






英文原文链接:
分形树与日志结构合并 (LSM) 树的比较
Bradley C. Kuszmaul
首席架构师
Tokutek
bradley@tokutek.com
2014 年 4 月 22 日
1 简介
我将用这份白皮书来对分形树和日志结构合并树进行比较、讨论。
本文解释了分形树索引相对于日志结构合并 (LSM) 树的优势。LSM 树最初由 O'Neil [13] 提出,现已在多个系统中实现,包括 [8-10, 12, 14, 17]。 分形树索引以对流式 B 树的研究 [4]为基础,部分借鉴了早期关于缓冲存储库树的算法工作 [6, 7]。分形树索引出现在 Tokutek 的数据库产品 [16] 中。
我将使用渐近分析和“典型”的在 64GB 内存的机器上运行的 10TB 数据库,从几个质量的衡量标准:写放大、读放大和空间放大,来比较这些数据结构。我将尝试用块大小 B、扇出 k、内存大小 M 和数据库大小 N 来表达这些,尽管比较不同的数据结构可能很困难,因为,举例来说,它们根据各自的特点选择不同的扇出。
2 目标
本节介绍我将会使用的质量指标,包括写放大、读放大和空间放大。
2.1 写放大
写放大是写入存储的数据量与应用程序写入的数据量之比。 相比于传统的 B 树,LSM 树和分形树索引都具有显著的优势。例如,如果一个数据库行包含 100 个字节,像 InnoDB 这样的 B 树使用 16KiB 大小的页[11],那么 B 树可能会执行 16KiB 的 I/O 来写入一个 100 字节的行,写放大就是160,相比之下,另外两种数据结构的写放大则是 30 到 70。
这种简单的写放大计算低估了 LSM 树和分形树的优势。但是,在同样情况下,相比于 16KiB 块的写放大为 160,使用 1MiB 块写放大的情况将更加糟糕,要差一个数量级(至少对于旋转磁盘来说)。由于本文的目标是将 LSM 树与分形树进行比较,因此我不会太担心这个指标使 B 树看起来比它们更好的事实。
写放大的问题在旋转磁盘和固态磁盘 (SSD) 上都存在,但是是由于不同的原因。正如我上面提到的,对于旋转磁盘,写放大并不能说明全部问题,因为许多小写入比相同总字节数的大写入要慢。但是 LSM 树和分形树的索引都执行大写操作,对此我们只关心带宽。磁盘通常具有有限的带宽(比如,每个驱动器 100MB/s)。
对于 SSD,写放大之所以是一个问题,是因为基于闪存的 SSD 只能写入有限的次数。执行随机更新的 B 树很容易用尽闪存的寿命。更小的写入放大可以帮助降低成本,因为您可以购买更便宜的闪存(可写入的次数更少),并且由于写入块更大,您可以提高存储有用数据的闪存存储的比例。
由于以下几点原因,更大的写入块对 SSD 是有利的。基于闪存的固态硬盘 (SSD) 的闪存转换层(FTL)会增加 SSD 内部闪存所经历的写放大。例如,对于配置利用率为 80% 的 SSD,在均匀随机写入的工作负载下,擦除块大小为 256KiB,B 树块大小为 16KiB,FTL 会再导致 5 倍的写放大。一般而言,如果 SSD 提供其存储的一小部分 r 给用户使用,并且块是随机写入的,并且如果写块的大小远小于擦除块的大小,则 FTL 会再导致 1/(1−r) 的写放大。
压缩可以进一步减少写放大。减少未压缩的写放大可以通过减少需要压缩的数据的量来降低 CPU 负载,从而提高性能。使用轻量级的压缩器可以降低这种成本,代价是降低压缩因子和提高写放大倍数。因此,较低的未压缩写放大可以使得使用更昂贵的压缩器成为可能,进而进一步降低在磁盘上看到的写放大。
取决于数据结构,写放大可能会被应用程序的写入模式影响。比如,写入随机均匀分布的密钥(例如在 iiBench [15] 中)和写入满足 Zipfian 分布 [18] 的偏斜密钥(例如在 LinkBench [2] 中)具有不同的写放大。
2.2 读放大
读放大是满足特定查询所需的 I/O 数量。读放大有两种重要的情况:冷缓存和热缓存。例如,对于冷缓存情况下的 B 树,点查询需要的 I/O 次数为 ,而对于大多数适当的 RAM 和磁盘配置,在热缓存的情况下,B 树的内部节点是被缓存的,因此 B 树每次查询最多需要一次 I/O。均匀随机与偏斜的选择也会影响读放大。
一些读取是为了点查询执行的,我们只是查找一个特定的键。一些读取是为了范围查询执行的,我们想要所有键在特定范围内的键值对。这两个问题是不同的,因为,比如布隆过滤器 [5] 可以优化点查询的读放大,但似乎对范围查询没有帮助。
请注意,写放大和读放大的单位不同。写放大衡量写入的数据比应用程序认为它写入的多多少,而读放大计算执行一次读取的 I/O 的次数。
2.3 空间放大
数据结构所需的空间可能因碎片或数据临时副本的要求而膨胀。 例如,由于 B 树块内的碎片,B 树通常只能实现 75% 的空间利用率。 因此 B 树的空间放大为 4/3。
3 B 树
在深入研究 LSM 树和分形树之前,我将先快速回顾一下 B 树。B 树索引是一种搜索树,其中树的每个节点都可以有许多子节点。B 树包含两种节点,叶节点和内部节点。叶节点包含数据记录,没有子节点,而内部节点有子节点和主键,但没有数据记录。有一个没有父节点的根节点。 其他每个节点都有一个父节点。 图 1 是一个 B 树的示例。

图 1:包含前二十个素数的 B 树(改编自 [3])。树的内部节点为黄色阴影,包含主键,而叶节点为粉色阴影,仅包含数据记录。根节点显示在树的顶部,在这个例子里恰好只含有单个主键(19),表示键小于等于 19 的记录存储在第一个子节点中,键大于 19 的记录存储在第二个子节点中。第一个子节点包含两个主键(7 和 13),表示键小于等于 7 的记录存储在第一个子节点中,那些键大于 7 小于等于 13 的记录存储在第二个子节点中,键大于 13 的记录存储在第三个子节点中。 最左边的叶节点包含四个值(2、3、5 和 7)。
通常,B 树被组织成具有统一的深度(即每一个叶节点到根结点的距离都是相同的)。
B 树的节点有多大?理论文献(例如,参见 [1] 的磁盘访问模型 (DAM))通常假设底层磁盘驱动器使用固定大小的块,并设置 B 树块的大小与设备块的大小匹配。为了简化分析,该理论假设所有块的访问成本都相同(实际磁盘在块之间表现出局部性,而且靠近磁盘外边缘的块的访问速度比靠近内边缘的块的访问速度要快)。该理论进一步假设没有小块或大块之类的东西,所有我们需要做的就是计算从磁盘获取和存储到磁盘的块数。该理论将树的块大小表示为 B,并假设键、指针和记录大小固定,因此每个内部节点包含 个子节点,每个叶节点包含
个数据记录。 (根节点是一种特殊情况,在某些情况下可能几乎是空的。)尽管存在所有这些不切实际的假设,但 DAM 理论仍然运行良好。在 DAM 模型中,一棵 B 树的深度为
,
,其中 N 是数据库的大小。
搜索或插入数据记录的成本有多高?搜索任意键所需的磁盘 I/O 次数最多为 ,因为这是树的深度。插入同样需要
的磁盘 I/O 次数。在具有缓存的系统中,一旦缓存预热,树的所有内部节点通常都会被缓存,因此搜索或插入可能仅需要一次 I/O。
我听到的一个常见误解是插入很昂贵,因为保持树的平衡很困难。(保持树的“平衡”包括保持树具有统一深度以及每个节点都有 个子节点。)虽然保持 B 树的平衡很棘手(这样做的代码通常非常复杂),但为了保持树的平衡几乎不会产生额外的 I/O。
实际上,大多数工程实现的 B 树选择以字节为单位的块大小 B。键和数据记录的大小都是可变的,因此真正的 B 树通常只是尽可能地填充它们的节点。这意味着每个节点的子节点数量(以及树的深度)取决于主键的大小。
B 树的写放大是多少?对于最坏情况的插入工作负载,每次插入都需要写入包含记录的叶块,因此写放大为 B(译者注:也就是上面说明的块的大小)。您可能很幸运,在将叶块从缓存中逐出之前,把两条或更多记录写入同一个叶块,但如果您的数据库远大于您的缓存,并且您执行随机插入,那么大多数插入都会导致一个完整的块的写入。要了解这种写放大有多糟糕,我们需要搞清楚如何为 B 树选择块大小。
在不同的实现里,B 树的块的大小差别很大:许多数据库使用 4KiB 块或 16KiB 大小的块,但有些使用更大的块。执行大量写入的数据库似乎更喜欢较小的块,而以读取为主的数据库似乎更喜欢使用较大的块,有时会达到 1 兆字节或更多。这是因为大块会加剧写放大,但是可以使树更浅以提升搜索性能。
事实证明,4KiB 或 16KiB 太小,无法在旋转磁盘上获得良好的性能,因为对于典型的磁盘,寻道时间可能为 5ms,传输速率可能为 100MB/s。 如果你写 4KiB 块,你将花费 5ms 寻道,0.04ms 传输数据,因此在一个应该能够做到 100MB/s 的磁盘上只实现 819KB/s 的传输速率。 为了充分利用磁盘,我们真的需要块大小处于范围的大端(接近兆字节)。B 树因此迫使数据库工程师陷入不愉快的境地。
4 分形树索引
讨论了 B 树之后,我现在将讨论分形树索引,我将其缩写为 FT 索引。 FT 索引背后的想法是维护一个 B 树,其中树的每个内部节点都包含一个缓冲区。
图 2 是一个 FT 索引的示例。除了有额外的缓冲区,这棵树与图 1 的 B 树非常相似。在这个示例中,FT 索引的缓冲区是空的。

图 2:包含前 20 个素数的 FT 索引(除了缺少 23、31、41 和 43)。 该数据结构在内部节点中包含缓冲区(用蓝色表示)。在此处显示的 FT 索引中,缓冲区为空。
图 3 显示了 FT 索引如何使用缓冲区。 当一个数据记录被插入树时,我们只是将数据记录插入到树的根节点的缓冲区中,而不是像 B 树那样遍历整棵树。

图 3:向图 2 的 FT 索引中插入 23、41 和 43 后的 FT 索引。这些新插入的记录现在出现在树根的缓冲区中。
最终根节点的缓冲区会被新的数据记录填满。 那时 FT 索引将插入的记录复制到树的下一层。 最终,新插入的记录将到达叶子节点,此时它们会按照 B 树的存储方式,简单地将记录存储在叶子节点中。

图 4:向图 3 中的 FT 索引插入 31 之后,FT 树将 41 和 43 移动到根的子节点中。
通过树的缓冲区下降的数据记录可以被认为是说“插入这条记录”的消息。FT 索引可以使用其他类型的消息,比如删除记录的消息或者更新记录的消息。
由于我们使用 B 树内部节点的一部分作为缓冲区,主键可用的空间就会变少。我们应该为缓冲区分配多少空间,为孩子节点分配多少空间?
为了使分析在理论上成立,我们可以设置孩子节点的数量 (回想一下,对于 B 树,
)。
在实践中,我们可能会设置 ,块大小 B 为 64KB。如果缓冲区已满,内部节点可以更大。多个叶节点被组合成一个 4MB 的块用于写入,也就是对于写入来说,块大小为 4MB(压缩前),对于读取来说,块大小还是 64KB(压缩前)。
FT 写放大的分析如下。在最坏的情况下,每个对象都向树的下层移动,每次移动一层。沿着树向下移动 个对象会导致 B 的写入成本,每层的写放大是 k,总写放大是
。倾斜写入可以实现更好的写放大,有时最终性能可以达到
。
无论是点查询还是范围查询,对于冷缓存的情况,读取的成本为 ,而对于热缓存的情况,读取成本通常为一次 I/O。
5 LSM 树
LSM 树背后的想法是维护一组已排序的数据 runs,每个 run 包含按键值升序排序的键值对。在某些系统中,run 作为单个文件进行管理,而在另一些系统中,run 作为较小文件的集合进行管理。 有些系统则兼而有之:例如,Cassandra 的分层压缩策略默认将 run 组织成最大 5MB 的文件,而它们的大小分层压缩策略每个 run 都只有一个文件 [9]。(译者注:run 基本可以理解为 levelDB 中的 memtable 和按层划分的 SSTable 的集合)
图 5 显示了具有三个 run 的简单 LSM 树,其中两个 run(长度为 4 和长度 6) 合并成一个长度为 10 的 run,第三个 run 保持不变。

图 5:具有三个 run(左)的 LSM,合并了其中两个 run(右)。正在合并的 run 用绿色表示。
给定一个排好序的 run,执行查询的一种方法是对数据进行二分搜索。在冷缓存中,这样的查询需要进行 次 I/O,其中 N 是数据库大小,B 是读取块大小。 这是大量的 I/O:对于读取块大小为 1MB 的 10TB 数据库,冷缓存的读取成本约为 26 次读取。 改变读取块的大小可能会有所帮助,但较小的读取块将需要更多的 I/O,而较大的读取块则更昂贵,我的计算表明,对于旋转磁盘,1MB 接近读取块的最佳大小。 热缓存的情况会好得多:如果系统可以在主存中保留 1 亿个键,那么它可以决定读取哪个块并通过单次 I/O 读取正确的块。
如果有多个 run,则查询可能需要对每个 run 都执行一次 I/O。 在实践中,较小的 run 通常被缓存。为了更好地权衡读取和写入,我们需要仔细研究 LSM 树如何处理压缩。LSM 树永远不会覆盖旧的 run。 相反,他们将所有更新写入新的 run 中。 随着时间的推移,在不同的 run 中,可能存在一行内容的许多不同版本,查找一行可能需要在所有这些 run 中进行查找。为了保持良好的读性能,压缩将两个或多个 run 合并为一个 run。 这种合并可以在磁盘带宽下完成,因为可以顺序读取被合并的 run,并且顺序写入新的 run。
LSM 树有两种风格:分层和大小分层。 在本节的其余部分,我将分别分析两种风格。
5.1 分层 LSM 树
在分层 LSM 树中,数据按层组织。 每层包含一个 run。 数据从 0 层开始,然后合并到 1 层的 run 中。 最终,1 层的 run 合并到 2 层的 run 中,依此类推。 每层的大小都受到限制。 例如,在某些系统中,第 i 层包含 到
兆字节的数据。 这样,第 1 层有 1MB 到 10MB 的数据,第 2 层有 10MB 到 100MB 的数据,第 3 层最多有 1GB 的数据,依此类推。 所以一个 10TB 的数据库将包含 7 层。 一些系统使用不同的生长因子。 我将分析一般情况和增长因子等于 10 的特殊情况。
图 6 显示了增长因子为 5 的分层 LSM。长度为 5 的 run 正在被合并为长度为 15 的 run。
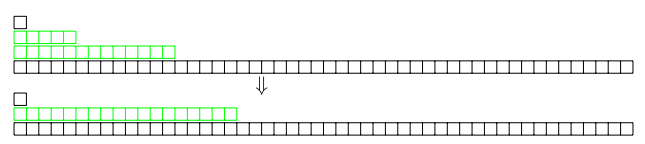
图 6:增长因子为 10 的分层 LSM。合并两行前(上)和合并后(下)。
在每个 run 只有一个文件的情况下,将一个 run 从一层合并到下一个层需要读取两个 run,并写一个新的 run。 这种合并可能需要两倍于数据库大小的临时存储空间。
在每个 run 有多个文件的情况下,可以通过一次读取第一层的一个文件,合并到第二层中相应文件的方式来进行合并。 在最坏的情况下,这种方法还需要两倍的空间,因为一层中的某个文件可能包含一行数据,这行数据注定要与下一层的每个文件合并。
分层压缩由 Cassandra [9]、LevelDB [12] 和 RocksDB 实现[14],也是原始 LSM 论文 [13] 中的方法。
我们可以像下面这样分析分层 LSM 树。 如果增长因子是 k 并且最小的层只有一个大小为 B 的文件,那么 LSM 的层数是 。 数据必须从每一层移出一次,但是来自特定层的数据会与来自前一层的数据重复合并。平均而言,在第一次写入一层后,每个数据项会重新合并回同一层大约 k/2 次。 所以总的写放大为
。
要在冷缓存情况下执行短范围查询,我们必须在每一个 run 上执行二分查找。最大的 run 是 ,因此需要
次的 I/O。下一个 run 的大小是
,因此需要
次 I/O。再下一个 run 需要
次 I/O。因此,I/O 的总数是, 渐近地,
其解为 。对于我们假设的 10TB 数据库,冷缓存大约需要 93 次读取。
对于热缓存,我们需要把不适合放入主存的每一层都读取一次。对于一个 64GB 的机器和 10TB 的数据库,除了最后三层都适合放入主存,因此系统需要 3 次读取。 对于短范围查询,相比之下,该因子 3 不如 B 树的单次读取。
通过给每个 run 添加布隆过滤器,避免为实际上不包含感兴趣的行的层执行磁盘 I/O,点查询可以更高效地运行。 在大多数情况下,这意味着点查询需要一次读取。
5.2 大小分层 LSM 树
第二种维护 LSM 的方法称为大小分层压缩。对于大小分层系统,每个 run 都使用单个文件实现,并且 run 在理论分析或实践中都不是固定大小。大小分层的文件随着时间的推移往往会变得更大。
图 7 显示了正在压缩的大小分层 LSM。四个长度为 4 的 run 合成一个长度为 16 的 run。
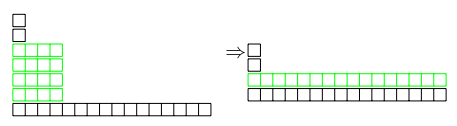
图 7:增长因子为 4 的大小分层 LSM。可以有 4 个长度不同的 run。合并四行之前(左)和合并之后(右)。
Cassandra [9] 中是这种方式的典型实现,在其中他们发现四个 run 是差不多相同的大小,并将它们合并在一起生成更大的 run。对于 10TB 的数据库,可以有一个接近 10TB 的大型 run,有四个在 500GB 和 2.5TB 之间 run,有四个在 100GB 和 500GB 之间的 run,等等。
该系统在最坏情况下的写放大可以进行如下分析。如果扇出是 k(以 Cassandra 为例,k = 4)有 层。数据在每层写入一次。因此写入会导致
的写放大。这远小于分层 LSM 树的
写放大,即使用于大小分层的 k 通常比较小:使
的因子更大(通过使 k 更小)的影响远不及写操作数乘以 k。
读取可能需要检查多达 个文件。对于冷缓存的情况,读取这些文件需要
,这是分层方法的 k 倍,因为必须在每层读取 k 个文件。对于我们假设的具有 64GB RAM 的机器上的 100TB 数据库,这相当于 17 次 I/O。
对于热缓存的情况,对于我们假设的 64GB 机器上的 10TB 数据库,可以有 13 个或更多文件大于主内存。 例如,人们可能会发现一种情况,其中有
- 1 个大小为 4TB 的 run,
- 4 个大小为 1TB 的 run,
- 4 个大小为 250GB 的 run,
- 4 个大小为 65GB 的 run,
共 13 个文件。渐近地这是 个文件,其中 M 是内存大小。布隆过滤器可以避免点查询的大部分读取,但对于范围查询则不能。
LevelDB 和 RocksDB 使用的多文件分层方法的空间放大率约为 1.1,因为大约 90% 的数据是最高级别的。大小分层压缩似乎无法获得那么低的空间放大。 RocksDB 默认配置为具有 3 的空间放大,但有可能是以损害读放大或写放大为代价来减少它。
大小分层压缩由 Cassandra [9]、WiredTiger [17]、HBase[10] 和 RocksDB [14] 实现。 Bigtable 论文 [8] 没有足够仔细地描述他们的 LSM 以确保知道:它看起来像一个大小分层的压缩方案,这是令人困惑的,因为 LevelDB 是分层的,而 LevelDB 通常被描述为相同数据结构的开源版本。
和一个文件一个 run 的分层 LSM 一样,一个潜在的问题是系统可能需要与数据库大小相等的临时存储空间来执行压缩。
6 总结
图 8 对各种放大进行了总结。

图 8:针对范围查询的写放大、读放大,以及各种方案的空间放大的总结。
- FT 索引在渐近和实践中都有出色的写放大、读放大和空间放大表现。
- 分层 LSM 基本上可以匹配 FT 索引的写放大。 每个 run 有多个文件的分层 LSM 在空间放大方面做得很好,但是每个 run 单个文件的则不太好。 在渐近和实践中,分层 LSM 明显会比 FT 索引产生更多的读取放大。 很少有应用程序适合使用分层 LSM。
- 大小分层 LSM 可以提供比分层 LSM 和 FT 索引低得多的写放大,但是范围查询的成本极高,空间放大的表现也非常差。 只执行很少的读取并且对空间放大不敏感,但是对写入成本非常敏感的工作负载可能会受益于大小分层 LSM。 根据我的经验,这是一个不寻常的应用程序,它的写入带宽如此之短,以至于它可以很高兴地放弃 13 倍的读放大。
- B 树具有比其他替代方案高得多的写放大,但是读放大做得好,空间放大做得很好。 很少有应用程序应该使用 B 树。
数据库中使用的数据结构只是决定的一部分。像 MVCC、具有 ACID 恢复的事务和两阶段分布式提交、备份和压缩这样的特性通常主导着这些系统的工程挑战,并经常决定数据库是否真正满足应用程序的需求。 例如,压缩对于 FT 索引非常有效,并且可以显著减少写入放大。 Tokutek 实现的分形树索引提供了 MVCC、事务、分布式事务、备份和压缩。
致谢
Mark Callaghan 帮助我理解了如何解释 LSM 树。
参考
[1] A. Aggarwal and J. S. Vitter. The input/output complexity of sorting and related problems. 31(9):1116–1127, September 1988.
[2] T. G. Armstrong, V. Ponnekanti, D. Borthakur, and M. Callaghan. LinkBench: A database benchmark based on the Facebook social graph. In Proceedings ofthe 2013 ACM SIGMOD International Conference on Management of Data, pages 1185– 1196, New York, NY, 2013.
[3] R. Bayer and E. M. McCreight. Organization and maintenance of large ordered indexes. Acta Informatica, 1(3):173–189, Feb. 1972.
[4] M. A. Bender, M. Farach-Colton, J. T. Fineman, Y. Fogel, B. C. Kuszmaul, and J. Nelson. Cache-oblivious streaming B-trees. In Proceedings of the Nineteenth ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), pages 81– 92, San Diego, CA, June 9–11 2007.
[5] B. H. Bloom. Spacetime trade-offs in hash coding with allowable errors. Communications ofthe ACM, 13(7):422–426, 1970.
[6] G. S. Brodal and R. Fagerberg. Lower bounds for external memory dictionaries. In Proceedings of the 13th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 39–48, 2002.
[7] A. L. Buchsbaum, M. Goldwasser, S. Venkatasubramanian, and J. R. Westbrook. On external memory graph traversal. In Proceedings ofthe Eleventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’00), pages 859–860, 2000.
[8] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: A distributed storage system for structured data. ACMTransactions on Computer Systems, 26(2), June 2008. Article No. 4.
[9] J. Ellis. Leveled compaction in Apache Cassandra. http://www.datastax.com/ dev/blog/leveled-compaction-in-apache-cassandra, Oct. 2011. Viewed April 22, 2014.
[10] Apache HBase. https://hbase.apache.org/. Viewed April 14, 2014. [11] InnoBase. InnoDB pluggable storage engine for MySQL. [12] LevelDB. https://code.google.com/p/leveldb/. Viewed April 14, 2014.
[13] P. E. O’Neil, E. Cheng, D. Gawlick, and E. J. O’Neil. The log-structured merge-tree (LSM-tree). Acta Inf., 33(4):351–385, 1996.
[14] RocksDB. rocksdb.org, 2014. Viewed April 19, 2014.
[15] Tokutek. iiBench Contest. http://blogs.tokutek.com/tokuview/iibench, Nov. 2009.
[16] Tokutek. MongoDB, MySQL, and MariaDB performance using Tokutek. tokutek. com, 2014.
[17] WiredTiger. wiredtiger.com. Viewed April 14, 2014. [18] G. K. Zipf. The Psychobiology ofLanguage. Houghton-Mifflin, 1935.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









