







参考:
矩阵分解推荐算法
推荐算法分类:协同过滤推荐、基于内容推荐、基于知识推荐、混合推荐
推荐算法
主要包括以下四种主流的推荐算法:协同过滤推荐、基于内容推荐、基于知识推荐、以及混合推荐。

基于内容
评估用户还没看到的物品与当前用户过去喜欢的物品的相似程度。
步骤:
1、给出物品表示:为每个物品抽取出一些特征来表示此物品;
2、学习用户偏好:利用一个用户过去喜欢(及不喜欢)的物品的特征数据,来学习出此用户偏好;
3、生成推荐列表:根据候选物品表示和用户偏好,为该用户生成其最可能感兴趣的 n 个物品。
优点:
1、用户之间的独立性:既然每个用户的用户偏好都是依据他本身对物品的喜好获得的,自然就与他人的行为无关。而协同过滤推荐刚好相反,协同过滤推荐需要利用很多其他人的数据。基于内容推荐的这种用户独立性带来的一个显著好处是别人不管对物品如何作弊(比如利用多个账号把某个产品的排名刷上去)都不会影响到自己。
2、好的可解释性:如果需要向用户解释为什么推荐了这些产品给他,你只要告诉他这些产品有某某属性,这些属性跟你的品味很匹配等等。
3、新的物品可以立刻得到推荐:只要一个新的物品加进物品库,它就马上可以被推荐,被推荐的机会和老的物品是一致的。而协同过滤推荐对于新的物品就很无奈,只有当此新的物品被某些用户喜欢过(或打过分),它才可能被推荐给其他用户。所以,如果一个纯协同过滤推荐的推荐系统,新加进来的物品就永远不会被推荐。
缺点:
1、物品的特征抽取一般很难:如果系统中的物品是文档,那么我们现在可以比较容易地使用信息检索里的方法来“比较精确地”抽取出物品的特征。但很多情况下我们很难从物品中抽取出准确刻画物品的特征,比如电影推荐中物品是电影,社会化网络推荐中物品是人,这些物品属性都不好抽。其实,几乎在所有实际情况中我们抽取的物品特征都仅能代表物品的一些方面,不可能代表物品的所有方面。这样带来的一个问题就是可能从两个物品抽取出来的特征完全相同,这种情况下基于内容的方法就完全无法区分这两个物品了。
2、无法挖掘出用户的潜在兴趣:既然基于内容推荐只依赖于用户过去对某些物品的喜好,它产生的推荐也都会和用户过去喜欢的物品相似。如果一个人以前只看与推荐有关的文章,那基于内容推荐只会给他推荐更多与推荐相关的文章,它不会知道用户可能还喜欢数码。
3、无法为新用户产生推荐:新用户没有喜好历史,自然无法获得他的用户偏好,所以也就无法为他产生推荐了。当然,这个问题协同过滤推荐也有。
举例说明(个性化阅读):
第一步,对于个性化阅读来说一个 item 就是一篇文章,我们首先要从文章内容中抽取出代表它们的属性。常用的方法就是利用出现在一篇文章中的词来代表这篇文章,而每个词对应的权重往往使用信息检索中的 tf-idf 来计算。利用这种方法,一篇抽象的文章就可以使用具体的一个向量来表示了。
第二步就是根据用户过去喜欢什么文章来产生刻画此用户喜好的 profile 了,最简单的方法可以把用户所有喜欢的文章对应的向量的平均值作为此用户的 profile。
第三步,在获得了一个用户的 profile 后,CB 就可以利用所有 item 与此用户 profile 的相关度对他进行推荐文章了。一个常用的相关度计算方法是 cosine。最终把候选 item 里与此用户最相关(cosine值最大)的 N 个 item 作为推荐返回给此用户。
协同过滤
协同过滤算法有两种:基于邻域的算法(也称为基于内存的协同过滤算法),该算法不需要模型训练,基于非常朴素的思想就可以为用户生成推荐结果。还有一类基于隐因子(模型)的协同过滤算法也非常重要,这类算法中最重要的代表就是矩阵分解算法。前者将所有数据记忆到存储体中。后者(离线)做数据降维,抽象出特征,运行时直接用特征。
优点:
1、模型通用性强:模型不需要太多对应数据领域的专业知识。
2、简单易用:工程实现简单且效果不错。
缺点:
1、用户的冷启动:当没有新用户任何数据的时候,无法较好的为新用户推荐物品。
2、物品的冷启动:当新物品没有用户行为数据是,无法通过协同过滤的方式进行推荐。
3、没有考虑到情景的差异:比如根据用户所在的场景进行推荐。
4、无法得到一些小众的独特喜好:这块是基于内容的推荐比较擅长的。
基于领域的算法
基于用户的协同过滤:给用户推荐和他兴趣相似的其他用户喜欢的物品
基于物品的协同过滤:给用户推荐和他之前喜欢的物品相似的物品
基于用户的协同过滤
步骤:
1.找到与目标兴趣相似的用户集群
2.到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户
缺点:
1、UserCF 需要维护一个用户兴趣相似度的矩阵,随着用户数目增多,维护用户兴趣相似度矩阵的代价越大。计算用户兴趣相似度矩阵的运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。
2、当数据发生变化的时候,之前计算出的用户之间的相似度不稳定。
3、基于用户的协同过滤很难对推荐结果作出解释。
基于物品的协同过滤
步骤:
1、计算物品之间的相似度。
2、根据物品的相似度和用户的历史行为给用户生成推荐列表。
缺点:
1、ItemCF 需要维护一个物品相似度矩阵,随着物品数目增多,维护物品相似度矩阵的代价越大。
基于隐因子(模型)的协同过滤
使用部分机器学习算法,找出用户与项的相互作用模型,从而找出数据中的特定模式。如关联模型,隐语义模型、图模型、混聚类模型、分类模型、回归模型、矩阵分解模型、神经网络模型、合模型、深度学习模型等。
矩阵分解
实现参考:https://github.com/qq209096727/Recommondation-System
https://github.com/ChenJiaDong9219/movieRecommendation
通过机器学习的手段将用户行为矩阵中缺失的数据(用户没有评分的元素)填补完整,最终达到可以为用户做推荐的目标。
最常见的矩阵分解算法就是矩阵奇异值分解(SVD),SVD 在图像压缩、推荐系统、金融数学等领域都有应用,著名的主成成分分析算法(PCA)也是通过 SVD 实现的。
2006年 Netflix Prize 中 Simon Funk 在博客公开的算法被称为(Funk-SVD)。简单的来说就是将原本的 SVD 的思想上加上了线性回归,也就是说,我们可以用均方差作为损失函数,来寻找 P 和 q 的最终值。
基于隐向量的矩阵分解LFM
Koren在2009年提出了基于隐向量的矩阵分解LFM,将原始评分矩阵分解成两个小矩阵p和q。满足r=p*q

优化目标函数

损失函数
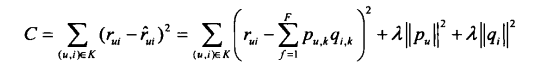
公式介绍

参数
其次,我们通过实验对比了LFM在TopN推荐中的性能。在LFM中、重要的参数有4个:
- 隐特征的个数F;
- 学习速率alpha;
- 正则化参数1ambda;
- 负样本/正样本比例ratio。

LFM性能
可以实现通过用户行为将物品聚类的功能

矩阵分解的目的
是通过机器学习的手段将用户行为矩阵中缺失的数据(用户没有评分的元素)填补完整,最终达到可以为用户做推荐的目标。
因子分解机
S.Rendle在2010年提出的FM(Factorization Machine)模型,此模型的提出是为了解决在数据极其稀疏的情况下的特征组合问题。
基于知识推荐
依赖协同过滤和基于内容方法没有用到的信息源的推荐系统。
基于知识的推荐系统的两种基本类型是:基于约束的推荐和基于实例的推荐。
这两种方法在推荐过程上比较相似:用户必须指定需求,然后系统设法给出解决方案。如果找不到解决方案,用户必须修改需求。此外,系统还需给出推荐物品的解释。
这两种方法的不同之处在于:如何使用所提供的知识。基于实例的推荐系统着重于根据不同的相似度衡量方法检索出相似的物品,而基于约束的推荐系统则依赖明确定义的推荐规则集合。
混合系统推荐
混合推荐的目标是构建一种混合系统,即能结合不同算法和模型的优点,又能克服其中的缺陷。
Burke 的分类方法(2002b)区分出了七种不同的混合策略。从更综合的角度来看,这七种策略可以概括成三种基本设计思路:整体式、并行式和流水线式。并行式和流水线式都具有两个以上的推荐单元,它们的推荐结果被组合起来。整体式混合设计与之不同,它只包含一个推荐单元,通过预处理和组合多个知识源从而将多种方法整合在一起。
整体式:是指将几种推荐策略整合到一个算法中实现的混合设计。根据 Burke(2002b)的分类方法,特征组合和特征补充都可以纳入这个类别。
并行式:多个推荐系统独立运行分别产生推荐列表,再利用一种特殊的混合机制将它们的输出结果整合在一起。Burke(2002b)详细说明了交叉、加权、和切换策略。不过多推荐列表的其他一些组合策略可能也适用,比如多数投票机制
流水线式:将多个推荐系统按照流水线架构连接起来,前一个推荐系统的输出变成后一个推荐系统的输入部分。当然,后面的推荐单元也可以选择使用部分原始输入数据。Burke(2002b)定义的串联和分级混合设计就是这种流水线架构的实例。
距离计算公式
皮尔逊相关系数
皮尔逊相关系数公式实际上就是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。 皮尔逊相关函数是余弦相似度在维度缺失上面的一种改进方法。
def Pearson(x,y):
sum_XY = 0.0
sum_X = 0.0
sum_Y = 0.0
normX = 0.0
normY = 0.0
count = 0
for a,b in zip(x,y):
count += 1
sum_XY += a * b
sum_X += a
sum_Y += b
normX += a**2
normY += b**2
if count == 0:
return 0
# denominator part
denominator = (normX - sum_X**2 / count)**0.5 * (normY - sum_Y**2 / count)**0.5
if denominator == 0:
return 0
return (sum_XY - (sum_X * sum_Y) / count) / denominator
numpy 简化实现皮尔逊相关系数
def Pearson(dataA,dataB):
# 在没有人协同的时候(小于3)直接返回1.0相当于完全相似
if len(np.nonzero(dataA)) < 3 : return 1.0
# 皮尔逊相关系数的取值范围(-1 ~ 1),0.5 + 0.5 * result 归一化(0 ~ 1)
return 0.5 + 0.5 * np.corrcoef(dataA,dataB,rowvar = 0)[0][1]
曼哈顿距离(Manhattan Distance)
def Manhattan(dataA,dataB):
return np.sum(np.abs(dataA - dataB))
print(Manhattan(dataA,dataB))
欧式距离(Euclidean Distance)

def EuclideanDistance(x,y):
d = 0
for a,b in zip(x,y):
d += (a-b)**2
return d**0.5
import numpy as np
def EuclideanDistance(dataA,dataB):
# np.linalg.norm 用于范数计算,默认是二范数,相当于平方和开根号
return 1.0/(1.0 + np.linalg.norm(dataA - dataB))
汉明距离(Hamming distance)
汉明距离表示的是两个字符串(相同长度)对应位不同的数量。比如有两个等长的字符串 str1 = “11111” 和 str2 = “10001” 那么它们之间的汉明距离就是3(这样说就简单多了吧。哈哈)。汉明距离多用于图像像素的匹配(同图搜索)。
Python 的矩阵汉明距离简单运用:
def hammingDistance(dataA,dataB):
distanceArr = dataA - dataB
return np.sum(distanceArr == 0)# 若列为向量则为 shape[0]
实践
待补充
tips:隐式反馈可以通过一定的策略转化为得分















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









