






点击下方卡片,关注“小白玩转Python”公众号
到目前为止,我们已经详细转换了各种重要的ViT架构。在这个视觉transformer系列的这一部分,我将使用PyTorch从零开始构建掩模自编码器视觉transformer。不再拖延,让我们直接进入主题!
掩模自编码器
Mae是一种自监督学习方法,这意味着它没有预先标记的目标数据,而是在训练时利用输入数据。这种方法主要涉及遮蔽图像的75%的补丁。因此,在创建补丁(H/补丁大小,W/补丁大小)之后,其中H和W是图像的高度和宽度,我们遮蔽75%的补丁,只使用其余的补丁并将其输入到标准的ViT中。这里的主要目标是仅使用图像中已知的补丁重建缺失的补丁。
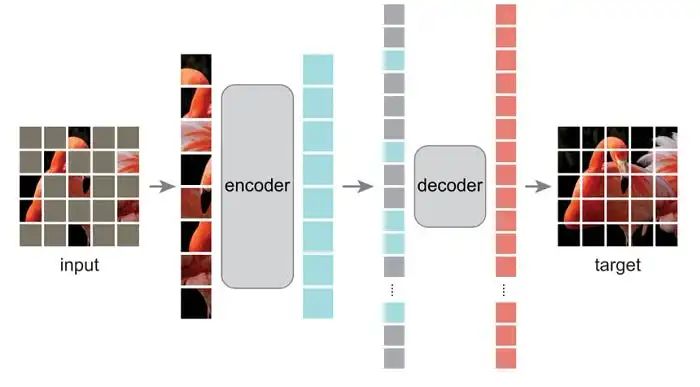
输入(75%的补丁被遮蔽) | 目标(重建缺失的像素)
MAE主要包含这三个组件:
随机遮蔽
编码器
解码器
随机掩盖
这就像选择图像的随机补丁,然后掩盖其中的3/4一样简单。然而,官方实现使用了不同但更有效的技术。
def random_masking(x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
B, T, D = x.shape
len_keep = int(T * (1 - mask_ratio))
# creating noise of shape (B, T) to latter generate random indices
noise = torch.rand(B, T, device=x.device)
# sorting the noise, and then ids_shuffle to keep the original indexe format
ids_shuffle = torch.argsort(noise, dim=1)
ids_restore = torch.argsort(ids_shuffle, dim=1)
# gathering the first few samples
ids_keep = ids_shuffle[:, :len_keep]
x = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([B, T], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x, mask, ids_restore假设输入形状是(B, T, C)。这里我们首先创建一个形状为(B, T)的随机张量,然后将其传递给argsort,这将为我们提供一个排序的索引张量——例如,torch.argsort([0.3, 0.4, 0.2]) = [2, 0, 1]。
我们还将ids_shuffle传递给另一个argsort以获取ids_restore。这只是一个具有原始索引格式的张量。
接下来,我们收集我们想要保留的标记。
生成二进制掩模,并将要保留的标记标记为0,其余标记为1。
最后,对掩模进行解洗牌,这里我们创建的ids_restore将有助于生成表示,掩模应该具有的。即哪些索引的标记被遮蔽为0或1,与原始输入有关?
注意:与在随机位置创建随机补丁不同,官方实现使用了不同的技术。
为图像生成随机索引。就像我们在ids_shuffle中所做的那样。然后获取前25%的索引(int(T*(1–3/4))或int(T/4)。我们只使用前25%的随机索引并遮蔽其余部分。
然后我们用ids_restore中原始索引的顺序帮助对掩模进行重新排序(解洗牌)。因此,在收集之前,掩模的前25%为0。但记住这些是随机索引,这就是为什么我们重新排序以获得掩模应该在的确切索引。
编码器
class MaskedAutoEncoder(nn.Module):
def __init__(self, emb_size=1024, decoder_emb_size=512, patch_size=16, num_head=16, encoder_num_layers=24, decoder_num_layers=8, in_channels=3, img_size=224):
super().__init__()
self.patch_embed = PatchEmbedding(emb_size = emb_size)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_emb_size))
self.encoder_transformer = nn.Sequential(*[Block(emb_size, num_head) for _ in range(encoder_num_layers)])
def encoder(self, x, mask_ratio):
x = self.patch_embed(x)
cls_token = x[:, :1, :]
x = x[:, 1:, :]
x, mask, restore_id = random_masking(x, mask_ratio)
x = torch.cat((cls_token, x), dim=1)
x = self.encoder_transformer(x)
return x, mask, restore_id1. PatchEmbedding和Block是ViT模型中的标准实现。
2. 我们首先获取图像的补丁嵌入(B, C, H, W)→(B, T, C),这里的PatchEmbedding实现还返回连接在嵌入张量x中的cls_token。如果你想使用timm库获取标准的PatchEmbed和Block,也可以这样做,但这个实现效果相同。即from timm.models.vision_transformer import PatchEmbed, Block
3. 由于我们已经有了cls_token,我们首先想要移除它,然后将其传递以生成遮蔽。x:(B K C),掩模:(B T)restore_id(B T),其中K是我们保留的标记的长度,即T/4。
4. 然后我们将cls_token连接起来并传递给标准的编码器_transformer。
解码器
解码阶段涉及将输入嵌入维度更改为decoder_embedding_size。回想一下,输入维度是(B, K, C),其中K是T/4。因此我们将未遮蔽的补丁与遮蔽的补丁连接起来,然后将它们输入到另一个视觉transformer模型(解码器)中,如图1所示。
class MaskedAutoEncoder(nn.Module):
def __init__(self, emb_size=1024, decoder_emb_size=512, patch_size=16, num_head=16, encoder_num_layers=24, decoder_num_layers=8, in_channels=3, img_size=224):
super().__init__()
self.patch_embed = PatchEmbedding(emb_size = emb_size)
self.decoder_embed = nn.Linear(emb_size, decoder_emb_size)
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, (img_size//patch_size)**2 + 1, decoder_emb_size), requires_grad=False)
self.decoder_pred = nn.Linear(decoder_emb_size, patch_size**2 * in_channels, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_emb_size))
self.encoder_transformer = nn.Sequential(*[Block(emb_size, num_head) for _ in range(encoder_num_layers)])
self.decoder_transformer = nn.Sequential(*[Block(decoder_emb_size, num_head) for _ in range(decoder_num_layers)])
self.project = self.projection = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=patch_size**2 * in_channels, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
def encoder(self, x, mask_ratio):
x = self.patch_embed(x)
cls_token = x[:, :1, :]
x = x[:, 1:, :]
x, mask, restore_id = random_masking(x, mask_ratio)
x = torch.cat((cls_token, x), dim=1)
x = self.encoder_transformer(x)
return x, mask, restore_id
def decoder(self, x, restore_id):
x = self.decoder_embed(x)
mask_tokens = self.mask_token.repeat(x.shape[0], restore_id.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1)
x_ = torch.gather(x_, dim=1, index=restore_id.unsqueeze(-1).repeat(1, 1, x.shape[2]))
x = torch.cat([x[:, :1, :], x_], dim=1)
# add pos embed
x = x + self.decoder_pos_embed
x = self.decoder_transformer(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x1. 我们将输入传递给decoder_embed。然后我们为所有我们遮蔽的标记创建mask_tokens,并将其与原始输入x连接起来,不包括其cls_token。
2. 现在张量具有前K个未遮蔽的标记,其余为遮蔽的标记,但现在我们想要按照索引的确切顺序重新排序它们。我们可以借助ids_restore来实现。
3. 现在ids_restore具有索引,当传递给torch.gather时,将对输入进行解洗牌。因此,我们在随机遮蔽中选择的未遮蔽标记(ids_shuffle中的前几个随机索引)现在被重新排列在它们应该在的确切顺序中。稍后我们再次将cls_token与重新排序的补丁连接起来。
4. 现在我们将整个输入传递给标准的视觉transformer,并移除cls_token并返回张量x以计算损失。
损失函数
掩模自编码器在遮蔽和未遮蔽的补丁上进行训练,并学习重建图像中的遮蔽补丁。掩模自编码器视觉transformer中使用的损失函数是均方误差。
class MaskedAutoEncoder(nn.Module):
def __init__(self, emb_size=1024, decoder_emb_size=512, patch_size=16, num_head=16, encoder_num_layers=24, decoder_num_layers=8, in_channels=3, img_size=224):
super().__init__()
self.patch_embed = PatchEmbedding(emb_size = emb_size)
self.decoder_embed = nn.Linear(emb_size, decoder_emb_size)
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, (img_size//patch_size)**2 + 1, decoder_emb_size), requires_grad=False)
self.decoder_pred = nn.Linear(decoder_emb_size, patch_size**2 * in_channels, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_emb_size))
self.encoder_transformer = nn.Sequential(*[Block(emb_size, num_head) for _ in range(encoder_num_layers)])
self.decoder_transformer = nn.Sequential(*[Block(decoder_emb_size, num_head) for _ in range(decoder_num_layers)])
self.project = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=patch_size**2 * in_channels, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
def random_masking(x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
B, T, D = x.shape
len_keep = int(T * (1 - mask_ratio))
# creating noise of shape (B, T) to latter generate random indices
noise = torch.rand(B, T, device=x.device)
# sorting the noise, and then ids_shuffle to keep the original indexe format
ids_shuffle = torch.argsort(noise, dim=1)
ids_restore = torch.argsort(ids_shuffle, dim=1)
# gathering the first few samples
ids_keep = ids_shuffle[:, :len_keep]
x = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([B, T], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x, mask, ids_restore
def encoder(self, x, mask_ratio):
x = self.patch_embed(x)
cls_token = x[:, :1, :]
x = x[:, 1:, :]
x, mask, restore_id = self.random_masking(x, mask_ratio)
x = torch.cat((cls_token, x), dim=1)
x = self.encoder_transformer(x)
return x, mask, restore_id
def decoder(self, x, restore_id):
x = self.decoder_embed(x)
mask_tokens = self.mask_token.repeat(x.shape[0], restore_id.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1)
x_ = torch.gather(x_, dim=1, index=restore_id.unsqueeze(-1).repeat(1, 1, x.shape[2]))
x = torch.cat([x[:, :1, :], x_], dim=1)
# add pos embed
x = x + self.decoder_pos_embed
x = self.decoder_transformer(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
def loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, patch*patch*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.project(imgs)
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
def forward(self, img):
mask_ratio = 0.75
x, mask, restore_ids = self.encoder(img, mask_ratio)
pred = self.decoder(x, restore_ids)
loss = self.loss(img, pred, mask)
return loss, pred, mask1. 在未遮蔽的补丁上训练视觉transformer模型,
2. 将未遮蔽补丁的输出与遮蔽补丁重新排序。
3. 在遮蔽和未遮蔽的补丁结合在一起的原始形式上训练视觉transformer模型。
4. 计算解码器预测输出的最后一个维度(B, T, decoder embed)和图像的原始补丁嵌入(B, T, patch embedding)之间的均方误差损失。
源码:
https://github.com/mishra-18/ML-Models/blob/main/Vission%20Transformers/mae.py

· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









