







论文标题:
Thinking Globally, Acting Locally: Distantly Supervised Global-to-Local Knowledge Selection for Background Based Conversation
该论文主要解决基于背景知识的对话系统中知识选择的问题,引入global-to-local knowledge selection(GLKS)机制,可以选择合适的背景知识生成response
- abs

给定对话内容和背景知识,首先学习到topic transition vector来编码那些最有可能被用到生成response的text fragments,该vector可以在解码阶段每个时间步指导知识的选择(KS)
- Intro

现存的Background Based Conversations (BBCs) 主要分为extraction(retrieval)和generation based 两种方法,前者通过学习两个指针从背景信息中提取spans作为response,虽然在发现知识方面优于generation based方法,但存在两个问题,1)大多情况下生成的response不自然,2)对话系统中一般没有标准答案
现存的generation based 方法通常采取local perspective,每个时间步仅仅根据当前的解码状态选择一个token,这样做的问题是缺少更global的guidance
提出改进

- GLKS model
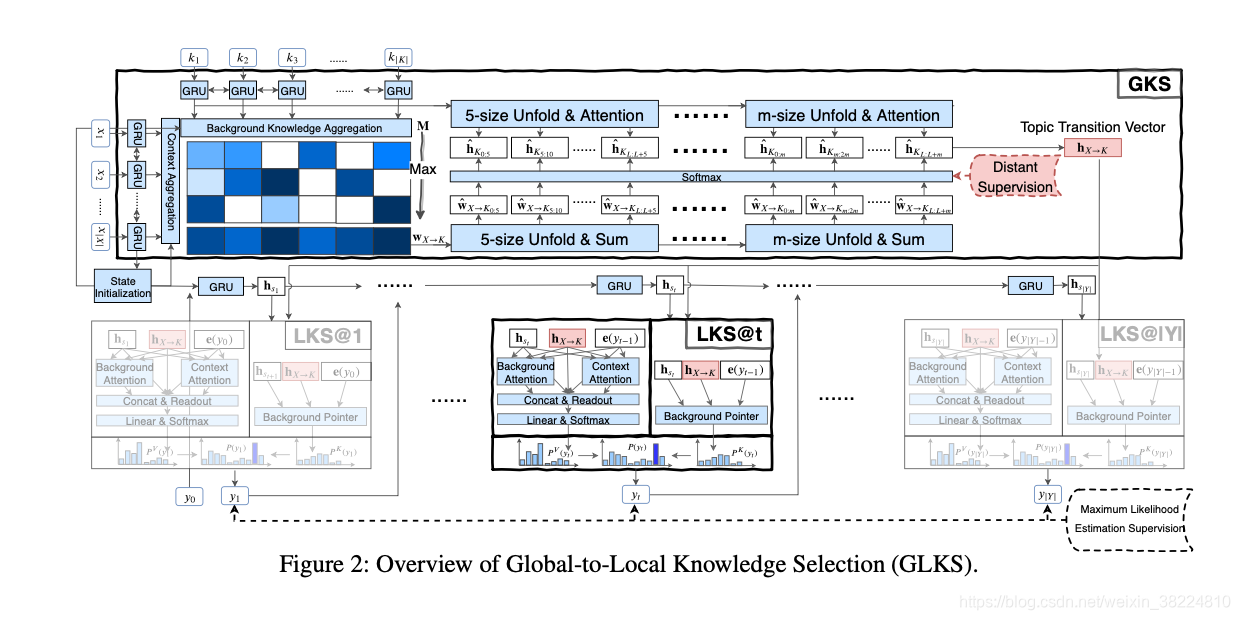
根据,background material:
K = [k1, k2, . . . , kt, . . . , k|K|], with |K| tokens
和当前的 conversational context:
X = [x1,x2,…,xt,…,x|X|], with |X| tokens
生成response Y =[y1,y2,…,yt,…,y|Y|]
by occasionally referencing background knowledge in K
GLKS, , consists of four modules: Background & Context Encoders, a Global Knowledge Selection (GKS) Module, a State Tracker, and a Local Knowledge Selection (LKS) Module.
- Background and context encoders
用bigru将背景知识和对话context转化成hidden representation sequences

- Global Knowledge Selection (GKS) module
该模块用于计算背景和context的匹配程度,步骤较多
首先分别将背景和context的向量 H K H^K HK和 H X H^X HX与context的最后一个output h ∣ X ∣ x h_{|X|}^x h∣X∣x用highway transformations进行聚合

然后计算transition matching matrix M

对X维度做最大池化的意义在于找出与每个背景token相关性最大的context token,进而得到与整句背景vector相关性最大的context vector
w
x
−
>
k
w_{x->k}
wx−>k,其中每个元素代表了context到背景token的转移概率
该weight vector
w
x
−
>
k
w_{x->k}
wx−>k仅考虑了token级别的transition,缺少全局的视角。
于是引入“m- size unfold & sum” 计算,首先从
w
x
−
>
k
w_{x->k}
wx−>k中提取滑动窗口大小为m的相邻weights,然后进行sum up
具体而言
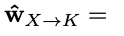

下标代表了元素的起始和终止位置
通过对应的“m-size unfold & attention”操作可以得到semantic unit representations

其中的attention是用context的最后一个output
h
∣
X
∣
x
h_{|X|}^x
h∣X∣x和背景vector的每个element
h
i
k
h_i^k
hik做dot product
H
^
K
\hat{\mathbf{H}}^{K}
H^K中每个元素代表了背景语句K中从L到L+m个token的语义
最终得到topic transition vector
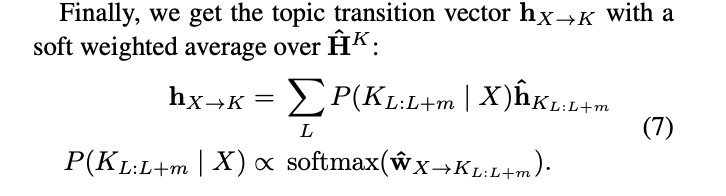
- State tracker
用于初始化decoding的时间步并且在之后的每个时间步进行更新

- Local Knowledge Selection (LKS) module
用于在解码阶段预测response的token,来源于vocabulary (with probability P V ( y t ) P^V (yt ) PV(yt)) 或者bacground K (with probability P K ( y t ) P^K (yt ) PK(yt))
具体步骤如下
首先将topic transition vector, 解码阶段的state和上一个时间步生成的response token拼接起来,然后和背景K语句做attention得到guidance-aware bg rep
h
^
t
K
\hat{\mathbf{h}}_t^{K}
h^tK向量,然后用相似的方式得到guidance-aware context rep- resentation
h
^
t
X
\hat{\mathbf{h}}_t^{X}
h^tX

构造readout feature vector,经过线性层后用softmax预测
P
V
(
y
t
)
P^V (yt )
PV(yt)

损失函数分三部分组成:
Maximum Likelihood Estimation loss, the Distant Supervision loss, and the Maximum Causal Entropy loss.

- experiment
dataset
Holl-E

baseline and evaluation metrics

- results



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









