









1.cuda
CUDA (Compute Unified Device Architecture) 是显卡厂商 NVIDIA 推出的运算平台。 CUDA™ 是一种由 NVIDIA 推出的通用并行计算架构,该架构使 GPU 能够解决复杂的计算问题。 它包含了 CUDA 指令集架构(ISA)以及 GPU 内部的并行计算引擎。 开发人员现在可以使用 C 语言, C++ , FORTRAN 来为 CUDA™ 架构编写程序,所编写出的程序可以在支持 CUDA™ 的处理器上以超高性能运行。GPU 云服务器采用 NVIDIA 显卡,需要安装 CUDA 开发运行环境。
安装CUDA开发运行环境:https://docs.ksyun.com/documents/2592
2.cudnn
cuDNN的全称为NVIDIA CUDA® Deep Neural Network library,是NVIDIA专门针对深度神经网络(Deep Neural Networks)中的基础操作而设计基于GPU的加速库。cuDNN为深度神经网络中的标准流程提供了高度优化的实现方式,例如convolution、pooling、normalization以及activation layers的前向以及后向过程。
安装方式:https://docs.ksyun.com/documents/2594
3. NCCL
NCCL是Nvidia Collective multi-GPU Communication Library的简称,它是一个实现多GPU的collective communication通信库,Nvidia做了很多优化,以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。
安装方式:https://docs.ksyun.com/documents/2594
4.slurm
SLURM 是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统。SLURM 维护着一个待处理工作的队列并管理此工作的整体资源利用。它还以一种排他或非排他的方式管理可用的计算节点(取决于资源的需求)。最后,SLURM 将作业分发给一组已分配的节点来执行工作并监视平行作业至其完成。
本质上,SLURM 是一个强健的集群管理器(更关注于对功能丰富性的需求方面),它高度可移植、可伸缩至大型节点集群、容错好,而且更重要的是它是开源的。SLURM 最早是一个开源的资源管理器,由几家公司(包括 Lawrence Livermore National Laboratory)协作开发。如今,SLURM 已经成为了很多最强大的超级计算机上使用的领先资源管理器。
SLURM 架构
SLURM 实现的是一种非常传统的集群管理架构(参见 图 2)。在顶部是一对冗余集群控制器(虽然冗余是可选项)。这些集群控制器可充当计算集群的管理器并实现一种管理守护程序,名为 slurmctld。slurmctld 守护程序提供了对计算资源的监视,但更重要的是,它将进入的作业(工作)映射到基本的计算资源。
每个计算节点实现一个守护程序,名为 slurmd。slurmd 守护程序管理在其上执行的节点,包括监视此节点上运行的任务、接受来自控制器的工作,以及将该工作映射到节点内部核心之上的任务。如果控制器发出请求,slurmd 守护程序也可以停止任务的执行
 SLURM 架构的高级别视图
SLURM 架构的高级别视图
此架构内还存在其他的守护程序,比如,实现安全的身份验证。但是集群并不仅仅是节点的随机组合,因为这些节点可以是逻辑相关的,以适时实现平行计算。
一组节点也可以组成一个逻辑组,称为分区,分区通常会包含进入工作的队列。分区也可以配置各种约束条件,比如哪个用户可以使用它,分区支持的时限的作业大小。分区的更进一步优化,就是将分区内的一组节点在工作的一段时间内映射到一个用户,这就是一个作业。一个作业内,是一个或多个作业步骤,即在节点子集上执行的任务集。
分区内一组节点一段时间内映射到一个用户即一个作业。
一个作业里有一个或者多个作业步。

上图展示了这个层次结构,进一步说明了资源的 SLURM 分区。请注意,这种分区包含了对资源的感知,相当于确保协作节点间的低延迟通信。
项目中主要用到srun命令交互式提交并行作业
- 主要用到的命令解释:
- –mpi=pmi2

- -p HA_senseAR
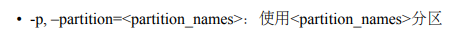
- -n1

- –gres=gpu:8
- 每个节点使用8张卡性能最优(公司设计)
- –ntasks-per-node=8 ·

- –job-name=align_exp


188:这种写法不合理,最好写成1,1,1。
上述命令:总共一个任务,每个节点用8张卡,每个节点执行8个任务。这样不合理,应该是总共一个任务,分配到一个节点下的1张卡,因为一张卡正好执行一个任务。
- –mpi=pmi2
备注: --gres=gpu --ntasks-per-node 一般设置成一样就好,对应了每个任务用一张卡跑。这样在设置-n时候,设置成几就是几卡跑,对应了我们常说的用几卡跑。
slurm参考文档:http://hmli.ustc.edu.cn/doc/userguide/slurm-userguide.pdf
5. MPI ,openmpi,intelMPI



参考:http://blog.sina.com.cn/s/blog_151391cb60102z0e3.html
8.LinkLink torch.distributed















 5190
5190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









