






 本文介绍了如何使用K-Means算法对啤酒数据集进行聚类分析,包括设定K值、初始化质心、距离计算、结果排序、质心求解、数据可视化以及数据归一化对聚类效果的影响。通过计算轮廓系数评估聚类质量,并探讨了不同K值对聚类性能的影响。
本文介绍了如何使用K-Means算法对啤酒数据集进行聚类分析,包括设定K值、初始化质心、距离计算、结果排序、质心求解、数据可视化以及数据归一化对聚类效果的影响。通过计算轮廓系数评估聚类质量,并探讨了不同K值对聚类性能的影响。
有关k-means的原理我们已经讲过了,为了更好的进行实战训练,我们先简单的回顾一下(K-means工作流程):
1. 先设定K值
2. 随机初始化K个质心点
3. 计算每个样本点到各个质心点的距离,样本点距离哪个质心的距离最小,就归到哪一类中。
4. 所有的样本点都归类结束后,更新质心点。对每个类重新算均值,算质心。
5. 重新遍历样本点,对样本点重新计算距离并归类。
6. 直到样本点分类不在发生变化,停止更新。
接下来进行今天的k-means实战练习。
首先看看我们的数据集:
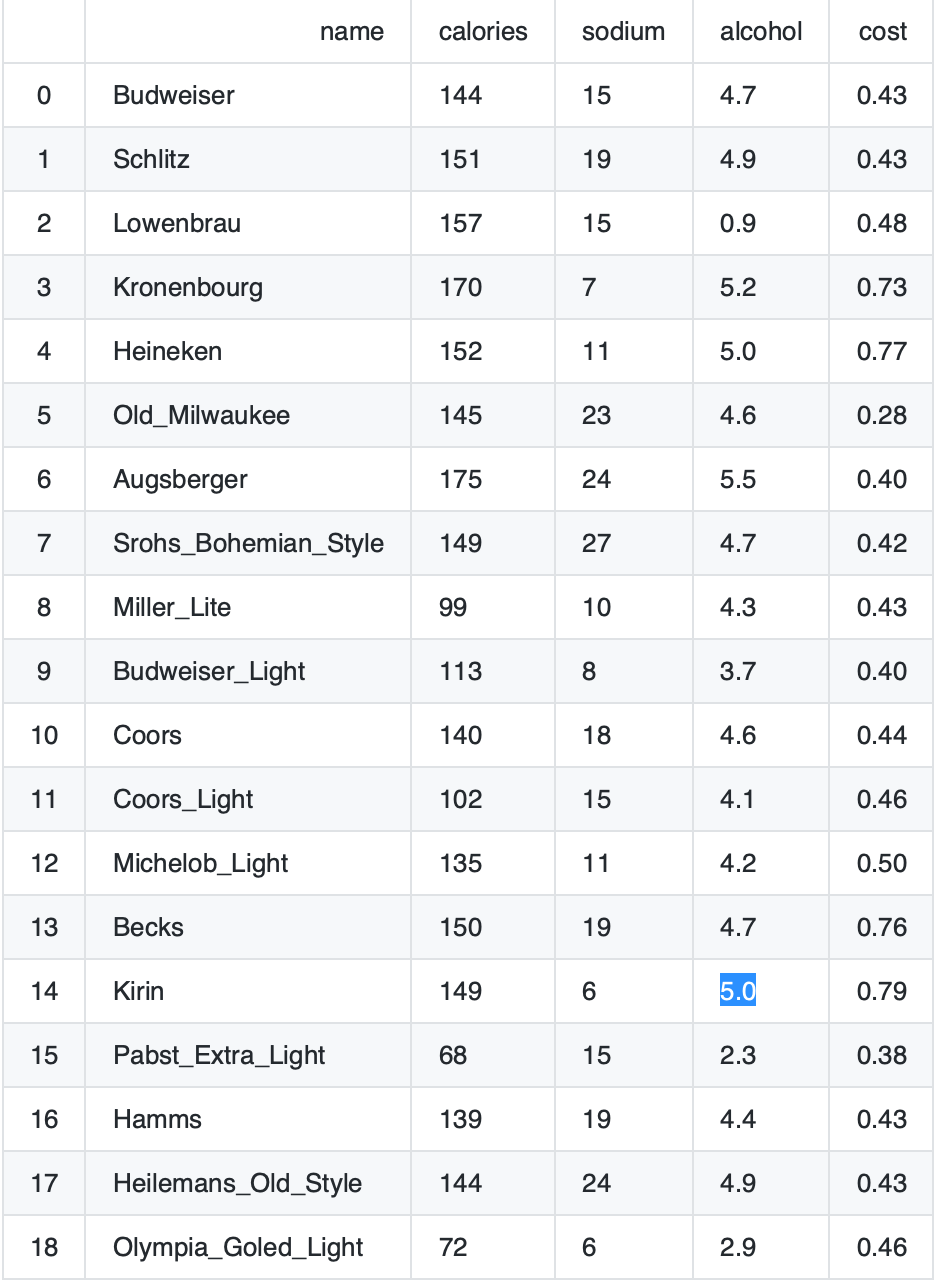
本次实战的目标是对啤酒进行分类,name是啤酒的名称。该数据集有四个属性:卡路里/钠含量/酒精含量/价值。
1. 首先写入数据集
import pandas as pd
beer = pd.read_csv('data.txt', sep=' ')
X = beer[["calories","sodium","alcohol","cost"]]
2.应用k-means算法进行聚类分析
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3).fit(X) #n_clusters就是k值,我们设定k=3或k=2做比较
km2 = KMeans(n_clusters=2).fit(X)
3.将分类结果进行排序
beer['cluster'] = km.labels_ #km.labels_对应数据标签
beer['cluster2'] = km2.labels_
beer.sort_values('cluster')
4.求出每一类的质心
centers = beer.groupby("cluster").mean().reset_index()
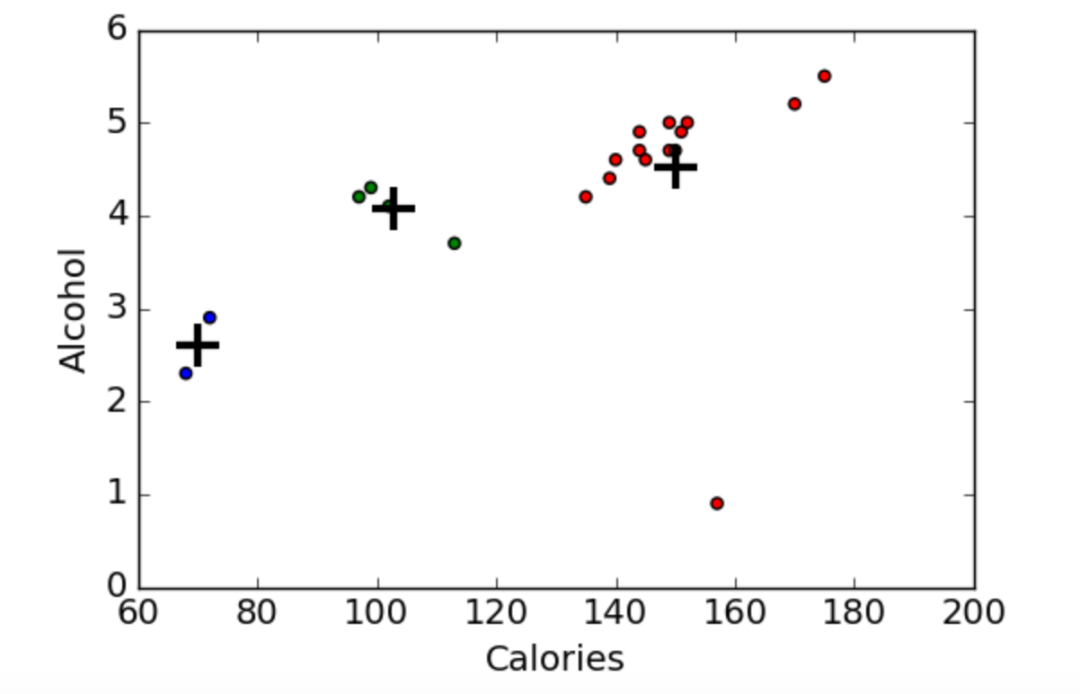
5.画图
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14
import numpy as np
colors = np.array(['red', 'green', 'blue', 'yellow'])
plt.scatter(beer["calories"], beer["alcohol"],c=colors[beer["cluster"]])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")
7.数据归一化
### Scaled data
#%%
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled:
array([[ 0.38791334, 0.00779468, 0.43380786, -0.45682969],
[ 0.6250656 , 0.63136906, 0.62241997, -0.45682969],
[ 0.82833896, 0.00779468, -3.14982226, -0.10269815],
[ 1.26876459, -1.23935408, 0.90533814, 1.66795955],
[ 0.65894449, -0.6157797 , 0.71672602, 1.95126478],
[ 0.42179223, 1.25494344, 0.3395018 , -1.5192243 ],
[ 1.43815906, 1.41083704, 1.1882563 , -0.66930861],
[ 0.55730781, 1.87851782, 0.43380786, -0.52765599],
[-1.1366369 , -0.7716733 , 0.05658363, -0.45682969],
[-0.66233238, -1.08346049, -0.5092527 , -0.66930861],
[ 0.25239776, 0.47547547, 0.3395018 , -0.38600338],
[-1.03500022, 0.00779468, -0.13202848, -0.24435076],
[ 0.08300329, -0.6157797 , -0.03772242, 0.03895447],
[ 0.59118671, 0.63136906, 0.43380786, 1.88043848],
[ 0.55730781, -1.39524768, 0.71672602, 2.0929174 ],
[-2.18688263, 0.00779468, -1.82953748, -0.81096123],
[ 0.21851887, 0.63136906, 0.15088969, -0.45682969],
[ 0.38791334, 1.41083704, 0.62241997, -0.45682969],
[-2.05136705, -1.39524768, -1.26370115, -0.24435076],
[-1.20439469, -1.23935408, -0.03772242, -0.17352445]])
8.使用归一化之后的数据再进行聚类算法
km = KMeans(n_clusters=3).fit(X_scaled)
beer["scaled_cluster"] = km.labels_
beer.sort_values("scaled_cluster")
9.使用轮廓系数来评判k-means算法分类的准确度
- 计算样本i到同簇其他样本的平均距离ai。ai 越小,说明样本i越应该被聚类到该簇。将ai 称为样本i的簇内不相似度。
- 计算样本i到其他某簇Cj 的所有样本的平均距离bij,称为样本i与簇Cj 的不相似度。定义为样本i的簇间不相似度:bi =min{bi1, bi2, ..., bik}
* si接近1,则说明样本i聚类合理
* si接近-1,则说明样本i更应该分类到另外的簇
* 若si 近似为0,则说明样本i在两个簇的边界上。
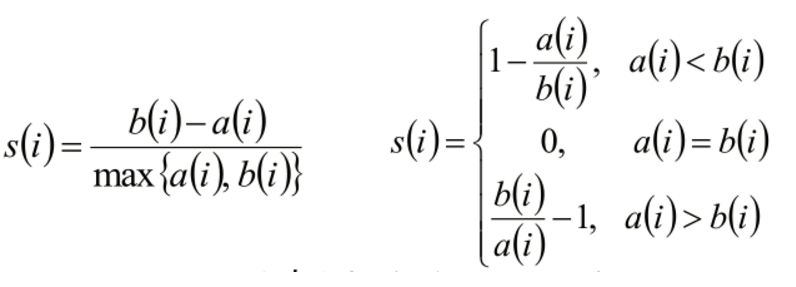
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaled_cluster)
score = metrics.silhouette_score(X,beer.cluster)
print(score_scaled, score)
0.179780680894 0.673177504646
如上是数据归一化和未归一化的轮廓系数,未进行归一化的数据使用k-means算法反而分类效果更好
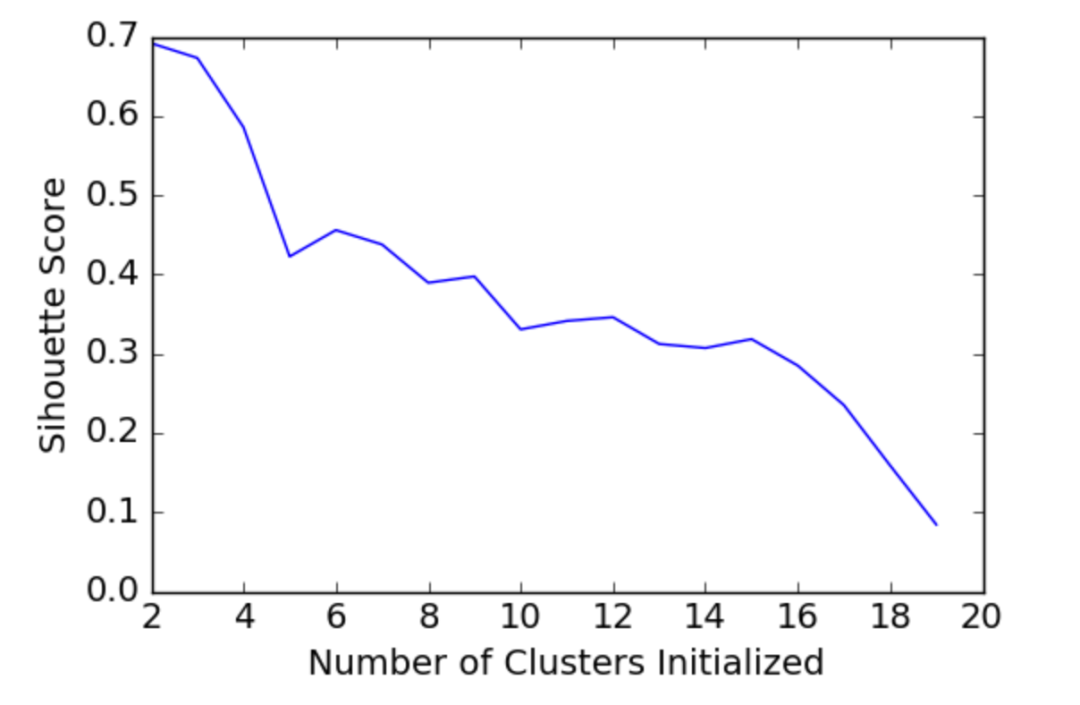
10.对k值进行遍历,选取轮廓系数最高的k值
scores = []
for k in range(2,20):
labels = KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X, labels)
scores.append(score)
scores
[0.69176560340794857,
0.67317750464557957,
0.58570407211277953,
0.42254873351720201,
0.4559182167013377,
0.43776116697963124,
0.38946337473125997,
0.39746405172426014,
0.33061511213823314,
0.34131096180393328,
0.34597752371272478,
0.31221439248428434,
0.30707782144770296,
0.31834561839139497,
0.28495140011748982,
0.23498077333071996,
0.15880910174962809,
0.084230513801511767]
11.画出不同k值轮廓系数变化图
plt.plot(list(range(2,20)), scores)
plt.xlabel(
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Sihouette Score")
如下是本次试验的数据集,复制粘贴到data.txt文件即可
name calories sodium alcohol cost
Budweiser 144 15 4.7 0.43
Schlitz 151 19 4.9 0.43
Lowenbrau 157 15 0.9 0.48
Kronenbourg 170 7 5.2 0.73
Heineken 152 11 5.0 0.77
Old_Milwaukee 145 23 4.6 0.28
Augsberger 175 24 5.5 0.40
Srohs_Bohemian_Style 149 27 4.7 0.42
Miller_Lite 99 10 4.3 0.43
Budweiser_Light 113 8 3.7 0.40
Coors 140 18 4.6 0.44
Coors_Light 102 15 4.1 0.46
Michelob_Light 135 11 4.2 0.50
Becks 150 19 4.7 0.76
Kirin 149 6 5.0 0.79
Pabst_Extra_Light 68 15 2.3 0.38
Hamms 139 19 4.4 0.43
Heilemans_Old_Style 144 24 4.9 0.43
Olympia_Goled_Light 72 6 2.9 0.46
Schlitz_Light 97 7 4.2 0.47
以上就是本次的k-means巩固小实验,抽时间动动手练习一下吧后台回复聚类实战可获取相应代码和数据集
喜欢的话点个关注哦~ 会每天分享人工智能机器学习内容,回复关键字可获取相关算法数据及代码~
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









