






MMSegmentation代码课_哔哩哔哩_bilibili
open-mmlab/mmsegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. (github.com)
安装参考
卫星遥感训练流程
下载数据
下载
在mmsegmentation下
wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/dataset/Dubai-dataset.zip
unzip Dubai-dataset.zip >> /dev/null # 解压
rm -rf Dubai-dataset.zip # 删除压缩包在mmsegmentation主目录中,出现文件夹Dubai-dataset
删除系统自动生成的多余文件
!for i in `find . -iname '__MACOSX'`; do rm -rf $i;done
!for i in `find . -iname '.DS_Store'`; do rm -rf $i;done
!for i in `find . -iname '.ipynb_checkpoints'`; do rm -rf $i;done可视化数据
在mmsegmentation目录下,导入依赖
import os
import cv2
import numpy as np
from PIL import Image
from tqdm import tqdm
import matplotlib.pyplot as plt
%matplotlib inline查看单张图及其语义分割
# 指定单张图像路径
img_path = 'Dubai-dataset/img_dir/train/14.jpg'
mask_path = 'Dubai-dataset/ann_dir/train/14.png'Image.open(img_path)Image.open(mask_path)mask灰度图标的含义
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)# mask 语义分割标注,与原图大小相同
np.unique(mask)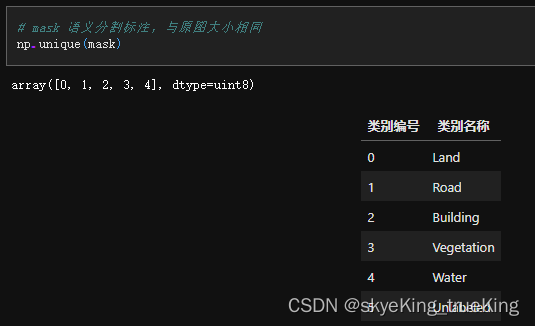
# 可视化语义分割标注
plt.imshow(mask[:,:,0])
plt.show()叠在原图上显示
plt.imshow(img[:,:,::-1])
plt.imshow(mask[:,:,0], alpha=0.4) # alpha 高亮区域透明度,越小越接近原图
plt.axis('off')
plt.show()批量可视化图像和标注
# 指定图像和标注路径
PATH_IMAGE = 'Dubai-dataset/img_dir/train'
PATH_MASKS = 'Dubai-dataset/ann_dir/train'# n行n列可视化
n = 5
# 标注区域透明度
opacity = 0.5
fig, axes = plt.subplots(nrows=n, ncols=n, sharex=True, figsize=(12,12))
for i, file_name in enumerate(os.listdir(PATH_IMAGE)[:n**2]):
# 载入图像和标注
img_path = os.path.join(PATH_IMAGE, file_name)
mask_path = os.path.join(PATH_MASKS, file_name.split('.')[0]+'.png')
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
# 可视化
axes[i//n, i%n].imshow(img)
axes[i//n, i%n].imshow(mask[:,:,0], alpha=opacity)
axes[i//n, i%n].axis('off') # 关闭坐标轴显示
fig.suptitle('Image and Semantic Label', fontsize=30)
plt.tight_layout()
plt.show()
准备config配置文件
在mmsegmentation目录下
导入依赖
import numpy as np
from PIL import Image
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
import matplotlib.pyplot as plt
%matplotlib inline定义数据类(类别名称及配色)
!rm -rf mmseg/datasets/DubaiDataset.py # 删除原有文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/DubaiDataset.py -P mmseg/datasets
reduce zero label 类别ID为0是否除去
注册数据类
!rm -rf mmseg/datasets/__init__.py # 删除原有文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/__init__.py -P mmseg/datasets

定义训练及测试pipeline
!rm -rf configs/_base_/datasets/DubaiDataset_pipeline.py
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/DubaiDataset_pipeline.py -P configs/_base_/datasets

下载模型config配置文件
!rm -rf configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py # 删除原有文件
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/Dubai/pspnet_r50-d8_4xb2-40k_DubaiDataset.py -P configs/pspnet
载入配置文件
from mmengine import Config
cfg = Config.fromfile('./configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py')
修改配置文件
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
# modify num classes of the model in decode/auxiliary head
# 模型 decode/auxiliary 输出头,指定为类别个数
cfg.model.decode_head.num_classes = 6
cfg.model.auxiliary_head.num_classes = 6
cfg.train_dataloader.batch_size = 8
cfg.test_dataloader = cfg.val_dataloader
# 结果保存目录
cfg.work_dir = './work_dirs/DubaiDataset'
# 训练迭代次数
cfg.train_cfg.max_iters = 3000
# 评估模型间隔
cfg.train_cfg.val_interval = 400
# 日志记录间隔
cfg.default_hooks.logger.interval = 100
# 模型权重保存间隔
cfg.default_hooks.checkpoint.interval = 1500
# 随机数种子
cfg['randomness'] = dict(seed=0)cfg.model.auxiliary_head.num_classes后面跟的是语音分割的类型个数
保存配置文件
cfg.dump('pspnet-DubaiDataset_20230612.py')训练语义分割模型
在mmsegmenttation目录下执行
导入依赖
import numpy as np
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine载入config配置文件
from mmengine import Config
cfg = Config.fromfile('pspnet-DubaiDataset_20230612.py')准备训练
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)开始训练
runner.train()如果遇到报错CUDA out of memeory,可尝试以下步骤:
-
调小 batch size
-
左上角
内核-关闭所有内核 -
重启实例,或者使用显存更高的实例即可。
可视化日志
在mmsegmentation目录下
设置Matplotlib中文字体
# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 如果遇到 SSL 相关报错,重新运行本代码块即可
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf
!rm -rf /home/featurize/.cache/matplotlibimport matplotlib
import matplotlib.pyplot as plt
matplotlib.rc("font",family='SimHei') # 中文字体
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline# 日志文件路径
log_path = 'work_dirs/DubaiDataset/20230612_100725/vis_data/scalars.json'
with open(log_path, "r") as f:
json_list = f.readlines()
len(json_list)
eval(json_list[4])df_train = pd.DataFrame()
df_test = pd.DataFrame()
for each in json_list[:-1]:
if 'aAcc' in each:
df_test = df_test.append(eval(each), ignore_index=True)
else:
df_train = df_train.append(eval(each), ignore_index=True)df_traindf_testdf_train.to_csv('训练日志-训练集.csv', index=False)
df_test.to_csv('训练日志-测试集.csv', index=False)可视化辅助函数
from matplotlib import colors as mcolors
import random
random.seed(124)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink']
markers = [".",",","o","v","^","<",">","1","2","3","4","8","s","p","P","*","h","H","+","x","X","D","d","|","_",0,1,2,3,4,5,6,7,8,9,10,11]
linestyle = ['--', '-.', '-']
def get_line_arg():
'''
随机产生一种绘图线型
'''
line_arg = {}
line_arg['color'] = random.choice(colors)
# line_arg['marker'] = random.choice(markers)
line_arg['linestyle'] = random.choice(linestyle)
line_arg['linewidth'] = random.randint(1, 4)
# line_arg['markersize'] = random.randint(3, 5)
return line_arg训练集损失函数
metrics = ['loss', 'decode.loss_ce', 'aux.loss_ce']
plt.figure(figsize=(16, 8))
x = df_train['step']
for y in metrics:
plt.plot(x, df_train[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.xlabel('step', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集损失函数', fontsize=25)
plt.savefig('训练集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()训练集准确率
df_train.columnsmetrics = ['decode.acc_seg', 'aux.acc_seg']plt.figure(figsize=(16, 8))
x = df_train['step']
for y in metrics:
plt.plot(x, df_train[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.xlabel('step', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集准确率', fontsize=25)
plt.savefig('训练集准确率.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()测试集评估指标
df_test.columnsmetrics = ['aAcc', 'mIoU', 'mAcc']plt.figure(figsize=(16, 8))
x = df_test['step']
for y in metrics:
plt.plot(x, df_test[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.ylim([0, 100])
plt.xlabel('step', fontsize=20)
plt.ylabel(y, fontsize=20)
plt.title('测试集评估指标', fontsize=25)
plt.savefig('测试集分类评估指标.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()














 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









