







如有错误,感谢指导
0、单词hive
hive,[haiv],n.蜂房、蜂群,忙碌的场所/地方;v.把蜜蜂收入蜂箱,贮备(zhubei),聚居
其中,贮备之意为【保存、备用】,正好对应了hive作为数据仓库工具的含义。
thrift,n./v.,节省、节约。
1、在计算机领域的Hive(包括 Thrift)

logo既然是大象(Hadoop)、Hive(蜜蜂)的合体!!
hive是基于Hadoop的一个数据仓库工具、基础架构、语言,可将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可将SQL语句转换为MapReduce任务进行运行。
依赖于Hadoop和JDK,底层支持多种不同的执行引擎(Hive on MapReduce、Hive on Tez、Hive on Spark);支持多种不同的压缩格式、存储格式以及自定义函数(压缩:GZIP、LZO、Snappy、BZIP2… ; 存储:TextFile、SequenceFile、RCFile、ORC、Parquet ; UDF:自定义函数)。
Thrift,Apache Thrift,是一种接口描述语言和二进制通讯协议,被用来定义和创建跨语言的服务,被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。
Thrift是一个软件框架,拥有强大的软件堆栈和代码生成引擎,用于可扩展、跨语言的服务开发。在Thrift框架内,象C++、 Java、 Go、Python、PHP、 Ruby、Erlang、Perl、Haskell、 C#、Cocoa、JavaScript、Node.js、Smalltalk、OCaml这些不同编程语言的程序可以实现无缝结合和高效服务。
它主要基于RPC传输协议开发应用。RPC对远程计算机程序的服务请求,跨越了传输层和应用层,因此在包括分布式、多程序在内的应用程序可以更加容易实现,比起HTTP协议要更胜一筹,特别是在大数据时代,Thrift的应用将越来越广泛。
2、必要概念掌握
数据仓库(Data Warehouse):简写DW或DWH,是为企业所有级别的决策制定,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告、决策支持的目的而创建。是决策支持系统(dss)、联机分析应用数据源的结构化数据环境。
数据库(database):是一种逻辑概念,用来存放数据的仓库,通过数据库软件来实现,是由很多表组成,表是二维的 ,一张表里面有很多字段。
数据仓库是数据库概念的升级,前者主要用于数据挖掘、数据分析、辅助领导做决策。
元数据(Metadata):又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property,关于数据的组织、数据域及其关系)的信息(比如:Hive元数据就存储了hive中所有表格的信息,包括表格的名字、表格的字段、字段的类型就是表的定义等),用来支持如存储位置、历史数据、资源查找、文件记录等功能。

3、Hadoop 2.0-Hive
Hive所在hadoop 2.0生态圈中的层次:对SQL的支持,即 SQL解析引擎。其中一个典型的应用场景是与Hbase集成。
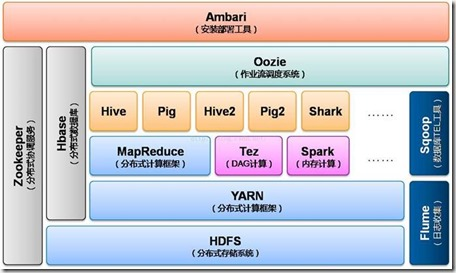
4、Hive发展历程
4.1 产生背景/原因/解决了什么问题
一个东西的产生,大部分都是为了解决某一个问题。先铺垫一下,Hadoop解决了什么问题?
它主要解决了海量数据的存储、分析、学习问题。因为随着数据的爆炸式增长,一味地靠硬件提升数据处理效率、增加存储量,不仅成本高,处理高维数据的效率也不会提升很多,这将是一个瓶颈。
Hadoop的搭建只需要普通的PC机,它的HDFS提供了分布式文件系统;MapReduce是一个并行编程模型,为程序员提供了编程接口,用于解决离线海量数据(文字、图形等)的计算问题。
HDFS(数据存储用)、MR(数据计算用)都屏蔽了分布式、并行底层的细节问题,程序员使用起来简单方便。
而对于大量数据的计算问题,Hadoop自身的MapReduce显得力不从心,一个是MR编程专业性较强,对于开发、测试不方便,在需求变更时也不方便,因为不仅是传统关系型数据库人员熟悉的是SQL,可能世界上会SQL的人比JAVA也多很多(黑人懵逼脸);另一个根本的问题是MR执行效率低,因为maptask、reducetask都是以进程执行的,即使它能够开启JVM,但在使用时得开启进程、不用时得关闭进程,耗费成本。
2004年成立的社交网络巨头Facebook不到一年用户数就超过100万。同年,Hadoop发布了最初版本。
Facebook当初为了解决海量结构化的日志数据统计问题,于是在MR的基础上开发了Hive框架(源码是Java语言),并且开源了。Hadoop是大数据时代的核心技术,而Hive也迅速成为了学习Hadoop相关技术的一个突破口。
4.2 发展历程
- 2007-08:诞生于Facebook;
- 2013-01:发布Hive 0.10.0版本,支持Hadoop 0.20.x、0.23.x.y、1.x.y、2.x.y;
- 2013-05:发布Hive 0.11.0版本,支持Hadoop 0.20.x、0.23.x.y、1.x.y、2.x.y;
- 2013-10:发布 Hive 0.12.0版本,支持Hadoop 0.20.x、0.23.x.y、1.x.y、2.x.y;
- 2014-04:发布 Hive 0.13.0版本,支持Hadoop 0.20.x、0.23.x.y、1.x.y、2.x.y;
- 2014-11:发布 Hive 0.14.0版本,支持Hadoop 1.x.y、2.x.y;
- 2015-02:发布 Hive 1.0.0版本,支持Hadoop 1.x.y、2.x.y;
- 2015-2016:…省略各小版本,1.1.0/1.1.1/1.2.0/1.2.1
- 2016-02:发布 Hive 2.0.0版本,支持Hadoop 2.x.y;
- 2016-2017:…省略各小版本,2.0.1/2.1.0/2.1.1/2.3.0/2.2.0/2.3.1/2.3.2/2.3.3、
1.2.2 - 2018-05:发布 Hive 3.0.0版本,支持Hadoop 3.x.y;
- 2018-07:发布 Hive 3.1.0版本,支持Hadoop 3.x.y;
- 2018-11:发布 Hive 3.1.1版本,支持Hadoop 3.x.y;
- 2018-11-07:发布 Hive 2.3.4版本,支持Hadoop 2.x.y;
- 2019-05-14:发布Hive 2.3.5版本,支持Hadoop 2.x.y;
- 2019-06-12:now
我用的是2017-07发布的Hive 1.2.2,支持Hadoop 1.x.y、2.x.y,本文以及后续文章均以Hive 1.2.2为准,除非特别说明。(用的Hadoop 2.6.5)
5、Hive 1.2.2-体系架构
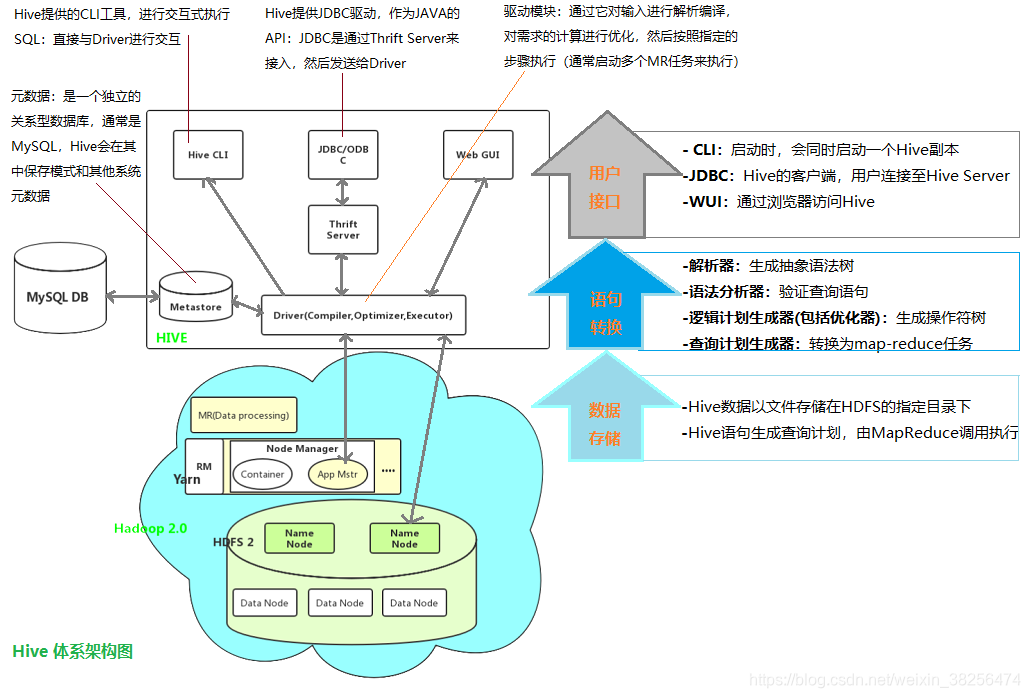
底层共享meta,可以实现Hive与SparkSQL/Pig/Impala/Presto等组件共享元数据信息,也就是说:在Hive中创建一个表,在其他几个组件里也都可以用。
6、工作原理/核心思想
需要处理的数据文件存放在HDFS上,但是HDFS上的文件缺少Schema(字段名,字段类型、索引、外键等),这是没办法使用SQL进行处理的。若想使用SQL去处理它,还需要一个前提:结构化、文件映射成表格---->Schema元数据信息(metastore)。
PS-小插曲:Schema,有位大佬翻译过一篇文章,非常好,详细解释了【数据中的Schema是什么?】
Hive定义了一种类似SQL的查询语言,被称为Hive SQL(只是语法类似,不等同)。
对于熟悉SQL的用户可以直接利用Hive来查询数据。同时,这个语言也允许熟悉 MapReduce 开发者们开发自定义的mappers、reducers来处理内建的mappers和reducers无法完成的复杂的分析工作。
Hive还允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:
- UDF,User Defined Functions
- UDAF,User Defined Aggregation Functions
- UDTF,User Defined Table Generating Functions
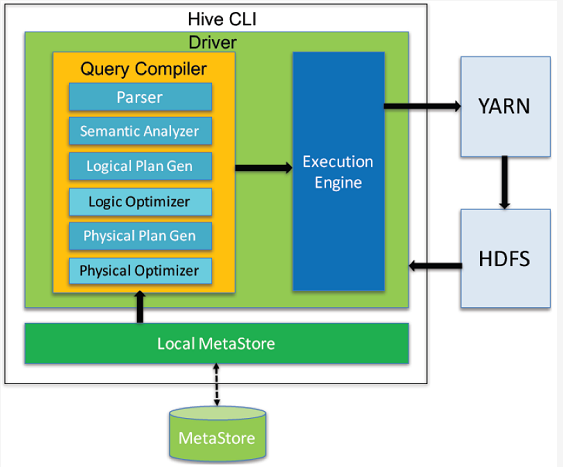
步入正题:Hive的工作原理 本质来说是一个查询引擎,即 Hive SQL任务本质上最后是转化成了MapReduce 任务执行。
Hive SQL转化为MapReduce的过程(编译过程),从接收到一个SQL,接下来做的事情是:
- 1,词法/语法分析:Antlr定义SQL的语法规则,完成SQL词法/语法解析,将SQL转化为抽象语法树AST Tree
- 2,语义分析:从MetaStore获取Schema(模式)信息,验证SQL语句中的表名、列名、数据类型的检查和隐式转换等,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
- 3,逻辑生产计划:生成逻辑计划-算子树
- 4,逻辑计划优化:对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
- 5,物理计划生成:将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
- 6、物理计划执行:将DAG发送到Hadoop集群进行执行
- 7、将查询结果返回
整个流程图如下:
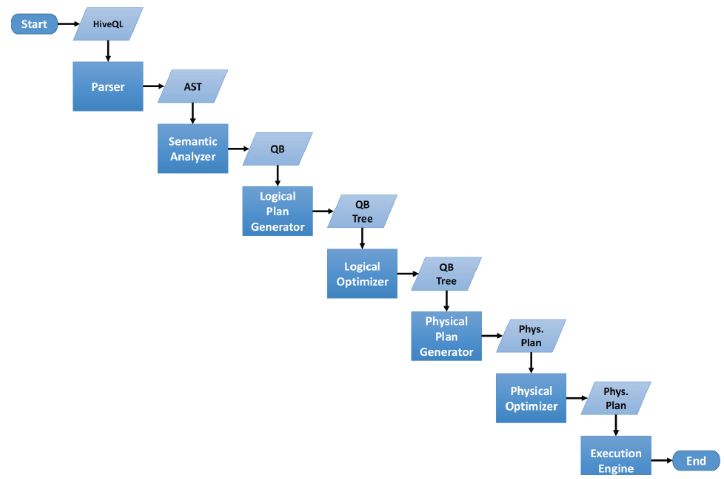
其中,Query Compiler流程图如下:
使用MapReduce作为计算引擎:
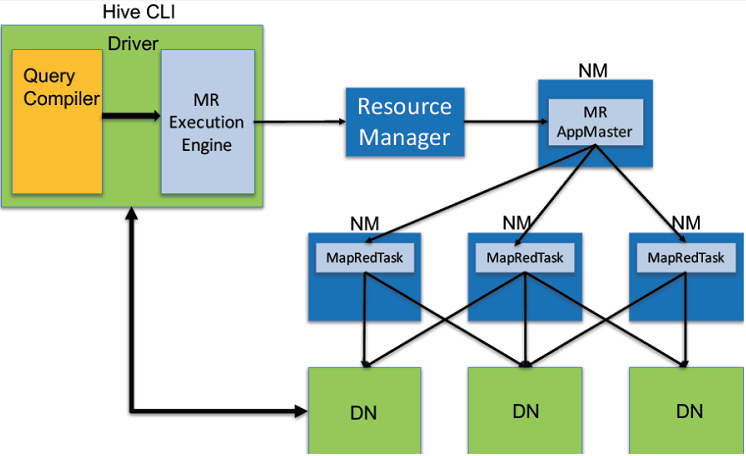
Hive也支持使用Spark或Tez作为执行(计算)引擎:
- Hive
0.12.0起,支持tez - Hive
1.1.0起,支持Spark
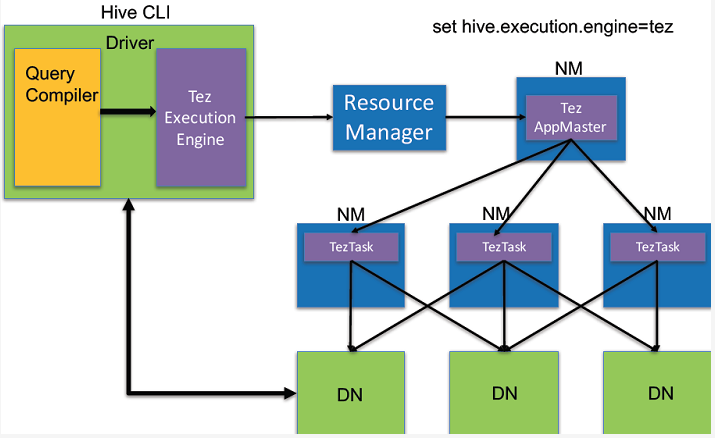
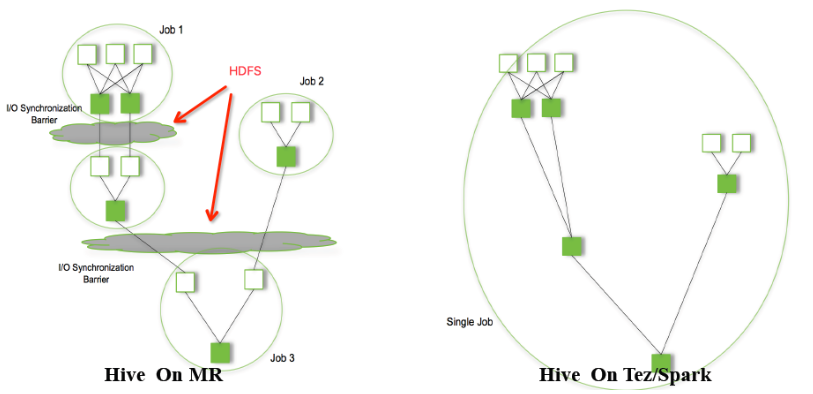
除了DML(Data Manipulation Language,数据操纵语言),Hive也提供DDL(Data Definition Language数据定义语言,与DML都是SQL语言中的概念)来创建表的schema。
Hive数据存储支持HDFS的一些文件格式,比如CSV、Sequence File、Avro、RC File、ORC、Parquet。也支持访问HBase。
Hive提供一个CLI工具(CLI,command line interface),类似Oracle的sqlplus,可以交互式执行sql;提供JDBC驱动作为Java的API。
通过上述流程图,对Hive已经有一个更加纯粹的理解了:
Hive就是一个使用SQL对分布式文件系统上存储的大数据集进行读写管理的data warehouse software (数据仓库软件)。它只是一个客户端,没有集群的概念。
7、Hive、RDBMS异同
Hive是一个数据仓库软件,就很容易想到得让Hive和传统的关系型数据库比一比了。
不过,从结构上来看,Hive和RDBMS除了拥有类似的查询语言,再无类似之处,也就是说 两者是有着很大区别。RDBMS可以用在Online的应用中,但Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。
Hive将外部的任务解析成一个MapReduce可执行计划,而启动MapReduce是个高延迟的一件事,每次提交任务和执行任务都需要消耗很多时间,这也就决定Hive只能处理一些高延迟的应用(如果想处理低延迟的应用,可以去考虑一下Hbase)。
同时,由于设计的目标不一样,Hive不支持事务处理,也不提供实时查询功能;不能对表数据进行修改:
- 不能更新、删除、插入;只能通过文件追加数据、重新导入数据)
- 不能对列建立索引(但是Hive支持索引的建立,不过不能提高Hive的查询速度。如果想提高Hive的查询速度,得运用Hive的分区、桶)
其实对于更新、事务和索引,并非Hive不支持,而是影响性能,不符合最初数据仓库的设计理念。但是随着时间的发展,Hive在很多方面也做出了妥协,这也导致了Hive和传统数据库的区别越来越小。
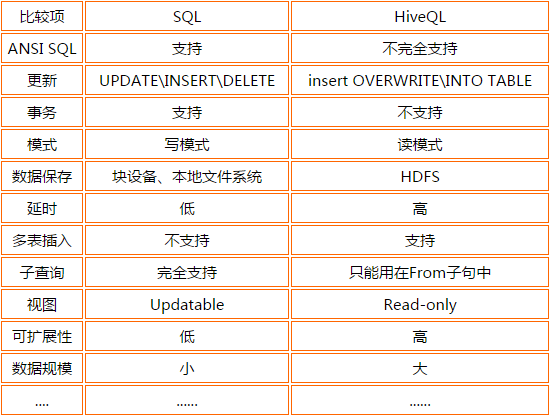
8、Hive优缺点
8.1 Hive优点
-
简单易上手:学习成本低,可通过类SQL语句(HQL)快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
-
可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统)
一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
-
提供统一的元数据管理(可与SparkSQL/Presto/Impala等共享数据)
-
延展性(编程模型):允许开发者自定义UDF、Transform、Mapper、Reducer,来更简单地完成复杂MapReduce无法完成的工作
-
容错:良好的容错性,节点出现问题SQL仍可完成执行
得用它来做擅长的事情!!!
所以,适合的场景:基于大量不可变数据的批处理作业
- 网络日志分析(百度、淘宝等在用)
- 统计网站一个时间段内的pv、uv
- 多维数据分析
- 海量结构化数据离线分析
不适合场景:那些需要低延迟的应用,例如,联机事务处理(OLTP)
8.2 Hive缺点(局限性)
-
Hive的HQL表达能力有限
-
迭代式算法无法表达,比如pagerank
-
数据挖掘方面,比如kmeans
-
-
Hive的效率比较低
-
Hive自动生成的mapreduce作业,通常情况下不够智能化
-
Hive调优比较困难,粒度较粗
-
Hive可控性差
-
9、学习指南
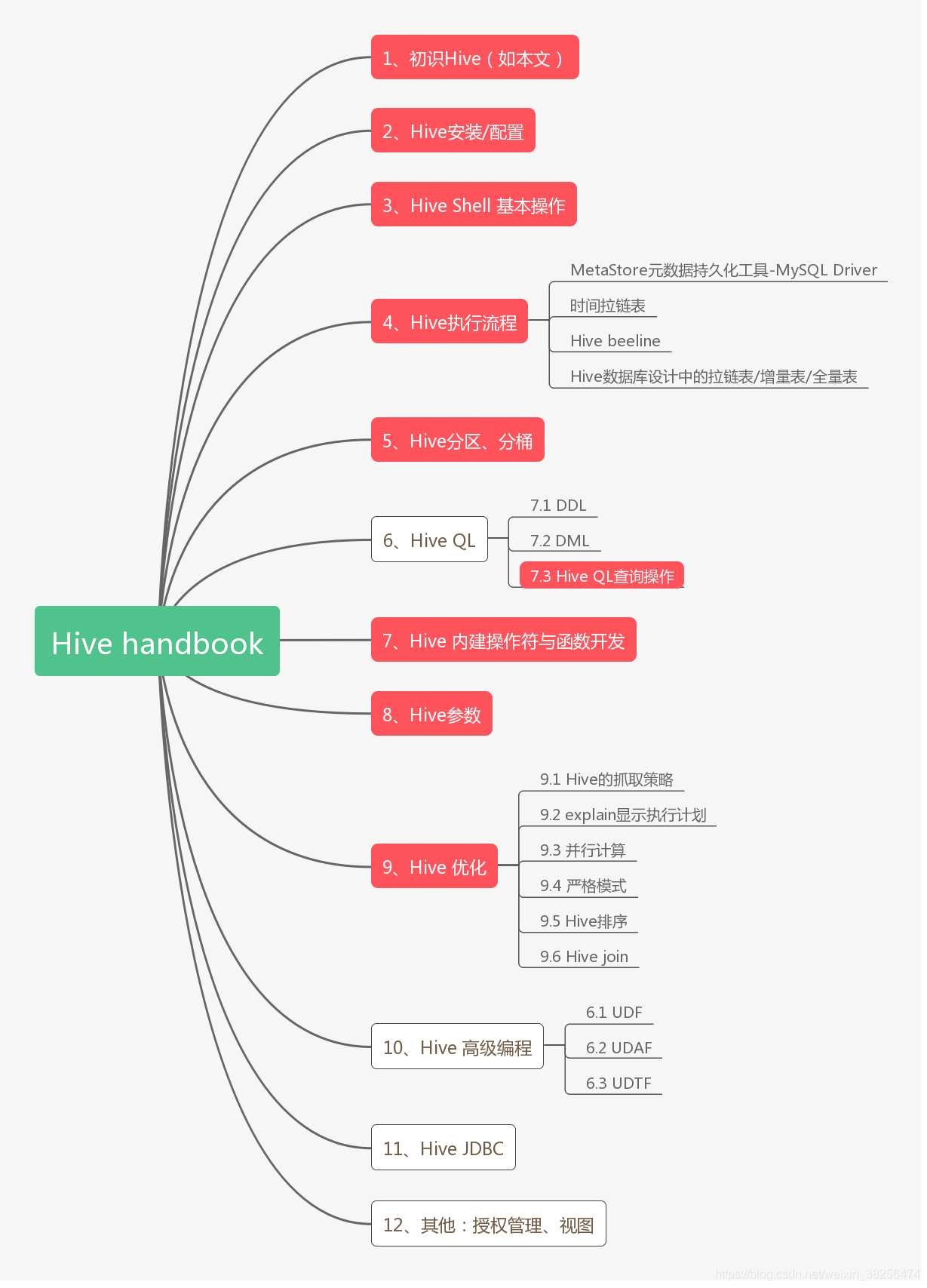
参考:
1、hadoop生态系统主要架构图汇总:写得非常好,特别是对各组件的分类
2、Apache Hive官网
3、百度百科-Hive
4、一张图看懂Hive:对于整体理解Hive非常有帮助
5、Hive SQL 编译过程:非常详细
6、Hive学习手册:仅供参考
7、Hive 1.2.2源码:github

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









