






前面的章节我们已经讲解了神经网络的构成参数更新方式和一些弊端以及解决方法,接下来进入实战环节,让我们以一个小项目来入手神经网络。
- 生成输入数据
首先,先来看下我们的数据:
生成以上三类数据的代码如下所示: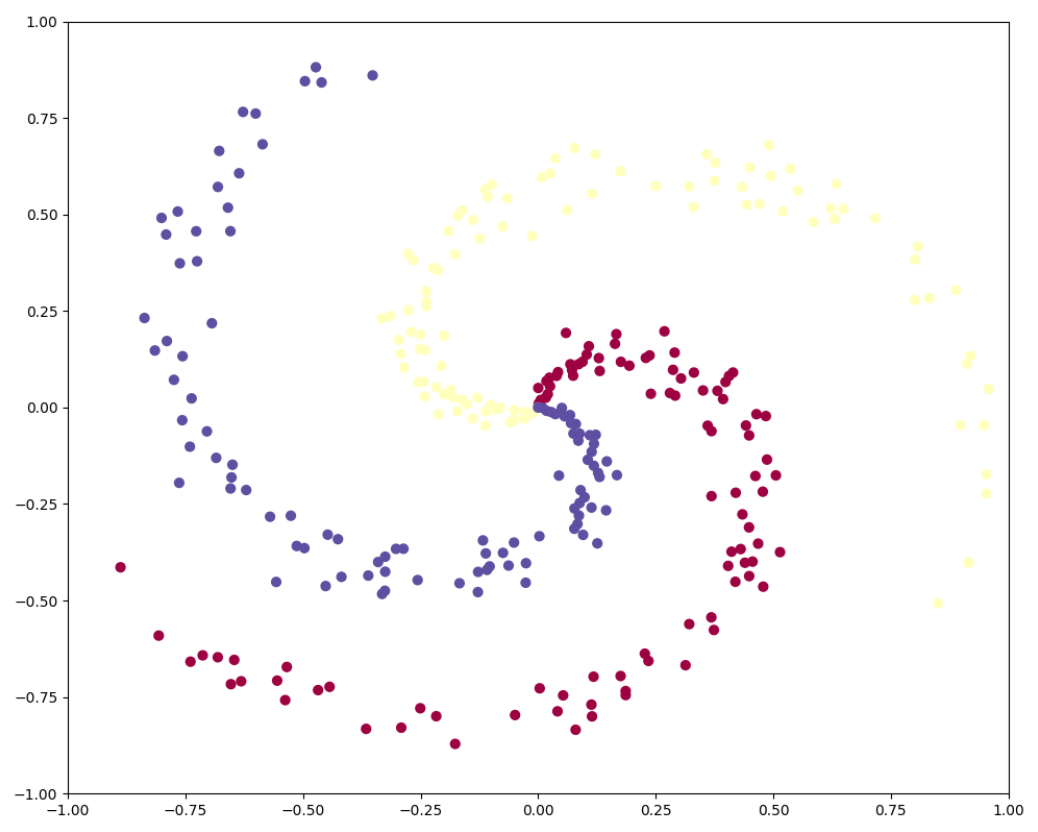

其中:
-
np.random.seed:接受一个整数参数seed,用来指定随机数生成器的种子。具体来说,当我们设置了种子之后,每次运行程序时,使用相同的种子参数,产生的随机数序列将保持一致。 -
np.zeros:是 NumPy 中用于创建指定形状的全零数组(或多维数组)的函数。 -
np.linspace:是 NumPy 中用于生成等间隔的数字序列的函数,它会在指定的范围内返回均匀间隔的数字。numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
-
np.c_:是 NumPy 中用于按列连接数组的类似索引对象。它允许将多个数组按列方向(即沿着第二个轴)
2. 神经网络分类
代码如下,我会逐行解释每句代码的含义:import numpy as np import matplotlib.pyplot as plt np.random.seed(0) N = 100 # number of points per class D = 2 # dimensionality K = 3 # number of classes X = np.zeros((N*K,D)) y = np.zeros(N*K, dtype='uint8') for j in xrange(K): ix = range(N*j,N*(j+1)) r = np.linspace(0.0,1,N) t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
---以上是输入数据的生成代码,这里不再赘述。
h = 100 # size of hidden layer
W = 0.01 * np.random.randn(D,h)# x:300*2 2*100
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))---隐藏层有100个神经元;
---隐藏层的w权重参数是2*100的矩阵,前面的0.01是权重惩罚值,防止过拟合,b初始为1*100的全0矩阵;
---输出层w2权重参数100*3的矩阵,b初始为1*3的全0矩阵;
step_size = 1e-0---学习率,学习率较大可以快速收敛,但容易陷入局部最优解;学习率过小可以使模型更加稳定,
---但是学习速度会变慢
reg = 1e-3
---正则化强度
num_examples = X.shape[0]
for i in xrange(2000):
---神经网络迭代次数2000
hidden_layer = np.maximum(0, np.dot(X, W) + b)
---前向传播:输入层 f=w*x+b,隐藏层应用relu函数,np.maximum(0,)就是relu函数
scores = np.dot(hidden_layer, W2) + b2
---输出层:f2=w2*h+b2
exp_scores = np.exp(scores)probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
---定义softmax函数,计算x属于每个类别的概率
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2)
loss = data_loss + reg_loss
if i % 100 == 0:
print "iteration %d: loss %f" % (i, loss)---计算交叉熵损失并且正则化
---总损失为交叉熵损失和 L2 正则化损失的总和
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples---softmax函数的梯度
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)---输出层w2和b2的梯度
dhidden = np.dot(dscores, W2.T)
dhidden[hidden_layer <= 0] = 0
---relu函数的梯度
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
---输入层w和b的梯度
dW2 += reg * W2
dW += reg * W---对各层梯度加入正则化,防止过拟合
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print 'training accuracy: %.2f' % (np.mean(predicted_class == y))---更新各层参数
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.maximum(0, np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b), W2) + b2
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())plt.show()
---
np.meshgrid是 NumPy 库中的一个函数,用于生成多维网格。当我们需要在多维空间中对数据进行计算或者可视化时,meshgrid函数非常有用---plt.contourf是 Matplotlib 库中用于绘制二维等高线填充图的函数。它可以用于可视化二维数据的分布或函数的等高线图,并且可以根据数据的数值范围自动填充不同颜色的区域---
plt.scatter是 Matplotlib 库中用于绘制散点图的函数,它可以用于可视化二维数据点的分布情况。散点图是一种常用的数据可视化方式,可以展示数据点之间的分布关系、聚类情况或者其他特征---
---训练完之后对神经网络进行可视化,可得到如下图像
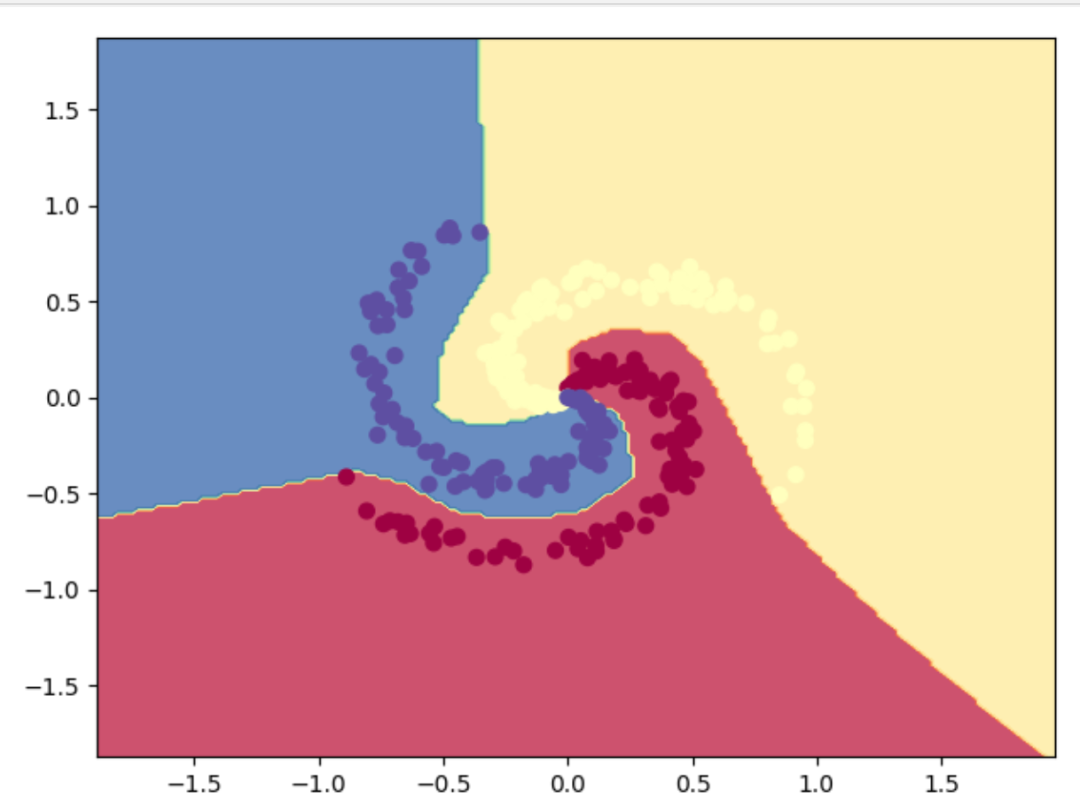
喜欢的话点个关注哦~会每天分享人工智能机器学习内容,回复关键字可获取相关算法数据及代码~
-
-
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









