cpu 核。在 linux 中,cpu 使用率是可以大于 100% 的,机器有几个 cpu 核,比如是 8,那么最大可占用的 cpu 是 800%。
④ 将进程号(pid)加入到 cgroup 中
echo xxx > cgroup.procs
执行完上述 4 个步骤之后,再使用 top 命令来查看,就能看到这个进程的 cpu 使用率在 10%。
当然也可以将多个进程号加入到一个 cgroup 里边,那么多个进程的 cpu 使用率之和会被限制在配置的资源之内。
1.4 cgroup v1 和 cgroup v2
cgroup 有两个版本,v1 和 v2。
当看到 v1 和 v2 时,我们常常会认为高版本可以完全替换低版本,各个方面都要优于低版本,并且两个版本只能二选一,不能同时使用。但是对于 cgroup v1 和 cgroup v2 来说,v2 并不能完全替换 v1,当前 ubuntu 20.04 的默认版本还是 v1,并且 v1 和 v2 可以同时使用,比如对于一个进程来说,cpu 使用 v1 来限制,blkio 使用 v2 来限制,这样也是可以的。
1.4.1 区别
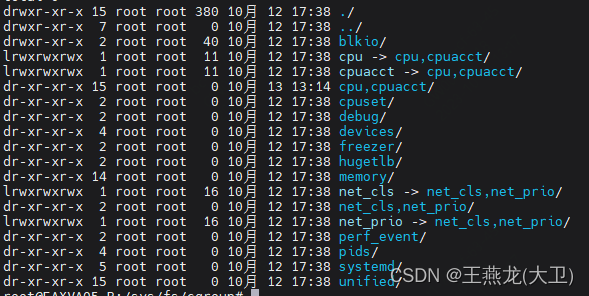
(1)cgroup v2 只有一个根节点,v1 是每种资源都对应一个根节点
这是在呈现形式上,最明显的一个区别。
cgroup v1 的根节点如下,每种资源都有一个根节点,比如 memory, cpu,如果一个应用需要限制 memory,也需要限制 cpu,那么就需要在这两个根节点下分别配置。
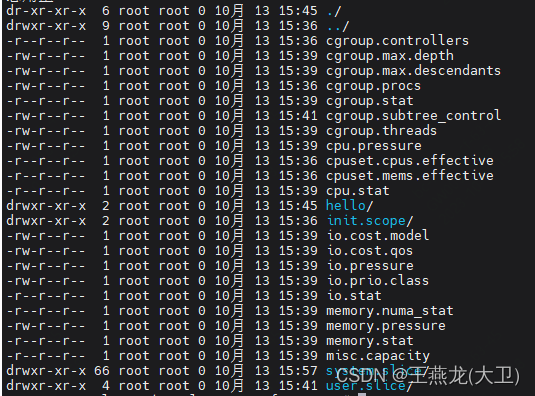
cgroup v2 只有一个根节点,应用如果想同时限制 memory 和 cpu 资源,只需要创建一个文件夹就可以,不需要每种资源都创建一个文件夹。
(2)cgroup v2 对磁盘 io 的限制更完善
cgroup v1 中 blkio 对文件读写的速率和带宽进行限制,但是这个功能不完善,只能限制 direct io 这种方式。但是我们大多数时候的使用场景是有缓存的读写,v1 中的 blkio 对这种无缓存的读写无法限制,cgroup v2 进行了完善,支持了对有缓存读写这种方式的限制。
(3)cgroup v2 没有对网络发送进行限制
本人在 cgroup v2 中没有找到 net 的 controller。如果想要对网络发送进行限制,需要使用 cgroup v1 中的 net_cls。

1.4.2 配置
cgroup v1 和 cgroup v2 的配置,在启动参数中进行配置,配置完毕之后需要重启才能生效。
ubuntu 中需要修改配置文件 /etc/default/grub。如下配置的意思是不使用 cgroup v1 中的 blkio,这个配置之后执行 update-grub,然后重启机器,就能看到 blkio 文件夹下是空的,也就是说 cgroup v1 下的 blkio 没有生效。如果需要设置 blkio 需要在 unified 下进行设置,这里相关的配置文件就是 cgroup v2 中对 io 限制的配置文件。
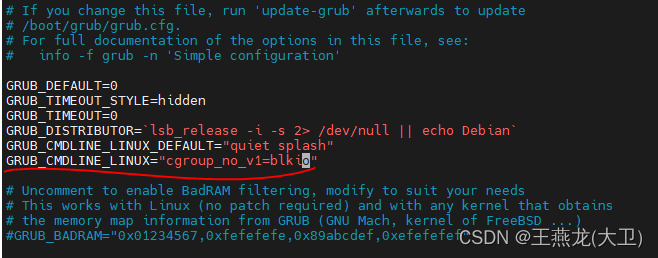
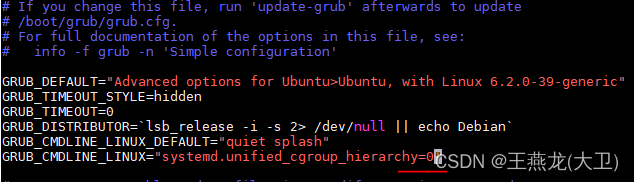
如果是在 ubuntu 22.04 的环境下,默认的 cgroup 版本是 v2 的。如果想将 v2 切回到 v1,则需要修改如下配置,该配置为 0 则是 v1,为 1 则是 v2。
2 cgroup controller
2.1 内存
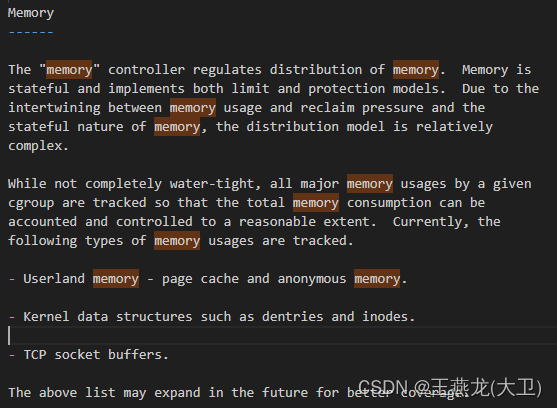
从 cgroup memory 的官方文档中可以看到,可以限制的内存种类包括以下 3 种:
(1)用户态使用的内存
page cache 和匿名内存
(2)内核态的内存,比如 dentry 和 inode 缓存
(3)tcp 缓冲区使用的内存
memory.limit_in_bytes:
用户态可以申请的内存的最大值。
memory.memsw.limit_in_bytes:
可以使用的内存和 swap 内存之和的最大值。
memory.memsw.limit_in_bytes 的值不能小于 memory.limit_in_bytes。
比如设置 memory.limit_in_bytes 为 1G,设置 memory.memsw.limit_in_bytes 为 2G,那么应用使用内存超过 1G 的时候就会使用 swap 内存,内存和 swap 内存之和最多可以使用 2G。
memory.usage_in_bytes:
显示当前使用的内存。
memory.memsw.usage_in_bytes:
显示当前使用的内存和 swap 之和。
在实际使用中往往只设置 memory.limit_in_bytes,memory.memsw.limit_in_bytes 在默认情况下是一个极大的值。这样的话,当内存使用达到限制之后,便会使用 swap 内存。
在测试中发现,memory.memsw.usage_in_bytes 至少要比 memory.usage_in_bytes 大 200k 以上,swap 才能生效,如果后者设置为 200k,前者设置为 400k,那么 swap 是不生效的,前者设置为 500k,那么会用 100k 的 swap。
memory.oom_control:
默认情况下如果应用使用的内存超过了 memory.memsw.limit_in_bytes 中设置的值,会被 kill 掉。

如果使用 echo 1 > memory.oom_control 将 oom kill disable 掉,那么当内存使用达到 memory.memsw.limit_in_bytes 时,应用不会被 kill 掉,应用会被 hung 住,查看进程的状态是 D 状态。

memory.kmem.tcp.limit_in_bytes:
tcp 缓冲区使用的内存。
2.3 io
io 是限制应用读写磁盘的速率,有 4 个参数可以设置:
wbps: 每秒可写的字节数
rbps: 每秒可读的字节数
wiops: 每秒写次数
riops: 每秒读次数
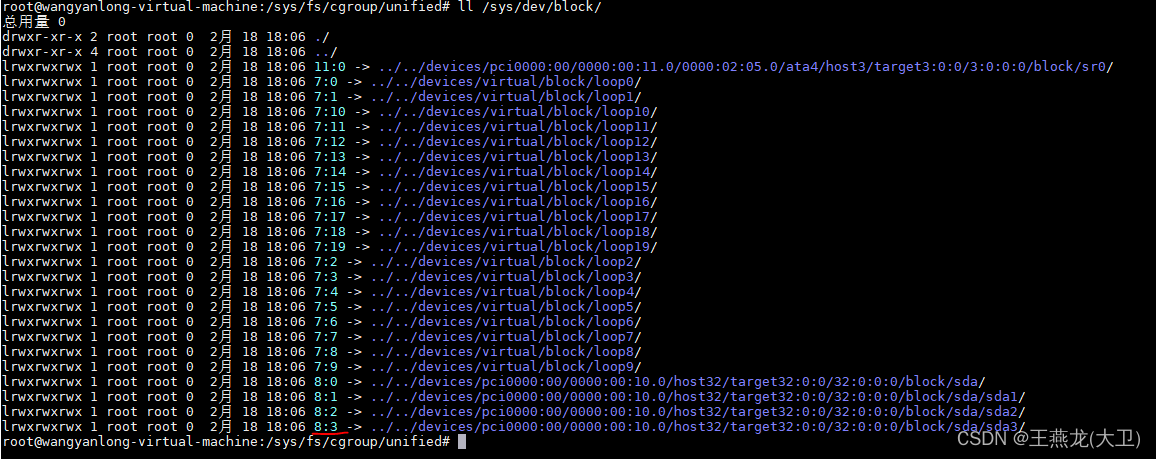
另外,设置 io 的时候,还需要指定 block 设备号,如下图所示,在 /sys/dev/block 下边显示机器中所有的块设备。设备号即下边的 8:3, 8:2 这些。
blkio 需要使用 v2:
cgroup v1 中 blkio 对文件读写的速率和带宽进行限制,但是这个功能不完善,只能限制 direct io 这种方式。我们大多数时候的使用场景是有缓存的读写,v1 中的 blkio 对这种无缓存的读写无法限制,cgroup v2 进行了完善,支持了对有缓存读写这种方式的限制。
2.2 cpu
对 cpu 的限制和调度策略有关,普通调度策略和实时调度策略的配置参数是分开的,并不是设置一个参数,这个进程内的所有线程,不管是什么调度策略都能限制。
普通调度策略:
cpu.cfs_period_us: 分配时间的间隔,默认是 100000, 也就是 100ms,每隔 100ms 分配一次时间
cpu.cfs_quota_us:在 period 内分配多长的时间,设置为 -1,意思为不做限制。
如果想让一个进程完全使用两个 cpu,则配置如下:
cpu.cfs_period_us=100000,cpu.cfs_quota_us=200000
上述这两个参数的单位是 μs,下限是 1000,不能设置小于 1000 的值
rt 调度策略:
cpu.rt_period_us
cpu.rt_runtime_us
rt 的这两个参数与 cfs 的两个参数意思类似
如果进程已经占用了 100% 的 cpu,这个时候修改限制值,进程实际占用的 cpu 会随着限制值变化而变化。
2.2.1 CONFIG_RT_GROUP_SCHED
如果想要支持对 rt 调度策略的限制,需要在编译内核时打开这个配置。
2.2.2 实时调度策略 cpu 最大比例
实时调度策略的优先级是高于普通调度策略的。当有实时调度策略的线程在运行时,普通调度策略的线程是得不得机会运行的。如果系统中所有的核都被实时线程占满,这个是后系统会卡死,想要使用 kill -9 把进程杀死也可能做不到,因为 kill -9 运行的时候也是起一个进程,这个进程也得不到机会运行。
所以内核中增加了一个配置 /proc/sys/kernel/sched_rt_runtime_us,通过这个配置可以决定实时调度策略最大能占用的 cpu 的比例,默认是 95%,这样有 5% 的时间可以运行普通线程。

2.2.3 [坑]system.slice 和 user.slice
/sys/fs/cgroup/cpu,cpuacct/system.slice/cpu.rt_runtime_us/cpu.rt_runtime_us
在有些系统中,该配置默认是 0,也就是不允许配置 rt 调度策略。而 linux 中 systemd 启动的服务如果需要配置 rt 调度策略,需要使用 system.slice 的份额。只有这个配置大于 0,systemd 启动的服务才可以配置 rt 调度策略。
systemd 启动的服务会在 system.slice 中创建一个节点,这个节点下的 cpu.rt_runtime_us 也需要配置大于 0。
/sys/fs/cgroup/cpu,cpuacct/user.slice/cpu.rt_runtime_us
我们手动启动的进程,如果要配置实时调度策略,是使用的 user.slice 中的份额。
需要该配置大于 0,手动启动的服务才可以配置 rt 调度策略。
2.2.4 单核 95% 还是整机的 95%
默认情况下,rt 调度策略只能使用 cpu 的 95%。
这里的 95% 是单核 95% 还是整机的 95% ?
假如机器有 8 个核,启动 2 个 rt 线程,如果是单核 95%,那么这两个线程每个线程都会占用 95% 的 cpu;如果是整机 95%,那么这两个线程分别能占用 cpu 的 100%,也就是说每个线程都能占满一个核,因为整机的 95% 是 800% * 0.95 = 760%,200% 还没有达到 760% 。
本人在工作中观察到的现象是:
如果内核没有配置 CONFIG_RT_GROUP_SCHED,那么就是单核 95%;
如果配置了 CONFIG_RT_GROUP_SCHED,那么就是整机 95%。
2.4 cpuset
cpuset 可以用来绑核。
cpuset.cpus:
可以设置 cgroup 的进程运行在哪些核上,
比如 echo 0-2,3 > cgroup.cpus,那那么加入到这个 cgroup 的进程就只能运行到 0, 1, 2, 3 这 4 个核上。其中 0-2 也可以写成 0,1,2, echo 0,1,2,3 > cgroup.cpus。
cpuset.mems:
可以使用 numactl --hardware 看看内存有几个 numa,这个配置是设置内存的节点。
cgroup v1 中使用 cpuset 的时候,cpuset.mems 和 cpuset.cpus 这两个配置都需要配才能使用。如果只配置了 cpuset.cpus 而没有配置 cpuset.mems,那么在向 cgroup.procs 加入进程号的时候会返回失败。
cgroup v2 中使用 cpuset 的时候,如果只配置了 cpuset.cpus 而没有配置 cpuset.mems,也是可以使用的。
2.4.1 cpuset 和绑核不一致时怎么处理
如下代码可以设置线程的亲和性。当 cpuset 和代码中的亲和性不一致时,是什么现象 ?
int32_t set_affinity(int8_t cpu_no)
{
cpu_set_t cpuset;
pthread_t thread;
CPU_ZERO(&cpuset);
CPU_SET(cpu_no, &cpuset);
thread = pthread_self();
if (pthread_setaffinity_np(thread, sizeof(cpuset), &cpuset) != 0)
{
printf("worker binding core failed, cpu_id %u\n", cpu_no);
return -1;
}
return 0;
}以 cpuset 为准,无论 cpuset 是先操作的还是后操作的,都是以 cpuset 为准。
(1)先加入 cpuset, 后通过 pthread_setaffinity_np() 设置亲和性,如果不一致,则设置失败。
(2)代码中先通过 pthread_setaffinity_np() 设置了亲和性,后加入到 cpuset 中,如果不一致,则以 cpuset 为准。
2.5 网络带宽
cgroup 中的 net_cls 可以用于限制应用发送侧的网络带宽。
其中要借助内核的 tc (traffic classifier) 来实现,cgroup net_cls 和 tc 关联的桥梁是一个 classid。
如下是一个官方的例子:
https://www.kernel.org/doc/Documentation/cgroup-v1/net_cls.txt
cd /sys/fs/cgroup/net_cls
mkdir hello
cd hello
echo 0x100001 > net_cls.classid
id 的格式是 0xAAAABBBB,其中 AAAA 是 major handle number,BBBB 是 minor handle number。
tc qdisc add dev ens33 root handle 10: htb
tc class add dev ens33 parent 10: classid 10:1 htb rate 40mbit
上边连个指令,设置将发送速率限制在 40mbit/s。

















 2947
2947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









