






教程所用colab相关环境版本
环境安装
conda create -n mmdet python=3.10.11pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113pip install -U "openmim==0.3.7"
mim install "mmengine==0.7.1"
mim install "mmcv==2.0.0"git clone -b tutorials https://github.com/open-mmlab/mmdetection.gitcd mmdetection
pip install -e .1 数据集准备和可视化
wget https://download.openmmlab.com/mmyolo/data/cat_dataset.zip
unzip cat_dataset.zip -d cat_dataset 8& rm cat_dataset.zip
其模型架构图如上所示。RTMDet 是一个高性能低延时的检测算法,目前已经实现了目标检测、实例分割和旋转框检测任务。其简要描述为:为了获得更高效的模型架构,MMDetection 探索了一种具有骨和 Nek 兼容容量的架构,由一个基本的构建块构成,其中包含大核深度卷积。MMDetection 进一步在动态标签分配中计算匹配成本时引入软标签,以提高准确性,结合更好的训练技巧,得到的目标检测器名为RTMDet,在 NVIDIA 3090 GPU 上以超过 300 FPS 的速度实现了 528% 的 COCO AP,优于当前主流的工业检测器。RTMDet 在小中/大特大型模型尺寸中实现了最佳的参数-准确度权衡,适用于各种应用场景,并在实时实例分割和旋转对象检测方面取得了新的最先进性能。

# 当前路径位于 mmdetection/tutorials, 配置将写到 mmdetection/tutorials 路径下
_base_ = '../configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py'
data_root = 'balloon_dataset/'
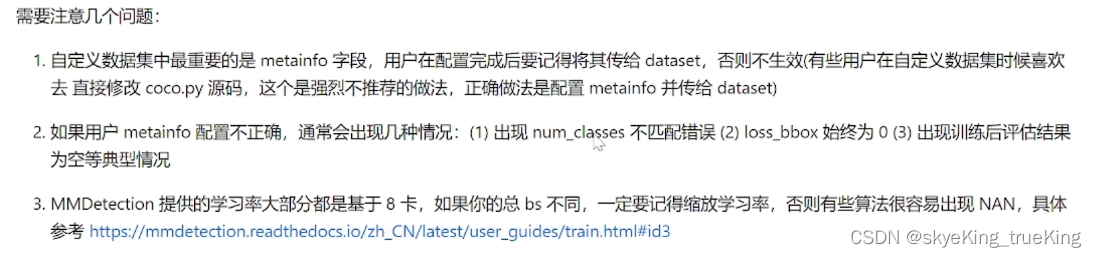
# 非常重要
metainfo = {
# 类别名,注意 classes 需要是一个 tuple,因此即使是单类,
# 你应该写成 `cat,` 很多初学者经常会在这犯错
'classes': ('balloon',),
'palette': [
(220, 20, 60),
]
}
num_classes = 1
# 训练 40 epoch
max_epochs = 200
# 训练单卡 bs= 12
train_batch_size_per_gpu = 12
# 可以根据自己的电脑修改
train_num_workers = 16
# 验证集 batch size 为 1
val_batch_size_per_gpu = 1
val_num_workers = 16
# RTMDet 训练过程分成 2 个 stage,第二个 stage 会切换数据增强 pipeline
num_epochs_stage2 = 5
# batch 改变了,学习率也要跟着改变, 0.004 是 8卡x32 的学习率
base_lr = 12 * 0.004 / (32*8)
# 采用 COCO 预训练权重
load_from = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth' # noqa
model = dict(
# 考虑到数据集太小,且训练时间很短,我们把 backbone 完全固定
# 用户自己的数据集可能需要解冻 backbone
backbone=dict(frozen_stages=4),
# 不要忘记修改 num_classes
bbox_head=dict(dict(num_classes=num_classes)))
# 数据集不同,dataset 输入参数也不一样
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
pin_memory=False,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='balloon/train/balloon_train.json',
data_prefix=dict(img='balloon/train/')))
val_dataloader = dict(
batch_size=val_batch_size_per_gpu,
num_workers=val_num_workers,
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='balloon/val/balloon_val.json',
data_prefix=dict(img='balloon/val/')))
test_dataloader = val_dataloader
# 默认的学习率调度器是 warmup 1000,但是 cat 数据集太小了,需要修改 为 30 iter
param_scheduler = [
dict(
type='LinearLR',
start_factor=1.0e-5,
by_epoch=False,
begin=0,
end=30),
dict(
type='CosineAnnealingLR',
eta_min=base_lr * 0.05,
begin=max_epochs // 2, # max_epoch 也改变了
end=max_epochs,
T_max=max_epochs // 2,
by_epoch=True,
convert_to_iter_based=True),
]
optim_wrapper = dict(optimizer=dict(lr=base_lr))
# 第二 stage 切换 pipeline 的 epoch 时刻也改变了
_base_.custom_hooks[1].switch_epoch = max_epochs - num_epochs_stage2
val_evaluator = dict(ann_file=data_root + 'balloon/val/balloon_val.json')
test_evaluator = val_evaluator
# 一些打印设置修改
default_hooks = dict(
checkpoint=dict(interval=10, max_keep_ckpts=2, save_best='auto'), # 同时保存最好性能权重
logger=dict(type='LoggerHook', interval=5))
train_cfg = dict(max_epochs=max_epochs, val_interval=10)_base_ 基于算法
data_root 训练测试数据集所在目录
mateinfo:classes后面紧跟着类别名,类型必须是元祖;palette(调色板)类型对应的颜色
val batch size per gpu 每张图验证一次
RTMDet训练过程氛围2个stage,第二个satge会切换数据增强pipeline
batch lr (学习率)
backbone的frozen stage =4 固定backbone
param scheduler 的 end 改为30,当训练图片较小时

ckpts保存最大数量为10个,interval指的是每隔10个训练步骤保存一次,启用save best会保存最佳权重















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









