







设计需求
Spark RDD 的设计目的是为了实现快速、可扩展和容错的数据处理。它是一个不可变的分布式数据集,可以在集群中分布式存储和处理数据。RDD 提供了一系列操作来处理数据,包括转换操作和行动操作。转换操作可以将一个 RDD 转换为另一个 RDD,而行动操作则可以将数据从 RDD 中获取出来并执行计算。RDD 的设计目的是为了充分利用内存和磁盘的性能,同时提供良好的容错性和可伸缩性。RDD 的设计允许数据可以在内存中缓存,以提高查询性能,并且可以在节点之间分布式存储和处理数据,以实现可伸缩性。同时,RDD 的设计还提供了多种容错机制,以保证数据处理的正确性。
说明
Spark RDD(Resilient Distributed Datasets)是一个弹性分布式数据集,是Spark中最基本的抽象概念。它是一个只读的、分区的、可伸缩的数据集,可以被分布式地存储在集群的节点上。RDD可以从外部数据源创建,也可以从其他RDD转换而来。
RDD有两个主要特征:弹性和分布式。弹性表示RDD可以自动地恢复数据丢失,因为它具有完全可重构性,即可以从其原始数据源重新计算出数据集的所有分区。分布式表示RDD可以在集群中分布式存储和处理数据,从而实现高效的数据处理。
RDD支持两种操作:转换操作和行动操作。转换操作会生成一个新的RDD,而行动操作会返回一个结果或副作用。转换操作包括map、filter、flatMap等,行动操作包括reduce、count、collect等。
RDD是Spark的核心组件之一,它提供了高效的、分布式的数据处理能力,被广泛应用于数据分析、机器学习、图计算等领域。
原理
首先,Spark会将数据集分成多个分区,每个分区都会被存储在不同的节点上。
接着,Spark会在集群中的节点上执行数据转换和计算操作,这些操作可以通过RDD方法来定义。
当执行RDD方法时,Spark会将操作应用于每个分区中的数据,并生成新的RDD。
如果新的RDD需要跨多个分区计算,Spark会将数据移动到需要计算的节点上,并在节点之间传递数据。
最后,当计算完成时,Spark会将结果返回给驱动程序,驱动程序可以将结果保存到磁盘或将其返回给用户。
总的来说,Spark RDD方法执行流程原理是将数据集分成多个分区,通过RDD方法定义操作,将操作应用于每个分区中的数据,并生成新的RDD,将数据移动到需要计算的节点上,并在节点之间传递数据,最后将结果返回给驱动程序。
使用方法
创建 RDD:可以从本地文件系统、HDFS、HBase、Cassandra、JSON、CSV 等多种数据源中创建 RDD。
转换 RDD:使用转换函数,如 map、filter、reduceByKey 等对 RDD 进行转换,生成新的 RDD。
行动操作:使用行动操作函数,如 count、collect、reduce、foreach 等触发计算过程,并返回结果。
持久化 RDD:使用 persist 或 cache 方法将 RDD 缓存到内存或磁盘,提高后续计算的性能。
分区和并行度:使用 partitionBy 和 repartition 等方法可以对 RDD 进行分区和重新分区,从而控制并行度。
RDD 的转换和持久化是惰性的,只有在行动操作时才会真正触发计算过程。
可以通过 Spark Web UI 查看 RDD 的依赖关系和分区情况。
通过 Spark 的分布式计算能力,可以对大规模数据集进行高效的分布式处理。
可以使用 Spark 提供的 API 进行交互式数据分析,如 Spark SQL、DataFrame 等。
总之,Spark RDD 是 Spark 的核心数据结构,可以帮助我们高效地处理大规模数据集。掌握 Spark RDD 的使用方法,可以让我们更好地利用 Spark 的强大分布式计算能力。
方法举例说明
map
map(func): 将RDD中的每个元素通过func函数映射为一个新的元素。例如:
rdd = sc.parallelize([1, 2, 3, 4, 5])
new_rdd = rdd.map(lambda x: x + 1)
print(new_rdd.collect()) # 输出 [2, 3, 4, 5, 6]
filter
filter(func): 过滤掉不符合条件的元素,返回符合条件的元素组成的新的RDD。例如:
rdd = sc.parallelize([1, 2, 3, 4, 5])
new_rdd = rdd.filter(lambda x: x % 2 == 0)
print(new_rdd.collect()) # 输出 [2, 4]
flatMap
flatMap(func): 将RDD中的每个元素通过func函数映射为一个新的元素,并将所有新元素组成的序列合并成一个序列。例如:
rdd = sc.parallelize([1, 2, 3])
new_rdd = rdd.flatMap(lambda x: [x, x * 2, x * 3])
print(new_rdd.collect()) # 输出 [1, 2, 3, 2, 4, 6, 3, 6, 9]
union
union(otherRDD): 返回一个新的RDD,包含原RDD和otherRDD中的所有元素。例如:
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize([4, 5, 6])
new_rdd = rdd1.union(rdd2)
print(new_rdd.collect()) # 输出 [1, 2, 3, 4, 5, 6]
distinct
distinct(numPartitions=None): 返回一个新的RDD,包含原RDD中的所有不重复元素。可以指定numPartitions参数来控制输出的分区数。例如:
rdd = sc.parallelize([1, 2, 3, 2, 3])
new_rdd = rdd.distinct()
print(new_rdd.collect()) # 输出 [1, 2, 3]
groupByKey
groupByKey(numPartitions=None): 对RDD中的key-value对进行分组,并返回一个新的RDD,其中每个key对应一个元素,值为该key的所有value组成的序列。可以指定numPartitions参数来控制输出的分区数。例如:
rdd = sc.parallelize([(1, ‘a’), (1, ‘b’), (2, ‘c’), (2, ‘d’)])
new_rdd = rdd.groupByKey()
print(new_rdd.collect()) # 输出 [(1, <pyspark.resultiterable.ResultIterable object at 0x7f3c3d68de50>), (2, <pyspark.resultiterable.ResultIterable object at 0x7f3c3d68d910>)]
for key, values in new_rdd.collect():
print(key, list(values))
输出
1 [‘a’, ‘b’]
2 [‘c’, ‘d’]
reduceByKey
reduceByKey(func, numPartitions=None): 对RDD中的key-value对进行分组,并对每个key对应的value使用func函数进行reduce操作,返回一个新的RDD,其中每个key对应一个元素,值为该key的所有value经过reduce操作后的结果。可以指定numPartitions参数来控制输出的分区数。例如:
rdd = sc.parallelize([(1, 2), (1, 3), (2, 1), (2, 2)])
new_rdd = rdd.reduceByKey(lambda x, y: x + y)
print(new_rdd.collect()) # 输出 [(1, 5), (2, 3)]
sortByKey
sortByKey(ascending=True, numPartitions=None): 对RDD中的key-value对按照key进行排序,并返回一个新的RDD,排序的顺序可以通过ascending参数来指定,numPartitions参数用于控制输出的分区数。例如:
rdd = sc.parallelize([(2, ‘b’), (1, ‘a’), (3, ‘c’)])
new_rdd = rdd.sortByKey()
print(new_rdd.collect()) # 输出 [(1, ‘a’), (2, ‘b’), (3, ‘c’)]
注意事项
一定要注意 RDD 的持久化和缓存,可以大大提高计算效率。
RDD 的转换操作是惰性执行的,只有遇到动作操作才会真正执行计算。
在对 RDD 进行操作时,应尽量避免使用匿名函数和闭包,因为它们会增加序列化和传输的负担,降低执行效率。
在使用算子时,应尽可能使用宽依赖算子(如 groupByKey、reduceByKey),而避免使用窄依赖算子(如 map、filter),因为宽依赖算子可以并行处理,而窄依赖算子只能串行处理。
在进行并行计算时,应尽量避免数据倾斜,即避免某个节点的数据量过大,导致该节点成为整个计算过程的瓶颈。
在 RDD 操作过程中,应注意内存使用情况,及时进行垃圾回收和资源释放,以避免内存溢出和资源浪费。
在进行 RDD 操作时,应尽量避免频繁读写 HDFS 或其他分布式文件系统,因为这会增加 I/O 操作的负担,降低计算效率。
其他概念
Shuffle
Shuffle是指在Spark中进行数据重分区的一种操作。当数据需要从一个RDD(Resilient Distributed Dataset)或DataFrame移动到另一个RDD或DataFrame时,shuffle操作就会发生。Shuffle操作通常发生在groupByKey、reduceByKey、join等操作中。
具体来说,Shuffle操作将数据分为多个分区,每个分区都包含来自原始RDD或DataFrame的一些数据。然后,Spark会将这些分区中的数据重新分配到不同的节点上进行处理。这种操作会产生大量的网络传输和磁盘I/O,因此Shuffle操作对于Spark集群的性能和可扩展性具有重要影响。
RDD的依赖关系
在 Spark 中,RDD 分区的数据不支持修改,是只读的。如果想更新 RDD 分区中的数据,那么只能对原有 RDD 进行转化操作,也就是在原来 RDD 基础上创建一个新的RDD。
那么,在整个任务的运算过程中,RDD 的每次转换都会生成一个新的 RDD,因此 RDD 们之间会产生前后依赖的关系。
说白了,就是相当于将对原始 RDD 分区数据的整个运算进行了拆解,当运算中出现异常情况导致分区数据丢失时,Spark 可以还通过依赖关系从上一个 RDD 中重新计算丢失的数据,而不是对最开始的 RDD 分区数据重新进行计算。
在 RDD 的依赖关系中,我们将上一个 RDD 称为父RDD,下一个 RDD 称为子RDD。
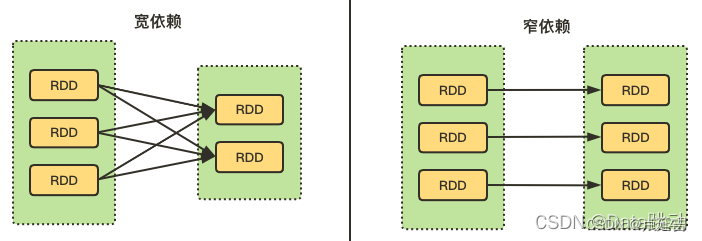
如何区分宽窄依赖
RDD 们之间的依赖关系,也分为宽依赖和窄依赖。
宽依赖 :父 RDD 中每个分区的数据都可以被子 RDD 的多个分区使用(涉及到了shuffle);
窄依赖 :父 RDD 中每个分区的数据最多只能被子 RDD 的一个分区使用。
说白了,就是看两个 RDD 的分区之间,是不是一对一的关系,若是则为窄依赖,反之则为宽依赖。
有个形象的比喻,如果父 RDD 中的一个分区有多个孩子(被多个分区依赖),也就是超生了,就为宽依赖;反之,如果只有一个孩子(只被一个分区依赖),那么就为窄依赖。
常见的宽窄依赖算子:
宽依赖的算子 :groupByKey、partitionBy、join(非hash-partitioned);
窄依赖的算子 :map、filter、union、join(hash-partitioned)、mapPartitions、mapValues;
为何设计要宽窄依赖
从上面的分析,不难看出,在窄依赖中子 RDD 的每个分区数据的生成操作都是可以并行执行的,而在宽依赖中需要所有父 RDD 的 Shuffle 结果完成后再被执行。
在 Spark 执行作业时,会按照 Stage 划分不同的 RDD,生成一个完整的最优执行计划,使每个 Stage 内的 RDD 都尽可能在各个节点上并行地被执行。
如下图,Stage3 包含 Stage1 和 Stage2,其中, Stage1 为窄依赖,Stage2 为宽依赖。
因此,划分宽窄依赖也是 Spark 优化执行计划的一个重要步骤,宽依赖是划分执行计划中 Stage 的依据,对于宽依赖必须要等到上一个 Stage 计算完成之后才能计算下一个阶段。
















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











