







最近看了几篇关于剪枝的paper,汇总如下:
1.Channel Pruning for Accelerating Very Deep Neural Networks
论文地址:https://arxiv.org/abs/1707.06168
代码地址: https://github.com/yihui-he/channel-pruning
对于完成网络训练后的模型加速的方法一般有三种:优化实现(FFT,快速傅里叶变换), 网络量化(模型存储float32转int8), 重新构建简化网络。
这篇论文的主要工作在第三点:重构简化网络。构建简化的网络模型的方法包括张量分解(tensor factorization),稀疏连接(sparse connection),和通道剪枝(channel pruning)。
1.首先说下张量分解:
张量分解应用的模型最典型的如:GoogleNet,GoogLeNet 网络优异的性能主要源于大量使用降维处理。这种降维处理可以看做通过分解卷积来加快计算速度的手段。
大尺寸滤波器的卷积(如5X5, 7X7)引入的计算量很大。例如一个 5X5 的卷积比一个3X3卷积滤波器多25/9=2.78倍计算量。当然5X5滤波器可以学习到更多的信息。那么我们能不能使用一个多层感知器来代替这个 55 卷积滤波器。答案是可以的,5X5卷积看先用一个3X3的卷积滤波器卷积在5X5区域滑动,然后再用一个33卷积输出。简单地说就是分解大卷积为2个小卷积,减少计算量。
用公式算下,
[
(
W
−
F
+
2
P
)
/
S
]
+
1
[\left ( W-F+2P \right )/S ]+1
[(W−F+2P)/S]+1 w代表输入数据维度(设为200),F表示卷积核大小。p表示padding大小,这里按0算, S为步长假设1,
将5代入算下来输出特征图维度为196,代入3计算2次输出维度为195,对特征图几乎没有损失,这个可以通过padding弥补。

原模块结构:

替代后:

2.稀疏连接
这个主要用于最后全连接层的优化,因为全连接层的参数量非常大,例如在VGG16中,第一个全连接层FC1有4096个节点,上一层POOL2是77512 = 25088个节点,则该传输需要4096*25088个权值,可占整个网络参数80%左右,需要耗很大的内存。该稀疏化方式一般是给全连接层的参数设定阈值R,让|a|<R的参数都为零,这种方法适用于硬件中保存模型的加速。博主测试了一下,让全连接层20%的权重稀疏为0,并不会让测试结果变得很差,这种方法不足是对模型的大小没有变化,但能够对后续硬件化有用。
先稀疏连接网络,然后用工具float32位转int8位,可以将模型大小减小为原来的四分之一,博主用腾讯开源的NCNN转了下,模型保存为bin格式。
实验如图:稀疏20%

稀疏全连接层后:

3. 通道剪枝
好了,终于言归正传,这篇《Channel Pruning for Accelerating Very Deep Neural Networks》论文主要工作在于剔除不重要的特征图通道,如下图所示(d)部分。

文章中说步骤(c)稀疏卷积层( sparse convolutional layers)为不规则形状很难实现,实现步骤(d)通道剪枝的方式直接降低了feature map的宽度,从而将网络缩减为更精简的网络,同时在CPU和GPU能实现很有效。
修剪通道很简单,但很有挑战性,因为删除一层中的通道可能会极大地改变下一层的输入。基于训练的通道剪枝工作主要是在训练过程中对权值施加稀疏约束,自适应地确定超参数,训练花费代价昂贵。本文的剪枝算法如下:

上图中虚线框是剪枝算法优化核心,其中字母B表示输入feature map,同时c表示B的通道数量;字母W表示卷积核,卷积核的数量是n,每个卷积核的维度是ckhkw,kh和kw表示卷积核的size;字母C表示输出feature map,通道数是n。因此通道剪枝的目的是要把B中的某些通道剪掉,使得剪掉后的B和W的卷积结果能尽可能和C接近。当要剪掉B中的一些feature map的通道时,相当于剪掉了W中与这些通道对应的卷积核(对应W中3个最小的立方体块),这也是后面要介绍的公式中β的含义和之所以用L1范数来约束β的原因,因为L1范数会使得W更加稀疏。另外生成这些被剪掉通道的feature map的卷积核也可以删掉(对应Figure2中第二列的6个长条矩形块中的2个黑色虚线框的矩形块)
主要目标有:
1.减少特征图B的数量为B。
2.减少B通道的同时对卷积核W通道重构(大白话就是减去B中特征图对应得卷积核),减为为w。
3.损失函数最小化,,用原始输出
C
−
W
0
×
B
0
C-W_{0}\times B_{0}
C−W0×B0使其最小
这个是文章中构建的损失函数,本质一样哈,后面做了一系列的假设,推导,博主也就讲到这了,后面慢慢推~
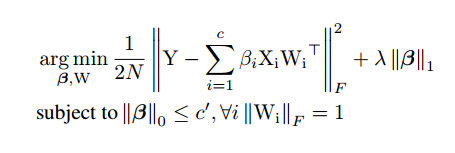
如下图,文章中说使用岭回归算法裁剪通道,重构通道使用最小二乘算法。实验结果在VGG-16上获得4倍加速,仅有1%的错误率降低,ResNet-50加速2倍,错误率降低1.4,效果相当不错。

前面介绍的都是对于网络没有分支情况下的通道剪枝,但是现在的ResNet、GoogleNet网络都有多分枝,对于这种网络,文中以ResNet为例也做了分析,如下图residual block中,除了第一层和最后一层外的其他层都可以采用前面介绍的通道剪枝方式进行剪枝。针对第一层,因为原来其输入feature map的通道数是输出的4倍,因此在剪枝之前先对输入feature map做采样。针对最后一层的通道剪枝,由原来对Y2来优化,改成对Y1-Y1‘+Y2来优化(Y1和Y2表示剪枝之前的输出),Y1’表示前面层剪枝后得到的结果(也就是该residual block的输入,只不过和Y1不同的是该输入是前面层剪枝后得到的结果),否者shortcut部分带来的误差会对结果影响较大。
















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









