







在VC的编程过程中,windows和C/C++都有自己定义的模板库,可以对字符串进行各种操作,也要经常进行CString, string,字符数组之间的类型转换。本文就常遇到的字符串问题进行知识点总结。
1. 宽窄字符介绍
在我们平时的编程过程中还会见到很多类型的字节,如下:
● 窄字节:
char、char * 、const char *
CHAR、(PCHAR、PSTR、LPSTR)、LPCSTR
● Unicode 宽字节:
wchar_t、wchar_t * 、const wchar_t *
WCHAR、(PWCHAR、PWSTR、LPWSTR)、LPCWSTR
● T 通用类型:
TCHAR、(TCHAR * 、PTCHAR、PTSTR、LPTSTR)、LPCTSTR
其中:P代表指针的意思,STR代表字符串的意思,C代表const常量的意思,W代表wide宽字节的意思,T大家可以理解为通用类型的意思(L是长指针的意思,在WIN32平台下可以忽略)
比如:TCHAR 类型,如果工程中定义了UNICODE 宏,那么就表明工程是宽字节编码,他最终就被定义成 wchar_t 类型,如果工程中没有定义UNICODE 宏,就表明工程当前是窄字节编码,那么 TCHAR 被最终定义成 char 类型。
2. 宽窄字符串的使用
(1)宽窄字符串类型指针的定义:
● 窄字节:char *p_str = “hello”;
● Unicode宽字节:wchar_t *p_wstr = L"hello";
● 通用类型:TCHAR *p_tstr = _T(“hello”); 或者 TCHAR *p_tstr= _TEXT(“hello”);
● 动态申请内存:TCHAR *pszBuf = new TCHAR[100];
其中,_TEXT 和 _T 是一样的,定义如下:
#define _T(x) T(x)
#define _TEXT(x) T(x)
来看看 _T 的最终定义:
#ifdef _UNICODE
#define _T(x) L##x // ##代表连接的意思
#else
#define _T(x) x
#endif
(2)常用的宽窄字节字符串处理函数:
字符串长度:
● 窄字节:strlen(char *str);
● Unicode宽字节:wcslen(wchar_t *str);
● 通用函数:_tcslen(TCHAR *str);
●窄字节:int atoi(const char *str);
● Unicode宽字节:int _wtoi(const wchar_t *str);
● 通用函数:tstoi(const TCHAR str);
字符串拷贝:
● 窄字节:strcpy(char *strDestination, const char *strSource);
● Unicode宽字节:wcscpy(wchar_t *strDestination, const wchar_t *strSource);
● 通用函数:_tcscpy(TCHAR *strDestination, const TCHAR *strSource);
这些字符串拷贝函数不安全,可能会有警告,可以考虑使用新的函数:
● 窄字节:strcpy_s(char *strDestination, size_t numberOfElements, const char *strSource);
● Unicode宽字节:wcscpy_s(wchar_t *strDestination, size_t numberOfElements, const wchar_t *strSource);
● 通用函数:_tcscpy_s(TCHAR *strDestination, size_t numberOfElements, const TCHAR *strSource);
如果忽略警告,可以将 _CRT_SECURE_NO_WARNINGS 加入 以下位置:
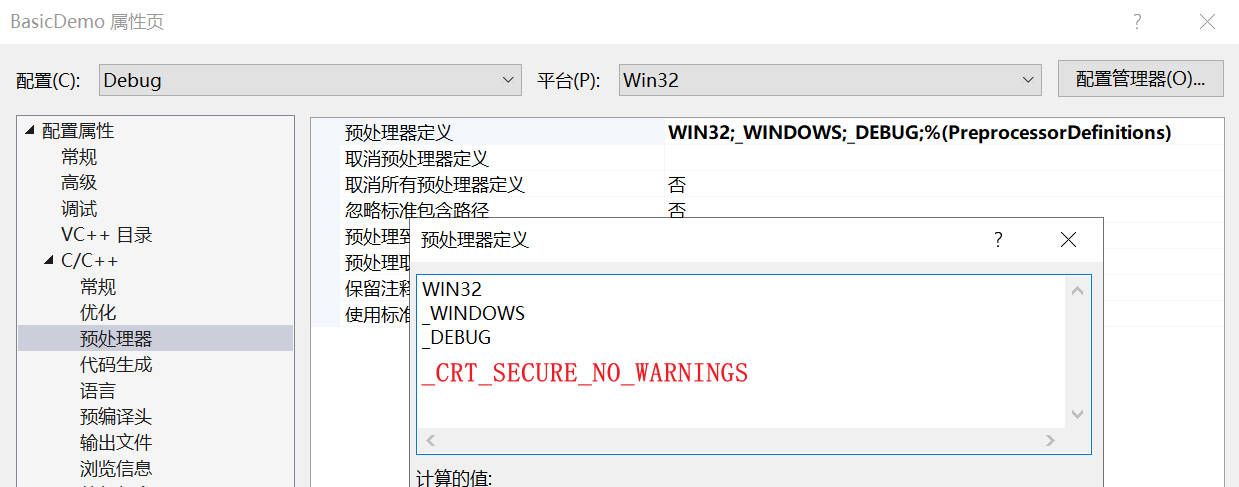
3. 宽窄字符串转换
//窄字节->宽字节
wchar_t* cctry_a2w(char* p_a){
int need_w_char = MultiByteToWideChar(CP_ACP, 0, p_a, -1, NULL, 0); //计算需要的宽字节数
if (need_w_char <= 0) return NULL;
wchar_t* p_w = new wchar_t[need_w_char]; //need_w_char 包含最后的'\0','\0'占2个字节
wmemset(p_w, 0, need_w_char);
MultiByteToWideChar(CP_ACP, 0, p_a, -1, p_w, need_w_char);
return p_w;
}
//宽字节->窄字节
char* cctry_w2a(wchar_t* p_w) {
int need_char = WideCharToMultiByte(CP_ACP, 0, p_w, -1, NULL, 0, NULL, NULL);
if (need_char <= 0) return NULL;
char* p_a = new char[need_char]; //need_char 包含最后的'\0','\0'占一个字节
memset(p_a, 0, need_char);
WideCharToMultiByte(CP_ACP, 0, p_w, -1, p_a, need_char, NULL, NULL);
return p_a;
}
#include <atlbase.h>
#include <atlstr.h> //使用CA2W,需要包含这两个头文件
int main(){
//方法一:使用 windows API 进行转换
char Text[] = "我爱你123!";
wchar_t* wText = cctry_a2w(Text);
char* cText = cctry_w2a(wText);
//方法二:使用windows封装的类进行转换
char p_a[] = "我爱你中国!";
CA2W a2wObj(p_a);
wchar_t* p_w = (wchar_t*)a2wObj;
CW2A w2aObj(p_w);
char* p_c = (char*)w2aObj;
return 0;
}
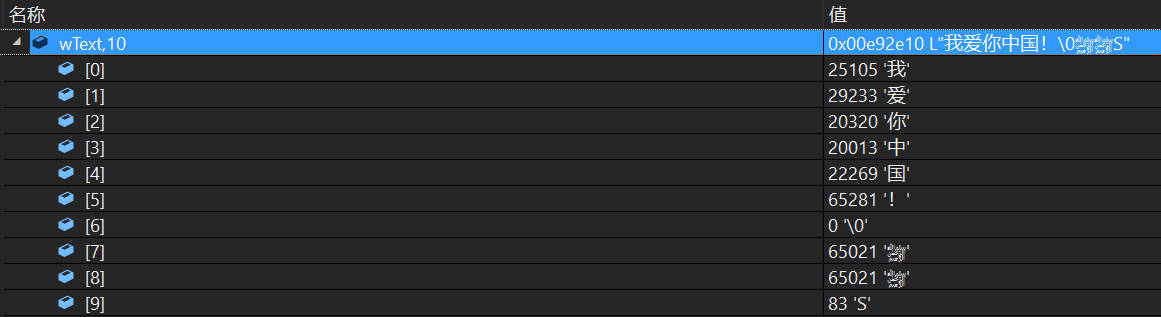
小Tips: 使用 ,10 可以显示wText指针开始的10个宽字节
4. CString类的使用
Cstring是ATL(active template library)中针对字符串的一个封装类,头文件 #include <altstr.h>,兼容MFC
(1)CString 对于 TCHAR 的封装:
针对当前编码,决定当前内部的指针是 char* 还是 wchar_t*,实际上CString 本身是个模板类,实际上有三种:
typedef ATL::CStringT< wchar_t, StrTraitMFC< wchar_t > > CStringW;
typedef ATL::CStringT< char, StrTraitMFC< char > > CStringA;
typedef ATL::CStringT< TCHAR, StrTraitMFC< TCHAR > > CString;
CStringA 内部使用的是 char,CStringW 内部使用的是 wchar_t,CString内部使用的是 TCHAR,所以 CString 本身会根据当前工程的编码决定使用 char 还是 wchar_t,这一点也比较方便。
(2)CString 类对于宽窄字节的转换:
const char* aaa = "123你好";
const wchar_t* bbb = L"123你好";
CString ccc;
ccc = aaa;
ccc = bbb;
(3) CString 操作:
trim 操作:去除掉首尾的不可见字符,比如回车,制表符,空格之类的;
reverse 操作:进行字符串的首尾颠倒反转;
upper操作:将字符串中的英文全变成大写字母;
lower操作:将字符串中的英文全变成小写字母;
right操作:直接返回字符串中结尾的指定字符;
format:格式化字符串
replace:替换字符串中的指定字符
#include <atlstr.h> //CString包含头文件
int main(int argc, TCHAR* argv[]){
CString str0 = _T(" abcdefg ");
str0.TrimLeft();
str0.TrimRight();
str0.Trim();
str0.MakeReverse();
str0.MakeUpper();
str0.MakeLower();
CString str1 = str0.Right(2);
CString str2;
str2.Format(" hello %d%s", 123, _T("zgx"));
str0.Replace("d", "D");
return 0;
}
5.string类的使用
(1)string对象构造
#include <iostream>
#include <string>
int main(int argc, TCHAR* argv[]){
std::string s0("Initial string");
// constructors used in the same order as described above:
std::string s1;
std::string s2(s0);
std::string s3(s0, 8, 3);
std::string s4("A character sequence");
std::string s5("Another character sequence", 12);
std::string s6a(10, 'x');
std::string s6b(10, 42); // 42 is the ASCII code for '*'
std::string s7(s0.begin(), s0.begin() + 7);
return 0;
}
(2)string赋值
std::string str1, str2, str3;
str1 = "Test string: "; // c-string
str2 = 'x'; // single character
str3 = str1 + str2; // string
std::cout << str3 << '\n';
(3)string遍历
std::string str ("Test string");
for ( std::string::iterator it=str.begin(); it!=str.end(); ++it)
std::cout << *it;
std::cout << '\n';
(4)string容量
//size(),length(),std::strlen()
char* cstr = "Test string";
std::string str ("Test string");
std::cout << "The size of str is " << str.size() << " bytes.\n"; //size()与length()用法相同
std::cout << "The size of cstr is " << std::strlen(cstr) << " bytes.\n";
//empty()
do {
getline(std::cin,line);
content += line + '\n';
} while (!line.empty());
(5)string更改
//[],at()
std::string str ("Test string");
for (int i=0; i<str.length(); ++i){
std::cout << str[i]; //等同于str.at(i)
}
//insert()
std::string str="to be question";
std::string str2="the ";
str.insert(6,str2); //"to be the question"
//erase()
std::string str ("This is an example sentence.");
str.erase (10,8); //"This is an sentence."
//swap()
std::string buyer ("money");
std::string seller ("goods");
buyer.swap(seller);
//c_str() 返回string指针
std::string str("Please split this sentence into tokens");
char* cstr = new char[str.length() + 1];
std::strcpy(cstr, str.c_str());
//find()
std::string str("There are two needles in this haystack with needles.");
std::string str2("needle");
std::size_t found = str.find(str2);
if (found != std::string::npos)
std::cout << "first 'needle' found at: " << found << '\n';
found = str.find("needles are small", found + 1, 6);
if (found != std::string::npos)
std::cout << "second 'needle' found at: " << found << '\n';
参考:VC驿站














 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









