






 本文介绍了如何使用贝叶斯方法进行新闻分类,包括数据抓取、分词、停用词处理、TF-IDF特征提取和朴素贝叶斯算法应用。通过一个实战项目演示了如何通过TfidfVectorizer生成特征向量并进行分类。
本文介绍了如何使用贝叶斯方法进行新闻分类,包括数据抓取、分词、停用词处理、TF-IDF特征提取和朴素贝叶斯算法应用。通过一个实战项目演示了如何通过TfidfVectorizer生成特征向量并进行分类。
前期我们讲过了贝叶斯的详细原理,今天我们来进行一个小小的项目实战---使用贝叶斯进行新闻分类。首先讲解一下整个项目的项目流程:
1. 从网络上爬取新闻资料。
2. 对整段的新闻资料进行分词。
3. 去除无用的停用词语。
4. 使用TF-IDF提取新闻的关键词,提取重要特征。
5. 使用朴素贝叶斯算法完成分类。
接下来我们进入代码详细解(由于目前我们使用的资料是现成的新闻数据:
http://www.sogou.com/labs/resource/ca.php
,所以这里省略第一步):
1. 首先看下我们的数据

2. 使用结巴分词器对content列进行分词。


3. 我们使用的是网络上现成的停用词库来进行分词的,去除停用词是数据清洗中很关键的一个步骤,可以帮助我们去除没有意义的连接词语,帮助我们筛选重要信息。
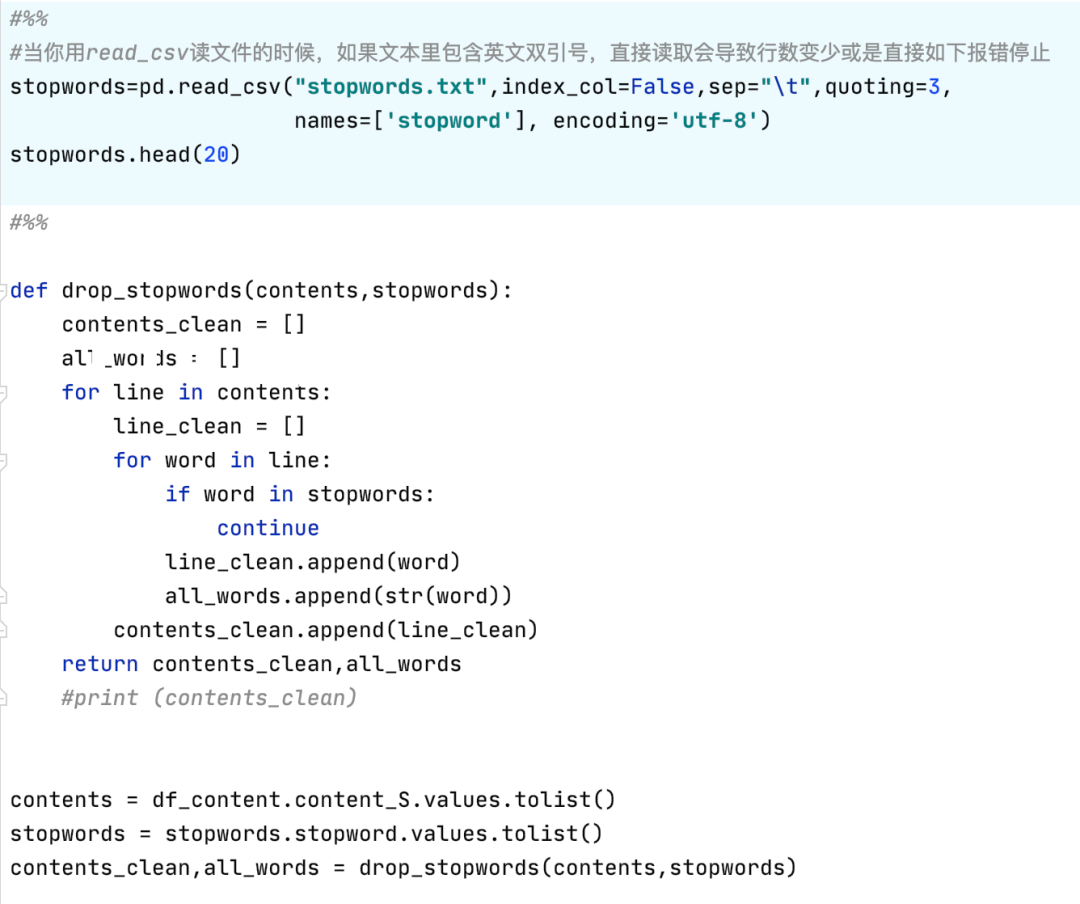
4. 首先我们要讲解一下TF-IDF。
TF-IDF也叫逆文档频率,他的算法主旨就是:如果某个词比较少见,但是它在这篇文章中多次出现,那么它很有可能反映了这篇文章的特性,也就是我们需要提取的特征关键词。我们来看一下它的公式:

用TF*IDF,得分最高的就是我们需要得到的关键词。举个例子:比如文章A有1000个词,词B在其中出现300次;我们的整个语料库有10000个文档,包含B的有999篇,那么词B的TF-IDF就是:(300/1000)*log(10000/1000)。
5. 我们在讲解一下根据关键词生成向量。如下例子所示,其实就是按照词频生成向量。如下texts中的特征有【bird cat dog fish】,【dog cat fish】中dog cat fish分别出现了一次,所以其向量是【0 1 1 1】,以此类推。

6.代码中我们使用TfidfVectorizer,即TfidfTransformer + CountVectorizer 即先提取关键词,再根据词频生成向量。

具体的数据和代码大家可以在后台回复:贝叶斯新闻分类,进行领取。大家可以下载代码多跑跑多看看,会对此项目有更深一步的了解。everybody加油哦~
喜欢的话点个关注哦~ 会每天分享人工智能机器学习内容,回复关键字可获取相关算法数据及代码~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









