




一、简述
mt7530 交换芯片的数据接收中断后,把具体接收数据工作任务、委托到 workqueue 队列中,让内核 work_thread () 线程任务来处理。这部分内容请参考《workqueue 工作原理》中的描述。
workqueue 基本工作流框架如下:
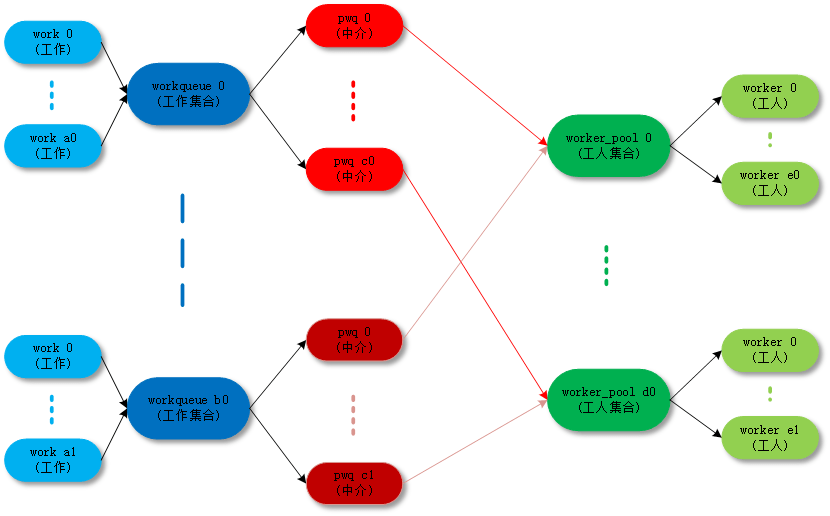
框架业务关系:
1、程序把work单、加入至workqueue 中,就等于把工作安排好,是工单的生成者、派遣者;
2、worker_pool 是工厂、提供工作的场地,worker是工人、负责执行工单,消费者;
3、PWQ(pool workqueue )是派遣工单给工厂协调者,负责匹配生成者与消费者之间协调;
workqueue 框架启动流程:
1、内核 kernel_init_freeable 初始化函数( in main.c ) 调用 workqueue_init() 初始化程序;
2、workqueue_init() 函数为每个cpu创建一个 worker_pool 池;
3、kthread_create_on_node() 创建一个 worker 进程,并 worker_attach_to_pool(worker, pool);添加到池子中;
worker 执行工作流程:workqueue.c --> static int worker_thread(void *__worker)
/*
* Finish PREP stage. We're guaranteed to have at least one idle
* worker or that someone else has already assumed the manager
* role. This is where @worker starts participating in concurrency
* management if applicable and concurrency management is restored
* after being rebound. See rebind_workers() for details.
*/
worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND);
do {
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
pool->watchdog_ts = jiffies;
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
process_one_work(worker, work); /* worker done work,执行queue中的work任务 */
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker);
} else {
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker);
}
} while (keep_working(pool));
2、数据接收任务单的执行者是谁?
上篇《详解 switch 数据接收驱动框架、mtk7621集成交换芯片mt7530》已经分析过,硬件中断后程序最终通过 insert_work() 函数,把待处理的数据任务放到 workqueue 中;开篇已经描述 worker_pool 中已经具有 worker 线程 one-by-one 执行工作任务,也即是说数据会被process_one_work(worker, work) 程序接收、并送往网络协议栈。
/**
* process_one_work - process single work
* @worker: self
* @work: work to process
*
* Process @work. This function contains all the logics necessary to
* process a single work including synchronization against and
* interaction with other workers on the same cpu, queueing and
* flushing. As long as context requirement is met, any worker can
* call this function to process a work.
*
* CONTEXT:
* spin_lock_irq(pool->lock) which is released and regrabbed.
*/
static void process_one_work(struct worker *worker, struct work_struct *work)
__releases(&pool->lock)
__acquires(&pool->lock)
{
struct pool_workqueue *pwq = get_work_pwq(work);
struct worker_pool *pool = worker->pool;
bool cpu_intensive = pwq->wq->flags & WQ_CPU_INTENSIVE;
int work_color;
struct worker *collision;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct from
* inside the function that is called from it, this we need to
* take into account for lockdep too. To avoid bogus "held
* lock freed" warnings as well as problems when looking into
* work->lockdep_map, make a copy and use that here.
*/
struct lockdep_map lockdep_map;
lockdep_copy_map(&lockdep_map, &work->lockdep_map);
#endif
/* ensure we're on the correct CPU */
WARN_ON_ONCE(!(pool->flags & POOL_DISASSOCIATED) &&
raw_smp_processor_id() != pool->cpu);
/*
* A single work shouldn't be executed concurrently by
* multiple workers on a single cpu. Check whether anyone is
* already processing the work. If so, defer the work to the
* currently executing one.
*/
collision = find_worker_executing_work(pool, work);
if (unlikely(collision)) {
move_linked_works(work, &collision->scheduled, NULL);
return;
}
/* claim and dequeue */
debug_work_deactivate(work);
hash_add(pool->busy_hash, &worker->hentry, (unsigned long)work);
worker->current_work = work;
worker->current_func = work->func;
worker->current_pwq = pwq;
work_color = get_work_color(work);
list_del_init(&work->entry);
/*
* CPU intensive works don't participate in concurrency management.
* They're the scheduler's responsibility. This takes @worker out
* of concurrency management and the next code block will chain
* execution of the pending work items.
*/
if (unlikely(cpu_intensive))
worker_set_flags(worker, WORKER_CPU_INTENSIVE);
/*
* Wake up another worker if necessary. The condition is always
* false for normal per-cpu workers since nr_running would always
* be >= 1 at this point. This is used to chain execution of the
* pending work items for WORKER_NOT_RUNNING workers such as the
* UNBOUND and CPU_INTENSIVE ones.
*/
if (need_more_worker(pool))
wake_up_worker(pool);
/*
* Record the last pool and clear PENDING which should be the last
* update to @work. Also, do this inside @pool->lock so that
* PENDING and queued state changes happen together while IRQ is
* disabled.
*/
set_work_pool_and_clear_pending(work, pool->id);
spin_unlock_irq(&pool->lock);
lock_map_acquire(&pwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
/*
* Strictly speaking we should mark the invariant state without holding
* any locks, that is, before these two lock_map_acquire()'s.
*
* However, that would result in:
*
* A(W1)
* WFC(C)
* A(W1)
* C(C)
*
* Which would create W1->C->W1 dependencies, even though there is no
* actual deadlock possible. There are two solutions, using a
* read-recursive acquire on the work(queue) 'locks', but this will then
* hit the lockdep limitation on recursive locks, or simply discard
* these locks.
*
* AFAICT there is no possible deadlock scenario between the
* flush_work() and complete() primitives (except for single-threaded
* workqueues), so hiding them isn't a problem.
*/
lockdep_invariant_state(true);
trace_workqueue_execute_start(work);
worker->current_func(work); /* !!! 此回调函数是执行此工作入口,因此需要查看任务工单内容 */
/*
* While we must be careful to not use "work" after this, the trace
* point will only record its address.
*/
trace_workqueue_execute_end(work);
lock_map_release(&lockdep_map);
lock_map_release(&pwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
pr_err("BUG: workqueue leaked lock or atomic: %s/0x%08x/%d\n"
" last function: %pf\n",
current->comm, preempt_count(), task_pid_nr(current),
worker->current_func);
debug_show_held_locks(current);
dump_stack();
}
/*
* The following prevents a kworker from hogging CPU on !PREEMPT
* kernels, where a requeueing work item waiting for something to
* happen could deadlock with stop_machine as such work item could
* indefinitely requeue itself while all other CPUs are trapped in
* stop_machine. At the same time, report a quiescent RCU state so
* the same condition doesn't freeze RCU.
*/
cond_resched_rcu_qs();
spin_lock_irq(&pool->lock);
/* clear cpu intensive status */
if (unlikely(cpu_intensive))
worker_clr_flags(worker, WORKER_CPU_INTENSIVE);
/* we're done with it, release */
hash_del(&worker->hentry);
worker->current_work = NULL;
worker->current_func = NULL;
worker->current_pwq = NULL;
worker->desc_valid = false;
pwq_dec_nr_in_flight(pwq, work_color);
}
3、数据是如何被接收的?
网卡在被 ifup | ifconfig up ,会触发 网卡驱动的 fe_probe 函数,函数调用关系如下:
文中有简单注释说明。
static int fe_probe(struct platform_device *pdev)
{
fe_base = devm_ioremap_resource(&pdev->dev, res);
netdev = alloc_etherdev(sizeof(*priv));
SET_NETDEV_DEV(netdev, &pdev->dev);
netdev->netdev_ops = &fe_netdev_ops;
netdev->base_addr = (unsigned long)fe_base;
netdev->irq = platform_get_irq(pdev, 0);
priv = netdev_priv(netdev);
INIT_WORK(&priv->pending_work, fe_pending_work); /* 初始化 work 工单,worker-> func () 回调函数 */
netif_napi_add(netdev, &priv->rx_napi, fe_poll, napi_weight); /* 注册数据接收函数 fe_poll 函数 */
fe_set_ethtool_ops(netdev);
err = register_netdev(netdev);
}
static void fe_pending_work(struct work_struct *work)
{
struct fe_priv *priv = container_of(work, struct fe_priv, pending_work);
int i;
bool pending;
for (i = 0; i < ARRAY_SIZE(fe_work); i++) {
pending = test_and_clear_bit(fe_work[i].bitnr,
priv->pending_flags);
if (pending)
fe_work[i].action(priv); /* 激活 任务标识 */
}
}
/* 数据接收函数入口 */
static int fe_poll(struct napi_struct *napi, int budget)
{
struct fe_priv *priv = container_of(napi, struct fe_priv, rx_napi);
struct fe_hw_stats *hwstat = priv->hw_stats;
int tx_done, rx_done, tx_again;
u32 status, fe_status, status_reg, mask;
u32 tx_intr, rx_intr, status_intr;
status = fe_reg_r32(FE_REG_FE_INT_STATUS);
fe_status = status;
tx_intr = priv->soc->tx_int;
rx_intr = priv->soc->rx_int;
status_intr = priv->soc->status_int;
tx_done = 0;
rx_done = 0;
tx_again = 0;
if (fe_reg_table[FE_REG_FE_INT_STATUS2]) {
fe_status = fe_reg_r32(FE_REG_FE_INT_STATUS2);
status_reg = FE_REG_FE_INT_STATUS2;
} else {
status_reg = FE_REG_FE_INT_STATUS;
}
if (status & tx_intr)
tx_done = fe_poll_tx(priv, budget, tx_intr, &tx_again); /* 调用数据发送函数 fe_poll_tx() 函数 */
if (status & rx_intr)
rx_done = fe_poll_rx(napi, budget, priv, rx_intr); /* 调用数据接收函数 fe_poll_rx() 函数 */
if (unlikely(fe_status & status_intr)) {
if (hwstat && spin_trylock(&hwstat->stats_lock)) {
fe_stats_update(priv);
spin_unlock(&hwstat->stats_lock);
}
fe_reg_w32(status_intr, status_reg);
}
if (unlikely(netif_msg_intr(priv))) {
mask = fe_reg_r32(FE_REG_FE_INT_ENABLE);
netdev_info(priv->netdev,
"done tx %d, rx %d, intr 0x%08x/0x%x\n",
tx_done, rx_done, status, mask);
}
if (!tx_again && (rx_done < budget)) {
status = fe_reg_r32(FE_REG_FE_INT_STATUS);
if (status & (tx_intr | rx_intr)) {
/* let napi poll again */
rx_done = budget;
goto poll_again;
}
napi_complete_done(napi, rx_done);
fe_int_enable(tx_intr | rx_intr);
} else {
rx_done = budget;
}
poll_again:
return rx_done;
}
/* 数据如何被读取出来、送往内核网络协议栈 */
static int fe_poll_rx(struct napi_struct *napi, int budget,
struct fe_priv *priv, u32 rx_intr)
{
struct net_device *netdev = priv->netdev;
struct net_device_stats *stats = &netdev->stats;
struct fe_soc_data *soc = priv->soc;
struct fe_rx_ring *ring = &priv->rx_ring;
int idx = ring->rx_calc_idx;
u32 checksum_bit;
struct sk_buff *skb;
u8 *data, *new_data;
struct fe_rx_dma *rxd, trxd;
int done = 0, pad;
if (netdev->features & NETIF_F_RXCSUM)
checksum_bit = soc->checksum_bit;
else
checksum_bit = 0;
if (priv->flags & FE_FLAG_RX_2B_OFFSET)
pad = 0;
else
pad = NET_IP_ALIGN;
while (done < budget) {
unsigned int pktlen;
dma_addr_t dma_addr;
/* 环形缓冲区获取数据 */
idx = NEXT_RX_DESP_IDX(idx);
rxd = &ring->rx_dma[idx];
data = ring->rx_data[idx];
fe_get_rxd(&trxd, rxd);
if (!(trxd.rxd2 & RX_DMA_DONE))
break;
/* alloc new buffer */
new_data = page_frag_alloc(&ring->frag_cache, ring->frag_size,
GFP_ATOMIC);
if (unlikely(!new_data)) {
stats->rx_dropped++;
goto release_desc;
}
dma_addr = dma_map_single(&netdev->dev,
new_data + NET_SKB_PAD + pad,
ring->rx_buf_size,
DMA_FROM_DEVICE);
if (unlikely(dma_mapping_error(&netdev->dev, dma_addr))) {
skb_free_frag(new_data);
goto release_desc;
}
/* receive data */
skb = build_skb(data, ring->frag_size);
if (unlikely(!skb)) {
skb_free_frag(new_data);
goto release_desc;
}
skb_reserve(skb, NET_SKB_PAD + NET_IP_ALIGN);
dma_unmap_single(&netdev->dev, trxd.rxd1,
ring->rx_buf_size, DMA_FROM_DEVICE);
pktlen = RX_DMA_GET_PLEN0(trxd.rxd2);
skb->dev = netdev;
skb_put(skb, pktlen);
if (trxd.rxd4 & checksum_bit)
skb->ip_summed = CHECKSUM_UNNECESSARY;
else
skb_checksum_none_assert(skb);
skb->protocol = eth_type_trans(skb, netdev); /* 获取协议号 */
if (netdev->features & NETIF_F_HW_VLAN_CTAG_RX &&
RX_DMA_VID(trxd.rxd3))
__vlan_hwaccel_put_tag(skb, htons(ETH_P_8021Q),
RX_DMA_VID(trxd.rxd3)); /* VLAN 打 tag 标 */
#ifdef CONFIG_NET_MEDIATEK_OFFLOAD /* NET_MEDIATEK_OFFLOAD 网络功能卸载 */
if (mtk_offload_check_rx(priv, skb, trxd.rxd4) == 0) {
#endif
stats->rx_packets++;
stats->rx_bytes += pktlen;
napi_gro_receive(napi, skb); /* 调用 napi_gro_receive() 接收数据*/
#ifdef CONFIG_NET_MEDIATEK_OFFLOAD
} else {
dev_kfree_skb(skb);
}
#endif
ring->rx_data[idx] = new_data;
rxd->rxd1 = (unsigned int)dma_addr;
release_desc:
if (priv->flags & FE_FLAG_RX_SG_DMA)
rxd->rxd2 = RX_DMA_PLEN0(ring->rx_buf_size);
else
rxd->rxd2 = RX_DMA_LSO;
ring->rx_calc_idx = idx;
/* make sure that all changes to the dma ring are flushed before
* we continue
*/
wmb();
fe_reg_w32(ring->rx_calc_idx, FE_REG_RX_CALC_IDX0);
done++;
}
if (done < budget)
fe_reg_w32(rx_intr, FE_REG_FE_INT_STATUS);
return done;
}
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb);
return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
EXPORT_SYMBOL(napi_gro_receive);
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb)
{
switch (ret) {
case GRO_NORMAL:
if (netif_receive_skb_internal(skb)) /* ip层的数据接收 */
ret = GRO_DROP;
break;
case GRO_DROP:
kfree_skb(skb);
break;
case GRO_MERGED_FREE:
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else
__kfree_skb(skb);
break;
case GRO_HELD:
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}
static int netif_receive_skb_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
if (skb_defer_rx_timestamp(skb))
return NET_RX_SUCCESS;
if (static_key_false(&generic_xdp_needed)) {
int ret;
preempt_disable();
rcu_read_lock();
ret = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
rcu_read_unlock();
preempt_enable();
if (ret != XDP_PASS)
return NET_RX_DROP;
}
rcu_read_lock();
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
return ret;
}
}
#endif
ret = __netif_receive_skb(skb); /* 调用数据接收函数 __netif_receive_skb() */
rcu_read_unlock();
return ret;
}
__netif_receive_skb() --> __netif_receive_skb_core() --> deliver_skb() 函数调用关系,最终调用 协议栈分发函数 deliver_skb() ;
/* skb 发送到网络协议栈 */
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
return -ENOMEM;
refcount_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
协议栈分发函数 deliver_skb() 调用的 pt_prev->func (skb, skb->dev, pt_prev, orig_dev) 函数,是在网络协议栈初始化时赋予的指针函数,接下来在分析网络协议栈的初始化过程。

















 5379
5379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









