







练习中的一些注意事项:
1)dat文件里面其实包含了变量X与y信息。而且把这个变量名字也包含在文件中的。
2)多分类时,预测结果要转成与Y可以比较的,需要在每一行找到最大值的索引(代表数字),然后与y进行比较
[all_theta] = oneVsAll(X, y, num_labels,lambda);
由于从dat文件中分解出来的y是数字1,2,3…并不能直接用于代价函数的计算,因此在
oneVsAll(X, y, num_labels, lambda)中调用代价函数时采用
[all_theta(c,:)] = fmincg(@(t)(lrCostFunction(t, X, (y == c), lambda)),initial_theta, options);
其中提交给lrCostFunction代价函数的y的是0或者1。0或者1由(y == c)决定。
1. 代价函数的计算
可以直接给出带正则化的计算,验证非正则化时,lambda代入0就可以了。
正则化时的代价函数计算公式:
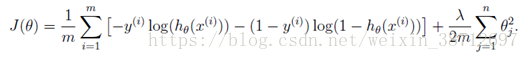
向量化的计算如下:
gz=sigmoid(X*theta); % calc g(z)
J1=y'*log(gz); %calc J cost function first part ,changeto vector calc
J0=(1-y)'*log(1-gz); %calc J cost functionsecond part, change to vector calc
theta_reg=theta(2:n);
reg=theta_reg'*theta_reg;
J=-(J1+J0)/m+lambda*reg/(2*m);
梯度计算的公式
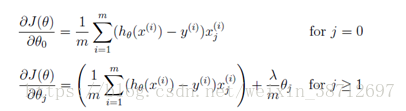
向量化计算如下:
beta=gz-y;
grad(1)=beta'*X(:,1)./m; %calc gradient ,vector calc
grad(2:n)=(beta'*X(:,[2:n])./m)'+lambda/m.*theta(2:n); %calc gradient ,vectorcalc
当然以上也可以优化,改成先计算没有正则化时的梯度,然后(2:n)再加上正则化的theta。
beta=gz-y;
grad(1)=beta'*X./m; %calc gradient ,vector calc
grad(2:n)= grad(2:n)+lambda/m.*theta(2:n); %calc gradient ,vectorcalc
2. 多分类时theta参数学习。
实际上有几个的分类标签label,就需要学习几组的theta
initial_theta = zeros(n + 1,1);
options = optimset('GradObj', 'on', 'MaxIter', 50);
for c = 1:num_labels
[all_theta(c,:)] = fmincg(@(t)(lrCostFunction(t, X, (y == c), lambda)),initial_theta, options);
end;
3. 参数学习后预测值与实际值的比较
predition=sigmoid(X*all_theta');
[val,p]=max(predition,[],2);%将每个行向量转化成数字标签0/1/2….9,方便与Y比较
通过mean(double(pred== y)) * 100 来计算正确率。
4. 神经网络
这个练习其实是推理,而不是训练。
输入层,隐藏层,输出层,总共3层网络。
X =[ones(m, 1) X]; % add onecolumn for bias calc
predition1=sigmoid(X*Theta1'); % hiden layer1 calc
predition1=[ones(m,1) predition1]; % add one column layerbias
predition2=sigmoid(predition1*Theta2');%output lay calc
[val,p]=max(predition2,[],2); %change to number














 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









