









一、什么是Spark?
介绍
诞生于加州大学伯克利分校AMP实验室,是一个基于内存的分布式计算框架
特点
- 速度快
基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
基于硬盘数据处理,比MR快10个数量级以上 - 易用性
支持Java、Scala、Python、R语言
交互式shell方便开发测试 - 通用性
一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习 - 随处运行
YARN、Mesos、EC2、Kubernetes、Standalone、Local
与MapReduce相比
-
MapReduce编程模型的局限性
1.繁杂
只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码
2.处理效率低:
Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据
3.任务调度与启动开销大
不适合迭代处理、交互式处理和流式处理 -
Spark是类Hadoop MapReduce的通用并行框架
1.Job中间输出结果可以保存在内存,不再需要读写HDFS
2.比MapReduce平均快10倍以上
技术栈

- Spark Core
核心组件,分布式计算引擎 - Spark SQL
高性能的基于Hadoop的SQL解决方案 - Spark Streaming
可以实现高吞吐量、具备容错机制的准实时流处理系统 - Spark GraphX
分布式图处理框架 - Spark MLlib
构建在Spark上的分布式机器学习库
二、Spark架构
运行架构

- 在驱动程序中,通过SparkContext主导应用的执行
- SparkContext可以连接不同类型的Cluster Manager(Standalone、YARN、Mesos),连接后,获得集群节点上的Executor
- 一个Worker节点默认一个Executor,可通过SPARK_WORKER_INSTANCES调整
- 每个应用获取自己的Executor
- 每个Task处理一个RDD分区
核心组件
| 术语 | 说 明 |
|---|---|
| Application | 建立在Spark上的用户程序,包括Driver代码和运行在集群各节点Executor中的代码 |
| Driver program | 驱动程序。Application中的main函数并创建SparkContext |
| Cluster Manager | 在集群(Standalone、Mesos、YARN)上获取资源的外部服务 |
| Worker Node | 集群中任何可以运行Application代码的节点 |
| Executor | 某个Application运行在worker节点上的一个进程 |
| Task | 被送到某个Executor上的工作单元 |
| Job | 包含多个Task组成的并行计算,往往由Spark Action触发生成,一个Application中往往会产生多个Job |
| Stage | 每个Job会被拆分成多组Task,作为一个TaskSet,其名称为Stage |
三、Spark Core
RDD
概念
RDD是弹性分布式数据集(Resilient Distributed Datasets)
- 分布式数据集
RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上
RDD并不存储真正的数据,只是对数据和操作的描述 - 弹性
RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘 - 容错性
根据数据血统,可以自动从节点失败中恢复分区
特性
- 一系列的分区(分片)信息,每个任务处理一个分区
- 每个分区上都有compute函数,计算该分区中的数据
- RDD之间有一系列的依赖
- 分区函数决定数据(key-value)分配至哪个分区
- 最佳位置列表,将计算任务分派到其所在处理数据块的存储位置
RDD依赖关系
Lineage:血统、遗传
- RDD最重要的特性之一,保存了RDD的依赖关系
- RDD实现了基于Lineage的容错机制
依赖关系
- 宽依赖
- 窄依赖

宽依赖对比窄依赖
- 宽依赖对应shuffle操作,需要在运行时将同一个父RDD的分区传入到不同的子RDD分区中,不同的分区可能位于不同的节点,就可能涉及多个节点间数据传输
- 当RDD分区丢失时,Spark会对数据进行重新计算,对于窄依赖只需重新计算一次子RDD的父RDD分区
结论:
相比于宽依赖,窄依赖对优化更有利
DAG
DAG(有向无环图)反映了RDD之间的依赖关系

DAGScheduler将DAG划分为多个Stage
- 划分依据:是否发生宽依赖(Shuffle)
- 划分规则:从后往前,遇到宽依赖切割为新的Stage
- 每个Stage由一组并行的Task组成

为什么需要划分Stage
-
数据本地化
移动计算,而不是移动数据
保证一个Stage内不会发生数据移动 -
最佳实践
尽量避免Shuffle
提前部分聚合减少数据移动

分区
分区是RDD被拆分并发送到节点的不同块之一
- 我们拥有的分区越多,得到的并行性就越强
- 每个分区都是被分发到不同Worker Node的候选者
- 每个分区对应一个Task

RDD的分区器是一个可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区
重写分区
- 分区函数:compute函数
- 默认分区方式:HashPartitioner
//对key求hash,将hash值对分区数取余,得出分配结果
partition = key.hashCode() % numPartitions
- 其他分区方式:RangePartitioner
- 第一步:先重整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
- 第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;该分区器要求RDD中的KEY类型必须是可以排序的
Shuffle过程
在分区之间重新分配数据
- 父RDD中同一分区中的数据按照算子要求重新进入子RDD的不同分区中
- 中间结果写入磁盘
- 由子RDD拉取数据,而不是由父RDD推送
- 默认情况下,Shuffle不会改变分区数量

RDD创建方式
- 使用集合创建RDD
//将list集合创建成RDD
val rdd=sc.parallelize(List(1,2,3,4,5,6))
//并设置分区数
val rdd=sc.parallelize(List(1,2,3,4,5,6),5)
//使用makeRDD创建
val rdd=sc.makeRDD(List(1,2,3,4,5,6))
1、Spark默认会根据集群的情况来设置分区的数量,也可以通过parallelize()第二参数来指定
2、Spark会为每一个分区运行一个任务进行处理
- 通过加载文件创建RDD
//加载本地文件
val distFile=sc.textFile("file:///.../hello.txt")
//加载HDFS上的文件
val distHDFSFile=sc.textFile("hdfs://192.168.**.**:9000/.../hello.txt")
//支持目录、压缩文件以及通配符
sc.textFile("/my/directory")
sc.textFile("/my/directory/*.txt")
sc.textFile("/my/directory/*.gz")
加载“file://……”时,以local运行仅需一份本地文件,以Spark集群方式运行,应保证每个节点均有该文件的本地副本
- 其他创建RDD的方法
//sc.wholeTextFiles():可以针对一个目录中的大量小文件返回<filename,fileContent>作为PairRDD
//普通RDD:org.apache.spark.rdd.RDD[data_type]
//PairRDD:org.apache.spark.rdd.RDD[(key_type,value_type)]
val distFile=sc.wholeTextFiles("hdfs://192.168.**.**:9000/test")
//Spark 为包含键值对类型的 RDD 提供了一些专有的操作,比如:reduceByKey()、groupByKey()……
//SparkContext.sequenceFile[K,V]()
//Hadoop SequenceFile的读写支持
//SparkContext.hadoopRDD()、newAPIHadoopRDD()
//从Hadoop接口API创建
//SparkContext.objectFile()
//RDD.saveAsObjectFile()的逆操作
//……
算子
分为lazy与non-lazy两种
- Transformation(lazy):也称转换操作、转换算子
- Actions(non-lazy):立即执行,也称动作操作、动作算子
转换算子
对于转换操作,RDD的所有转换都不会直接计算结果
- 仅记录作用于RDD上的操作
- 当遇到动作算子(Action)时才会进行真正计算
啥意思?举个栗子:textFile读取本地文件来创建RDD,哪怕实际上该文件并不存在,也能成功创建RDD。当RDD遇到第一个行动算子( actions)操作时,需要对RDD进行计算,此时才会报错,也就说明了转化操作的本质:仅仅是记录旧RDD如何转化成新RDD ,但不会立即进行计算,以免浪费资源。
常用的转换算子(Scala版)
//对每个元素都执行操作
//一进一出,每个元素都会到与之对应的输出结果
println("_____________map算子___________________")
val mapRdd:RDD[String]=sc.parallelize(List("hello","world"))
//通过map将每个元素形成元组
mapRdd.map((_,1)).collect.foreach(println)
/*输出结果:
(hello,1)
(world,1)
*/
//过滤器
//对元素进行过滤,对每个元素应用指定函数,返回值为true的元素保留在新的RDD中
println("____________filter算子_________________")
val filterRdd:RDD[Int]=sc.parallelize(List(1,2,3,4,5))
filterRdd.filter(_%2==0).collect.foreach(println)
/*输出结果:
2
4
*/
//只对value进行操作
//原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素,仅适用于PairRDD
println("____________mapValue算子_________________")
val mapvalueRdd:RDD[(Int,String)] = sc.parallelize(List("dog","tiger","cat")).map(x=>(x.length,x))
mapvalueRdd.mapValues(x=>"*"+x+"*").collect.foreach(println)
/*输出结果:
(3,*dog*)
(5,*tiger*)
(3,*cat*)
*/
//去重
println("______________distinct算子________________")
val disRdd:RDD[Int]=sc.parallelize(List(1,2,2,2,3,3,4))
disRdd.distinct.collect.foreach(println)
/*输出结果:
1
2
3
4*/
//根据判断key值是否相等来决定是不是执行括号内的代码
println("______________reduceByKey算子________________")
val rbkRdd:RDD[(Int,String)] = sc.parallelize(List("dog","tiger","cat","lion","eagle")).map(x=>(x.length,x))
rbkRdd.reduceByKey((a,b)=>a+b).collect.foreach(println)
/*输出结果:
(3,dogcat)
(4,lion)
(5,tigereagle)
*/
println("______________groupBykey算子________________")
val gbkRdd:RDD[(Int,String)] = sc.parallelize(List("dog","tiger","cat","lion","eagle")).map(x=>(x.length,x))
//返回的value是迭代器
val gbkRdd2:RDD[(Int,Iterable[String])]=gbkRdd.groupByKey()
gbkRdd3.collect.foreach(println)
/*输出结果:
(3,CompactBuffer(dog,cat))
(4,CompactBuffer(lion))
(5,CompactBuffer(tiger,eagle))
*/
//聚合
println("______________union算子________________")
val unRdd1:RDD[Int]=sc.parallelize(List(1,2))
val unRdd2:RDD[Int]=sc.parallelize(List(3,4))
unRdd1.union(unRdd2).collect.foreach(println)
/*输出结果:
1
2
3
4
*/
//返回左集合不存在于右集合的所有元素
println("___________________subtract算子_______________________")
val rddSub:RDD[Int] = sc.parallelize(List(1,2,3,4))
val rddSub2:RDD[Int] = sc.parallelize(List(1,2,3))
rddSub.subtract(rddSub2).collect.foreach(x=>print(x+","))
/*输出结果:
4
*/
//将两个集合中key值相同的元素连接
println("___________________join算子_______________________")
val rddJoin:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",1),new Tuple2[String,Int]("b",1)))
val rddJoin2:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",2),new Tuple2[String,Int]("a",2),new Tuple2[String,Int]("b",2),new Tuple2[String,Int]("c",2)))
rddJoin.join(rddJoin2).collect.foreach(println)
/*输出结果:
(a,(1,2))
(a,(1,2))
(b,(1,2))*/
//全连接,存在相同key的元素和join一样,不存在相同的key的则返回None
println("___________________fullOuterJoin算子_______________________")
val rddFoj:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",1),new Tuple2[String,Int]("b",1)))
val rddFoj2:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",2),new Tuple2[String,Int]("b",2),new Tuple2[String,Int]("c",2)))
rddFoj.fullOuterJoin(rddFoj2).collect.foreach(println)
/*输出结果:
(a,(Some(1),Some(2)))
(b,(Some(1),Some(2)))
(c,(None,Some(2)))*/
//左关联:右集合中有无关联的丢弃,左边有无关联的保留
println("___________________LeftOuterJoin算子_______________________")
val rddLoj:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",1),new Tuple2[String,Int]("b",1),new Tuple2[String,Int]("c",1)))
val rddLoj2:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",2),new Tuple2[String,Int]("b",2),new Tuple2[String,Int]("d",2)))
rddLoj.leftOuterJoin(rddLoj2).collect.foreach(println)
/*输出结果:
(a,(1,Some(2)))
(b,(1,Some(2)))
(c,(1,None))*/
//右关联:左集合中有无关联的丢弃,右边有无关联的保留
println("___________________RightOuterJoin算子_______________________")
val rddRoj:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",1),new Tuple2[String,Int]("b",1),new Tuple2[String,Int]("c",1)))
val rddRoj2:RDD[(String,Int)] = sc.parallelize(List(new Tuple2[String,Int]("a",2),new Tuple2[String,Int]("b",2),new Tuple2[String,Int]("d",2)))
rddRoj.rightOuterJoin(rddRoj2).collect.foreach(println)
/*输出结果:
(d,(None,2))
(a,(Some(1),2))
(b,(Some(1),2))*/
}
}
常用的转换算子(Java版)
//过滤器,根据条件筛选元素
System.out.println("_________________filter算子________________________");
//创建ArrayList集合
ArrayList<Integer> arrFilter = new ArrayList<>();
arrFilter.add(1);
arrFilter.add(2);
arrFilter.add(3);
//创建RDD,将集合作为RDD数据源
JavaRDD<Integer> rddFilter = sc.parallelize(arrFilter);
//方法:def filter(f : org.apache.spark.api.java.function.Function[T, java.lang.Boolean]) : org.apache.spark.api.java.JavaRDD[T]
//解释:参数为Function对象,重写call方法,指定call方法的输入类型为Integer,返回值为Boolean类型,因为实现的是判断元素是否满足指定条件,算子会根据判断结果来决定是否返回元素
//实现:判断元素对2取余是否等于0
JavaRDD<Integer> rddFilter2 = rddFilter.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer integer) throws Exception {
return integer % 2 == 0;
}
});
//使用collect算子,将元素转成list集合
List<Integer> collectFilter = rddFilter2.collect();
//遍历list集合
for (Integer integer : collectFilter) {
System.out.println(integer);
}
/*
* 输出结果:
* 2
* */
//对所有元素进行相同操作,返回RDD中的元素个数,与原RDD元素个数一一对应
System.out.println("_________________map算子________________________");
//创建ArrayList集合
ArrayList<Integer> arrMap = new ArrayList<>();
arrMap.add(1);
arrMap.add(2);
arrMap.add(3);
//创建RDD,将集合作为RDD数据源
JavaRDD<Integer> rddMap = sc.parallelize(arrMap);
//方法:def map[R](f : org.apache.spark.api.java.function.Function[T, R]) : org.apache.spark.api.java.JavaRDD[R]
//解释:在map算子中创建Function对象,重写call方法(创建Function需要指定重写call方法的输入、输出类型)
//实现:将所有元素对2取余
JavaRDD<Integer> rddMap2 = rddMap.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer integer) throws Exception {
return integer % 2;
}
});
List<Integer> collect = rddMap2.collect();
for (Integer integer : collect) {
System.out.println(integer);
}
/*输出结果:
* 1
* 0
* 1*/
//一个元素,生成多个元素
System.out.println("_________________flatMap算子________________________");
ArrayList<String> arrFlatMap = new ArrayList<>();
arrFlatMap.add("hello world");
arrFlatMap.add("hello scala");
arrFlatMap.add("hello spark");
JavaRDD<String> rddFlatMap = sc.parallelize(arrFlatMap);
//方法:def flatMap[U](f : org.apache.spark.api.java.function.FlatMapFunction[T, U]) : org.apache.spark.api.java.JavaRDD[U]
//解释:flatMap的参数是FlatMapFunction对象,指定重写方法的输入类型为String,返回的类型是元组Tuple2<String,Integer>
//实现:将字符串按空格切分为单个元素,在将单独的字符串以[String,1]的组合塞入tuple元组中
JavaRDD<Tuple2<String, Integer>> rddFlatMap2 = rddFlatMap.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
ArrayList<Tuple2<String, Integer>> arr = new ArrayList<>();
String[] s1 = s.split(" ");
for (String s2 : s1) {
arr.add(new Tuple2<>(s2, 1));
}
return arr.iterator();
}
});
List<Tuple2<String, Integer>> collectFlatMap = rddFlatMap2.collect();
for (Tuple2<String, Integer> stringIntegerTuple2 : collectFlatMap) {
System.out.println(stringIntegerTuple2);
}
/*
* 输出结果:
* (hello,1)
(world,1)
(hello,1)
(scala,1)
(hello,1)
(spark,1)
*/
//将RDD元素去重后生成新的RDD
System.out.println("_________________distinct算子________________________");
ArrayList<String> arrDistinct = new ArrayList<>();
arrDistinct.add("a");
arrDistinct.add("a");
arrDistinct.add("b");
arrDistinct.add("c");
JavaRDD<String> rddDistinct = sc.parallelize(arrDistinct);
//这里直接调用了无参数的Distinct
JavaRDD<String> rddDistinct2 = rddDistinct.distinct();
List<String> collectDistinct = rddDistinct2.collect();
for (String s : collectDistinct) {
System.out.println(s);
}
/*
* 输出结果
* a
* b
* c
* */
//合并两个RDD
System.out.println("_________________union算子________________________");
JavaRDD<String> rddUnion= sc.parallelize(Arrays.asList("a","b"));
JavaRDD<String> rddUnion2= sc.parallelize(Arrays.asList("c","d"));
JavaRDD<String> rddUnion3 = rddUnion.union(rddUnion2);
List<String> collectUnion = rddUnion3.collect();
for (String s : collectUnion) {
System.out.print(s+",");
}
System.out.println();
/*输出结果:a,b,c,d,*/
//返回两个RDD的交集,并且去重,需要混洗数据,比较浪费性能
System.out.println("_________________intersection算子________________________");
JavaRDD<String> rddIntersection= sc.parallelize(Arrays.asList("a","b","c"));
JavaRDD<String> rddIntersection2= sc.parallelize(Arrays.asList("a","b","c","d","e","a"));
JavaRDD<String> rddIntersection3 = rddIntersection.intersection(rddIntersection2);
List<String> collectIntersection= rddIntersection3.collect();
for (String s : collectIntersection) {
System.out.println(s);
}
/*输出结果:
* a
* b
* c
* */
//RDD1.subtract(RDD2),返回在RDD1中出现,但是不在RDD2中出现的元素,不去重
System.out.println("_________________subtract算子________________________");
JavaRDD<String> rddSubtract= sc.parallelize(Arrays.asList("a","a","b","c","d","e"));
JavaRDD<String> rddSubtract2= sc.parallelize(Arrays.asList("c","d","e"));
JavaRDD<String> rddSubtract3 = rddSubtract.subtract(rddSubtract2);
List<String> collectSub = rddSubtract3.collect();
for (String s : collectSub) {
System.out.println(s);
}
/*
* 输出结果:
* a
* a
* b
* */
//RDD1.cartesian(RDD2) 返回RDD1和RDD2的笛卡儿积,这个开销非常大
System.out.println("_________________cartesian算子________________________");
JavaRDD<String> rddCartesian= sc.parallelize(Arrays.asList("1","2","3"));
JavaRDD<String> rddCartesian2= sc.parallelize(Arrays.asList("a","b","c"));
JavaPairRDD<String, String> rddCartesian3 = rddCartesian.cartesian(rddCartesian2);
List<Tuple2<String, String>> collectCartesion = rddCartesian3.collect();
for (Tuple2<String, String> stringStringTuple2 : collectCartesion) {
System.out.println(stringStringTuple2);
}
/*输出结果:
(1,a)
(1,b)
(1,c)
(2,a)
(2,b)
(2,c)
(3,a)
(3,b)
(3,c)*/
//对每个元素操作,最后返回元组,一个元素生成一个结果
System.out.println("_________________mapToPair算子________________________");
ArrayList<String> arrMapToPair = new ArrayList<>();
arrMapToPair.add("aa bb");
arrMapToPair.add("cc dd");
arrMapToPair.add("ee ff");
JavaRDD<String> rddMapToPair = sc.parallelize(arrMapToPair);
//方法:def mapToPair[K2, V2](f : org.apache.spark.api.java.function.PairFunction[T, K2, V2]) : org.apache.spark.api.java.JavaPairRDD[K2, V2]
//解释:mapToPairde的参数是PairFunction对象,对象需要传入3个参数,分别是传入参数的类型,与返回结果的两个输出类型
//实现:将元素按空格切割,取第一个,最为key,1作为value,以元组的对象返回
JavaPairRDD<String, Integer> rddMapToPair2 = rddMapToPair.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s.split(" ")[0], 1);
}
});
List<Tuple2<String, Integer>> collectMapToPair = rddMapToPair2.collect();
for (Tuple2<String, Integer> stringIntegerTuple2 : collectMapToPair) {
System.out.println(stringIntegerTuple2);
}
/*
* 输出结果
* (aa,1)
* (cc,1)
* (ee,1)
* */
// mapToPair是一对一,一个元素返回一个元素,而flatMapToPair可以一个元素返回多个
System.out.println("_________________flatMapToPair算子________________________");
ArrayList<String> arrFlatMapToPair = new ArrayList<>();
arrFlatMapToPair.add("aa bb");
arrFlatMapToPair.add("cc dd");
arrFlatMapToPair.add("ee ff");
JavaRDD<String> rddFlatMapToPair2 = sc.parallelize(arrFlatMapToPair);
//方法:def flatMapToPair[K2, V2](f : org.apache.spark.api.java.function.PairFlatMapFunction[T, K2, V2]) : org.apache.spark.api.java.JavaPairRDD[K2, V2]
//解释:flatMapToPair的参数是PairFlatMapFunction对象,同样是重写call方法,但返回值是Iterator迭代器
//实现:将元素按空格拆分,以拆分后的字符串为key,1为value组成Tuple,放入提前建好的ArrayList集合中,最后通过集合.Iterator的方法,转成迭代器返回
JavaPairRDD<String, Integer> rddFlatMapToPair3 = rddFlatMapToPair2.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
ArrayList<Tuple2<String, Integer>> arr = new ArrayList<>();
String[] s1 = s.split(" ");
for (String s2 : s1) {
arr.add(new Tuple2<>(s2, 1));
}
return arr.iterator();
}
});
List<Tuple2<String, Integer>> collectFlatMapToPari = rddFlatMapToPair3.collect();
for (Tuple2<String, Integer> stringIntegerTuple2 : collectFlatMapToPari) {
System.out.println(stringIntegerTuple2);
}
/* 输出结果:
(aa,1)
(bb,1)
(cc,1)
(dd,1)
(ee,1)
(ff,1)
*/
//聚合运算
System.out.println("_________________combinByKey算子________________________");
ArrayList<Tuple2<String,Integer>> arrCombinByKey=new ArrayList<>();
//插入两名学生的成绩
arrCombinByKey.add(new Tuple2<>("zs",98));
arrCombinByKey.add(new Tuple2<>("zs",72));
arrCombinByKey.add(new Tuple2<>("zs",90));
arrCombinByKey.add(new Tuple2<>("ls",91));
arrCombinByKey.add(new Tuple2<>("ls",67));
arrCombinByKey.add(new Tuple2<>("ls",80));
JavaRDD<Tuple2<String, Integer>> rddCombinByKey = sc.parallelize(arrCombinByKey);
//将元素通过mapToPair转换成二元组,才能使用combinByKey
JavaPairRDD<String, Tuple2<String, Integer>> rddCombinByKey2 = rddCombinByKey.mapToPair(new PairFunction<Tuple2<String, Integer>, String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Tuple2<String, Integer>> call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return new Tuple2<>(stringIntegerTuple2._1, stringIntegerTuple2);
}
});
//CombinByKey有三个参数,都是Function对象
//先实现第一个Function
//function拿到元组的value进行操作,此时的value依然是元组,第一个function将value中的成绩取出,作为key,1做为value形成新的元组传至第二个function
Function<Tuple2<String, Integer>, Tuple2<Integer, Integer>> function1 = new Function<Tuple2<String, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return new Tuple2<>(stringIntegerTuple2._2, 1);
}
};
//实现第二个Funcition
//第二个function将拿到第一个function的结果作为参数一,参数二有combinByKey根据key值也就是同一个人,来传入这个人的其他value,接下就是实现成绩相加,课程数+1,得出的数据形成新的元组传至第三个Function
Function2<Tuple2<Integer, Integer>, Tuple2<String, Integer>, Tuple2<Integer, Integer>> function2 = new Function2<Tuple2<Integer, Integer>, Tuple2<String, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> integerIntegerTuple2, Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return new Tuple2<>(integerIntegerTuple2._1 + stringIntegerTuple2._2, integerIntegerTuple2._2 + 1);
}
};
//实现第三个Function
//第三个function将拿到多个第二个function计算的结果,这种情况是因为不同的分区计算的结果,最后汇总在一起
Function2<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> function3 = new Function2<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> integerIntegerTuple2, Tuple2<Integer, Integer> integerIntegerTuple22) throws Exception {
return new Tuple2<>(integerIntegerTuple2._1 + integerIntegerTuple22._1, integerIntegerTuple2._2 + integerIntegerTuple22._2);
}
};
//调用combinBykey,将三个Function对象传入
JavaPairRDD<String, Tuple2<Integer, Integer>> rddCombinByKey4 = rddCombinByKey2.combineByKey(function1, function2, function3);
//将结果转成List
List<Tuple2<String, Tuple2<Integer, Integer>>> collectCombinByKey = rddCombinByKey4.collect();
//遍历输出
for (Tuple2<String, Tuple2<Integer, Integer>> stringTuple2Tuple2 : collectCombinByKey) {
//将汇总的总成绩除以总门数就得出了该学生的综合平均值
System.out.println(stringTuple2Tuple2._1+"\t"+stringTuple2Tuple2._2._1/stringTuple2Tuple2._2._2);
}
/*
输出结果:
zs 86
ls 79
*/
//聚合运算
System.out.println("_________________reduceByKey算子________________________");
JavaRDD<String> rddReduceByKey = sc.parallelize(Arrays.asList("hello world hello scala hello spark"));
//使用reduceByKey需要先对元素生成对应的元组,所以这里将使用flatMapToPair,而flatMapToPair的参数是PairFlatMapFunction对象
//实现flatMapToPair中需要的PairFlatMapFunction
//功能:根据空格对元素分隔,再将分隔后的字符串作为key,1作为value组成元组,放入ArrayList集合中最后return出去
PairFlatMapFunction<String, String, Integer> pfm = new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
ArrayList<Tuple2<String, Integer>> list = new ArrayList<>();
String[] s1 = s.split(" ");
for (int i = 0; i < s1.length; i++) {
Tuple2<String, Integer> stringIntegerTuple2 = new Tuple2<>(s1[i], 1);
list.add(stringIntegerTuple2);
}
return list.iterator();
}
};
//实现reduceByKey的参数Function对象
//功能:将key值相同的Tuple中的value值进行相加
Function2<Integer, Integer, Integer> rby = new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
};
//用rdd调用flatMapToPair传入上面实现的PairFlatMapFunction对象,在调用reduceByKey传入上面实现的Function对象
//这里实现的是WorldCount的功能
JavaPairRDD<String, Integer> stringIntegerJavaPairRDD = rddReduceByKey.flatMapToPair(pfm).reduceByKey(rby);
//将算子转成List集合
List<Tuple2<String, Integer>> collectReduceByKey = stringIntegerJavaPairRDD.collect();
//遍历输出
for (Tuple2<String, Integer> stringIntegerTuple2 : collectReduceByKey) {
System.out.println(stringIntegerTuple2);
}
/*输出结果:
(hello,3)
(world,1)
(spark,1)
(scala,1)*/
//foldByKey也是聚合运算,但是会多一个参数,这个参数会跟每个value进行相同操作后,再去执行聚合
System.out.println("_________________foldByKey算子________________________");
ArrayList<Tuple2<String,Integer>> arrayList = new ArrayList();
arrayList.add(new Tuple2<>("A",1));
arrayList.add(new Tuple2<>("A",2));
arrayList.add(new Tuple2<>("B",1));
arrayList.add(new Tuple2<>("c",1));
JavaRDD<Tuple2<String, Integer>> rddFoldByKey = sc.parallelize(arrayList);
//这里foldByKey无法直接对rdd直接操作,需要转换一下,把rdd放入JavaPairRDD.fromJavaRDD()中
//方法:def foldByKey(zeroValue : V, func : org.apache.spark.api.java.function.Function2[V, V, V]) : org.apache.spark.api.java.JavaPairRDD[K, V]
//解释:foldByKey有两个参数,第一个参数zeroValue为Int,第二个参数为Function2的对象,传入相同key的value,最后返回一个value
//举两个例子说一下zeroValue的作用:
//例子一:zeroValue=1,如果实现的Function2的call方法是将相同的key的value进行相加,在相加之前,zeroValue会对每个value+1,即("A",1)=>("A",1+1),("A",2)=>("A",2+1)最后才会执行("A",2)+("A",3)=("A",5)
//例子二:zeroValue=2,如果实现的Function2的call方法是将相同的key的value进行相乘,在相乘之前,zeroValue会对每个value*2,即("A",1)=>("A",1*2),("A",2)=>("A",2*2)最后才会执行("A",2)*("A",4)=("A",8)
//以此类推,就是这样的一个操作
JavaPairRDD<String, Integer> rddFoldByKey2 = JavaPairRDD.fromJavaRDD(rddFoldByKey).foldByKey(1, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer,Integer integer2) throws Exception {
return integer + integer2;
}
});
List<Tuple2<String, Integer>> collectFoldByKey = rddFoldByKey2.collect();
for (Tuple2<String, Integer> stringIntegerTuple2 : collectFoldByKey) {
System.out.println(stringIntegerTuple2);
}
/*输出结果:
(A,5)
(B,2)
(c,2)*/
//排序,默认降序,传入参数false为升序
System.out.println("_________________SortByKey算子________________________");
ArrayList<Tuple2<Integer,String>> list = new ArrayList<>();
list.add(new Tuple2<>(98,"zs"));
list.add(new Tuple2<>(84,"ls"));
list.add(new Tuple2<>(99,"ww"));
list.add(new Tuple2<>(72,"ll"));
list.add(new Tuple2<>(79,"lq"));
JavaRDD<Tuple2<Integer, String>> rddSortByKey = sc.parallelize(list);
//依需要转换一下。然后直接调用sortByKey就可以了。我这里直接collect了
List<Tuple2<Integer, String>> collectSortByKey = JavaPairRDD.fromJavaRDD(rddSortByKey).sortByKey().collect();
for (Tuple2<Integer, String> rddSortByKey2 : collectSortByKey) {
System.out.println(rddSortByKey2);
}
/*输出结果:
(72,ll)
(79,lq)
(84,ls)
(98,zs)
(99,ww)*/
//根据key分组
System.out.println("_________________groupByKey算子________________________");
JavaRDD<Tuple2<String,Integer>> rddGBK = sc.parallelize(Arrays.asList(new Tuple2("xiaoming", 90), new Tuple2("xiaoming", 80), new Tuple2("lihua", 60), new Tuple2("lihua", 98)));
JavaPairRDD<String, Integer> rddGBK2 = JavaPairRDD.fromJavaRDD(rddGBK);
JavaPairRDD<String, Iterable<Integer>> rdd3 = rddGBK2.groupByKey();
List<Tuple2<String, Iterable<Integer>>> collectGBK = rdd3.collect();
for (Tuple2<String, Iterable<Integer>> s : collectGBK) {
for (Integer integer : s._2) {
System.out.println(s._1+","+integer);
}
}
/*输出结果:
lihua,60
lihua,98
xiaoming,90
xiaoming,80*/
//将多个rdd中的元素分组在一起
System.out.println("_________________Cogroup算子________________________");
JavaRDD<Tuple2<String,Integer>> rddCg = sc.parallelize(Arrays.asList(new Tuple2("xiaoming", 1), new Tuple2("xiaoming", 1), new Tuple2("lihua", 1), new Tuple2("lihua", 1)));
JavaRDD<Tuple2<String,Integer>> rddCg2 = sc.parallelize(Arrays.asList(new Tuple2("xiaoming", 2), new Tuple2("xiaoming", 2), new Tuple2("lihua", 2), new Tuple2("lihua", 2)));
JavaRDD<Tuple2<String,Integer>> rddCg3 = sc.parallelize(Arrays.asList(new Tuple2("xiaoming", 3), new Tuple2("xiaoming", 3), new Tuple2("lihua", 3), new Tuple2("lihua", 3)));
JavaPairRDD<String, Integer> rddCgJava = JavaPairRDD.fromJavaRDD(rddCg);
JavaPairRDD<String, Integer> rddCgJava2 = JavaPairRDD.fromJavaRDD(rddCg2);
JavaPairRDD<String, Integer> rddCgJava3 = JavaPairRDD.fromJavaRDD(rddCg3);
//返回的元组中的value是每个集合中相同key的值组成的结果
JavaPairRDD<String, Tuple3<Iterable<Integer>, Iterable<Integer>, Iterable<Integer>>> rddCgAll = rddCgJava.cogroup(rddCgJava2, rddCgJava3);
List<Tuple2<String, Tuple3<Iterable<Integer>, Iterable<Integer>, Iterable<Integer>>>> collectCg = rddCgAll.collect();
for (Tuple2<String, Tuple3<Iterable<Integer>, Iterable<Integer>, Iterable<Integer>>> s : collectCg) {
System.out.println(s._1+","+s._2);
}
/*输出结果:
xiaoming,([1, 1],[2, 2],[3, 3])
lihua,([1, 1],[2, 2],[3, 3])*/
//返回左集合不存在于右集合的所有元素
System.out.println("_________________subtract算子________________________");
JavaRDD<Integer> rddSub1 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> rddSub2 = sc.parallelize(Arrays.asList(1, 2, 3));
JavaRDD<Integer> rddSub3 = rddSub1.subtract(rddSub2);
List<Integer> collectS = rddSub3.collect();
for (Integer integer : collectS) {
System.out.println(integer);
}
/*输出结果:
4
*/
//取交集:将两个集合中key值相同的元素连接
System.out.println("_________________join算子________________________");
JavaRDD<Tuple2<String,Integer>> rddJoin1 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",1),new Tuple2<String,Integer>("b",1)));
JavaRDD<Tuple2<String,Integer>> rddJoin2 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",2),new Tuple2<String,Integer>("b",2),new Tuple2<String,Integer>("c",2)));
JavaPairRDD<String, Integer> rddJavaJoin1 = JavaPairRDD.fromJavaRDD(rddJoin1);
JavaPairRDD<String, Integer> rddJavaJoin2 = JavaPairRDD.fromJavaRDD(rddJoin2);
JavaPairRDD<String, Tuple2<Integer, Integer>> join = rddJavaJoin1.join(rddJavaJoin2);
List<Tuple2<String, Tuple2<Integer, Integer>>> collectJoin = join.collect();
for (Tuple2<String, Tuple2<Integer, Integer>> s : collectJoin) {
System.out.println(s);
}
/*输出结果:
(a,(1,2))
(b,(1,2))*/
//全连接,元组的value类型为Optional,当存在无对应连接的元组,返回Optional.empty
System.out.println("_________________fullOuterJoin算子________________________");
JavaRDD<Tuple2<String,Integer>> rddfoj1 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",1),new Tuple2<String,Integer>("b",1)));
JavaRDD<Tuple2<String,Integer>> rddfoj2 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",2),new Tuple2<String,Integer>("b",2),new Tuple2<String,Integer>("c",2)));
JavaPairRDD<String, Integer> rddJavafoj1 = JavaPairRDD.fromJavaRDD(rddfoj1);
JavaPairRDD<String, Integer> rddJavafoj2 = JavaPairRDD.fromJavaRDD(rddfoj2);
JavaPairRDD<String, Tuple2<Optional<Integer>, Optional<Integer>>> rddfoj = rddJavafoj1.fullOuterJoin(rddJavafoj2);
List<Tuple2<String, Tuple2<Optional<Integer>, Optional<Integer>>>> collectfoj = rddfoj.collect();
for (Tuple2<String, Tuple2<Optional<Integer>, Optional<Integer>>> s : collectfoj) {
System.out.println(s);
}
/*输出结果:
(a,(Optional[1],Optional[2]))
(b,(Optional[1],Optional[2]))
(c,(Optional.empty,Optional[2]))*/
//左关联:右集合中有无关联的丢弃,左边有无关联的保留
System.out.println("_________________LeftOuterJoin算子________________________");
JavaRDD<Tuple2<String,Integer>> rddLoj1 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",1),new Tuple2<String,Integer>("b",1),new Tuple2<String,Integer>("c",1)));
JavaRDD<Tuple2<String,Integer>> rddLoj2 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",2),new Tuple2<String,Integer>("b",2),new Tuple2<String,Integer>("d",2)));
JavaPairRDD<String, Integer> rddJavaLoj1 = JavaPairRDD.fromJavaRDD(rddLoj1);
JavaPairRDD<String, Integer> rddJavaLoj2 = JavaPairRDD.fromJavaRDD(rddLoj2);
JavaPairRDD<String, Tuple2<Integer, Optional<Integer>>> rddLoj = rddJavaLoj1.leftOuterJoin(rddJavaLoj2);
List<Tuple2<String, Tuple2<Integer, Optional<Integer>>>> collectLoj = rddLoj.collect();
for (Tuple2<String, Tuple2<Integer, Optional<Integer>>> s : collectLoj) {
System.out.println(s);
}
/* 输出结果:
(a,(1,Optional[2]))
(b,(1,Optional[2]))
(c,(1,Optional.empty))*/
//右关联:左集合中有无关联的丢弃,右边有无关联的保留
System.out.println("________________RightOuterJoin算子________________________");
JavaRDD<Tuple2<String,Integer>> rddRoj1 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",1),new Tuple2<String,Integer>("b",1),new Tuple2<String,Integer>("c",1)));
JavaRDD<Tuple2<String,Integer>> rddRoj2 = sc.parallelize(Arrays.asList(new Tuple2<String,Integer>("a",2),new Tuple2<String,Integer>("b",2),new Tuple2<String,Integer>("d",2)));
JavaPairRDD<String, Integer> rddJavaRoj1 = JavaPairRDD.fromJavaRDD(rddRoj1);
JavaPairRDD<String, Integer> rddJavaRoj2 = JavaPairRDD.fromJavaRDD(rddRoj2);
JavaPairRDD<String, Tuple2<Optional<Integer>, Integer>> rddRoj = rddJavaRoj1.rightOuterJoin(rddJavaRoj2);
List<Tuple2<String, Tuple2<Optional<Integer>, Integer>>> collectRoj = rddRoj.collect();
for (Tuple2<String, Tuple2<Optional<Integer>, Integer>> s : collectRoj) {
System.out.println(s);
}
/*输出结果:
(a,(Optional[1],2))
(b,(Optional[1],2))
(d,(Optional.empty,2))*/
}
}
动作算子
- 本质上动作算子通过SparkContext执行提交作业操作,触发RDD DAG(有向无环图)的执行
- 所有的动作算子都是急迫型(non-lazy),RDD遇到Action就会立即计算
常用的动作算子(Scala)
//返回第一个元素
println("_____________first_________________")
val rddFirst:RDD[Int] = sc.parallelize(List(1,2,3,4))
println(rddFirst.first())
/*输出结果:
1
*/
//返回第前n个元素
println("_____________take_________________")
val rddTake:RDD[Int] = sc.parallelize(List(1,2,3,4))
val rddTakeArray = rddTake.take(2)
for (elem <- rddTakeArray) {
println(elem)
}
/*输出结果:
1
2
*/
//以Array返回RDD的所有元素。一般在过滤或者处理足够小的结果的时候使用
println("_____________collect_________________")
val rddCollect:RDD[Int] = sc.parallelize(List(1,2,3,4))
val ints = rddCollect.collect()
for (elem <- ints) {
println(elem)
}
/*输出结果:
1
2
3
4*/
//返回RDD中元素个数
println("_____________count_________________")
val rddCount:RDD[Int] = sc.parallelize(List(1,2,3,4))
println(rddCount.count())
/*输出结果:
4
*/
//返回RDD中各元素出现的次数
println("_____________countByValue_________________")
val rddCBV:RDD[Int] = sc.parallelize(List(1,1,2,3,3,4))
val rddCBVmap = rddCBV.countByValue()
for (elem <- rddCBVmap) {
println(elem._1+"出现了:"+elem._2+"次")
}
/*输出结果:
1出现了:2次
2出现了:1次
3出现了:2次
4出现了:1次*/
//并行整合RDD中所有数据
println("_____________reduce_________________")
val rddReduce:RDD[Int] = sc.parallelize(List(1,2,3,4))
println(rddReduce.reduce(_ + _))
/*输出结果:
10
*/
//和 reduce() 一 样, 但是提供了初始值num,每个元素计算时,先要合这个初始值进行折叠, 注意,这里会按照每个分区进行fold,然后分区之间还会再次进行fold
println("_____________fold_________________")
val rddFold:RDD[Int] = sc.parallelize(List(1,2,3,4),2)
println(rddFold.fold(1)((x,y)=>{println(x,y);x+y}))
/*输出结果:
(当分区为1 的时候) 12
(当分区为2 的时候) 13
...
*/
//按照升序排列rdd,根据传入的参数取前n个元素
println("_____________top_________________")
val rddTop:RDD[Int] = sc.parallelize(List(1,2,3,4))
val arrayTop = rddTop.top(2)
for (elem <- arrayTop) {
println(elem)
}
/*输出结果:
4
3
*/
//于top相反,将rdd按降序排列,取前n个元素
println("_____________takeOrdered_________________")
val rddTo:RDD[Int] = sc.parallelize(List(1,2,3,4))
val arrayTo = rddTo.takeOrdered(2)
for (elem <- arrayTo) {
println(elem)
}
/* 输出结果:
1
2
*/
//对RDD中的每个元素执行指定函数
println("_____________foreach_____________________")
val rdd:RDD[Int] = sc.parallelize(List(1,2,3,4))
rdd.foreach(println)
/*输出结果(存在分区,每次输出顺序会不同):
1
2
3
4*/
//lookup:用于PairRDD,返回K对应的所有V值
println("_____________lookup_____________________")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.lookup('a') //输出WrappedArray(1, 2)
//saveAsTextFile:保存RDD数据至文件系统
println("_____________saveAsTextFile_____________________")
val rdd=sc.parallelize(1 to 10,2)
rdd.saveAsTextFile("hdfs://192.168.**.**:9000/data/rddsave/")
RDD持久化
RDD缓存机制:缓存数据至内存/磁盘,可大幅度提升Spark应用性能
1. cache=persist(MEMORY)
2. persist
缓存策略StorageLevel
-
MEMORY_ONLY(默认)
1.如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别
2.如果RDD中数据比较多时(比如几十亿),直接用MEMORY_ONLY持久化级别,会导致JVM的OOM内存溢出异常 -
MEMORY_AND_DISK
1.如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略 -
DISK_ONLY
1.通常不建议使用DISK_ONLY和后缀为_2的级别
缓存使用时机:每个RDD的compute执行时,将判断缓存的存储级别。如果指定过存储级别则读取缓存
缓存应用场景
- 从文件加载数据之后,因为重新获取文件成本较高
- 经过较多的算子变换之后,重新计算成本较高
- 单个非常消耗资源的算子之后
使用注意事项
- cache()或persist()后不能再有其他算子
- cache()或persist()遇到Action算子完成后才生效
检查点:类似于快照
sc.setCheckpointDir("hdfs:/checkpoint0918")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.checkpoint
rdd.collect //生成快照
rdd.isCheckpointed
rdd.getCheckpointFile
检查点与缓存的区别
- 检查点会删除RDD lineage,而缓存不会
- SparkContext被销毁后,检查点数据不会被删除
RDD共享变量
广播变量:允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本
//不能对RDD进行广播
val broadcastVar=sc.broadcast(Array(1,2,3)) //定义广播变量
broadcastVar.value //访问方式
注意事项:
1、Driver端变量在每个Executor每个Task保存一个变量副本
2、Driver端广播变量在每个Executor只保存一个变量副本
累加器:只允许added操作,常用于实现计数
val accum = sc.accumulator(0,"My Accumulator")
sc.parallelize(Array(1,2,3,4)).foreach(x=>accum+=x)
accum.value
RDD分区设计
分区大小限制为2GB
分区太少
- 不利于并发
- 更容易受数据倾斜影响
- groupBy, reduceByKey, sortByKey等内存压力增大
分区过多
- Shuffle开销越大
- 创建任务开销越大
经验
- 每个分区大约128MB
- 如果分区小于但接近2000,则设置为大于2000
数据倾斜
指分区中的数据分配不均匀,数据集中在少数分区中
- 严重影响性能
- 通常发生在groupBy,join等之后

定位导致数据倾斜的代码
- 常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等
解决方案
- 使用新的Hash值(如对key加盐)重新分区
- 对数据进行ETL预处理
- 过滤少数导致倾斜的key
- 提高shuffle操作的并行度
- 两阶段聚合(局部聚合+全局聚合)
- 将reduce join转为map join
- 采样倾斜key并分拆join操作
- 使用随机前缀和扩容RDD进行join
示例:WordCount
- 新建maven项目
不清楚如何创建maven项目的可以点击这里(前六步) - 配置pom.xml文件
<!- 版本需要根据自己使用的版本进行修改>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
-
引入scala SDK

-
现在即可创建scala Class

-
点击后选择Object

-
现在即可在里面进行编写Spark程序
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partition, SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数
//初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量
//驱动器程序通过SparkContext对象来访问Spark
//创建SparkConf对象,配置初始化参数
//setMaster:设置Executor数量(local:一个,local[3]:三个,local[*]:由电脑线程决定)
//setAppName:名称
val conf:SparkConf = new SparkConf().setMaster("local[3]").setAppName("wordcount")
//获取SparkContxt实例,传入SparkConf对象
val sc:SparkContext = SparkContext.getOrCreate(conf)
//创建RDD
//调用SparkContext 的 parallelize(),将一个存在的集合,变成一个RDD,这种方式试用于学习spark和做一些spark的测试
//我们可以通过parallelize的第二个参数设置rdd分区数
val rdd1:RDD[String] = sc.parallelize(List("hello world","hello java","hello scala"),3)
//对RDD进行操作,实现功能
//RDD后的一系列操作称为算子,在Spark学习的过程中,这部分相对比较重要,需要了解的访问下面的地址
//https://blog.csdn.net/weixin_38468167/article/details/109488651
rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).collect.foreach(println)
}
}
//输出结果
(hello,3)
(java,1)
(world,1)
(scala,1)
Spark WordCount运行原理

四、Spark SQL
Shark:Spark SQL前身
初衷:让Hive运行在Spark之上
- 是对Hive的改造,继承了大量Hive代码,给优化和维护带来了大量的麻烦

架构

- Spark SQL是Spark的核心组件之一(2014.4 Spark1.0)
- 能够直接访问现存的Hive数据
- 提供JDBC/ODBC接口供第三方工具借助Spark进行数据处理
- 提供了更高层级的接口方便地处理数据
- 支持多种操作方式:SQL、API编程
- 支持多种外部数据源:Parquet、JSON、RDBMS等
运行原理
- Catalyst优化器是Spark SQL的核心

Catalyst Optimizer:Catalyst优化器,将逻辑计划转为物理计划
Catalyst优化器
-
逻辑计划

-
优化
1、在投影上面查询过滤器
2、检查过滤是否可下压

- 物理计划

API
SparkContext
SQLContext
- Spark SQL的编程入口
HiveContext
- SQLContext的子集,包含更多功能
SparkSession(Spark 2.x推荐)
- SparkSession:合并了SQLContext与HiveContext
- 提供与Spark功能交互单一入口点,并允许使用DataFrame和Dataset API对Spark进行编程
//SaprkSession的创建方式
val spark = SparkSession.builder.master("master").appName("appName").getOrCreate()
DataSet(Spark 1.6+)
- 特定域对象中的强类型集合
创建方式
- RDD隐式转换toDS()
object DatasetDemo{
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//定义隐式转换(否则会报错)
import spark.implicits._
//创建DataSet
spark.createDataset(1 to 3).show
spark.createDataset(List(("a",1),("b",2),("c",3))).show
spark.createDataset(sc.parallelize(List(("a",1,1),("b",2,2)))).show
//显示数据
ds.show()
}
}
1、createDataset()的参数可以是:Seq、Array、RDD
2、上面三行代码生成的Dataset分别是:Dataset[Int]、Dataset[(String,Int)]、Dataset[(String,Int,Int)]
3、Dataset=RDD+Schema,所以Dataset与RDD有大部共同的函数,如map、filter等
- 使用Case Class创建Dataset
Scala中在class关键字前加上case关键字 这个类就成为了样例类,样例类和普通类区别:
(1)不需要new可以直接生成对象
(2)默认实现序列化接口
(3)默认自动覆盖 toString()、equals()、hashCode()
object DatasetDemo{
//定义样例类
case class student(name:String,age:Int)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//定义隐式转换(否则会报错)
import spark.implicits._
//创建RDD,将属性通过map转成student类型,在通过toDS转成Dataset
val ds = spark.sparkContext.parallelize(Array(("zs",1),("ls",2))).map(x=>student(x._1,x._2)).toDS()
//显示数据
ds.show()
}
}
- 加载csv文件
object DatasetDemo{
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//使用read函数加载csv文件返回Dataset对象
val ds = spark.read.csv("file:///home/hadoop/data/users.csv")
ds.show()
}
}
- 加载json文件
object DatasetDemo{
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//使用read函数加载csv文件返回Dataset对象
val df = spark.read.json("file:///home/hadoop/data/people.json")
ds.show()
}
}
- DataFrame转Dataset
1.RDD -> Dataset
val ds = rdd.toDS()
2.RDD -> DataFrame
val df=rdd.toDF()
3.Dataset -> RDD
val rdd = ds.rdd
4.Dataset -> DataFrame
val df = ds.toDF()
5.DataFrame -> RDD
val rdd = df.rdd
6.DataFrame -> Dataset
val ds = df.toJSON
val ds = df.as[T]
DataFrame(Spark 1.4+)
- DataFrame=Dataset[Row]
- 类似传统数据的二维表格
- 在RDD基础上加入了Schema(数据结构信息)
- DataFrame Schema支持嵌套数据类型
struct
map
array
- 提供更多类似SQL操作的API
RDD与DataFrame对比

创建方式
- RDD -> DataFrame
object Dataset2 {
//定义样例类
case class student(name: String, age: Int)
def main(args: Array[String]): Unit = {
//获取SparkSession实例
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//引入implicits
import spark.implicits._
//通过RDD.map将数据转成student类型,在.toDF生成DataFrame对象
val df = spark.sparkContext.parallelize(List(("zs,20"),("ls,24"))).map(_.split(",")).map(x=>student(x(0),x(1).toInt)).toDF()
df.show()
/*
+----+---+
|name|age|
+----+---+
| zs| 20|
| ls| 24|
+----+---+
*/
- (RDD[ROW],Schema) -> DataFrame
Schema的作用:因为RDD的数据本身没有结构,可以通过创建DataFrame的时候传入Schema,指定RDD的数据结构
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//定义生成DataFrame的RDD数据列名
val schemaString="name age"
//这里需要引入一下包
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{StringType,StructField,StructType}
//然后使用StructType函数,将定义的schemaString切分后生成对应的StructField(列名,类型)
//返回类型为StructType[StructField[x,StringType]]
val schema = StructType(schemaString.split(" ").map(x=>StructField(x,StringType,true)))
//创建RDD,通过.map将数据都转成RDD[ROW]格式
val rdd:RDD[Row] = spark.sparkContext.parallelize(List(("zs,20"),("ls,24"))).map(_.split(",")).map(x=>Row(x(0),x(1)))
val frame = spark.createDataFrame(rdd,schema)
frame.show()
/*
+----+---+
|name|age|
+----+---+
| zs| 20|
| ls| 22|
+----+---+
*/
- 加载csv格式文件
object SelectCSV {
def main(args: Array[String]): Unit = {
//获取SparkSession实例
val conf = new SparkConf().setMaster("local").setAppName("select")
val spark = SparkSession.builder().config(conf).getOrCreate()
//加载cav格式文件
val df:DataFrame = spark.read.format("csv").option("header","true").load("in/users.csv")
//显示文件数据结构
df.printSchema()
/*
root
|-- user_id: string (nullable = true)
|-- locale: string (nullable = true)
|-- birthyear: string (nullable = true)
|-- gender: string (nullable = true)
|-- joinedAt: string (nullable = true)
|-- location: string (nullable = true)
|-- timezone: string (nullable = true)
*/
//显示列名为user_id与locale的数据
df.select("user_id","locale").show()
/*
+----------+------+
| user_id|locale|
+----------+------+
|3197468391| id_ID|
|3537982273| id_ID|
| 823183725| en_US|
| 184647001| id_ID|
|1013376584| id_ID|
|2686249984| en_US|
+----------+------+
*/
}
}
加载Json格式文件
object SelectJSON {
def main(args: Array[String]): Unit = {
//护球SparkSession实例
val conf: SparkConf = new SparkConf().setAppName("csv").setMaster("local")
val session = SparkSession.builder().config(conf).getOrCreate()
//加载Json格式文件
val df = session.read.format("json").option("header","true").load("in/users.json")
//显示文件数据结构
df.printSchema()
/*
root
|-- Age: long (nullable = true)
|-- name: string (nullable = true)
*/
//显示json文件数据
df.select("Age","name").show()
/*
+----+-------+
| Age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
*/
常用算子
DataSet、DataFrame有很多算子与与RDD一致,这里就不重复太多,示例一部分 演示一下
object DataSet {
//定义样例类
case class student(name:String,age:Integer,grade:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("ds").getOrCreate()
//定义隐式转换(否则会报错)
import spark.implicits._
//使用集合转Dataset
val ds1 = spark.sparkContext.parallelize( Seq(("zs",20,"13"),("ls",23,"15"))).map(x=>student(x._1,x._2,x._3)).toDS()
//显示表结构
ds1.printSchema()
/*root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- grade: string (nullable = true)*/
//选择输出
println("____________________select_________________________")
//仅显示name列的数据
ds1.select("name").show()
/*
+----+
|name|
+----+
| zs|
| ls|
+----+*/
//仅显示name列的数据的第一条
ds1.select("name").show(1)
/*
+----+
|name|
+----+
| zs|
+----+*/
//过滤器
println("____________________filter/where_________________________")
//过滤出,age大于20的数据信息
ds1.filter("age>20").show()
/*
+----+---+-----+
|name|age|grade|
+----+---+-----+
| ls| 23| 15|
+----+---+-----+*/
//过滤出字段age小于20并且grade字段不为空的数据
//filter可以使用$符合来指定操作字段
ds1.filter($"age"<=20 && $"grade"!=null).show()
/*
+----+---+-----+
|name|age|grade|
+----+---+-----+
| zs| 20| 13|
+----+---+-----+
*/
//过滤age字段大于20,并且grade等于15的数据
//x为每行数据相当于一个对象
ds1.filter(x=>x.age>20 && x.grade.equals("15")).show()
/*
+----+---+-----+
|name|age|grade|
+----+---+-----+
| ls| 23| 15|
+----+---+-----+
*/
//等同于filter
ds1.where("age>20").show()
ds1.where($"age"<=20 && $"grade"!=null).show()
//这句是错的,where不能像filter一样可以按列操作
//ds1.where(x=>x.age>20 && x.grade.equals("15")).show()
//操作列名 属性
println("____________________withColumn_________________________")
//新增列,列名name1,数据与name一致
val dswc2 = ds1.withColumn("name1",ds1.col("name"))
dswc2.printSchema()
/* root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- grade: string (nullable = true)
|-- name1: string (nullable = true)*/
//修改列名,将原来的name改为Name
val dswc3 = ds1.withColumn("Name",ds1.col("name"))
dswc3.printSchema()
/*root
|-- Name: string (nullable = true)
|-- age: integer (nullable = true)
|-- grade: string (nullable = true)*/
//新增列,列名Grade,将grade列的数据以int类型传至新列
val dswc4 = ds1.withColumn("Grade",ds1.col("grade").cast("int"))
dswc4.printSchema()
/*root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- Grade: integer (nullable = true)*/
//修改grade列的数据类型为int
val dswc5 = ds1.withColumn("grade",ds1.col("grade").cast("int"))
dswc5.printSchema()
/*root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- grade: integer (nullable = true)*/
//将age列的所有数据整体加5
val dswc6 = ds1.withColumn("age",ds1.col("age")+5)
dswc6.printSchema()
/*
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- grade: string (nullable = true)
*/
dswc6.show()
/*
+----+---+-----+
|name|age|grade|
+----+---+-----+
| zs| 25| 13|
| ls| 28| 15|
+----+---+-----+*/
//删除age列
val dswc7 = ds1.drop("age")
dswc7.printSchema()
/*root
|-- name: string (nullable = true)
|-- grade: string (nullable = true*/
}
}
聚合聚合Agg
agg的作用
- 正常情况下,当我们使用了聚合算子,后面就无法在使用其他聚合算子
- 而agg可以使我们同时获取多个聚合运算结果
示例
object InnerFunctionDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("function").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val stuDF: DataFrame = Seq(
Student(1001, "zhangsan", "F", 20),
Student(1002, "lisi", "M", 16),
Student(1003, "wangwu", "M", 21),
Student(1004, "zhaoliu", "F", 21),
Student(1005, "zhouqi", "M", 22),
Student(1006, "qianba", "M", 19),
Student(1007, "liuliu", "F", 23)
).toDF()
import org.apache.spark.sql.functions._
//同样也可以这样写
//stuDF.groupBy("gender").agg(max("age"),min("age"),avg("age"),count("id")).show()
stuDF.groupBy("gender").agg("age"->"max","age"->"min","age"->"avg","id"->"count").show()
/*
+------+--------+--------+------------------+---------+
|gender|max(age)|min(age)| avg(age)|count(id)|
+------+--------+--------+------------------+---------+
| F| 23| 20|21.333333333333332| 3|
| M| 22| 16| 19.5| 4|
+------+--------+--------+------------------+---------+
*/
}
}
窗口函数
- ‘*’为表中所有列,‘rank()为窗口,是一个新列,于Mysql的使用一致’
val df = df.selectExpr("*"," rank() over(partition by 字段 order by 字段 desc) as 字段别名" )
//selectExpr之后依旧可以执行一些其他操作
val df = df.selectExpr("*"," rank() over(partition by 字段 order by 字段 desc) as 字段别名" ).where.等等
正则匹配
- 基于API实现正则匹配得方式
//使用rlike正则匹配
//示例:过滤匹配时间戳
val df=df.filter($"timestamp".rlike("^\\d{4}-\\d{2}-\\d{2}\\s\\d{2}:\\d{2}:\\d{2}.*"))
- 基于SQL实现正则匹配得方式
//通过regexp来实现正则匹配
//注册视图
df.createOrReplaceTempView("df")
spark.sql("""
select * from df where timestamp regexp '^\\d{4}-\\d{2}-\\d{2}T\\d{2}:\\d{2}:\\d{2}.*'
""").show()
UDF定义与使用
UDF概述
- UDF(一进一出):对每个列中的每个元素进行操作,只返回一个结果
UDF的定义
spark.udf.register("自定义UDF名称",(v:[数据类型])=>[自定义执行代码块...])
UDF的使用
spark.sql("select UDF名称(字段) from 表(DF/视图等)")
示例
object SparkUDFDemo {
case class Hobbies(name:String,hobbies: String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("udf").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val rdd = sc.parallelize(List(("zs,29"),("ls,23")))
val df = rdd.map(x=>x.split(",")).map(x=>Hobbies(x(0),x(1))).toDF()
df.show()
/*
+----+-------+
|name|hobbies|
+----+-------+
| zs| 29|
| ls| 23|
+----+-------+
*/
//创建视图
df.createOrReplaceTempView("df")
//定义UDF
spark.udf.register("hoby_num",(v:String)=>v.length)
//使用UDF
val frame:DataFrame = spark.sql("select name,hobbies,hoby_num(hobbies) as hobnum from df")
frame.show()
/*
+----+-------+------+
|name|hobbies|hobnum|
+----+-------+------+
| zs| 29| 2|
| ls| 23| 2|
+----+-------+------+
*/
}
}
UDAF的定义与使用
UDAF概述
- UDAF(多进一出):类似聚合函数
- UDF(一进一出):UDF的定义与使用
- UDTF(一进多出):UDTF的定义与使用
UDAF定义
//创建class类继承UserDefinedAggregateFunction并重写其中的方法inputSchema、bufferSchema、dataType、deterministic、initialize、update、merge、evaluate
class 类名 extends UserDefinedAggregateFunction{}
UDAF的使用
//注册自定义UDAF函数
val 对象名= new 类名
spark.udf.register("自定义UDAF名称",对象名)
//在sapark.sql中操作指定列
val df2: DataFrame = spark.sql("select 字段,UDAF名称(字段) from userinfo group by 字段")
UDAF示例
/*
user.json数据
{"id": 1001, "name": "foo", "sex": "man", "age": 20}
{"id": 1002, "name": "bar", "sex": "man", "age": 24}
{"id": 1003, "name": "baz", "sex": "man", "age": 18}
{"id": 1004, "name": "foo1", "sex": "woman", "age": 17}
{"id": 1005, "name": "bar2", "sex": "woman", "age": 19}
{"id": 1006, "name": "baz3", "sex": "woman", "age": 20}
*/
object SparkUDAFDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("UDAF").getOrCreate()
import spark.implicits._
val df: DataFrame = spark.read.json("in/user.json")
//创建并注册自定义UDAF函数
val function = new MyAgeAvgFunction
spark.udf.register("myAvgAge",function)
//创建视图
df.createTempView("userinfo")
//查询男女平均年龄
val df2: DataFrame = spark.sql("select sex,myAvgAge(age) from userinfo group by sex")
df2.show()
}
}
//实现UDAF类
//实现的功能是对传入的数值进行累加,并且计数传入的个数,最后相除得到平均数
class MyAgeAvgFunction extends UserDefinedAggregateFunction{
//聚合函数的输入数据结构
override def inputSchema: StructType = {
new StructType().add(StructField("age",LongType))
}
//缓存区数据结构
override def bufferSchema: StructType = {
new StructType().add(StructField("sum",LongType)).add(StructField("count",LongType))
}
//聚合函数返回值数据结构
override def dataType: DataType = DoubleType
//聚合函数是否是幂等的,即相同输入是否能得到相同输出
override def deterministic: Boolean = true
//设定默认值
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//sum
buffer(0)=0L
//count
buffer(1)=0L
}
//给聚合函数传入一条新数据时所需要进行的操作
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//将传入的数据进行累加
buffer(0)=buffer.getLong(0)+input.getLong(0)
//每传入一次计数加一
buffer(1)=buffer.getLong(1)+1
}
//合并聚合函数的缓冲区(不同分区)
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
//不同分区的数据进行累加
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
//计算最终结果
override def evaluate(buffer: Row): Any = {
//将sum/count的得到平均数
buffer.getLong(0).toDouble/buffer.getLong(1)
}
}
UDTF的定义与使用
UDTF概述
- UDTF(一进多出):对每个列中的每一个元素进行操作,返回一个列(行转列)
UDTF的定义
//创建class类继承GenericUDTF,重写initialize、process、close
class UDTF类名 extends GenericUDTF {}
UDTF的使用
//在获取SparkSession实例时需要加上.enableHiveSupport(),否则无法使用
val spark = SparkSession.builder().appName("UDTF").master("local[*]").enableHiveSupport().getOrCreate()
//注册UDTF
spark.sql("CREATE TEMPORARY FUNCTION 自定义UDTF别名 AS 'UDTF类名'")
UDTF示例
/*
UDTF.txt测试数据
01//zs//Hadoop scala
02//ls//Hadoop kafka
03//ww//spark hive sqoop
*/
object SparkUDTFDemo {
def main(args: Array[String]): Unit = {
//在获取SparkSession实例时加上enableHiveSupport
val spark = SparkSession.builder().appName("UDTF").master("local[*]").enableHiveSupport().getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val rdd = sc.textFile("in/UDTF.txt")
val df = rdd.map(_.split("//")).map(x=>(x(0),x(1),x(2))).toDF("id","name","class")
df.createOrReplaceTempView("student")
//注册UDTF,如果报错说找不到UDTF类,可像我这里写的一样,加上包名nj.kgc.类名
spark.sql("CREATE TEMPORARY FUNCTION udtf AS 'nj.kgc.myUDTF'")
//对比原始
spark.sql("select name,class from student").show()
/*
+----+----------------+
|name| class|
+----+----------------+
| zs| Hadoop scala|
| ls| Hadoop kafka|
| ww|spark hive sqoop|
+----+----------------+
*/
//使用UDTF后
spark.sql("select name,udtf(class) from student").show()
/*
+----+------+
|name| type|
+----+------+
| zs|Hadoop|
| zs| scala|
| ls|Hadoop|
| ls| kafka|
| ww| spark|
| ww| hive|
| ww| sqoop|
+----+------+
*/
}
}
//创建UDTF类继承GenericUDTF并重写下面的方法
class myUDTF extends GenericUDTF {
override def initialize(argOIs: Array[ObjectInspector]): StructObjectInspector = {
//判断传入的参数是否只有一个
if (argOIs.length != 1) {
throw new UDFArgumentException("有且只能有一个参数")
}
//判断参数类型
if (argOIs(0).getCategory != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("参数类型不匹配")
}
val fieldNames = new util.ArrayList[String]
val fieldOIs = new util.ArrayList[ObjectInspector]
fieldNames.add("type")
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector)
ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs)
}
override def process(objects: Array[AnyRef]): Unit = {
//将传入的数据拆分,形成一个Array数组
val strings: Array[String] = objects(0).toString.split(" ")
//遍历集合
for (elem <- strings) {
//每次循环都创建一个新数组,长度为1
val tmp = new Array[String](1)
//将循环到的数据传入数组
tmp(0) = elem
//显示出去,必须传入的时数组
forward(tmp)
}
}
//关闭方法,这里就不写了
override def close(): Unit = {}
}
操作外部数据源
Spark To MySQL
- 创建maven项目
- 然后在pom.xml中添加依赖包(根据的自己的使用的版本修改,不清楚的可以去maven官网查找自己对应版本的代码),对项目创建不清楚的可以:
点击这里](https://blog.csdn.net/weixin_38468167/article/details/109471551)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
- 读取MySQL数据
object SparkToMysql {
def main(args: Array[String]): Unit = {
//获取SparkSession实例
val spark = SparkSession.builder().master("local[*]").appName("mysql").getOrCreate()
//定义url格式为:“jdbc:mysql://IP地址:3306/库名”
val url="jdbc:mysql://192.168.**.**:3306/hive"
//mysql用户名
val user="root"
//mysql密码
val password="ok"
//deriver
val driver="com.mysql.jdbc.Driver"
//创建Properties实例
val prop=new Properties()
//将用户名、密码以及driver放入prop对象中
prop.setProperty("user",user)
prop.setProperty("password",password)
prop.setProperty("driver",driver)
//通过spark.read.jdbc的方式将url、表名以及配置信息传入,即可读取
val df: DataFrame = spark.read.jdbc(url,"TBLS",prop)
}
}
- 数据写入MySQL
//ds为DataSet
ds.write.format(source = "jdbc")
.mode(SaveMode.Append)
.option("url", "jdbc:mysql://192.168.**.**:3306/库名")
.option("dbtable", "表名")
.option("user", "用户名")
.option("password", "密码")
.option("driver", "com.mysql.jdbc.Driver")
.save()
Spark To Hive
- 在pom.xml中添加依赖(同样根据自己使用的版本情况修改版本号)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
- 读取hive表中的数据
object SparksqlOnHiveDemo {
def main(args: Array[String]): Unit = {
//配置SparkSession,启用对Hive的支持,配置hive的IP与端口
val spark = SparkSession.builder()
.appName("hive")
.master("local[*]")
.config("hive.metastore.uris","thrift://192.168.**.**:9083")
.enableHiveSupport()
.getOrCreate()
//spark默认连接hive default库
//连接其他库需要"库名.表名"
val df:DataFrame = spark.sql("select * from hive_demo.employee")
}
}
Spark To HDFS
- 读取HDFS上的数据无需添加依赖
- 读取本地文件数据
object SparkToHDFS {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("hdfs").master("local[*]").getOrCreate()
//testFile默认读取本地路径,如果在前面加上"hdfs://IP地址:9000/路径"即可读取HDFS上的数据
val ds: Dataset[String] = spark.read.textFile("hdfs://192.168.**.**:9000/test/a.txt")
}
}
四、Spark Streaming
1.介绍
Spark Streaming是基于Spark Core API的扩展,用于流式数据处理
- 支持多种数据源和多种输出

特点
- 高容错
- 可扩展
- 高流量
- 低延时(Spark 2.3.1 延时1ms,之前100ms)
什么是(数据)流
- 数据的流入
- 数据的处理
- 数据的流出
随处可见的数据流
- 电商网站、日志服务器、社交网络和交通监控产生的大量实时数据
流处理
- 是一种允许用户在接收到的数据后的短时间内快速查询连续数据流和检测条件的技术
为什么需要流处理
- 它能够更快地提供洞察力,通常在毫秒到秒之间
大部分数据的产生过程都是一个永无止境的事件流
- 要进行批处理,需要存储它,在某个时间停止数据收集,并处理数据
- 流处理自然适合时间序列数据和检测模式随时间推移
流处理的应用场景
- 股市监控
- 交通监控
- 计算机系统与网络监控
- 监控生产线
- 供应链优化
- 入侵、监视和欺诈检测
- 大多数智能设备应用
- 上下文感知促销和广告
- ……
常用流处理框架
- Apache Spark Streaming
- Apache Flink
- Confluent
- Apache Storm
2.流数据处理架构

3.内部工作流程
微批处理:输入->分批处理->结果集
- 以离散流的形式传入数据(DStream:Discretized Streams)
- 流被分成微批次(1-10s),每一个微批都是一个RDD

4.StreamingContext
- Spark Streaming流处理的入口
- 2.2版本SparkSession未整合StreamingContext,所以仍需单独创建
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
//1、一个JVM只能有一个StreamingContext启动
//2、StreamingContext停止后不能再启动
val conf=new SparkConf().setMaster("local[2]").setAppName("kgc streaming demo")
val ssc=new StreamingContext(conf,Seconds(8))
在spark-shell下,会出现如下错误提示:
org.apache.spark.SparkException: Only one SparkContext may be running in this JVM
解决:
方法1、sc.stop //创建ssc前,停止spark-shell自行启动的SparkContext
方法2、或者通过已有的sc创建ssc:val ssc=new StreamingContext(sc,Seconds(8))
5.流数据类型:DStream
- 离散数据流(Discretized Stream)是Spark Streaming提供的高级别抽象
- DStream代表了一系列连续的RDDs
a.每个RDD都包含一个时间间隔内的数据
b.DStream既是输入的数据流,也是转换处理过的数据流
c.对DStream的转换操作即是对具体RDD操作

6.Input DStreams与接收器(Receivers)
- Input DStream指从某种流式数据源(Streaming Sources)接收流数据的DStream
流式数据源:文件系统、Socket、Kafka、Flume……

每一个Input DStream(file stream除外)都与一个接收器(Receiver)相关联,接收器是从数据源提取数据到内存的专用对象
7.流式数据源创建方法
- 文件系统
def textFileStream(directory: String): DStream[String]
- Socket
def socketTextStream(hostname: String, port: Int, storageLevel: StorageLevel): ReceiverInputDStream[String]
- Flume Sink
val ds = FlumeUtils.createPollingStream(streamCtx, [sink hostname], [sink port]);
- Kafka Consumer
val ds = KafkaUtils.createStream(streamCtx, zooKeeper, consumerGrp, topicMap);
8.DStream支持的转换算子
- map,flatMap
- filter
- count, countByValue
- repartition
- union, join, cogroup
- reduce, reduceByKey
- transform
- updateStateByKey
9.DStream输出算子
- print()
- saveAsTextFiles(prefix,[suffix])
- saveAsObjectFiles(prefix,[suffix])
- saveAsHadoopFiles(prefix,[suffix])
- foreachRDD(func)
a.接收一个函数,并将该函数作用于DStream每个RDD上
b.函数在Driver节点中执行
示例:foreachRDD
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record =>
connection.send(record))
}
}
10.优化策略
减少批处理时间
- 数据接收并发度
- 数据处理并发度
- 任务启动开销
设置合适的批次间隔
内存调优
- DStream持久化级别
- 清除老数据
- CMS垃圾回收器
- 其他:使用堆外内存持久化RDD
演示一:将端口做为数据源
实现SparkStream类:两个版本二选一即可
实现SparkStream类(Scala版)
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkStream")
// 采集周期,指定的3秒为每次采集的时间间隔
val streamingContext = new StreamingContext(conf,Seconds(3))
// 指定采集的端口
val socketLineStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("192.168.**.**",7777)
//指定采集本地目录
//val socketLineStream: DStream[String] = streamingContext.textFileStream("file:///D:/ideaProject/SparkStream/in")
// 将采集的信息进行处理,统计数据(wordcount)
val wordStream: DStream[String] = socketLineStream.flatMap(line=>line.split("\\s+"))
val mapStream: DStream[(String, Int)] = wordStream.map(x=>(x,1))
val wordcountStream: DStream[(String, Int)] = mapStream.reduceByKey(_+_)
// 打印
wordcountStream.print()
// 启动采集器
streamingContext.start()
streamingContext.awaitTermination()
}
}
实现SparkStream类(Java版)
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class SparkStreamJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkStreamjava");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(3));
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("192.168.**.**", 7777);
JavaDStream<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
String[] split = s.split("\\s+");
return Arrays.asList(split).iterator();
}
});
JavaPairDStream<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
reduceByKey.print();
jsc.start();
try {
jsc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
启动SparkStreaming
启用端口
- 启用命令:
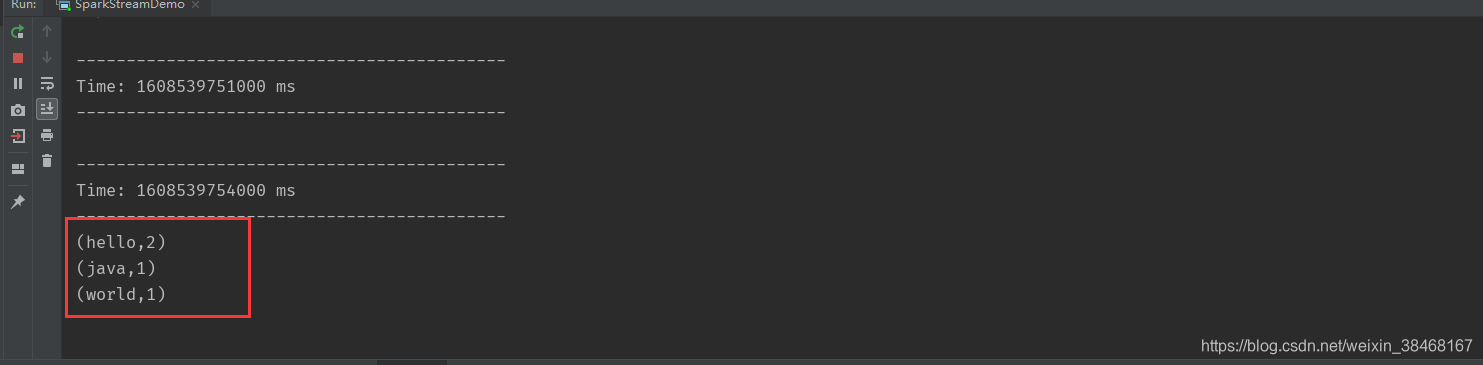
nc -lk 7777 - 输入数据
hello world
hello java
hello spark

查看Streaming输出内容
演示二:指定Kafka做为数据源
实现SparkStreaming类
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkStreamKafkaSource {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSreamKafkaSource").setMaster("local[*]")
val context = new StreamingContext(conf,Seconds(3))
//kafka配置信息
val kafkaParms: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.**.**:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "kafkaGroup1")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
context,
LocationStrategies.PreferConsistent,
//指定采集的Toipc,以及kafka配置信息
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParms)
)
//将采集的数据进行wordcount
val wordStream: DStream[String] = kafkaStream.flatMap(v=>v.value().toString.split("\\s+"))
val mapStream: DStream[(String, Int)] = wordStream.map((_,1))
val reduceStream: DStream[(String, Int)] = mapStream.reduceByKey(_+_)
//输出处理后的数据
reduceStream.print()
// 启动采集器
context.start()
context.awaitTermination()
}
}
创建Toipc
kafka-topics.sh --create --zookeeper 192.168.**.**:2181 --topic sparkKafkaDemo --partitions 1 --replication-factor 1
创建生产者
kafka-console-producer.sh --topic sparkKafkaDemo --broker-list 192.168.**.**:9092
启动SparkStreaming

生产者生产数据
hello world
hello java
hello spark

查看SparkStreaming输出数据

演示三:时间窗口示例
采集Kafka中数据
实现Spark Streaming类
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindoowDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSreamKafkaSource").setMaster("local[*]")
val context = new StreamingContext(conf, Seconds(2))
//存放临时数据目录(默认当前项目路径下)
context.checkpoint("in")
//配置Kafka信息
val kafkaParms: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.**.**:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "kafkaGroup1")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
context,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParms)
)
//设置窗口长度10秒
val numStream: DStream[(String,Int)] = kafkaStream.flatMap(x=>x.value().toString.split("\\s+")).map((_,1)).window(Seconds(10))
//设置窗口长度10秒,窗口间隔5秒
//val numStream: DStream[(String,Int)] = kafkaStream.flatMap(x=>x.value().toString.split("\\s+")).map((_,1)).window(Seconds(10),Seconds(6))
//使用计数窗口,窗口长度10秒,窗口间隔5秒
//val numStream: DStream[Long] = kafkaStream.flatMap(x=>x.value().toString.split("\\s+")).map((_,1)).countByWindow(Seconds(10),Seconds(6))
//仅对相同key的值进行计数,窗口长度10秒,窗口间隔6秒
//val numStream: DStream[(String, Long)] = kafkaStream.flatMap(x => x.value().toString.split("\\s+")).countByValueAndWindow(Seconds(10), Seconds(6))
//输出数据
numStream.print()
//开始采集
context.start()
context.awaitTermination()
}
}
创建Kafka Topic
kafka-topics.sh --create --zookeeper 192.168.**.**:2181 --topic sparkKafkaDemo --partitions 1 --replication-factor 1
创建Kafka 生产者
kafka-console-producer.sh --topic sparkKafkaDemo --broker-list 192.168.**.**:9092
启动Spark Streaming

生产者输入数据
hello world
Spark Streaming输出数据
















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









