









分析错误原因
decode 和encode的区别
decode是解码
encode是编码
报错信息是解码错误,utf8解码失败
怎么判断应该用什么来解码呢?
打印中文 以及中文的长度,分析每个中文占的字节大小
如果占两个是gb2312
如果占三个是utf8
gb2312还是很省地方的嘛!!
找到中文的编码类型,按照该类型来解码即可
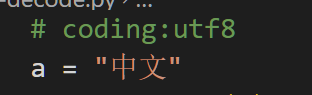
下面我们在vscode中尝试一下,举个例子:

我们看到两个中文字,占了6个字节,一个占3个字节,所以是utf8编码的
我们尝试用根本312解码,看看是否会报错:


我想改变中文的编码方式,怎么办?
用encode改变中文的编码方式

注意 如果python中有中文的话,必须在第一行中标注编码















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









