






为什么使用消息队列
-
解耦:服务和服务之间通过消息队列传送消息,这样就完成服务之间的解耦合
-
异步:异步处理,这样可以降低响应时间。
-
削峰:存储流量,降低并发请求
多种消息队列的比较
-
RabbitMQ:
-
优点:轻量,迅捷,容易部署和使用,拥有灵活的路由配置
-
缺点:性能和吞吐量不太理想,不易进行二次开发
-
-
RocketMQ:
-
优点:性能好,高吞吐量,稳定可靠,有活跃的中文社区
-
缺点:兼容性上不是太好
-
-
Kafka:
-
优点:拥有强大的性能及吞吐量,兼容性很好
-
缺点:由于“攒一波再处理”导致延迟比较高
-
| 消息中间件 | ACTIVEMQ | RABBITMQ | KAFKA | ROCKETMQ |
| 开发语言 | Java | ErLang | Java | Java |
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| Topic | - | - | 百级Topic时会影响系统吞吐量 | 千级Topic时会影响系统吞吐 |
| 社区活跃度 | 低 | 高 | 高 | 高 |
通信方式
-
同步的RPC远程调用
-
基于中间件代理的异步通信方式。(一般为消息中间件)

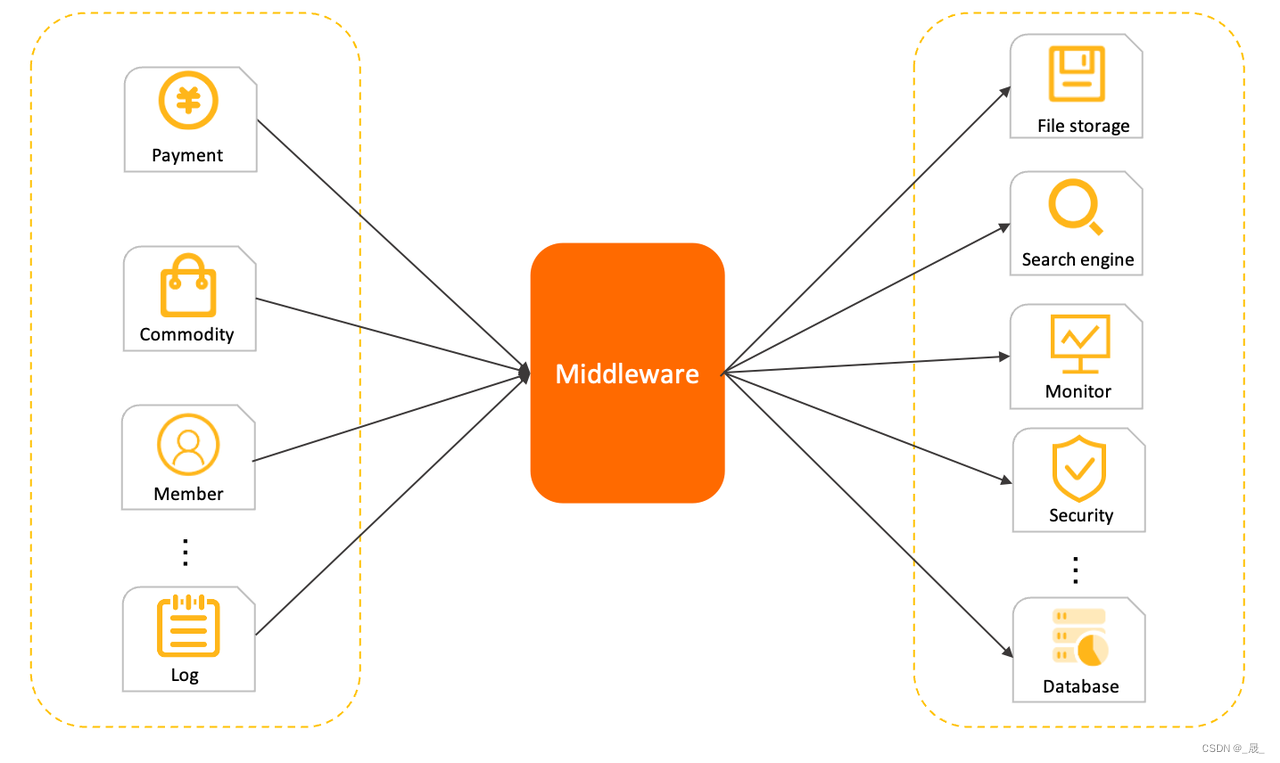
核心概念
-
NameServer:可以理解为是一个注册中心。在NameServer的集群中,NameServer与NameServer之间是没有任何通信的。
-
保存topic路由信息
-
管理Broker
-
-
Broker:核心的一个角色。在一个Broker集群中,相同的BrokerName可以称为一个Broker组,一个Broker组中,BrokerId为0的为主节点,其它的为从节点。BrokerName和BrokerId是可以在Broker启动时通过配置文件配置的。每个Broker组只存放一部分消息。
-
保存topic的信息
-
接受生产者产生的消息
-
持久化消息
-
-
生产者:生产消息的一方就是生产者
-
生产者组:一个生产者组可以有很多生产者,只需要在创建生产者的时候指定生产者组,那么这个生产者就在那个生产者组
-
消费者:用来消费生产者消息的一方
-
消费者组:跟生产者一样,每个消费者都有所在的消费者组,一个消费者组可以有很多的消费者,不同的消费者组消费消息是互不影响的。
-
topic(主题) :可以理解为一个消息的集合的名字,生产者在发送消息的时候需要指定发到哪个topic下,消费者消费消息的时候也需要知道自己消费的是哪些topic底下的消息。Topic:库存,Topic:订单
-
Tag(子主题) :比topic低一级,可以用来区分同一topic下的不同业务类型的消息,发送消息的时候也需要指定。Topic:库存(tag=上海,tag=江苏,tag=浙江)
工作流程
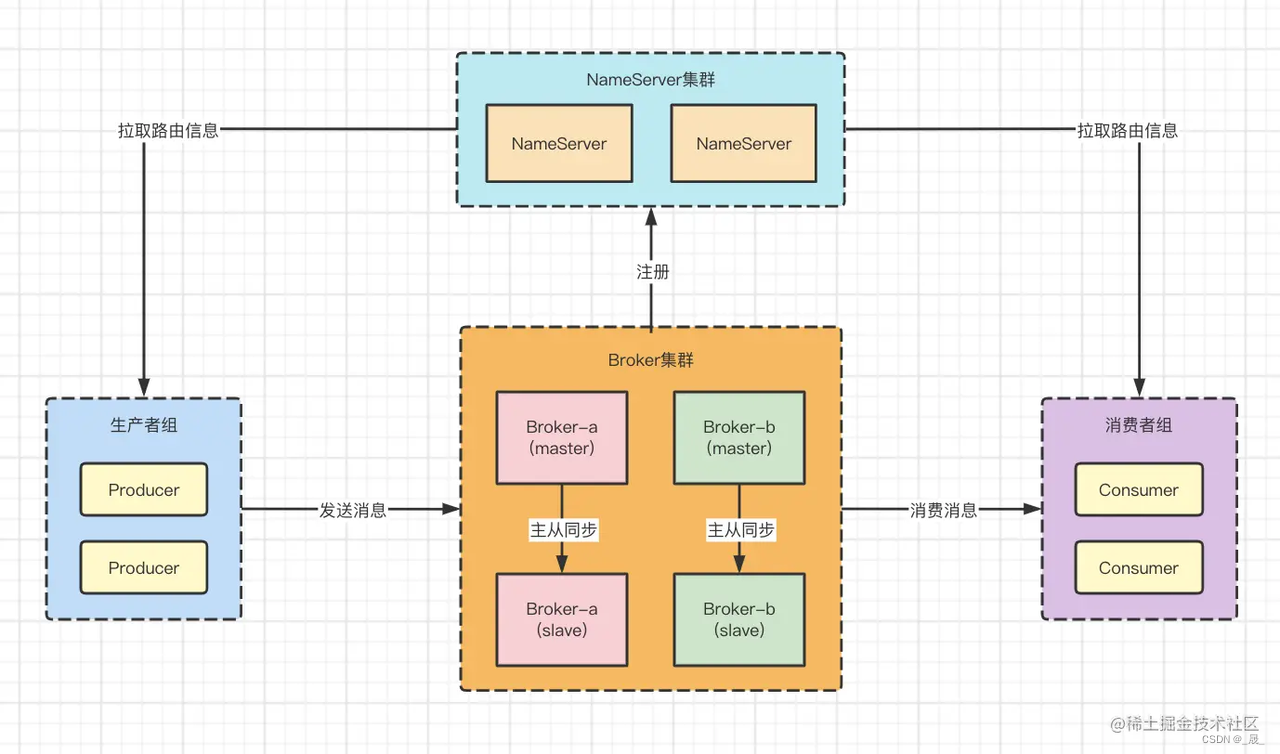
1. Broker向NameServer注册
Broker启动的时候,会往每台NameServer(因为NameServer之间不通信,所以每台都得注册)注册自己的信息,这些信息包括自己的ip和端口号,自己这台Broker有哪些topic等信息。
2. Producer拉取路由信息,发送消息。
Producer在启动之后会跟会NameServer建立连接,定期从NameServer中获取Broker的信息,当发送消息的时候,会根据消息需要发送到哪个topic去找对应的Broker地址,如果有的话,就向这台Broker发送请求;没有找到的话,就看根据是否允许自动创建topic来决定是否发送消息。
3. Broker存储消息
Broker在接收到Producer的消息之后,会将消息存起来,持久化,如果有从节点的话,也会主动同步给从节点,实现数据的备份
4. Consumer拉取路由信息,获取消息。
Consumer启动之后也会跟会NameServer建立连接,定期从NameServer中获取Broker和对应topic的信息,然后根据自己需要订阅的topic信息找到对应的Broker的地址,然后跟Broker建立连接,获取消息,进行消费
消息模型
消息队列有两种模型:点对点模型(队列模型)和发布/订阅模型。
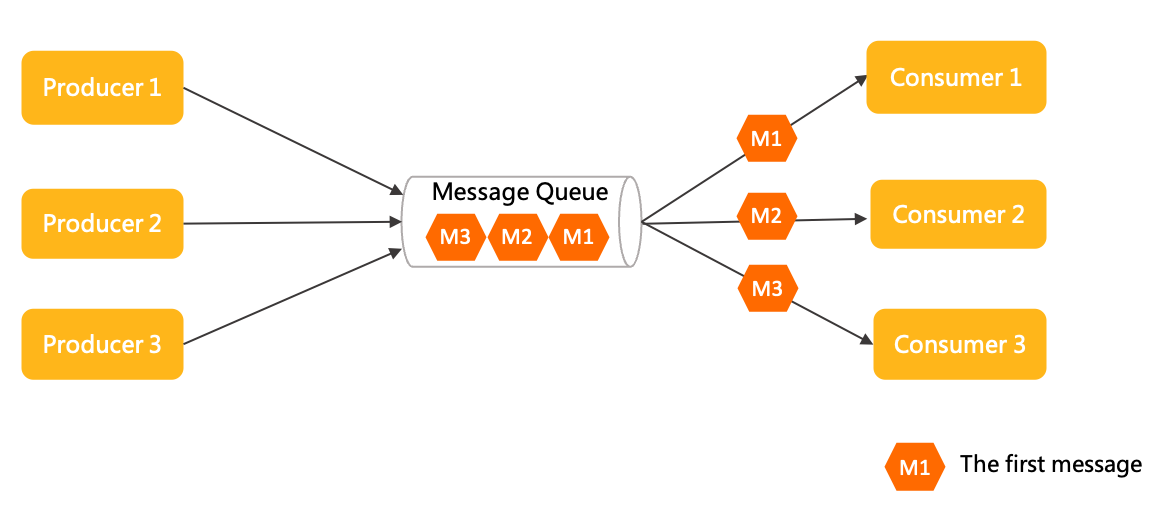
点对点模型(队列模型)
-
消费匿名:消息上下游沟通的唯一的身份就是队列,下游消费者从队列获取消息无法申明独立身份。
-
一对一通信:基于消费匿名特点,下游消费者即使有多个,但都没有自己独立的身份,因此共享队列中的消息,每一条消息都只会被唯一一个消费者处理。因此点对点模型只能实现一对一通信。
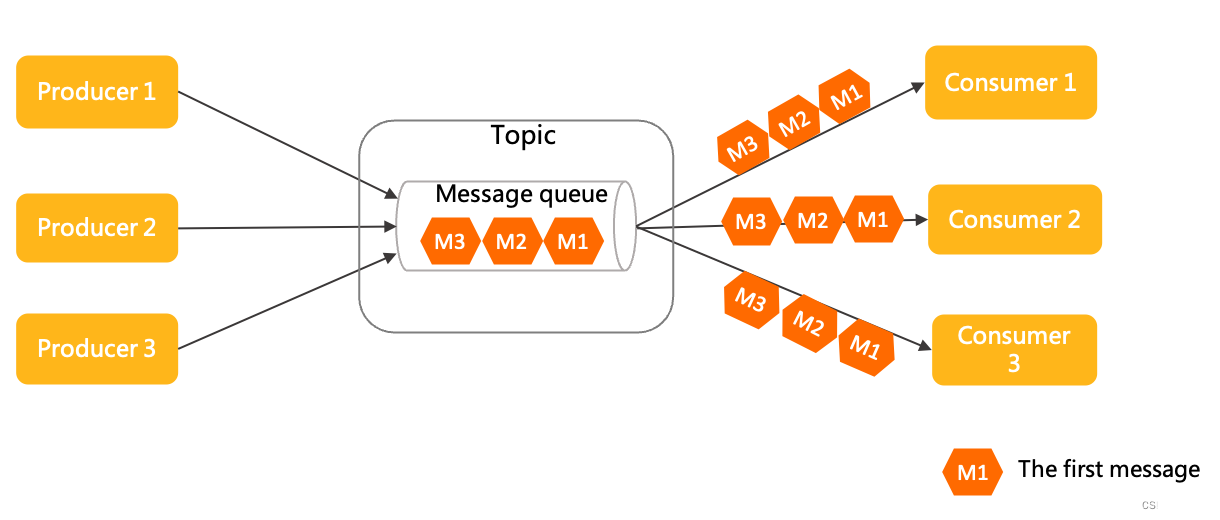
发布/订阅模型
-
消费独立:相比队列模型的匿名消费方式,发布订阅模型中消费方都会具备的身份,一般叫做订阅组(订阅关系),不同订阅组之间相互独立不会相互影响。
-
一对多通信:基于独立身份的设计,同一个主题内的消息可以被多个订阅组处理,每个订阅组都可以拿到全量消息。因此发布订阅模型可以实现一对多通信。
生命周期
主要分为消息生产、消息存储、消息消费
-
消息生产:生产者Producer
-
消息存储:主题Topic,队列MessageQueue,消息Message
-
消息消费:消费者分组ConsumerGroup,消费者Consumer,订阅关系Subscription
消息类型
-
顺序消息
-
延时消息
-
批量消息
-
过滤消息
事务消息
事务消息处理流程
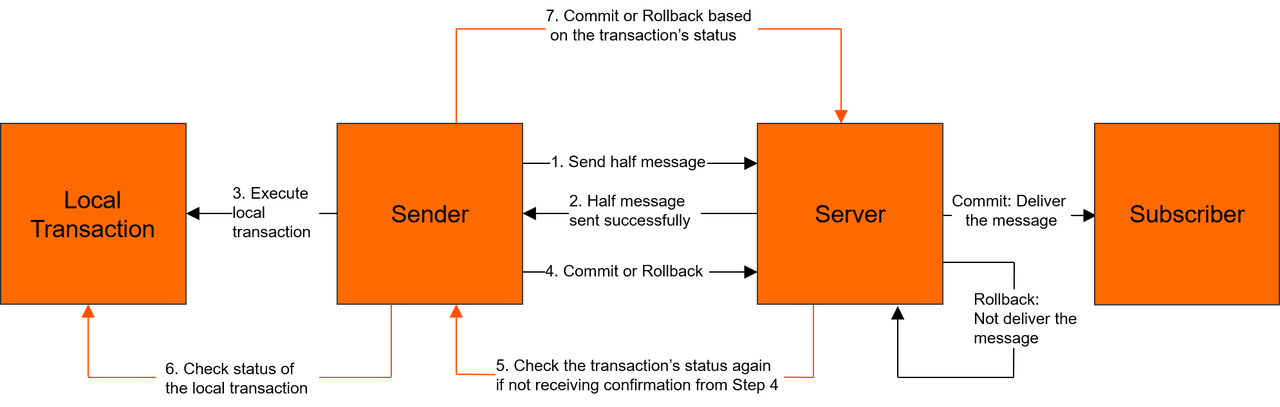
-
生产者将消息发送至Apache RocketMQ服务端。
-
Apache RocketMQ服务端将消息持久化成功之后,向生产者返回Ack确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下的消息即为半事务消息。
-
生产者开始执行本地事务逻辑。
-
生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
-
二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
-
二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
-
-
在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。 说明 服务端回查的间隔时间和最大回查次数,请参见参数限制。
-
生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
-
生产者根据检查到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理。
事务消息生命周期
-
初始化:半事务消息被生产者构建并完成初始化,待发送到服务端的状态。
-
事务待提交:半事务消息被发送到服务端,和普通消息不同,并不会直接被服务端持久化,而是会被单独存储到事务存储系统中,等待第二阶段本地事务返回执行结果后再提交。此时消息对下游消费者不可见。
-
消息回滚:第二阶段如果事务执行结果明确为回滚,服务端会将半事务消息回滚,该事务消息流程终止。
-
提交待消费:第二阶段如果事务执行结果明确为提交,服务端会将半事务消息重新存储到普通存储系统中,此时消息对下游消费者可见,等待被消费者获取并消费。
-
消费中:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程。 此时服务端会等待消费者完成消费并提交消费结果,如果一定时间后没有收到消费者的响应,Apache RocketMQ会对消息进行重试处理。具体信息,请参见消费重试。
-
消费提交:消费者完成消费处理,并向服务端提交消费结果,服务端标记当前消息已经被处理(包括消费成功和失败)。 Apache RocketMQ默认支持保留所有消息,此时消息数据并不会立即被删除,只是逻辑标记已消费。消息在保存时间到期或存储空间不足被删除前,消费者仍然可以回溯消息重新消费。
-
消息删除:Apache RocketMQ按照消息保存机制滚动清理最早的消息数据,将消息从物理文件中删除。更多信息,请参见消息存储和清理机制。
参考资料















 4495
4495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









