






文献速递:多模态影像组学文献分享:生成一种多模态人工智能模型以区分甲状腺良性和恶性滤泡性肿瘤:概念验证研究
文献速递介绍
近年来,人工智能(AI)领域日益被探索,作为一种增强传统医学诊断和预后方法的手段。机器学习(ML),AI的一个子领域,是一系列算法,任务是通过从数据集中提取有意义的特征和模式来创建预测或二元分类。当应用于医学图像时,ML有潜力揭示人工分析所遗漏的诊断特征,并已展现出与专家放射科医生相当乃至超越的预测能力。鉴于甲状腺结节在普通人群中的高发病率,加之超声解释中的主观性问题和观察者间的可变性,改善甲状腺超声图像的分类一直是AI研究的特别关注领域。
特别是在甲状腺疾病领域,ML方法主要集中在开发二元分类模型上,试图仅凭超声图像更准确地区分良性和恶性结节。然而,大多数先前的研究都包括了所有甲状腺癌,很少有专注于特定组织学亚型,如滤泡性癌,它们约占分化型甲状腺癌的5%到10%。
滤泡性癌与良性滤泡腺瘤仅凭人类对超声的解释无法区分,在没有明确的局部区域性或转移性疾病的情况下,需要在外科切除后对包膜或血管侵犯进行病理确认。因此,传统基于图像特征的ML分类模型在这一特定亚型的应用可能面临特别的挑战。
提高这些ML模型预测能力的方法,特别是在不常见的组织类型上,仍然是探索性追求的领域。结合多模态数据,而不是仅使用单一视觉数据类型(例如,超声图像或病理切片)或传统的临床病理数据,可能是一种实现更高准确性的方法。理论上,这种数据融合更好地模拟了临床决策实际过程,临床医生必须考虑来自多个来源的不同数据类型(例如,实验室值、影像学、患者病史和症状、生命体征的实时趋势),并开始应用于医学领域的不同领域。最近对多模态ML在健康环境中的应用的综述显示,与单模态模型相比,多个先前研究中展示了更好的预测能力。然而,多模态模型由于需要获取、处理和清洗大量数据,可能构建起来复杂且耗时,并且使用这种方法的当前研究报告了不同的技术。
鉴于特定组织学亚型ML模型数据的匮乏,我们寻求探索多模态ML方法的新颖性,其具体的二元分类任务是预测滤泡性癌与腺瘤。因此,这个概念验证研究的目的是开发一个多模态ML模型,任务是在接受甲状腺手术的研究人群中对滤泡性癌与腺瘤进行分类,并评估其与单一数据类型ML模型相比的预测准确性。作为一项探索性研究,我们广泛调查了所有术前和术后临床和影像学特征的相对重要性,这些特征可能有助于滤泡性癌与腺瘤的分类,以更好地了解哪些数据点在这一患者人群中最具有预测癌症的能力。
Title
题目
Generating a multimodal artificial intelligence model to differentiatebenign and malignant follicular neoplasms of the thyroid: A proof-ofconcept study
生成一种多模态人工智能模型以区分甲状腺良性和恶性滤泡性肿瘤:概念验证研究
Background
背景
Machine learning has been increasingly used to develop algorithms that can improve
medical diagnostics and prognostication and has shown promise in improving the classification of
thyroid ultrasound images. This proof-of-concept study aims to develop a multimodal machine-learning
model to classify follicular carcinoma from adenoma.
机器学习已越来越多地被用于开发算法,以提高医学诊断和预后的能力,并且在改善甲状腺超声波影像分类方面显示出潜力。这项概念验证研究旨在开发一种多模态机器学习模型,以区分滤泡性癌症和腺瘤。
Methods
方法
This is a retrospective study of patients with follicular adenoma or carcinoma at a single
institution between 2010 and 2022. Demographics, imaging, and perioperative variables were collected.
The region of interest was annotated on ultrasound and used to perform radiomics analysis. Imaging
features and clinical variables were then used to create a random forest classifier to predict malignancy.Leave-one-out cross-validation was conducted to evaluate classifier performance using the area underthe receiver operating characteristic curve.
这是一项回顾性研究,研究了2010年至2022年期间在单一机构接受治疗的滤泡性腺瘤或癌症患者。收集了人口统计学、影像学和围手术期变量。在超声波上标注了感兴趣区域,并用于进行放射组学分析。然后使用影像特征和临床变量创建随机森林分类器以预测恶性肿瘤。使用接收者操作特征曲线下面积进行留一交叉验证以评估分类器性能。
Results
结果
Patients with follicular adenomas (n ¼ 7) and carcinomas (n ¼ 11) with complete imaging and
perioperative data were included. A total of 910 features were extracted from each image. The t
distributed stochastic neighbor embedding method reduced the dimension to 2 primary represented
components. The random forest classifier achieved an area under the receiver operating characteristic
curve of 0.76 (clinical only), 0.29 (image only), and 0.79 (multimodal data).Conclusion: Our multimodal machine learning model demonstrates promising results in classifyingfollicular carcinoma from adenoma. This approach can potentially be applied in future studies to generatemodels for preoperative differentiation of follicular thyroid neoplasms.
包括了有完整影像和围手术期数据的滤泡性腺瘤(n = 7)和癌症(n = 11)患者。每个影像中提取了910个特征。t分布的随机邻居嵌入方法将维度降至2个主要代表性组成部分。随机森林分类器在接收者操作特征曲线下面积达到0.76(仅临床),0.29(仅影像),和0.79(多模态数据)。结论:我们的多模态机器学习模型在区分滤泡性癌症和腺瘤方面显示出有希望的结果。这种方法未来可以应用于生成用于术前区分滤泡性甲状腺肿瘤的模型的研究。
Figure
图
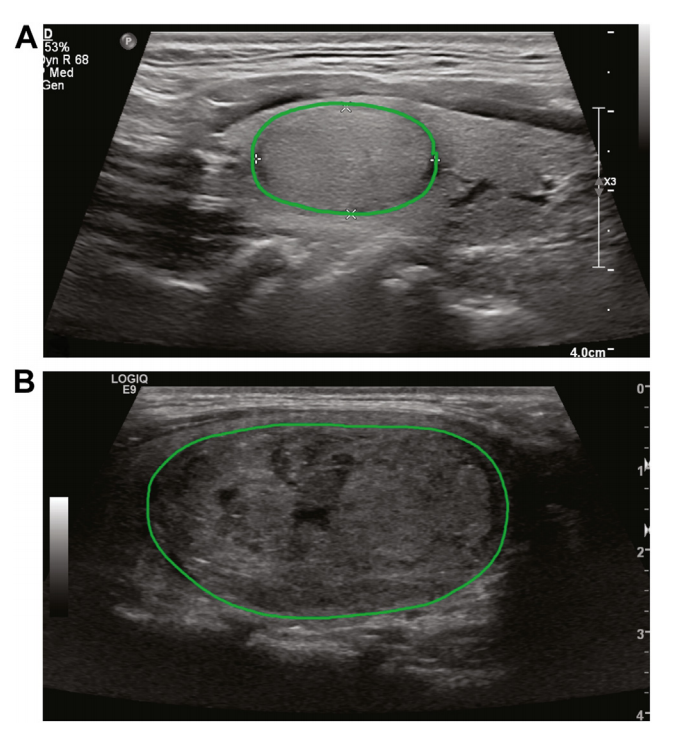
Figure 1. Two examples of annotated ultrasound imagesd(A) adenoma; (B) carcinoma. Ultrasound images were cross-referenced with pathology reports to identifynodule of interest in each patient. All images that had nodule in view were manuallyannotated as shown to indicate region of interest ROI.
图1. 两个标注过的超声波影像示例(A)腺瘤;(B)癌症。超声波影像与病理报告进行了交叉参考,以确定每个患者感兴趣的结节。所有展示结节的影像均已手动标注,如图所示,以指示感兴趣区域(ROI)。
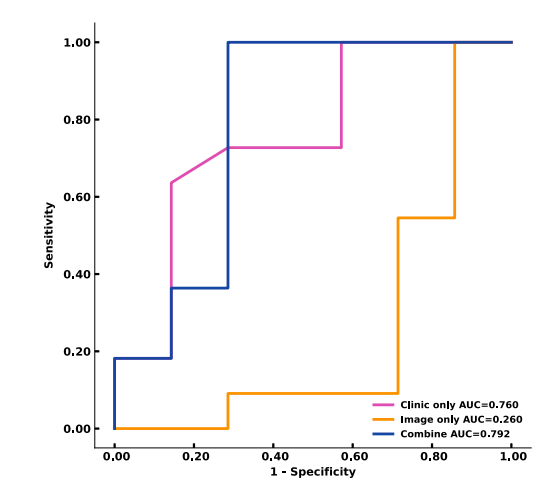
Figure 2. Receiver operating characteristic curves of clinical only, image only, andmultimodal model performance are shown. The area under the curve values demonstrate the improved performance of the multimodal model (0.792) in comparison withthe clinical only model (0.759) and image only model (0.260). AUC, area under thecurve.
图2. 仅临床、仅影像和多模态模型性能的接收者操作特征曲线展示如下。曲线下面积值显示了多模态模型(0.792)相比于仅临床模型(0.759)和仅影像模型(0.260)的性能提升。AUC,曲线下面积。
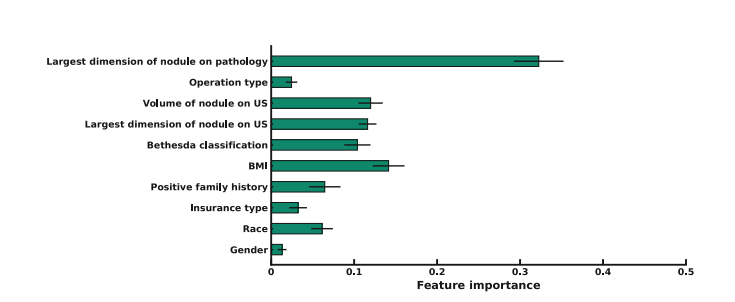
Figure 3. This graph displays feature importance score based on the clinical random forest classifier model, with size of nodule on pathology showing highest importance scoreamong the included clinical variables. BMI, body mass index; US, ultrasonography
图3. 该图展示了基于临床随机森林分类器模型的特征重要性评分,其中病理学上结节的大小显示为最高重要性评分在包括的临床变量中。BMI,身体质量指数;US,超声波检查。
Table
表
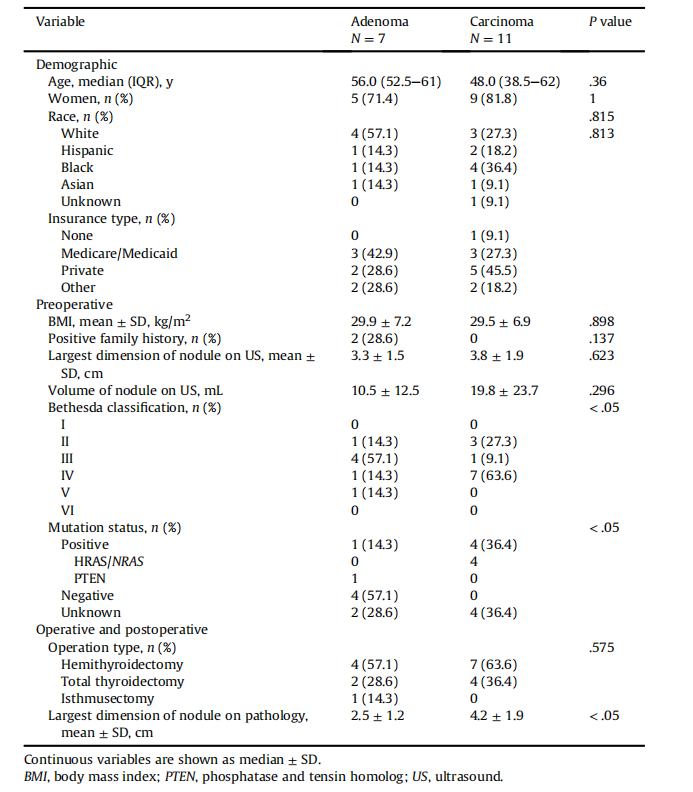
TableIDemographic,preoperative,andoperative/postoperative clinical variables for patients in the 2 cohorts
表I 两组患者的人口统计学、术前和术中/术后临床变量
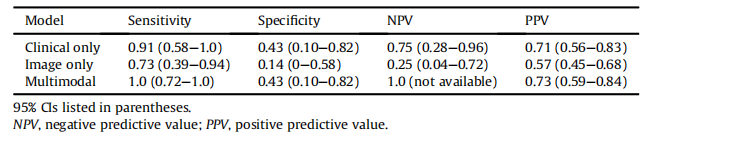
Table IISummary of sensitivity, specificity, NPV, and PPV of the clinical only, image only, and multimodal models
zx-1701917912981)]
Table IISummary of sensitivity, specificity, NPV, and PPV of the clinical only, image only, and multimodal models
表II 仅临床、仅影像和多模态模型的灵敏度、特异性、NPV和PPV总结
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









