







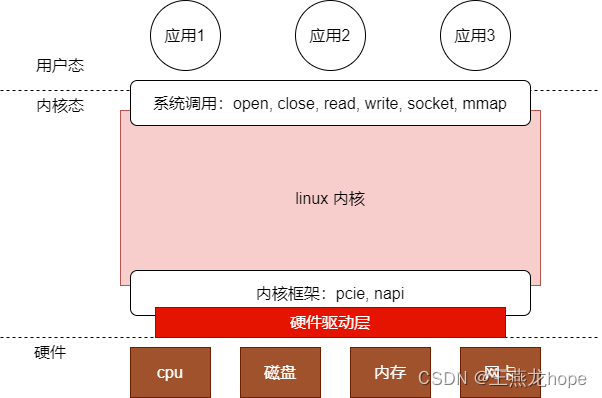
linux 操作系统一般指 linux 内核。在 linux 上开发应用的时候,可以使用 linux 提供的系统调用。linux 内核管理着机器上的硬件资源:内存,磁盘,网卡等。开发应用的时候不能直接操作这些硬件,而只能通过系统调用来使用这些资源。linux 系统调用可以说是 linux 内核提供给上层的一些接口。这种内核和用户隔离的机制保证了安全性的同时,也简化了应用的开发。
linux 内核除了给上层应用提供了接口之外,给底层的硬件驱动也提供了框架和机制。在 linux 中开发驱动的时候,硬件驱动也可以看做是 linux 内核的应用层,不过和用户态应用相比,硬件驱动工作在内核态。
linux 内核的用户有两个部分,一个是用户态的程序,一个是底层的硬件驱动。
1 基础收包方式
在讨论 io 模型时,经常讨论阻塞,非阻塞,同步,异步的 io 模型。在网卡收包方面,有两种基础的收包方式,分别是中断和轮询。中断和轮询的工作机制与 io 模型是有些类似的,中断是异步的,轮询是同步非阻塞的的。
1.1 中断
中断方式是软件和硬件交互的基本方式。在 linux 中,中断的优先级是最高的,高于线程也高于软中断。
中断的优点是实时性好(谁都可以打断),适用于网络流量不是很大的场景。如果网络流量很大的话,那么 cpu 就会一直陷入网络报文的处理中,其它中断和其它任务得不到机会运行。
当内核线程被中断打断时,调用中断服务例程之前还要保存当前线程的寄存器和栈信息。如果中断太多的话会造成频繁的线程上下文和中断之间的切换,上下文切换也会造成 cpu 的浪费。
1.2 轮询
中断方式是硬件主动通知软件,轮询方式是软件主动查询硬件。轮询收包的方式,一般会有一个线程,这个线程中是一个 while(1) 死循环,在死循环中会通过读网卡的寄存器来判断当前接收队列中有没有包,如果有包的话便会从接收队列中接收报文。
使用轮询方式收包,不会有线程和中断之间的上下文切换。轮询方式适用于网络流量比较大的场景,因为轮询方式会占满一个 cpu,如果网络流量很小的话,那么线程会有很多空转的情况,造成 cpu 资源的浪费。一些网络专用设备,比如路由器,核心工作就是转发报文,不像服务器上会跑很多业务,路由器的功能比较单一, 所以在路由器上使用轮询的方式,即使一直占着 cpu,也不会影响其它应用,因为路由器上其它的应用很少。DPDK 中使用了轮询的方式来收包。
2 napi
napi 的名字全称是 new api,一个新的 api,这样的名字并不是很直观。在软件开发中起名字是很困难的事情,从 napi 也可以看出来,即使在 linux 中,也有这样不是很直观的名字存在。
从上边的分析中也可以看出来,中断方式收包和轮询方式收包,各有优缺点。中断方式收包的优点是响应快,缺点是只能适用于流量较小的场景,如果在流量较大的场景下使用中断方式收包,网络中断会影响系统其它任务的执行。轮询方式收包的优点是不会有线程和中断之间的上下文切换,缺点是当流量较小的时候,会造成 cpu 资源的浪费。
所以中断收包适用于流量较小的场景,轮询适用于流量较大的场景。
napi 收包方式中既有中断,也有轮询,集成了中断和轮询的优点。
本文中以 ixgbe 网卡为例进行记录。
2.1 napi 框架
软中断收包:
使用 napi 来接收报文是在软中断中处理的。硬中断服务例程中只做很少量的工作,做完之后硬中断立即返回,报文后续的处理在软中断重处理。
(1)硬中断会调用函数 napi_schedule_irqoff(),最终会调用到函数 ____napi_schedule(),在该函数中做两件事
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}① 将 napi 加到数据结构 struct softnet_data 中,struct softnet_data 是一个全局的数据结构,是 per cpu 类型的。在软中断中处理的时候便会从 struct softnet_data 中找到挂接的 napi,从 napi 找到处理函数,然后进行收包。
② 触发 NET_RX_SOFTIRQ 软中断
struct napi_struct:
/*
* Structure for NAPI scheduling similar to tasklet but with weighting
*/
struct napi_struct {
/* The poll_list must only be managed by the entity which
* changes the state of the NAPI_STATE_SCHED bit. This means
* whoever atomically sets that bit can add this napi_struct
* to the per-CPU poll_list, and whoever clears that bit
* can remove from the list right before clearing the bit.
*/
struct list_head poll_list;
unsigned long state;
...
int (*poll)(struct napi_struct *, int); NAPI_STATE_SCHED
int weight;
...
};
struct napi_struct 中重要的成员有 4 个。
| weight | napi 一次可以处理的报文个数,在软中断中收包是轮询的方式。如果网络流量很大,那么会一直轮询收包吗 ? 不会的,为了网络不影响系统中其它任务的执行,napi 每次接收报文的数量是有上限的,当接收的的报文数量达到上限时,即使网卡接收队列中有报文,也不再继续处理了,而是让出 cpu,等下次软中断处理时再进程接收。 保证了收包任务和系统其它任务的公平性。 |
| poll | 函数指针,使用 napi 的网卡将网卡的收包函数挂到这个指针上。 |
| state | napi 的状态, NAPI_STATE_SCHED 状态说明 napi 是可以工作的。 |
| poll_list | 上边也说了,napi 通过 poll_list 与 struct softnet_data 进行关联。 |
netif_napi_add():
网卡驱动中会调用这个函数对网卡使用 napi 进行初始化。包括挂接 poll 函数,初始化 weight。
void netif_napi_add(struct net_device *dev, struct napi_struct *napi,
int (*poll)(struct napi_struct *, int), int weight)2.2 网卡驱动使用 napi
struct ixgbe_q_vector 可以看作网卡的一个接收队列。在 struct ixgbe_q_vector 中有一个成员 struct napi_struct napi。
struct ixgbe_q_vector {
...
struct napi_struct napi;
...
};在初始化中断时,中断的参数是 struct ixgbe_q_vector * 指针类型,所以在中断处理函数中能通过 q_vector 找到 napi,从而可以将 napi 挂接到 struct softnet_data 中,进而被软中断处理。
static int ixgbe_request_msix_irqs(struct ixgbe_adapter *adapter)
{
...
err = request_irq(entry->vector, &ixgbe_msix_clean_rings, 0,
q_vector->name, q_vector);
...
return err;
}
从下边的代码中可以看出来,ixgbe 网卡的 napi 收包函数是 ixgbe_poll(),weight 是 64。
static int ixgbe_alloc_q_vector(struct ixgbe_adapter *adapter,
int v_count, int v_idx,
int txr_count, int txr_idx,
int xdp_count, int xdp_idx,
int rxr_count, int rxr_idx)
{
...
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi,
ixgbe_poll, 64);
...
}2.3 网卡收包过程分析
网卡收包过程分为两个阶段,第一阶段是硬中断处理,第二阶段是软中断处理。
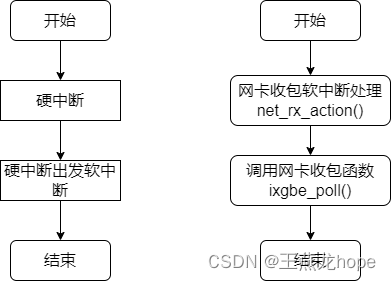
2.3.1 硬中断
ixgbe_msix_clean_rings() 是 ixgbe 网卡的中断服务例程。从注释来看,调用这个函数的时候,中断是关闭的,所以调用函数 napi_schedule_irqoff() 来调度 napi。
static irqreturn_t ixgbe_msix_clean_rings(int irq, void *data)
{
struct ixgbe_q_vector *q_vector = data;
/* EIAM disabled interrupts (on this vector) for us */
if (q_vector->rx.ring || q_vector->tx.ring)
napi_schedule_irqoff(&q_vector->napi);
return IRQ_HANDLED;
}对于一个 napi 来说,将这个 napi 调度,就是将这个 napi 设置状态 NAPI_STATE_SCHED,只有设置了这个状态,软中断处理流程中才会处理这个 napi,否则不处理。
对于一个 napi,在同一时刻只允许调度一次,不允许多次调度。函数 napi_schedule_prep() 就是判断 napi 是不是已经被调度,如果是的话返回 false,否则返回 true。
/**
* napi_schedule_irqoff - schedule NAPI poll
* @n: NAPI context
*
* Variant of napi_schedule(), assuming hard irqs are masked.
*/
static inline void napi_schedule_irqoff(struct napi_struct *n)
{
if (napi_schedule_prep(n))
__napi_schedule_irqoff(n);
}在硬中断服务例程中,最终调用到函数 ____napi_schedule(),在该函数中做两件事:将 napi 挂接到 struct softnet_data 中,触发软中断。
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
2.3.2 软中断
函数 net_rx_action() 是收包软中断的入口函数。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
// softnet_data 是全局的数据结构,是 per cpu 类型的
// 在硬中断中将 napi 挂在了 softnet_data 中
// 在这里将 napi 取出来进行处理
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
// 软中断处理的最长时间
unsigned long time_limit = jiffies +
usecs_to_jiffies(READ_ONCE(netdev_budget_usecs));
// 软中断处理的最大报文个数
int budget = READ_ONCE(netdev_budget);
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
// 调用网卡的 poll 函数进行收包
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
// 当处理的报文数量超过 budget 或者处理的时间超过限制的时候
// 停止处理,保证内核任务的公平性
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
// 如果 softnet_data 还没处理完,那么再次触发软中断
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}函数 napi_poll() 中调用 napi 中的 poll 函数指针来收包。对于 ixgbe 网卡来说,对应的函数是 ixgbe_poll()。
static int napi_poll(struct napi_struct *n, struct list_head *repoll)
{
...
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n, work, weight);
}
...
}













 2535
2535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









