






 这篇综述论文探讨了X射线安检图像中深度学习的应用,包括对象分类、检测、分割和异常检测任务。文章指出,深度学习模型在这一领域的表现优于传统机器学习方法,尤其是在多视图信息利用和数据集扩大方面。然而,缺乏大型、平衡的数据集和跨扫描仪的域适应仍是主要挑战。未来研究应关注合成数据集的改进、无监督学习方法的优化以及材料信息的有效利用。
这篇综述论文探讨了X射线安检图像中深度学习的应用,包括对象分类、检测、分割和异常检测任务。文章指出,深度学习模型在这一领域的表现优于传统机器学习方法,尤其是在多视图信息利用和数据集扩大方面。然而,缺乏大型、平衡的数据集和跨扫描仪的域适应仍是主要挑战。未来研究应关注合成数据集的改进、无监督学习方法的优化以及材料信息的有效利用。
Towards Automatic Threat Detection: A Survey of Advances of Deep Learning within X-ray Security Imag
面向自动的危险品检测:X 射线安检图像中深度学习进展的调查
Abstract
X-ray被广泛应用于维护航空、运输安全,这篇综述旨在将该领域分为机器学习和深度学习来回顾X-ray的发展历程,第一部分为机器学习方法,第二部分为深度学习方法,其中深度学习中又分为监督学习和无监督学习,依次探讨了对象的分类,检测,分割和异常检测任务。最后,讨论了X-ray的数据集并提供了性能指标,以及未来的发展趋势和方向。
1. Introductionf
这段就是说,X-ray检测很重要,以前人们使用图片分析法和机器学习方法,现在开始用深度学习了,下图是调查结果:

本文的主要贡献
- 分类——X 射线安检图像中经典机器学习和当代深度学习的概述(图 2)。
- 数据集——用于在该领域训练深度学习方法的大型数据集的概述。
- 开放性问题——根据计算机视觉领域的当前趋势讨论开放性问题、当前挑战和未来方向。
后面内容:
第 2 节简要介绍了 X 射线成像的原理。
第 3 节和第 4 节介绍了用于衡量性能的数据集和评估标准。
第 5 节和第 6 节探讨了传统的图像分析和机器学习算法。
第 7 节回顾了深度学习算法在 X 射线安检图像中的应用。
第 8 节讨论了未解决的问题、当前的挑战
第 9 节最后总结了本文。
2. Background: X-ray Imaging
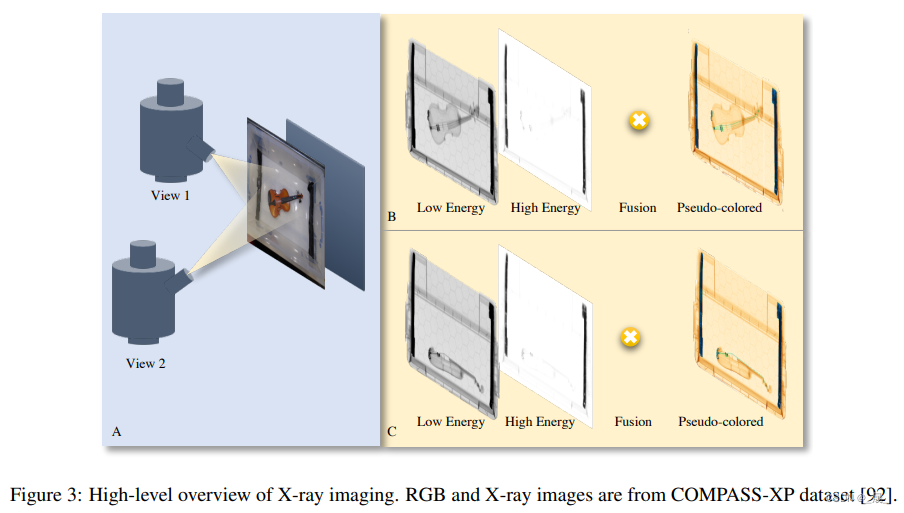
X 射线成像的主要原理是 X 射线管产生穿透扫描对象的光束。
如图 3A 所示,X 射线成像的主要原理是 X 射线管产生穿透扫描对象的光束。 根据其材料密度,物体会衰减 X 射线信号。该衰减公式为,其中
是
cm 处的强度,
是初始强度,
是基于材料的线性衰减系数。 这个公式表明材料密度和测量强度成反比——例如,高密度材料产生高衰减和低测量强度。
现代 X 射线机配备了多个能量 (m) ,可通过不同的能量产生 m 个 X 射线图像(图 3B),识别物体的密度和有效原子序数 ()。 估计的强度和
值通过查找表 [29] 转换为伪彩色图像。除了多个能级之外,最先进的机器还从多个视点生成 X 射线扫描,以从各个角度查看感兴趣的对象(图 3C)。
3. Datasets
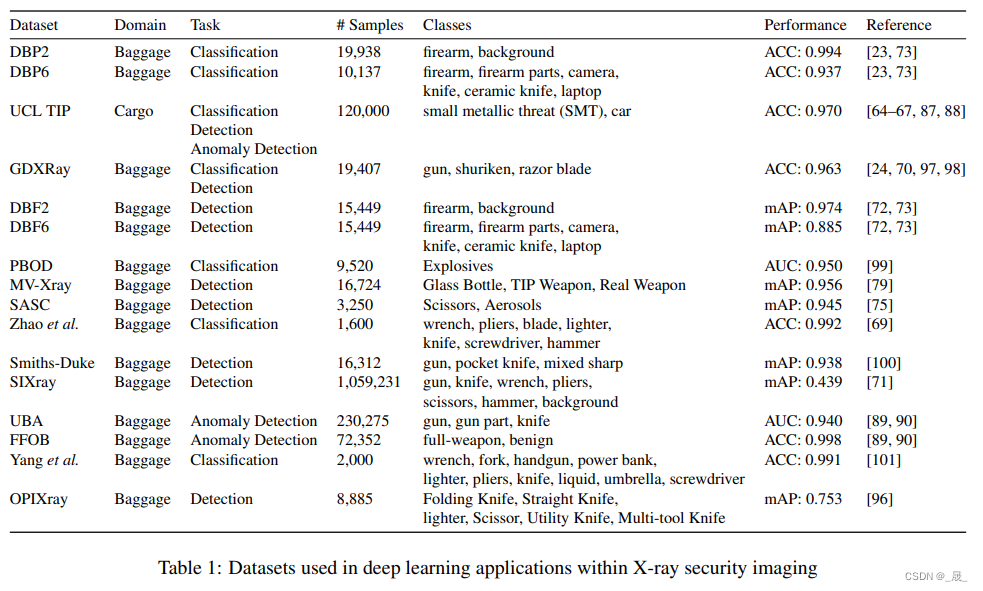
3.1. Durham Baggage (DB) Patch/Full Image Dataset
3.2. GDXray
3.3. UCL TIP
3.4. SIXray
3.5. Durham Baggage Anomaly Dataset –DBA
3.6. Full firearm vs Operational Benign –FFOB
3.7. Compass - XP Dataset
3.8. OPIXray Dataset
4. Evaluation Criteria
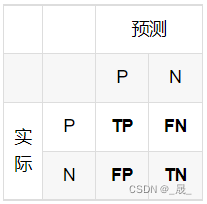
true positives (TP), false positives (FP), true negatives (TN) and false negatives (FN).
准确率。 (ACC) 定义为预测样本中预测正确数占所有样本数的比例
真阳性率。 (TPR)是正确预测的正样本的比例
假阳性率。 (FPR) 计算为预测为正的负样本的比率
均值平均精度。 (mAP) 定义为平均精度的平均值,这是一个由精度和召回曲线下面积评估的指标,其中精度为 TP/(TP + FP),以及
召回率是 TP/(FN + TP)。
mAP = 所有类别的平均精度求和除以所有类别
曲线下面积。 (AUC) 是receiver operating characteristics (ROC) 曲线下的面积,
ROC曲线的横坐标为FPR(False Positive Rate), 纵坐标为TPR(True Positive Rate)。
5. Conventional Image Analysis
本节探讨执行图像增强和危险性图像投影的传统图像分析技术。
5.1. Image Enhancement
预处理输入数据对于产生更高质量的图像起着重要作用,从而提高了筛查仪和计算机的可读性。
文献中常用的方法是 融合低能和高能 X 射线图像并应用背景减法来降噪,其次是手动或自适应阈值选择。
另一种增强技术是伪着色,可以对灰度 X 射线图像进行着色,提高检测性能和操作人员的警觉性水平。
5.2. Threat Image Projection
危险图像投影 (TIP)(危险品图像注入)是另一种可以归类为传统图像分析的方法。
TIP 用于生成合成数据集以训练人工筛选器或机器/深度学习模型。
一种常见的 TIP 方法是通过乘法将二进制危险掩码投影到良性输入 X 射线图像上,从而生成带有危险项目的输出 X 射线图像。
仿射或对数变换的应用将各种危险投影添加到良性图像上。
6. Machine Learning Approaches in X-ray Security Imaging
6.1. Object Classification
在深度学习在该领域占据主导地位之前,视觉词袋(BoVW)方法很普遍。
常见的方法是:
(i) 通过检测器/描述符执行特征提取,(ii) 通过 k-means 对特征进行聚类,(iii) 用 RF、SVM 或 sparse-representation 进行分类。
另外,其他计算机视觉/机器学习技术:
利用结构估计和分割以及通用跟踪算法来检测 X 射线对象。也有基于 k-NN 的稀疏表示,实现了 GDXray 数据集上的深度模型相当的精度。
6.2. Object Detection
与第 6.1 节类似,传统的检测算法也主要采用视觉词袋(BoVW)方法。
各种特征描述符表明,稀疏强度域图像描述符(SPIN)实现了最高的检测性能(mAP:46.1%)。
利用多视图图像,多视图成像有助于人类操作员和机器提高检测性能。 [48,50,52,112] 的工作中提出的通用多阶段方法最初通过特征描述符和 k-NN 分类器 [113] 执行特征提取。 从不同视图匹配的特征由 k-NN 分类器[113](95.7% 精度)进行分类。
6.3. Object Segmentation
本节探讨文献中提出的各种分割技术。
[58, 59] 研究了具有固定绝对阈值和区域分组的简单的基于像素的分割
[13、19、20、60、61] 随后的工作,更多地关注通过最近邻、重叠背景去除和最终分类的预分割
另一种方法是利用基于图的算法进行分割。
[61, 114] 早期的工作集中在属性关系图之间的模糊相似性距离上,而最近研究了光谱聚类和变分图像分割 [115]。
7. Deep Learning in X-ray Security Imaging
本节回顾了利用深度学习算法的x射线安检应用。将算法分类为有监督(分类、检测和分割)和无监督(异常检测)方法。
7.1. Supervised Approaches
监督方法分为分类、检测和分割任务,其中模型分别使用ground-truth、bounding-box和pixel-wise labels。
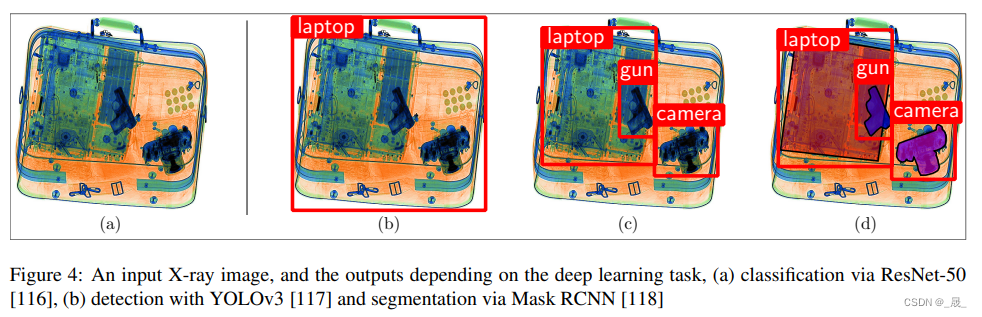
7.1.1. Classification
简单的说就是深度学习比传统方法好。
[66]中探索使用双能 X 射线图像进行自动危险品检测。
作者研究了应用于不同变换,通过双能 X 射线机拍摄的 X 射线图像。 使用 UCL TIP 数据集,通过 256 × 256 的滑动窗口生成 640,000 个图像块。使用具有不同输入通道的固定 VGG-19 网络训练该数据集,包括单通道 (H)、双通道({H, − log H}, {− log H, − log L}) 和四通道 ({− log L, L, H, − log H}) 表明双通道和四通道始终比它们的单通道变体实现卓越的检测性能(ACC:95%–双通道 vs 90%–单通道)。
受 X 射线数据集有限可用性的启发,
[69] 提出了一种三阶段算法。第一阶段通过从输入图像中提取的前景对象的角度信息对输入的 X 射线数据集进行分类和标记。 第二阶段通过对抗网络生成新的 X 射线对象。最后,用小型分类网络分类。
后续[101] 进一步研究改进 GAN 训练以产生更好的 X 射线图像的方法。
[71] 引入一个模型(CHR)来分类/检测来自 SIXray 的 X 射线图像。该模型通过从三个连续层中提取图像特征来解决类别不平衡和杂乱问题,
其中后续层被上采样并与前一层连接。
在 SIXray 上与 ResNet-101 一起使用时,使用建议的损失训练模型会产生 2.13% 的 mAP 改进(36.01 与 38.14)。
[96] 引入了一个即插即用模块,该模块利用边缘和材料信息通过注意力机制定位对象。
研究了使用 CNN 进行爆炸物检测的任务。初始阶段通过固定图像大小、裁剪 的不相关背景对象并应用数据增强变换来处理输入数据。
随机初始化与 VGG19、Xception 上的预训练的评估,和 InceptionV3 网络表明,随机初始化的模型在二元分类任务中实现了卓越的准确性。
为了研究强度和 Z-eff 值对性能的影响,作者在强度和 Z-有效、仅强度和仅 Z-有效方面训练了三个 VGG-19 网络。
仅使用 Z-eff 训练模型可以产生最高的准确度。
最后一组实验通过热图研究定位,并表明预训练网络实现了卓越的性能,因为随机初始化的网络往往会在小数据集上过拟合。
[67] 研究使用来自各种扫描仪的不同数据集训练的模型的泛化能力。
作者从单个或多个域创建训练和测试,以研究在其他模型之间转换的影响。
7.1.2. Detection
本节通过分类单视图和多视图目标检测来探索基于 CNN 的目标检测算法。
单视图检测。
[72] 在 DBF2/6 数据集上训练基于滑动窗口的 CNN、Faster RCNN 和 R-FCN 模型,用于枪支和多类检测问题。实验表明,带有 VGG16 的 Faster RCNN 在 6 类 DBF6 数据集上产生 88.3% 的 mAP,而带有 ResNet101 的 R-FCN 在 2 类(枪与无枪)DBF2 数据集上实现了最高性能(96.3 mAP) 。
[129] 利用对抗域适应技术来匹配相当大的 unlabelled stream of commerce (SoC) 数据集的背景分布。
这样做有助于通过在小型标记数据集上训练 Faster RCNN 来检测 SoC 数据集中的对象。
[77] 在 SIXray10 数据集上训练 SSD 和 RetinaNet,分别达到 60.5% 和 60.9%。
[75] 通过 YOLOv2 执行目标检测,以检测 SASC 数据集上的剪刀和气溶胶。
训练 YOLO v2 进行 6000 次迭代可产生 94.5% 的平均精度和 92.6% 的召回率,运行速度为 68 FPS。
[76] 认为 RetinaNet 实现了相当的检测性能, 使用 5000 个 X 射线货物集装箱和 544 支枪械通过 TIP 合成生成的 30,000 张图像进行训练时,比传统的滑动窗口分类要快得多。
[74] 提出了一种目标检测算法,其中 RoI 是通过级联多尺度结构张量生成的,该张量基于目标方向的变化进行提取。
然后将提取的 RoI 传递到 CNN,其在 GDXray 和 SIXray 数据集上的定量和计算性能优于 RetinaNet、YOLOv2 和 F-RCNN。
[78, 132] 中的方法生成基于轮廓的目标候选框,随后将其前向传递到 CNN,在 SIXray10 数据集上实现 96% 的 mAP。
由于部分数据集缺乏标记信息
[70] 利用注意力机制来定位危险物品。
第一阶段前向传递输入并找到相应的类概率。反向传播时识别在输出类决策期间激活的互连神经元。 生产第一个卷积层激活生成的热图。
最后阶段将前一层激活后进行归一化来细化激活图。所提出的方法在不需要边界框信息的情况下实现了出色的检测。
与传统的反卷积方法(mAP:34.3%)这个篇文章:(56.6%)。
[82]研究了CNN的泛化能力。 通过在不同数据集上训练/验证 CNN(DBF3 (88% mAP) → SIXray (85% mAP))。
多视图检测。 有许多论文利用多视图 X 射线图像来提高其模型的检测性能。
多视图优于单视图,
[100. 2018] 探索了 F-RCNN、R-FCN 和 SSD 在单视图/多视图 X 射线图像中的性能。通过合并来自单个视图的目标检测输出,利用 OR-gate 检测,表明多视图优于单视图(使用 R-FCN 和 ResNet-101 训练时为 0.938 对 0.798)。
[133] Two-stage, 首先提取前景物体,随后利用 F-RCNN 检测 32、253 张地铁 X 射线图像,6 个物体类别的 mAP 为 77%。
[80] 通过在包含 4 个危险品类别的数据集上进行训练来探索 SSD 和 F-RCNN,每个危险品类别包含大约 3、400 张图像。
具有 Inception ResNetv2 主干的 F-RCNN 产生最高的 mAP(在单视图和多视图图像上分别为 92.2 和 97.7)。
[79] 通过修改 F-RCNN 来利用多视图。多视图池化层构造从卷积层中提取的 3D 特征 2D。3D 区域提议网络生成 RoI。在 3D RoI 池化层之后执行分类和边界框预测。 实验表明,与单视图图像相比,多视图产生了改进(95.56% 对 91.23%)。
[81] 通过利用 X 射线图像多视图的对极约束来训练 YOLOv3 [117] 检测器,其性能优于单视图 2.2%(图 4C)。
R-FCN 和 ResNet-101 单视图0.798,多视图0.938
Two-stage 方法[Deep Convolutional Neural Network Based Object Detector for X-Ray Baggage Security Imagery,2019], mAP 为 77%
Toward Automatic Threat Recognition for Airport X-ray Baggage Screening with Deep Convolutional Object Detection,2019, 4 个危险品类别的数据集,以Inception ResNetv2 主干的 F-RCNN ,单视图92.2 ;多视图97.7
Multi-view Object Detection Using Epipolar Constraints within Cluttered X-ray Security Imagery,2020,
多视图 YOLOv3,多视图优于单视图 2.2%
7.1.3. Segmentation
由于具有像素级注释的数据集稀缺,分割任务在该领域内的研究不足。(2019)
[83] 将分割和异常检测任务一起解决,其中双 CNN 管道最初通过 Mask RCNN 分割 RoI,并通过 ResNet-18 将区域分类为良性/异常,达到 97.6%分割 mAP 和 66.0% 的异常检测精度(图 4D)。
134]提出了三阶段方法,其中(i)通过使用Mask RCNN 实现对象级分割,(ii)通过超像素分割对子组件区域进行分割,以及(iii)最终对象分类是通过细粒度的 CNN 分类执行的,总体上对 7, 878 个电子项目产生 97.91% 的异常检测准确率。
[135]提出了一种在编码器-解码器分割网络中利用双重注意机制的分割模型。前一个注意模块对 RoI 进行分类,而后者则对对象进行定位。在 PASCAL 类似的结构化 X 射线数据集上进行的实验包含来自 7 个类别的 7、532 张增强图像,产生 99.3 的准确度和 68.3 的平均交叉联合 (mIoU)。
7.2. Unsupervised Approaches
本节探讨无监督深度学习模型,其中提出的算法主要研究异常检测任务。
[86]以无监督的方式采用稀疏前馈自动编码器来学习正常和异常数据的特征编码。然后,SVM 将图像分类为异常或良性。对 MNIST 和货运集装箱数据集(空与非空)的验证表明,从自动编码器中提取的隐藏层表示对于检测图像中的异常具有重要意义。当与原始输入和残差融合时,来自隐藏层的特征编码会产生更好的检测性能。
后续工作利用从 UCL TIP 数据集的补丁中提取的强度、对数强度和 VGG-19 特征,并通过随机分裂树异常检测器 的森林训练正常图像。在正常 + 异常数据上测试模型产生 64% AUC。
[89]其中图像和潜在向量空间针对异常检测进行了优化,利用了对抗网络,使得生成器包括编码器-解码器子网络。该模型的目标是最小化真实/生成图像及其潜在表示之间的距离,总体上在统计和计算上都优于以前的最新技术(UBA:64.3%,FFOB:88.2% – AUC )。
[90] 通过 (i) 利用生成器网络中的跳跃连接来处理更高分辨率的图像,以及 (ii) 学习鉴别器网络中的潜在表示,进一步提高 [89] 的性能(UBA:94.0% , FFOB: 90.3% – AUC)。
[91] (i) 首先从 Inception v3类似网络中提取正常图像的特征,(ii) 随后训练多元高斯模型以捕获 CAST 数据集的正态分布。 测试样本的异常分数基于其相对于模型的可能性,总体产生 92.5% AUC。
8. Discussion and Future Directions
数据集。缺乏大型数据集,这限制了深度模型训练。因此必须构建大型、同质、现实和公开可用的数据集,
可以通过 (i) 在实验室环境中手动扫描具有不同对象和方向的行李箱 (ii) 通过算法生成合成数据集来扩充。但消耗人力和时间
合成数据集的方法,TIP或GAN,
TIP 会影响真实示例的检测
GAN 无法生成完整的 X 射线图像,生成的图像质量不真实。
需要进行进一步的研究。通过使用当代 GAN 算法创建更逼真的 X 射线图像。
利用多视图信息。 多视图比单视图检测性能更好,需要进一步研究利用多视图图像的其他方法。
X 射线扫描仪之间的域自适应。 由于扫描仪的未知内在特性,在不同扫描仪之间传输模型可能具有挑战性。
未来的工作将利用域适应,其中源域包含来自一个扫描仪的图像,而目标域将是另一个 X 射线扫描仪的图像。 即使使用不平衡的数据集进行训练学习,也可以从一个映射到另一个。
改进无监督异常检测方法。 7.2节中的方法在实际场景中部署时有一定的限制。
材料信息的使用。在双能X-ray系统中,高能和低能在不同材料上的衰减并不相同,应进一步研究不同材料信息对于能量衰减的反应
9. Conclusion
本文对 X 射线安检图像中使用的传统机器和现代深度学习算法进行分类。
传统方法包括图像增强、危险性图像投影、分割、特征提取、分类和检测。
深度学习方法包括在该领域应用的分类、检测、分割和无监督异常检测算法。
未来发展方向的几个结论。 尽管最近出现了数据集,但缺乏大型、平衡的数据集,限制了深度学习算法的设计,这些算法具有足够的通用性,可以部署在实时环境中。 此外,由于公共数据集大多来自具有不同内在特性的各种机器,因此使用领域适应技术可以提高算法的泛化能力。
与传统机器学习中的大量研究不同,最近的大多数方法都没有充分利用 X 射线成像,例如多视图几何和高低能量。 尽管存在一些研究,但仍有进一步研究的空间。 此外,无监督学习的研究可以进一步利用现有的未标记且未使用的 X 射线数据集。

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









