






进程内存结构
每个进程都有独立的虚拟地址空间。在 32 位的机器上,虚拟地址空间总大小为 4GB。在地址高段的 1GB 是内核空间,低段的 3GB 是用户空间。如果是 64 位机器,理论上 64 位地址寻址能覆盖 16EB 的空间,但是实际一般只用 48 位地址,高段 128TB(0xFFFF8000 00000000∼0xFFFFFFFF FFFFFFFF)作为内核空间,低段 128TB(0x0000 00000000∼0x7FFF FFFFFFFF)作为用户空间,两段中间的地址空出不用。
用户空间从高地址到低地址又划分为 栈、内存映射区、堆、bss 段、数据段、代码段 或者 栈、内存映射区、自由存储区、全局区、代码段。前者是 C 语言/操作系统 里的划分方法,后者是 C++ 里的划分方法。关于两种划分方法的区别:
在 C++ 里,自由存储是通过 new 和 delete 动态分配和释放对象的抽象概念,通过 new 来申请的内存区域可称为自由存储区。默认情况下,C++ 的编译器用堆来实现自由存储,也就是说,用 new 来分配的对象就是在堆上。
在 C 语言里,按照是否已进行初始化对 全局区(静态区)进行划分:bss 段(bss segment,Block Started by Symbol Segment,由符号启始的区块)存放未初始化的全局变量与静态变量,一般在初始化时会进行清零;数据段存放程序中已初始化的全局变量和静态变量。C++ 里则不做是否初始化的区分,把初始化、未初始化的全局变量、静态变量混合存储在一起。PS:C++ 里很重要的虚函数表也是存放在静态区。
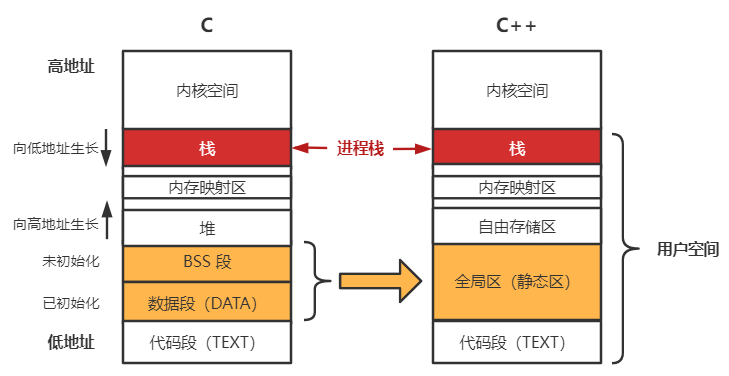
图. 进程内存结构
线程栈
线程栈是通过 mmap 系统调用从进程的地址空间中映射出来的一块内存区域。线程栈的实际位置在上面说的内存映射区,而不是在进程栈里(/proc/进程号/maps 文件展示了虚拟地址的使用情况,包括上面所说的各块内存区域的地址范围,通过创建线程、打印线程内局部变量的地址,再与 maps 的内容进行核对就可以确认线程栈的位置)。
不同于进程栈可以动态增长,线程栈不能动态增长,线程栈的大小在线程创建时就确定,默认为 8MB,一旦用尽就没了。使用 pthread_attr_setstack 或者 ulimit -s 可以修改线程栈的大小。
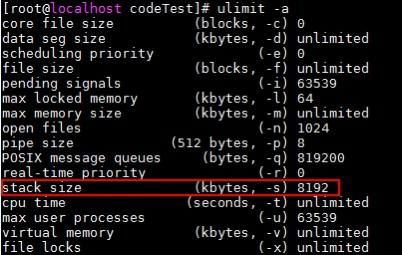
图. 栈大小设置
函数栈帧
每个函数的每次调用,都有一个独立的栈帧。栈帧里包含了函数的局部变量、函数参数、函数调用的上下文信息。上下文信息又主要包括父函数(调用函数)栈帧的栈底指针、子函数(被调函数)返回后要执行的指令的地址。
栈底指针是什么?栈底指针指向的是栈帧的开始位置,对应的是栈帧地址的最大值。栈底指针保存在寄存器 rbp(base pointer)中。
为什么子函数要保存父函数的栈底指针?rbp 寄存器只有一份。当父函数调用子函数,rbp 中的值即被更新为子函数栈帧的栈底指针值;当子函数运行结束,恢复父函数的运行环境时,需要给 rbp 重新赋父函数栈帧的栈底;为了能在子函数运行过程中一直保留父函数栈帧的栈底,即将父函数栈帧的栈底指针值存入子函数的栈帧。
和栈底指针对应的还有栈顶指针。栈顶指针指向栈帧的结束位置,对应着栈帧地址的最小值,保存在寄存器 rsp(stack pointer)中。rsp 也只有一份,为什么子函数不保存父函数的栈顶指针?因为父函数的栈顶就是子函数的栈底,当子函数运行结束,pop 出栈底的最后一个元素,自然就恢复到父函数的栈顶。
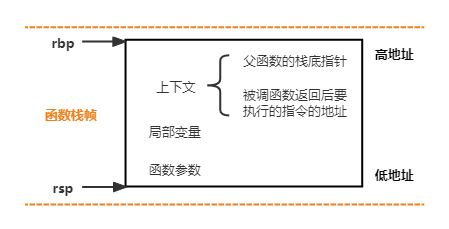
图. 栈帧示意
代码实验
1、定义 主函数 main 和 求和函数 sum;
2、在主函数里定义局部变量 a、b、ret,以 a、b 作为参数调用求和函数 sum,用 ret 接收 sum 的返回值;
3、在 sum 函数里定义局部变量 c 和 ret,对入参 a、b 和 c 进行求和,用 ret 接收求和结果,返回给 main 函数;
int sum(int a, int b) {
int c = 3;
int ret = 1;
ret = a + b + c;
return ret;
}
int main() {
int a = 1, b = 2;
int ret = 0;
ret = sum(a, b);
return 0;
}4、把源代码保存为 stackTest.c 进行编译,编译后生成名为 stackTest 的可执行文件,加入 -g 参数,使编译出的程序可用 gdb 进行调试:
gcc -g -o stackTest stackTest.c5、对编译生成的 stackTest 进行反汇编,反汇编结果写入 stackTest.txt:
objdump -s -d stackTest > stackTest.txt结果分析
在 64 位的机器上,用 4.8.5 版本的 gcc 进行编译。反汇编结果和栈空间示意图如下。在反汇编结果中,第一列是指令在内存中的地址、第二列是机器指令、第三列是对应的汇编代码。
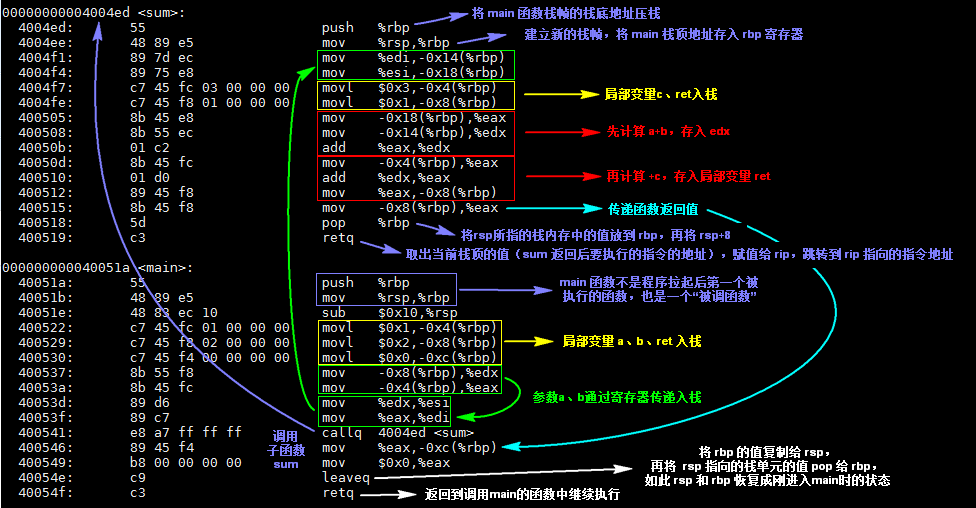
图. 反汇编结果
按照局部变量的定义顺序,先定义的变量先入栈,在高地址,后定义的变量后入栈,在低地址。在 main 函数栈帧里 a、b、ret 的位置是 a 最高、b 次之、ret 最低(%rbp-0x4 ~ %rbp-0xc)。
在函数参数的入栈顺序上,右侧的参数先传入寄存器,但是后压入子函数栈帧,在低地址;左侧的参数后传入寄存器,但是先压入子函数栈帧,在高地址。在 sum 函数调用过程中,进入 sum 函数前(执行 callq 指令前)参数 b 的值先传入寄存器 edx、esi,参数 a 的值再传入寄存器 eax、edi;进入 sum 函数以后,a 的值先压入 sum 函数栈帧,在 %rbp-0x14 的位置,b 的值后压入 sum 函数栈帧,在 %rbp-0x18 的位置。
在栈帧布局上,子函数的栈底是父函数栈帧的栈底指针值,其次是局部变量,再往下是函数参数;父函数栈帧的布局和子函数的布局基本一致,除了栈顶是子函数返回后要执行的指令的地址(栈空间示意图中用紫色虚线标记的部分)。

图. 栈空间示意图
「在当前的实验结果下,存在两个点无法解释:理论上,main 函数栈帧的起始位置应是父函数的 rbp 指针值,但实际却是 0x0;另外,在 main 函数栈帧中,rbp-0x10 的位置有一四字节的值,像是指针,但是在 64 位机器上,4 字节的地址不是一个完整的内存地址,和前后内存的内容也无法联系」
函数对栈帧的处理方式和编译器强相关。同样的程序,在不一样版本的编译器上进行编译,编译出的结果可能截然不同。用 4.4.6 版本的 gcc 编译上面的实验代码,从反汇编结果看,在局部变量入栈顺序(存储位置)上、加法的计算指令上就不同于上面的实验结果:
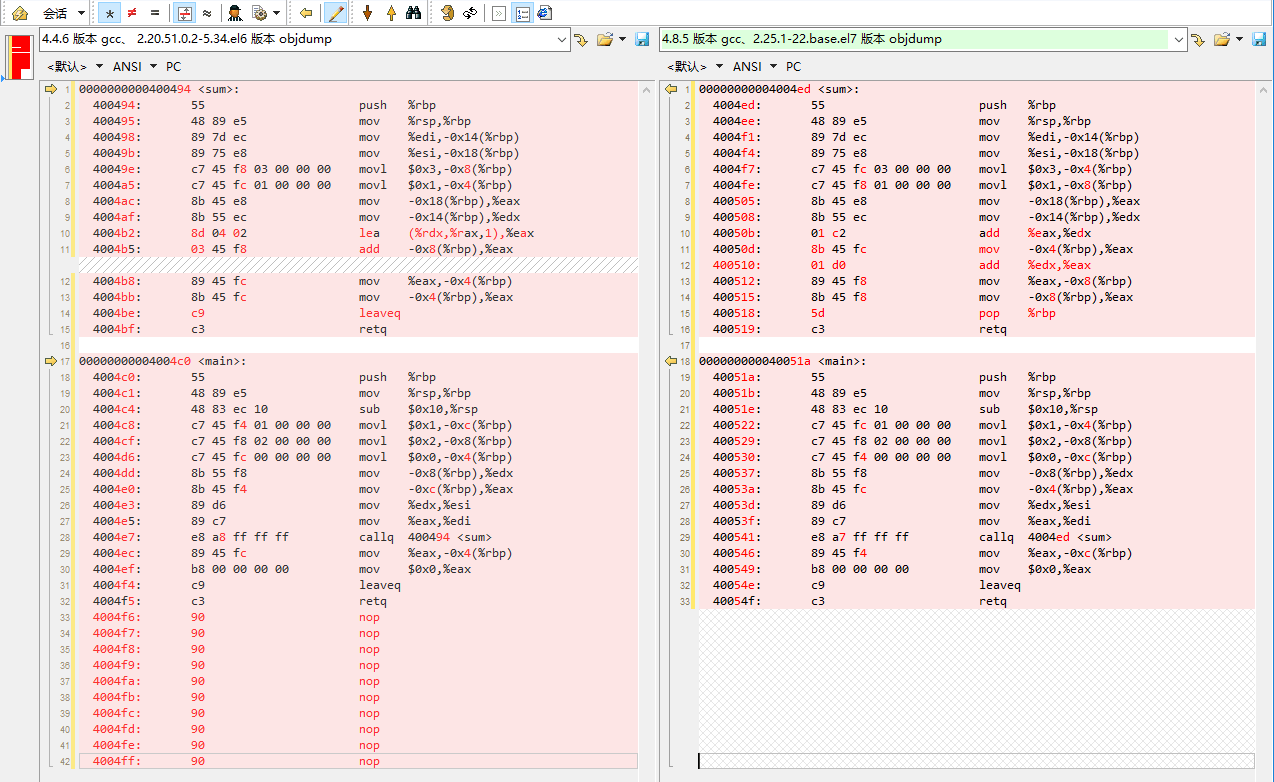
图. 反汇编结果对比















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









